Inverse Probability Weighting and Age-of-Information Aggregation for Decentralized Federated Learning under Partial Reception
Abstract
Decentralized Federated Learning (DFL) over lossy wireless networks faces two key challenges: selection bias, where updates from poor-quality links are systematically underrepresented due to partial model reception, and update staleness, where asynchronous nodes contribute outdated information. We show that uniform gossip aggregation with local-fill reconstruction introduces persistent link-quality-induced bias, while completeness-based weighting further amplifies this effect. To address these challenges, we propose DFL-AA (Decentralized Federated Learning with Adaptive AoI-weighted Aggregation), which combines Inverse Probability Weighting with online EWMA-based channel estimation to correct selection bias and Age-of-Information-based weighting to mitigate staleness without requiring global synchronization. We theoretically show that DFL-AA removes link-quality distortion in expectation and experimentally demonstrate consistent improvements over state-of-the-art baselines across varying loss rates, network sizes, and heterogeneous wireless conditions.
I Introduction
Distributed edge intelligence in wireless sensor networks and IoT environments increasingly relies on Decentralized Federated Learning (DFL) [1, 2] rather than centralized alternatives [3, 4, 5], enabling collaborative model training without requiring the centralization of raw data. DFL is particularly suitable for applications such as industrial IoT systems, smart city infrastructures, autonomous vehicle networks, and UAV swarms, where data is generated in a distributed manner at the network edge. However, these environments typically operate over unreliable wireless communication channels and are subject to strict latency constraints, making retransmission-based communication mechanisms impractical. As a result, maintaining efficient and robust decentralized learning under lossy communication conditions remains a significant challenge.
(1) Unreliable Communication: Wireless communication links widely used in networks experience high packet loss due to distance, interference, and obstacles. Unlike data centers with loss [6], wireless networks cannot rely on TCP (Transmission Control Protocol) retransmissions without violating the low-latency requirements of real-time decision-making. Additionally, industrial evidence also verified that retransmission overhead caused by TCP-like protocols is a significant performance bottleneck in production deployments [7, 8, 9]. Figure 1 illustrates the expected data loss over an unreliable communication channel for a given ML model. In this regime, nodes must aggregate whatever partial model information is available at each communication round rather than waiting for complete reception. In practice, per-link channel quality varies across the network due to differences in distance and interference, motivating per-link channel estimation rather than a single global loss parameter.

(2) Heterogeneity and Asynchrony: System heterogeneity in computation speed and link quality, combined with non-IID (Independent and Identically Distributed) data distributions across nodes, causes gradient divergence. In wireless deployments, nodes train and communicate at different rates, determined by local compute capacity and link availability, resulting in genuinely asynchronous behavior with no global synchronization barrier. Figure 2 further illustrates the asynchronous behavior of decentralized training and communication of peer nodes due to their heterogeneous capabilities. Partial model reception under these conditions creates asymmetric information availability, in which nodes with poor links receive fewer of their neighbors’ models over rounds, amplifying the effect of data heterogeneity on aggregation quality.

I-A The Problem: Partial and Stale Updates
When focusing on the low-latency “fire-and-forget” regime, where retransmissions are infeasible, decentralized wireless networks face spatial incompleteness and temporal freshness issues. Model parameters are serialized into fixed-size chunks. Each chunk is dropped independently, so the receiving node receives an incomplete parameter vector. Critically, these two failure modes are independent in origin. Selection bias from spatial incompleteness arises from channel quality, while staleness arises from compute and communication heterogeneity and must be addressed jointly within a single aggregation rule to avoid compounding their effects.
I-B Motivation
Most existing production-level Federated Learning approaches assume reliable communication, even when they do not explicitly state so [10, 11, 8]. When it comes to DFL [12, 13, 14, 15, 16] and wireless DFL deployments focusing on vehicular systems [17, 18, 19, 20], most works still assume perfect communication. However, a lightweight solution that meets low-latency constraints is required to address the aforementioned challenge in DFL configurations, especially when operating in a wireless regime with no or minimal retransmissions. Systematic solutions in the literature for handling partial receptions without retransmissions either drop partially received updates or naively fill in the missing data from the local model [21, 22] or zeros or maintain a complex network coding to reconstruct missing data chunks [23]. These approaches lead either to wasted communication resources by ignoring updates, to selection bias due to naive partial acceptance, or to extra overhead in heavy computation. Reconstruction methods for lossy channels alone cannot withstand realistic conditions in a wireless DFL setting, as described earlier. Moreover, the integration of model freshness effects into partial model reception in configurations remains limited, even though it should be properly managed given the inherent asynchrony. This gap is particularly acute in IoT and sensor network deployments, where per-link channel quality is determined by physical distance and interference, yet existing gossip aggregation protocols are limited in their ability to estimate and correct per-link reception rates online.
I-C Our Approach
We observe that selection bias is a statistical sampling problem where the inbox is a biased sample of the neighborhood because links with lower reception rates appear less frequently. The classical remedy is the Horvitz-Thompson estimator [24], which reweights each observed sample by the inverse of its inclusion probability. DFL-AA instantiates this principle in the gossip aggregation step with local-fill reconstruction for missing chunks: each model update(reconstructed) from neighbor is weighted by , where is an online EWMA estimate of the observed link reception rate, up-weighting under-represented neighbors to restore a statistically unbiased sample of the neighborhood. This is combined with an AoI (Age of Information) [25]-based exponential decay , computed from generation timestamps in received messages without a global clock, to discount temporally stale contributions. The combined weight addresses both failure modes independently and multiplicatively, where a high weight requires both good channel quality and temporal freshness.
I-D Contributions
-
C1
Problem positioning. We provide the first systematic study of the joint effect of selection bias and update staleness in asynchronous DFL over fixed directed graphs in wireless networks, revealing drastic performance degradation of state-of-the-art methods.
- C2
-
C3
DFL-AA algorithm. We introduce DFL-AA (Decentralized Federated Learning with Adaptive AoI-weighted Aggregation), an IPW-corrected, AoI-aware gossip aggregation rule for asynchronous fixed directed graphs, with online EWMA channel estimation requiring no coordination, no global clock, and no additional communication overhead.
-
C4
Unbiasedness guarantee. We prove that DFL-AA removes the coefficient distortion in expectation, weighting each neighbor purely by AoI freshness (Theorem 1).
-
C5
Empirical validation. We evaluate on EMNIST and CIFAR-10 across - and -node fixed directed topologies using discrete-event priority queue simulation, demonstrating consistent improvement over all baselines across loss levels –, with additional validation under heterogeneous per-link channel conditions.
The remainder of the paper is structured as follows. Section II reviews related work and discusses the gaps identified with positioning our work. Section III introduces the system model, including the network model, decentralized learning, and missing value reconstruction. Section IV presents the DFL-AA solution with all formulations. Section V demonstrates the validation of design choices. Section VI presents the performance evaluation, and Section VII concludes the paper and outlines future directions.
II Related Work
We review existing work across four dimensions relevant to DFL-AA and identify the gap that motivates our approach.
| Method | Partial reception. | Staleness | Topology | Decentral. | Async |
| FedAvg [10] | Full only ✗ | ✗ | Star | ✗ | ✗ |
| FedBuff [26] | Full only ✗ | Buffer | Star | ✗ | ✓ |
| D-PSGD [27] | Full only ✗ | ✗ | Undir. | ✓ | ✗ |
| SGP† [28] | Full only ✗ | ✗ | Dir. | ✓ | ✗ |
| AD-PSGD [29] | Full only ✗ | Bounded | Undir. | ✓ | ✓ |
| SWIFT [30] | Full only ✗ | Wait-free | Undir. | ✓ | ✓ |
| Kwon et al. [23] | ✓ | ✗ | Star | ✗ | ✗ |
| AMA [22] | ✓ | Round | Dynamic | ✓ | ✓ |
| Soft-DSGD [21] | ✓ | ✗ | Undir. | ✓ | ✗ |
| DFL-AA (ours) | ✓ | AoI ✓ | Dir. | ✓ | ✓ |
-
Originally a distributed optimization algorithm; included as the canonical directed-graph gossip baseline.
-
•
✓ = fully addressed. ✓ = fully addressed. = async-capable but handles staleness only via an assumption (bounded ) or a coarse mechanism (round counter, buffer), not via continuous decay weighting. ✗ = not addressed. Undir. = undirected topology. Dir. = directed topology.
II-A Decentralized Federated Learning
To overcome the bottlenecks and single point of failure (SPoF) of client-server FL, decentralized federated learning (DFL) has emerged as a scalable and robust alternative [1, 2]. Existing DFL research has explored heterogeneity-aware asynchronous learning that employed a coordinator that predicts the runtime configuration for the next round based on past data and probability distributions [12], adaptive topology and communication optimization [13, 15], asynchronous model synchronization to mitigate stragglers [14], and adaptive neighbor weighting strategies [16]. While these approaches improve efficiency and scalability, they generally assume reliable communication and do not explicitly address partial model reception and update staleness in lossy wireless environments.
II-B Asynchronous and Staleness-Aware FL
Staleness naturally arises when nodes train and communicate at different rates. FedAsync and FedBuff address this in centralized settings by weighting or buffering delayed updates, but staleness is typically defined in round- or iteration-based terms (i.e., how many server/global steps have elapsed since an update was computed) rather than by wall-clock time [31, 26]. AD-PSGD [29] allows fully decentralized asynchronous operation under a bounded-delay assumption. SWIFT [30] removes the bounded-delay requirement, achieving convergence guarantees. FedASMU and BLADE [32, 33] follow similar principles, using dynamic, staleness-aware updates. However, all of these methods assume lossless delivery. They are designed for reliable networks and lack a mechanism to handle incomplete model receptions. However, in lossy wireless communication, model updates may be received only partially, resulting in incomplete information used during aggregation and, consequently, degrading learning performance.
II-C Partial Reception and Communication-Efficient FL
A smaller body of work explicitly addresses the reception of partial models. Soft-DSGD [21] adopts a UDP-based fire-and-forget model and fills missing parameters with local values. AMA [22] uses a similar local-fill strategy with link-quality thresholding. Kwon et al. [23] reconstruct missing parameters via an SVD-based approximation combined with systematic network coding, but report 172% packet overhead and operate in a centralized server setting that is not applicable to peer-to-peer topologies [23]. DFL-AA requires no additional communication overhead beyond the model transmission itself. Crucially, none of these methods corrects the selection bias introduced by partial reception. Furthermore, none of these methods handle staleness as they assume synchronous or near-synchronous operation, which does not hold in genuinely asynchronous wireless deployments.
II-D Wireless and IoT Deployments
The partial reception problem is particularly acute in wireless deployments, where per-link channel quality varies with distance, interference, and node heterogeneity [38]. Wireless FL research has explored vehicular networks [17, 18, 19], UAV systems [20], and mobility-aware optimization [39], but these works focus on scheduling and resource allocation under reliable communication rather than correcting aggregation bias from packet loss.
In IoT and sensor network settings, early work on in-network aggregation [40] established the importance of handling partial data collection in sensor networks to reduce communication overhead. However, this work was designed to reduce aggregation overhead but does not explicitly consider the stochastically received model aggregation. FL for IoT under communication constraints [41, 42] typically assumes reliable delivery or relies on centralized gateway aggregation, neither of which applies to our setting.
II-E Research Gap
Table I summarizes how DFL-AA relates to existing methods. No prior work jointly addresses partial reception and staleness in asynchronous wireless DFL: approaches that handle partial updates typically ignore staleness, while asynchronous methods assume lossless communication. In addition, round-based staleness metrics are poorly suited, where heterogeneous computation and communication delays create irregular round gaps that fail to reflect true model freshness; Age-of-Information (AoI) provides a more appropriate measure in such environments. In contrast, DFL-AA is the only method that jointly corrects selection bias due to lossy links and captures temporal staleness via AoI, operating on directed graphs without requiring synchronized rounds or lossless delivery assumptions, which are properties particularly valuable for IoT and sensor network deployments in a wireless setting where per-link channel quality is heterogeneous, and retransmission is infeasible.
III System Model
III-A Network Model
We consider nodes connected by a fixed directed graph that remains fixed over time. A directed edge indicates that node can transmit to node . Let denote the in-neighborhood of node . In contrast, denote the out-neighborhood. We assume is strongly connected.
Assumption 1 (Strong connectivity).
The directed graph is strongly connected, meaning that for every pair of nodes , there exists a directed path from to .
Remark 1.
We restrict to fixed directed topologies, capturing scenarios where connectivity is preplanned rather than opportunistic, such as industrial IoT sensor meshes with fixed gateway placement, satellite constellations with predictable orbital links, and infrastructure-assisted vehicular networks with roadside units. Extending to fully dynamic topologies is left for future work.
III-B Learning Objective
Each node holds private dataset drawn from local distribution . Each node maintains a local model cooperating to minimize a global objective:
| (1) |
where is the local loss for node over its private data distribution , and is the loss function. We consider the non-IID setting , modeled by Dirichlet- label partitioning.
III-C Communication Model
We adopt a fire-and-forget UDP-like communication model. Each node serializes its model into fixed-size chunks, each containing parameters. Chunk on link is received independently with probability .
Definition 1 (Bernoulli chunk loss).
Let independently for each chunk . The parameter-level reception mask is defined as:
| (2) |
where denotes the chunk index to which parameter belongs.
Definition 2 (Completeness).
The observed completeness of a transmission from to is , with .
Assumption 2 (Homogeneous chunk loss).
The Bernoulli loss probability is identical across all chunks on a given link : for all . Every chunk on the same link experiences the same loss probability.
Local-fill reconstruction completes the received vector via element-wise multiplication:
| (3) |
where denotes elementwise multiplication, is the reception mask from Definition 1, and is the partially received model with arbitrary values at unobserved positions. Received parameters () retain their transmitted values; missing parameters () are substituted with the receiver’s own values .
III-D Asynchronous Operation
Nodes operate without a global synchronization barrier. Each node maintains:
-
•
Local model .
-
•
Inbox storing the most recent from each in-neighbor, where is generation timestamp. Older entries are overwritten on the new reception.
-
•
EWMA estimate for each in-neighbor, updated on each reception.
Age of Information. Each transmission carries a generation timestamp in the simulation’s virtual time. Node computes the AoI reference as the most recent timestamp in its inbox, thereby no global clock is required:
| (4) |
IV The DFL-AA Algorithm
IV-A Design Rationale
DFL-AA addresses two independent failure modes with two independent components:
Spatial: IPW corrects selection bias. Under partial reception, low-quality links (low ) contribute fewer messages, leading to systematic under-representation. This creates selection bias, where the received models are not a uniform sample of neighbors. DFL-AA uses the Horvitz–Thompson [24] correction by weighting each received update with , so weaker links are up-weighted to compensate for their lower visibility.
Temporal: AoI decay discounts staleness. DFL-AA addresses the staleness issue by applying an exponential decay , reducing the influence of outdated updates relative to fresh ones. This operates independently of IPW, where the first corrects spatial sampling bias, while the second accounts for temporal staleness.
Table II summarizes the notation used throughout Algorithm 1, which presents DFL-AA at a single node , and Figure 3 illustrates the overall process of the proposed method.
| Symbol | Description |
| Local model at round | |
| Model after local training, before aggregation | |
| Inbox: most recent transmission per in-neighbor | |
| Inbox entries with | |
| True complete model at node | |
| Partially received model from neighbor | |
| Local-fill reconstructed model from | |
| Observed completeness of transmission from | |
| EWMA estimate of reception rate on link | |
| Generation timestamp of ’s transmission | |
| Reference time: | |
| Age-of-Information of ’s update at round | |
| Combined IPW AoI weight for neighbor |
IV-B EWMA Channel Estimation
Since the true reception rate is unknown a priori and may vary with distance and interference, DFL-AA estimates it online via EWMA:
| (5) |
where is the observed completeness of the most recent transmission from and is the EWMA forgetting factor. The estimate is initialized to the first observed and floored at to prevent from becoming numerically degenerate: .
IV-C Aggregation Rule
The aggregation step at node is a normalized weighted average:
| (6) |
where excludes transmissions below the minimum completeness threshold and is local-fill reconstructed model parameters according to Equation (3) and with as hyperparameter for decay.
Remark 2 (Necessity of local-fill reconstruction).
Local-fill reconstruction (3) is a prerequisite for the IPW correction rather than an independent design choice. IPW reweights each neighbor’s contribution by to correct for the underrepresentation of poor-quality links across rounds. However, this correction requires a complete, fixed-length parameter vector for aggregation. Without reconstruction, partially received models have variable support across coordinates, making a normalized weighted average undefined. Local-fill provides this fixed-length input at negligible cost: it requires no additional communication, no coordination with the sender, and only a single element-wise operation over parameters (Eq. (3)), which is dominated by the local SGD computation by several orders of magnitude and comparably low computation than other existing methods [23], which uses SVD-based reconstruction from systematic network coding. Local-fill is therefore both necessary for IPW to operate and provably safe under the DFL-AA aggregation rule.

V Design Validation
We prove that the two components of DFL-AA’s weight formula (6) are each necessary, and that natural alternatives are provably incorrect. Throughout, denotes the true per-chunk reception probability on link from Definition 1, and expectations are taken over chunk loss randomness.
V-A Failure Mode 1: Selection Bias
Lemma 1 (Expected local-fill reconstruction).
Under Bernoulli chunk loss and local-fill reconstruction (3), the expected reconstructed model at each parameter is:
| (7) |
Proof:
From Definition 1, parameter belongs to chunk , and where . From the local-fill equation (3), takes one of two values depending on whether chunk was received:
| (8) |
Note that when , the received value equals the true value since the chunk arrived intact. Taking expectation by conditioning on the two cases:
| (9) |
where and are deterministic given the current model states and are therefore constant with respect to the Bernoulli reception process . We used (Assumption 2). ∎
Proposition 1 (Selection bias of uniform gossip).
Under Bernoulli chunk loss, the expected uniform gossip aggregate:
| (10) |
satisfies:
| (11) |
where is the full-reception aggregate. The bias is irreducible under non-IID data and grows with both the loss rate and the model disagreement .
Proof:
Applying Lemma 1 coordinate-wise and taking the expectation of the uniform aggregate:
| (12) |
| (13) |
The bias vanishes only if for all (lossless links). Under partial reception with , the expected aggregate under-weights each neighbor . Under non-IID data, throughout training, so the bias is irreducible due to poor link quality. ∎
Remark 3 (Bias as coefficient distortion).
The term in Proposition 1 is the standard gossip update direction and is not itself the bias. The bias arises because local filling scales this direction by rather than its ideal coefficient. As a result, low-quality links are systematically under-represented in the aggregate. DFL-AA corrects this distortion through IPW (18), making the numerator weight of each neighbor proportional to , independent of .
V-B Failure Mode 2: Push-Sum Weight Drain
Push-sum [28] is the canonical method for gossip-based SGD on directed graphs and is the algorithmic family closest to DFL-AA’s setting. However, we show that it is fundamentally incompatible with chunk-level packet loss, making it unsuitable for directed DFL under lossy communication.
Proposition 2 (Push-sum weight drain).
In standard push-sum under Bernoulli chunk loss, where the weight variable is credited regardless of actual chunk reception, the total weight mass decays geometrically:
| (14) |
As , for all , causing the model estimate to become numerically degenerate.
Proof:
Summing the expected total weight held by all nodes after one round:
| (15) |
where is the mean reception rate across all directed edges. The inequality holds because by definition of . Let:
| (16) |
since implies the numerator is strictly less than the denominator, we obtain:
| (17) |
which gives by induction. As , for all , causing the model estimate to become numerically degenerate. ∎
DFL-AA avoids push-sum entirely. The self-normalized denominator in Eq. (6) is recomputed each round using only locally available information, without maintaining auxiliary weight variables. This enables operation on directed graphs under lossy links, where push-sum-based methods such as SGP [28] fail.
V-C Why IPW Corrects Selection Bias
Theorem 1 (Unbiasedness of DFL-AA aggregation).
Suppose exactly for all . Then the expected DFL-AA aggregate satisfies:
| (18) |
where . The coefficient distortion of Proposition 1 is exactly eliminated: each neighbor’s update direction is weighted purely by AoI freshness , with no residual dependence on link quality in the numerator.
Remark 4 ( only affects normalization).
Although appears in the denominator , it does not reintroduce the bias of Proposition 1. The bias originates from distorted coefficients on the update directions . In Theorem 1, these coefficients depend only on and are independent of . The denominator serves only as a normalization factor that adjusts the update magnitude.
Proof:
The expected denominator is:
| (21) |
Remark 5 (Finite EWMA residual).
When , the bias cancellation is approximate, leaving a residual of order . Both factors shrink during training as the EWMA converges geometrically to and the models approach consensus, so the residual vanishes asymptotically.
V-D Why Multiplicative Combination
The IPW and AoI factors must be combined multiplicatively rather than additively. An additive combination would allow a very fresh but structurally under-represented neighbor to receive an inflated weight regardless of link quality, or vice versa. The multiplicative form enforces a both-must-be-good criterion: a neighbor receives high weight only if it is both well-represented across rounds (low correction needed) and temporally fresh (low AoI).
VI Performance Evaluation
| FedAvg | SWIFT | AD-PSGD | Soft-DSGD | DFL-AA (Ours) | ||||||||||||
| Dataset | Loss | Acc | Loss | AUC | Acc | Loss | AUC | Acc | Loss | AUC | Acc | Loss | AUC | Acc | Loss | AUC |
| EMNIST | 10% | 29.74 | 7.96 | 27260 | 72.03 | 0.90 | 62289 | 70.20 | 0.95 | 58507 | 51.72 | 3.71 | 45203 | 74.86 | 0.81 | 66194 |
| 20% | 29.74 | 7.96 | 27260 | 71.17 | 0.93 | 61254 | 69.68 | 0.97 | 58199 | 51.44 | 3.72 | 44907 | 74.53 | 0.82 | 65632 | |
| 30% | 29.74 | 7.96 | 27260 | 70.43 | 0.95 | 59994 | 69.14 | 0.99 | 57521 | 51.02 | 3.74 | 44363 | 74.14 | 0.84 | 64841 | |
| 50% | 29.74 | 7.96 | 27260 | 67.28 | 1.06 | 56378 | 66.88 | 1.08 | 54784 | 50.37 | 3.76 | 43092 | 73.19 | 0.87 | 62868 | |
| CIFAR-10 | 10% | 26.93 | 5.74 | 104641 | 41.71 | 2.27 | 149772 | 38.94 | 2.60 | 144799 | 37.39 | 3.63 | 143724 | 50.47 | 1.62 | 185392 |
| 20% | 26.24 | 6.00 | 104511 | 40.08 | 2.40 | 145664 | 37.99 | 2.65 | 144258 | 36.35 | 3.75 | 142892 | 50.35 | 1.59 | 183707 | |
| 30% | 26.44 | 5.97 | 104442 | 39.41 | 2.43 | 140693 | 39.03 | 2.46 | 142942 | 37.78 | 3.58 | 143168 | 50.24 | 1.58 | 182608 | |
| 50% | 26.71 | 5.94 | 104162 | 37.21 | 2.62 | 132485 | 39.54 | 2.46 | 136200 | 38.62 | 3.65 | 140288 | 49.39 | 1.56 | 178080 | |



| FedAvg | SWIFT | AD-PSGD | Soft-DSGD | DFL-AA (Ours) | ||||||||||||
| Dataset | Topology | Acc | Loss | AUC | Acc | Loss | AUC | Acc | Loss | AUC | Acc | Loss | AUC | Acc | Loss | AUC |
| EMNIST | (1) | 29.74 | 7.96 | 27260 | 68.50 | 1.03 | 57866 | 68.57 | 1.02 | 57682 | 29.79 | 7.98 | 27234 | 68.24 | 1.04 | 57863 |
| (2) | 29.74 | 7.96 | 27260 | 74.36 | 0.80 | 64725 | 72.64 | 0.86 | 60577 | 81.49 | 0.59 | 72811 | 81.59 | 0.58 | 73288 | |
| (3) | 29.74 | 7.96 | 27260 | 72.03 | 0.90 | 62289 | 70.20 | 0.95 | 58507 | 51.72 | 3.71 | 45203 | 74.86 | 0.81 | 66194 | |
| CIFAR-10 | (1) | 26.57 | 5.94 | 104257 | 41.40 | 2.27 | 144226 | 40.96 | 2.27 | 145076 | 27.08 | 5.63 | 104476 | 41.58 | 2.29 | 149041 |
| (2) | 26.71 | 5.99 | 104327 | 41.18 | 2.79 | 148995 | 37.68 | 2.31 | 142850 | 62.82 | 1.07 | 235581 | 63.59 | 1.04 | 234981 | |
| (3) | 26.93 | 5.74 | 104641 | 41.71 | 2.27 | 149772 | 38.94 | 2.60 | 144799 | 37.39 | 3.63 | 143724 | 50.47 | 1.62 | 185392 | |
-
•
(1) Ring topology, where each node communicates with two neighbors in a circular structure. (2) Fully connected topology, where each node communicates with all other nodes. (3) Erdős-R’enyi random graph with average degree 4.
| Method | Value | Accuracy(%) | Loss | AUC |
| DFL-AA | 01 | 74.02 | 0.84 | 66229 |
| DFL-AA | 02 | 74.52 | 0.82 | 66265 |
| DFL-AA | 03 | 74.77 | 0.81 | 66252 |
| DFL-AA | 05 | 74.86 | 0.81 | 66194 |
| DFL-AA | 10 | 74.89 | 0.81 | 66090 |
| DFL-AA | 15 | 74.87 | 0.81 | 66104 |
| DFL-AA | 20 | 74.74 | 0.82 | 66114 |
| Mean AoI | Max AoI | Accuracy(%) | Loss | Cons. Dist. | AUC |
| 1.09 | 2.0 | 74.86 | 0.81 | 0.05 | 66194 |
| 1.38 | 3.5 | 73.79 | 0.84 | 0.05 | 63621 |
| 1.96 | 5.0 | 73.05 | 0.87 | 0.06 | 62208 |

Simulator
All experiments are conducted in a custom discrete-event simulator built on a priority-queue event engine. The system schedules local training completion, chunk transmission, inbox updates, and aggregation as timestamped events that are processed in causal order. We use virtual time as the x-axis for all training curves since the round number is not meaningful under asynchronous execution. Bandwidth is set to be largely sufficient for the simulator, as it constrains communication, leading to chunk loss under congestion, which is the same failure mode DFL-AA is designed to correct. All experiments are conducted on a virtual machine equipped with an L40s-16c GPU (24 GB vRAM), 16 vCPUs, and 118 GB RAM.
Datasets and Models
We evaluate on two standard FL benchmarks using a non-IID Dirichlet () partitioning scheme, which represents strong label heterogeneity for our main experiments.
-
•
EMNIST [43]: grayscale handwritten characters with 47 classes. Model: two-layer MLP with hidden dimensions 256–256, LayerNorm after each layer, ReLU activations, and dropout (0.1). Optimizer: Adam, learning rate .
-
•
CIFAR-10 [44]: RGB images with 10 classes. Model: CNN with three stages of standard convolutions (64–128–128 channels), BatchNorm, ReLU, a single residual skip at the widest stage, and a 256-unit FC head with dropout (0.2). Optimizer: SGD with momentum , learning rate , weight decay .
Training Configuration
We set local epochs , batch size 64, EWMA factor , , , and and packet size 1400 bytes following standard MTU constraints [45], which determines the number of chunks where is the model dimension and is the byte size per parameter, which is set as 4. The AoI decay constant is set to , and the sensitivity analysis is provided in Table V.
Topology and Loss Levels
We use random fixed directed Erdős-R’enyi graphs with average degree of 4. We evaluate on nodes. Chunk loss is applied homogeneously across links with rates . We also test the topology’s robustness to ring and fully connected structures at a representative loss level and evaluate its robustness under heterogeneous per-link loss levels.
Baselines
We compare against FedAvg [10] (decentralized variant which drops partial updates), Soft-DSGD [21] (local-fill reconstruction and gossip weighting), AD-PSGD [29] (asynchronous decentralized SGD assuming full delivery), and SWIFT [30] (wait-free asynchronous DFL under reliable delivery assumptions). All baselines are implemented in the simulator under identical topology, loss, and data partitioning settings. Each asynchronous method (AD-PSGD and SWIFT) is adapted with local-fill reconstruction for a fair comparison, since these methods were not originally designed to handle packet loss.
VI-A Main Results
Table III reports test accuracy, loss, and AUC for all methods with nodes across all loss levels under a heterogeneous data distribution among nodes (Dirichlet ). DFL-AA achieves the highest accuracy in every configuration across both datasets. As loss increases, the advantage of DFL-AA grows monotonically, reaching 73.19% on EMNIST and 49.39% on CIFAR-10 at , outperforming the next-best method (SWIFT) by 5.91 pp and 12.18 pp respectively. This monotonic widening directly validates Proposition 1, the coefficient distortion grows with loss rate, and DFL-AA’s IPW correction becomes proportionally more valuable as the channel degrades.
Among the baselines, AD-PSGD and SWIFT perform second-best despite assuming full delivery, because we augment them with local-fill reconstruction to ensure a fair comparison. Soft-DSGD, the method designed for partial reception, underperforms on both EMNIST and CIFAR-10, validating that local-fill reconstruction alone cannot be robust in asynchronous environments. Strikingly, FedAvg, which simply drops partial updates, stays as a lower bound, limiting itself to training the local model due to its architectural design.
DFL-AA emerges as the best solution across different channel loss levels on every metric, including accuracy, loss, and AUC, thereby validating our unbiasedness Theorem 1 for DFL-AA aggregation over asynchronous lossy channels.
VI-B Impact of Packet Loss Rate
Figure 4 and 5 show accuracy and consensus distance over virtual time at loss levels 10–50% for both datasets. Three observations are consistent across all configurations.
First, DFL-AA converges faster and achieves higher accuracy than all baselines across all loss levels, and remains stable at higher loss rates. The convergence speed advantage is most pronounced under a high loss rate (at ) on EMNIST; DFL-AA reaches 70% accuracy, while all other baselines fail to reach that level at that loss level. FedAvg remains below 30% throughout the 1000 s runtime due to its local-only training as described in the main results section. Furthermore, the visible gap between all the baselines and DFL-AA widens on both datasets as channel loss increases , again validating Proposition 1. The reduction in accuracy, along with an increase in channel loss, is minimal in DFL-AA compared to the best baseline. As loss increases from 10% to 50%, DFL-AA degrades by only 1.67 pp on EMNIST and 1.08 pp on CIFAR-10, while the next-best method SWIFT degrades by 4.75 pp and 4.5 pp, respectively. A relative degradation 2.84 and 4.17 larger than DFL-AA on EMNIST and CIFAR-10, respectively, confirming that IPW correction becomes proportionally more effective as channel quality worsens.
Second, Soft-DSGD exhibits a degradation pattern due to its inability to operate in asynchronous environments, despite being designed to handle partial model reception. This confirms that the local-fill reconstruction alone is insufficient in asynchronous wireless systems.
Third, Figure 5 shows that DFL-AA achieves strictly lower consensus distance than all baselines across all loss levels and both datasets. This confirms that DFL-AA not only improves individual node accuracy but also drives the network toward tighter model agreement, a property that follows from eliminating the directional distortion in Proposition 1, which would otherwise push different nodes’ aggregates in systematically different directions depending on their local link quality profiles.
VI-C Scalability Analysis
Figure 6 shows accuracy and consensus distance for nodes at fixed link loss. DFL-AA maintains its advantage across all node counts on both datasets. As increases, absolute accuracy decreases slightly across all methods due to sparser effective neighborhoods at a fixed average degree of 4 with fewer data samples, but DFL-AA’s relative advantage is preserved. Consensus distance for DFL-AA remains consistently below all baselines across all scales, confirming that the IPW correction scales correctly with network size and that DFL-AA is robust to scalability.
Notably, FedAvg’s accuracy collapses at 40 and 80 nodes on both datasets, because it limits its training on a local model as it drops partial receptions ( loss), and due to increasing node counts, local data belonging to each node is limited, and it pushes the model to produce low accuracy proportional to node count on a test dataset. There is another notable performance degradation for Soft-DSGD as the node count increases, whereas AD-PSGD, SWIFT, and DFL-AA remain stable. This might be due to extreme heterogeneity and limited local data at each node, as well as directional bias introduced by local filling and averaging, which Soft-DSGD is designed to mitigate.
VI-D Topology Robustness
Table IV reports performance across three topologies at link loss for ring, fully connected, and Erdős-R’enyi random directed graph with average degree 4.
DFL-AA maintains competitive performance across all topologies. On the fully connected graph, Soft-DSGD achieves the second-highest accuracy on both datasets, only being defeated by DFL-AA. The gap is tiny, and it validates the Soft-DSGD design, as the authors demonstrate its robustness on a fully connected topology.
In the ring topology, all methods suffer significant accuracy degradation due to poor network connectivity, where each node has only two neighbors, thereby limiting information flow. DFL-AA maintains parity with SWIFT and AD-PSGD on this topology, confirming that the IPW correction is topology-agnostic, operating on per-link reception statistics available locally and not depending on global topology knowledge. Furthermore, our direct competitor, Soft-DSGD, performs well only in a fully connected regime, which its authors tested; we demonstrate its degradation under low information flow (random neighbors and ring topologies), while DFL-AA maintains stability across topologies, demonstrating its robustness.
VI-E Heterogeneity Level Analysis
Figure 8 illustrates the performance of each method on the CIFAR-10 dataset under link loss at two levels of heterogeneity ( and ). As increases, the heterogeneity of the data distribution decreases, helping each node achieve higher accuracy than at lower values in the same configuration. Figure 8 clearly shows that the gap between DFL-AA and other baselines decreases with higher values (lower data heterogeneity), but DFL-AA still manages to outperform other baselines by a clear margin, validating IPW-correctness under lossy channels along with staleness decay. However, the consensus distance between DFL-AA and the other best baselines (AD-PSGD and SWIFT) is not clearly visible at low levels of heterogeneity. These experimental results emphasize the importance of DFL-AA in wireless lossy network systems, where participating nodes mostly have heterogeneous data and operate asynchronously, and DFL-AA performs extremely well.
VI-F Hyperparameter Sensitivity
Table V reports DFL-AA accuracy on EMNIST under 10% loss for seven values of the AoI decay constant . Accuracy is stable across the range , with the peak at (74.89%). A very small slightly overpenalizes stale updates, reducing accuracy by 0.87 pp relative to the peak. A very large also degrades accuracy as the AoI weight approaches uniformity. The mean AoI in this experiment is 1.09 s with a maximum of 2.0 s, and the stable range is , suggesting a practical tuning rule that sets to 3–10 the expected mean AoI in the deployment.
Table VI shows DFL-AA accuracy across three staleness levels (mean AoI: 1.09, 1.38, 1.96 s) with fixed . Accuracy degrades gracefully as staleness increases. A 0.87 s increase in mean AoI reduces accuracy by only 1.81 pp, confirming that the AoI decay term effectively discounts stale updates and maintains robust performance under increased asynchrony.
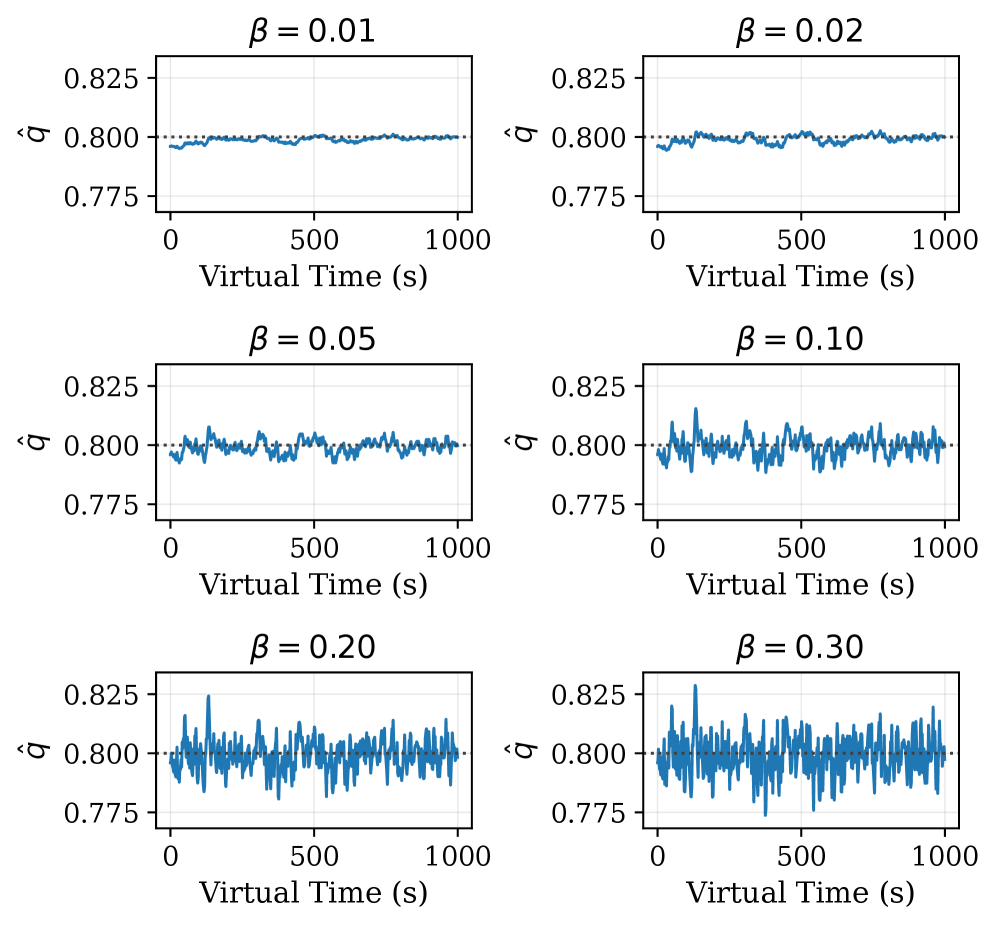
Figure 7 shows over virtual time for a tracked link with a true reception rate of , using a shared y-axis to make the asymptotic variance directly comparable across panels. All six values of yield estimates centered on the true rate throughout training, confirming that the online channel-estimation assumption underlying Theorem 1 holds in practice. The figure reveals a clear bias-variance trade-off, where yields an almost flat estimate with minimal variance, whereas converges at the same rate but exhibits roughly wider oscillations around the true value. The default maintains a tight, stable estimate. The residual bias from Remark 5 is therefore negligible throughout training for all reasonable values.
VII Conclusions and Future Work
We presented DFL-AA, an asynchronous gossip aggregation algorithm for decentralized federated learning over fixed directed graphs, with chunk-level Bernoulli packet loss over fixed directed wireless links. DFL-AA addresses two key failure modes not handled by classical gossip methods: selection bias, where low-quality links are under-represented in the inbox, and update staleness, where asynchronous nodes contribute models with varying temporal freshness. The IPW correction with online EWMA channel estimation removes the coefficient distortion in expectation, while the AoI decay discounts stale updates without requiring a global clock. Experiments on EMNIST and CIFAR-10 over 20-, 40-, and 80-node directed topologies show consistent gains over all baselines across loss rates from to , with larger improvements under higher loss and stronger heterogeneity. Additional experiments under heterogeneous per-link channel conditions, varying data heterogeneity levels, and ResNet-18 confirm that DFL-AA generalizes beyond the homogeneous evaluation setting and remains effective regardless of channel distribution, data heterogeneity, or model architecture. Finally, EWMA tracking experiments confirm that converges to the true reception rate under reasonable forgetting factors.
Despite these results, DFL-AA relies on several assumptions that motivate future work. First, the chunk loss model studied in this work does not capture burst losses due to correlated fading, and extending IPW to temporally correlated links remains an open problem. Second, the method assumes unlimited bandwidth, and incorporating bandwidth constraints into chunk sizing and IPW design would improve practicality. Third, aggregation is performed over full model vectors; extending it to parameter-level updates without reconstruction could reduce residual bias under finite EWMA accuracy. Finally, extending DFL-AA to Byzantine and heterogeneous model settings and deriving convergence proofs under synchronous learning remain important directions for future work.
Acknowledgments
This work is supported by the Australian Research Council (ARC) grants: Discovery Project (DP240102088) and Linkage Infrastructure, Equipment and Facilities (LE200100049).
References
- [1] L. Yuan, Z. Wang, L. Sun, P. S. Yu, and C. G. Brinton, “Decentralized federated learning: A survey and perspective,” IEEE Internet of Things Journal, vol. 11, no. 21, pp. 34 617–34 638, 2024.
- [2] C. Medjadji, G. Leduc, S. Kubler, and Y. L. Traon, “Centralized vs decentralized federated learning: A trade-off performance analysis,” in 2024 11th International Conference on Future Internet of Things and Cloud (FiCloud), 2024, pp. 69–76.
- [3] P. M. Mammen, “Federated learning: Opportunities and challenges,” arXiv preprint arXiv:2101.05428, 2021.
- [4] D. Li and J. Wang, “Fedmd: Heterogenous federated learning via model distillation,” CoRR, vol. abs/1910.03581, 2019.
- [5] T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V. Smith, “Federated optimization in heterogeneous networks,” in Proceedings of Machine Learning and Systems, I. Dhillon, D. Papailiopoulos, and V. Sze, Eds., vol. 2, 2020, pp. 429–450.
- [6] C. Lao, Y. Le, K. Mahajan, Y. Chen, W. Wu, A. Akella, and M. Swift, “ATP: In-network aggregation for multi-tenant learning,” in 18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21). USENIX Association, Apr. 2021, pp. 741–761.
- [7] A. Dhamija, B. Madhavan, H. Li, J. Meng, S. Khare, M. Rao, L. Brakmo, N. Spring, P. Kannan, S. Sundaresan, and S. Ghorbani, “A large-scale deployment of DCTCP,” in 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). Santa Clara, CA: USENIX Association, Apr. 2024, pp. 239–252.
- [8] K. A. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V. Ivanov, C. M. Kiddon, J. Konečný, S. Mazzocchi, B. McMahan, T. V. Overveldt, D. Petrou, D. Ramage, and J. Roselander, “Towards federated learning at scale: System design,” in SysML 2019, 2019, to appear.
- [9] R. Gao, P. Tammana, S. Gandhi, M. Calder, and E. Katz-Bassett, “Impact of tcp loss on regional application performance,” Microsoft, Tech. Rep. MSR-TR-2019-19, July 2019.
- [10] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, A. Singh and J. Zhu, Eds., vol. 54. PMLR, 20–22 Apr 2017, pp. 1273–1282.
- [11] D. J. Beutel, T. Topal, A. Mathur, X. Qiu, T. Parcollet, and N. D. Lane, “Flower: A friendly federated learning research framework,” CoRR, vol. abs/2007.14390, 2020.
- [12] J. Cao, Z. Lian, W. Liu, Z. Zhu, and C. Ji, HADFL: Heterogeneity-Aware Decentralized Federated Learning Framework. IEEE Press, 2022, p. 1–6.
- [13] Y. Liao, Y. Xu, H. Xu, L. Wang, and C. Qian, “Adaptive configuration for heterogeneous participants in decentralized federated learning,” in IEEE INFOCOM 2023 - IEEE Conference on Computer Communications, 2023, pp. 1–10.
- [14] Z. Chen, J. Pan, and S. Zhang, “Asynchronous federated learning in decentralized topology based on dynamic average consensus,” in ICC 2022 - IEEE International Conference on Communications, 2022, pp. 2822–2827.
- [15] D. Menegatti, A. Giuseppi, C. Poli, and A. Pietrabissa, “Dynamic topology optimization for efficient and decentralised federated learning,” in 2024 IEEE International Conference on Big Data (BigData), 2024, pp. 7939–7945.
- [16] M. R. Behera and S. Chakraborty, “pfedgame - decentralized federated learning using game theory in dynamic topology,” in 2024 16th International Conference on COMmunication Systems and; NETworkS (COMSNETS). IEEE, Jan. 2024, p. 651–655.
- [17] D. Chen, T. Deng, H. Huang, J. Jia, M. Dong, D. Yuan, and K. Li, “Mobility-aware multi-task decentralized federated learning for vehicular networks: Modeling, analysis, and optimization,” IEEE Transactions on Mobile Computing, vol. 25, no. 2, pp. 2594–2610, 2026.
- [18] B. Xie, Y. Sun, S. Zhou, Z. Niu, Y. Xu, J. Chen, and D. Gunduz, “Mob-fl: Mobility-aware federated learning for intelligent connected vehicles,” in ICC 2023 - IEEE International Conference on Communications, 2023, pp. 3951–3957.
- [19] P. Singh, B. Hazarika, K. Singh, C. Pan, W.-J. Huang, and C.-P. Li, “Drl-based federated learning for efficient vehicular caching management,” IEEE Internet of Things Journal, 06 2024.
- [20] N. Baganal-Krishna, R. Lübben, E. Liotou, K. V. Katsaros, and A. Rizk, “A federated learning approach to qos forecasting in cellular vehicular communications: Approaches and empirical evidence,” Comput. Netw., vol. 242, no. C, Apr. 2024.
- [21] H. Ye, L. Liang, and G. Y. Li, “Decentralized federated learning with unreliable communications,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 3, pp. 487–500, 2022.
- [22] M. Movahedian, M. Dolati, and M. Ghaderi, “Adaptive model aggregation for decentralized federated learning in vehicular networks,” in 2023 19th International Conference on Network and Service Management (CNSM), 2023, pp. 1–9.
- [23] J. Kwon and H. Park, “Efficient and resilient packet recovery for federated learning via approximation,” IEEE Transactions on Mobile Computing, vol. 25, no. 5, pp. 6413–6428, 2026.
- [24] D. G. Horvitz and D. J. Thompson, “A generalization of sampling without replacement from a finite universe,” Journal of the American Statistical Association, vol. 47, no. 260, pp. 663–685, 1952.
- [25] İ. Kahraman, A. Köse, M. Koca, and E. Anarim, “Age of information in internet of things: A survey,” IEEE Internet of Things Journal, vol. 11, no. 6, pp. 9896–9914, 2024.
- [26] J. Nguyen, K. Malik, H. Zhan, A. Yousefpour, M. Rabbat, M. Malek, and D. Huba, “Federated learning with buffered asynchronous aggregation,” in International conference on artificial intelligence and statistics. PMLR, 2022, pp. 3581–3607.
- [27] X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu, “Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17. Red Hook, NY, USA: Curran Associates Inc., 2017, p. 5336–5346.
- [28] M. Assran, N. Loizou, N. Ballas, and M. Rabbat, “Stochastic gradient push for distributed deep learning,” in Proceedings of the 36th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, K. Chaudhuri and R. Salakhutdinov, Eds., vol. 97. PMLR, 09–15 Jun 2019, pp. 344–353.
- [29] X. Lian, W. Zhang, C. Zhang, and J. Liu, “Asynchronous decentralized parallel stochastic gradient descent,” in Proceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 3043–3052.
- [30] M. Bornstein, T. Rabbani, E. Z. Wang, A. Bedi, and F. Huang, “SWIFT: Rapid decentralized federated learning via wait-free model communication,” in Proceedings of the 11th International Conference on Learning Representations, 2023.
- [31] C. Xie, S. Koyejo, and I. Gupta, “Asynchronous federated optimization,” arXiv preprint arXiv:1903.03934, 2019.
- [32] J. Liu, J. Jia, T. Che, C. Huo, J. Ren, Y. Zhou, H. Dai, and D. Dou, “Fedasmu: efficient asynchronous federated learning with dynamic staleness-aware model update,” in Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence, ser. AAAI’24/IAAI’24/EAAI’24. AAAI Press, 2024.
- [33] C. Ying, B. Li, and B. Li, “Blade: Pushing the performance envelope of asynchronous federated learning,” in 2024 IEEE/ACM 32nd International Symposium on Quality of Service (IWQoS), 2024, pp. 1–6.
- [34] P. M. S. Sánchez, E. T. M. Beltrán, M. F. Llamas, G. Bovet, G. M. Pérez, and A. H. Celdrán, “Profe: Communication-efficient decentralized federated learning via distillation and prototypes,” 2024.
- [35] B. Li, W. Gao, J. Xie, M. Gong, L. Wang, and H. Li, “Prototype-based decentralized federated learning for the heterogeneous time-varying iot systems,” IEEE Internet of Things Journal, vol. 11, no. 4, pp. 6916–6927, 2024.
- [36] J. Liu, T. Che, Y. Zhou, R. Jin, H. Dai, and P. Valduriez, “AEDFL: Efficient Asynchronous Decentralized Federated Learning with Heterogeneous Devices,” in SDM 2024 - SIAM International Conference on Data Mining, Society for Industrial and Applied Mathematics. Houston, TX, United States: Society for Industrial and Applied Mathematics, Apr. 2024, pp. 833–841.
- [37] X. Liang, J. Tang, and T. Q. S. Quek, “Large-scale decentralized asynchronous federated edge learning with device heterogeneity,” in ICC 2024 - IEEE International Conference on Communications, 2024, pp. 4566–4571.
- [38] A. Imteaj, U. Thakker, S. Wang, J. Li, and M. H. Amini, “A survey on federated learning for resource-constrained iot devices,” IEEE Internet of Things Journal, vol. 9, no. 1, pp. 1–24, 2022.
- [39] D. Chen, T. Deng, J. Jia, S. Feng, and D. Yuan, “Mobility-aware decentralized federated learning with joint optimization of local iteration and leader selection for vehicular networks,” Comput. Netw., vol. 263, no. C, May 2025.
- [40] S. Madden, M. J. Franklin, J. M. Hellerstein, and W. Hong, “TAG: A tiny AGgregation service for Ad-Hoc sensor networks,” in 5th Symposium on Operating Systems Design and Implementation (OSDI 02). Boston, MA: USENIX Association, Dec. 2002.
- [41] J. Park, S. Samarakoon, A. Elgabli, J. Kim, M. Bennis, S.-L. Kim, and M. Debbah, “Communication-efficient and distributed learning over wireless networks: Principles and applications,” Proceedings of the IEEE, vol. 109, no. 5, pp. 796–819, 2021.
- [42] M. S. H. Abad, E. Ozfatura, D. GUndUz, and O. Ercetin, “Hierarchical federated learning across heterogeneous cellular networks,” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 8866–8870.
- [43] G. Cohen, S. Afshar, J. Tapson, and A. van Schaik, “EMNIST: an extension of MNIST to handwritten letters,” CoRR, vol. abs/1702.05373, 2017.
- [44] A. Krizhevsky, “Learning multiple layers of features from tiny images,” 2009.
- [45] H. Harkous, M. Jarschel, M. He, R. Pries, and W. Kellerer, “P8: P4 with predictable packet processing performance,” IEEE Transactions on Network and Service Management, vol. 18, no. 3, pp. 2846–2859, 2021.