1307\vgtccategoryResearch\vgtcinsertpkg\preprinttext\teaser![[Uncaptioned image]](2606.12849v1/x1.png) SemanticXR overview. SemanticXR enables real-time, open-vocabulary semantic mapping for low-power XR through a device-cloud architecture organized around objects as first-class units of communication, execution, and memory footprint. Object-level innovations (green) speed-up server-side mapping (Section 2.1), reduce upstream bandwidth (Section 2.3); on the device, a sparse local map with incremental updates and update prioritization enables network-robust querying (Section 2.2).
Organizing every operation at object granularity allows both applications and the system to trade off resource usage against semantic quality, suiting application requirements and operating conditions respectively, without modifying the perception and mapping pipeline (Section 2.4).
SemanticXR overview. SemanticXR enables real-time, open-vocabulary semantic mapping for low-power XR through a device-cloud architecture organized around objects as first-class units of communication, execution, and memory footprint. Object-level innovations (green) speed-up server-side mapping (Section 2.1), reduce upstream bandwidth (Section 2.3); on the device, a sparse local map with incremental updates and update prioritization enables network-robust querying (Section 2.2).
Organizing every operation at object granularity allows both applications and the system to trade off resource usage against semantic quality, suiting application requirements and operating conditions respectively, without modifying the perception and mapping pipeline (Section 2.4).
SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture
Abstract
Semantic mapping is a core service that enables grounded interactions in emerging Extended Reality (XR) applications such as AI assistants and spatial object search. Deploying this capability on mobile XR devices requires a system that is open-vocabulary, real-time, and low-power. Existing approaches are compute-intensive and assume server-class resources. Cloud offloading offers a practical path, but no existing system splits semantic mapping between the device and the cloud, and current approaches do not address how to manage communication, execution, and memory footprint across the device-cloud boundary.
We present SemanticXR, the first device-cloud system for real-time, open-vocabulary semantic mapping and querying under XR power, bandwidth, and memory constraints. Our key insight is to elevate semantically identifiable objects to first-class units of system design, governing how the system communicates, executes, and manages memory across the device and the server. On the server, object-level parallelism and geometry downsampling improve mapping latency, while object-level depth-mapping co-design reduces upstream bandwidth. On the device, an object-level sparse local map with incremental updates and update prioritization enables network-robust querying with bounded memory and downstream bandwidth. Object-level configurable resource usage vs. quality trade-offs allow both applications and the system to adapt semantic mapping behavior to application requirements and operating conditions respectively.
Evaluation against a device-cloud baseline using the same perception models shows that object-level system organization improves server-side mapping latency by 2.2 at equivalent semantic quality. Object-level depth-mapping co-design maintains upstream bandwidth under 2.5 Mbps. On the device, SemanticXR sustains sub-100 ms query latency for up to 10,000 objects even under network drops, supports tens of thousands of objects within 500 MB memory footprint, and scales downstream bandwidth with map changes rather than total scene size. The system adds only 2% device power during normal operation.
Introduction
Extended Reality (XR) has the potential to transform application domains such as education, healthcare, accessibility, and industrial work. To support emerging capabilities such as spatial object search, AI assistants, and context-aware scene understanding, XR devices must go beyond reconstructing 3D geometry to associating semantic meaning with the physical environment. This requires a semantic mapping service that incrementally builds and retains a queryable 3D map linking geometry with meaning. For example, when a user asks ”Where are my keys?”, the system can guide them to the keys’ location, even if the keys are not currently in view, and highlight the keys once they come into view.
Deploying semantic mapping as a service on XR devices imposes several concurrent requirements. From the algorithm side, because XR devices operate in diverse and previously unseen environments, the semantic layer must be open-vocabulary, supporting recognition beyond fixed categories. From the system side, the system must operate in real time and within strict power budgets to support interactive applications on battery-constrained, all-day wearable devices. The resulting system must deliver high semantic quality, but quality demands vary across applications, creating opportunities to trade off resource usage for semantic coverage and geometric detail.
Recent algorithmic work in robotics has advanced open-vocabulary semantic mapping by lifting outputs from 2D foundation models into persistent 3D representations [conceptfusion, conceptgraph, clio, open-fusion, lerf, langsplat, ovir3d, onlineAnySeg, onemaptofindthemall]. Some of these approaches achieve real-time performance, but they assume server-class GPUs, with compute and power resources well beyond those available on mobile XR devices. No existing system delivers open-vocabulary, real-time semantic mapping within the power constraints of mobile XR devices.
| Location | System Requirements | ||||||||
| System Architecture | Mapping | Query | Device Power | Real-Time Mapping | Upstream BW | Query under Network Drops | Downstream BW | Device Memory | |
| All on-device | Device | Device | × | × | N/A | N/A | N/A | × | |
| Straightforward device-cloud† | Cloud | Cloud | ✓ | ✓ | × | ✓ | N/A | ||
| Cloud | Device | ✓ | ✓ | ✓ | × | × | |||
| Ours: SemanticXR — co-designed device-cloud semantic mapping | |||||||||
| Key insight: objects as the core system abstraction for communication, execution, and memory footprint | |||||||||
| Cloud | Cloud + Device | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| \rowcolorgray!12 SemanticXR object-level innovations | |||||||||
| \rowcolorgray!12 Object-level parallelism | ✓ | ✓ | |||||||
| \rowcolorgray!12 Object-level geometry downsampling | ✓ | ✓ | |||||||
| \rowcolorgray!12 Object-level depth-mapping co-design | ✓ | ✓ | |||||||
| \rowcolorgray!12 Object-level incremental updates | ✓ | ✓ | ✓ | ||||||
| \rowcolorgray!12 Object-level sparse local map | ✓ | ✓ | ✓ | ✓ | |||||
| \rowcolorgray!12 Object-level update prioritization | ✓ | ✓ | ✓ | ✓ | |||||
| \rowcolorgray!12 Object-level configurable resource usage vs. quality | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
One on-device alternative is specialized hardware acceleration, but rapidly evolving foundation model architectures limit the effective deployment lifetime of such accelerators. Cloud offloading offers a more practical path: it leverages powerful server-side GPUs potentially without increasing device power, avoids dependence on custom hardware, and frees on-device resources for other latency-sensitive XR tasks [xrgo, cloudxr, remotevio, slamshare, googlestream, meshreduce, tvmc_dasari, accumo, arise, elf, edgeAssistedObjectDetection, marvel, vips, rao]. However, how to partition semantic mapping across the device and the cloud under XR constraints remains an open problem.
SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture explores the design space and system requirements. A natural device-cloud split is to perform both mapping and querying on the server, but this leaves the device unable to answer queries during network drops, which are common in mobile XR. An alternative is to perform mapping on the server and maintain a copy of the semantic map on the device for local querying. This restores query availability during network drops, but introduces new costs: updating the device map requires transferring the full scene to the device, causing downstream bandwidth and device memory footprint to grow with scene size. On the server side, existing approaches incur high per-frame mapping latency despite access to powerful GPUs (Section 4.1). No single architecture satisfies all system requirements for deploying semantic mapping under XR constraints.
The underlying limitation is how existing approaches organize computation. Many fuse semantics into monolithic scene-level representations such as global volumetric maps [open-fusion], tying every cost to the total scene size and making them fundamentally incompatible with device-cloud deployment. Others detect and operate on fine-grained entities such as objects [conceptgraph, conceptfusion, clio, onlineAnySeg, openmask3d], but target algorithmic quality rather than system organization. In both cases, existing work specifies how to construct semantic maps, but not how to manage their communication, execution, and memory footprint across a device-cloud boundary.
We present SemanticXR, the first end-to-end device-cloud system that enables real-time, open-vocabulary semantic mapping and querying within the power, bandwidth, and memory constraints of mobile XR. Our key insight is to elevate semantically identifiable objects to first-class units of device-cloud system design, governing communication, execution, and memory footprint across the device and the server. This object-level system organization addresses the gaps identified in SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture, and is not tied to a specific foundation model, generalizing across pipelines that produce per-object mapping representations (Section 6.1).
SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture summarizes SemanticXR’s object-level system innovations and the system requirements they address. Object-level parallelism and geometry downsampling manage server-side computation at object granularity, improving real-time mapping latency over frame- or scene-level execution (Section 2.1). Object-level depth-mapping co-design downsamples depth before transmitting to the server and mitigates quality loss through per-object mapping decisions, providing a lightweight alternative to compression techniques [adaPang] for reducing upstream bandwidth with negligible device-side overhead (Section 2.3). On the device, an object-level sparse local map bounds device memory and downstream bandwidth while enabling queries under network drops (Section 2.2). Object-level incremental updates keep downstream bandwidth proportional to map changes rather than total scene size (Section 2.2). Object-level update prioritization further reduces device memory usage and downstream bandwidth by sending and storing only relevant object updates to the device. Object-level configurable resource usage vs. quality trade-offs unify these innovations, allowing both applications and the system to adapt semantic mapping behavior to application requirements and operating conditions respectively, without modifying the perception and mapping pipeline (Section 2.4).
Together, these innovations lead to the following contributions:
-
1.
We introduce SemanticXR, the first system to enable real-time, open-vocabulary semantic mapping and querying within the power, bandwidth, and memory constraints of mobile XR devices.
-
2.
We identify objects as the core system abstraction for device-cloud semantic mapping, elevating them to first-class units of communication, execution, and memory footprint management. This abstraction enables the innovations that collectively address all the gaps identified in SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture.
-
3.
We enable per-object configurable resource usage vs. quality trade-offs, allowing diverse applications and the system to adapt semantic mapping to application requirements and operating conditions respectively, without modifying the perception and mapping pipeline.
Since no existing system implements device-cloud semantic mapping, we construct a device-cloud baseline that uses the same perception models and mapping algorithm as SemanticXR but does not organize system operations at object granularity. This controlled comparison ensures that observed differences are attributable to system design rather than algorithmic or model choice. As discussed, approaches that fuse semantics into monolithic representations remain architecturally incompatible with device-cloud deployment (Section 7). Among compatible approaches, this device-cloud baseline is the only one to achieve real-time mapping latency without sacrificing semantic quality: the only other real-time approach has worse quality, and every approach with comparable quality runs offline, taking seconds to minutes per frame (Section 4.1). Over this device-cloud baseline, SemanticXR improves real-time mapping latency by 2.2 at equivalent semantic quality, maintains upstream bandwidth under 2.5 Mbps, and enables sub-100 ms query latencies even under network drops while supporting tens of thousands of objects within 500 MB. Downstream bandwidth scales with map changes rather than total scene size, and the system adds only 2% device power over idle during normal operation.
1 Background
1.1 Geometric Mapping and Semantic Mapping
Geometric mapping reconstructs a 3D representation of the environment, typically as a mesh, point cloud, or volumetric model, using inputs such as device pose, depth, and RGB frames. These maps support core XR functionalities such as collision detection, occlusion handling, and spatial audio. However, geometric mapping alone cannot assign semantic meaning to the scene; for example, it cannot distinguish or track objects or determine their semantic attributes.
Many emerging XR applications require understanding not only where surfaces exist, but also what they represent and how they relate to one another. Supporting such applications requires semantic mapping, which augments geometric reconstructions with persistent, queryable, and spatially grounded semantic attributes. Unlike per-frame semantic perception, semantic mapping maintains a persistent map with spatio-temporal consistency, recognizing previously observed objects, associating new observations with existing entities, and updating their attributes in place rather than creating a new map entry for each observation. Recent advances in open-vocabulary recognition enable systems to infer a broad and evolving set of object categories. Thus, realizing semantic mapping in XR requires not only accurate semantic inference, but also a system that manages a persistent semantic map under power, bandwidth, and memory constraints.
1.2 Foundation Models and Open-Vocabulary Semantic Mapping
Foundation models have substantially advanced 2D scene understanding by enabling open-vocabulary recognition and generalization to previously unseen categories. Models for grounded object detection, segmentation, captioning, and vision-language embedding extraction [gdino, ram, sam, sam2, clip, openclip1, openclip2, openclip3] provide strong building blocks for semantic mapping in XR. However, these models produce view-centric 2D predictions and do not natively maintain open-vocabulary semantics over persistent 3D scenes. Recent work addresses this by lifting outputs from 2D foundation models into persistent 3D representations, as described in Section 1.3.
1.3 Semantic Mapping using 2D Foundation Models
Semantic mapping using 2D foundation models has been explored in several prior works [conceptfusion, conceptgraph, open-fusion, ovir3d, multimodal3Dfusion:ISMAR24, onemaptofindthemall, onlineAnySeg, 3d_mem]. These approaches differ in how they structure semantic information. Some embed 2D region semantics into a monolithic 3D representation [open-fusion, seem, regionclip], tying all costs to total scene size. Others organize semantics around identifiable objects [conceptfusion, conceptgraph], producing discrete per-object representations. Both families target mapping quality rather than system organization: neither addresses how the semantic map is managed across a device-cloud boundary.
All the above approaches rely on computationally intensive foundation models, requiring server-class GPUs well beyond the power budget of mobile XR devices. As discussed in SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture, monolithic representations that tie every cost to total scene size are fundamentally incompatible with device-cloud deployment. We therefore build on the object-based family of pipelines, which produce discrete per-object representations. Our contributions are not tied to a specific foundation model but apply to any pipeline that produces per-object representations (Section 6.1).
1.3.1 Semantic Mapping Flow
Fig. 1 illustrates a representative semantic mapping pipeline. At a high level, the pipeline consists of two stages. First, per-frame semantic information is extracted using open-vocabulary models, producing per-object predictions. Second, these predictions are lifted into 3D using depth and camera pose and incrementally associated with existing objects in the map based on spatial and semantic similarity. Transient observations are pruned over time to mitigate noise.

1.3.2 Querying the Semantic Map
Once a semantic map is constructed, users can issue textual queries to retrieve relevant objects from the scene (Fig. 1). The system matches a semantic embedding of the query text against per-object descriptors (e.g., using CLIP embeddings and cosine similarity) and returns the best-matching objects along with their 3D representations. Because queries operate over the persistent semantic map, their cost depends on how that map is maintained and, in device-cloud settings, how much of it must be retained on the device.
2 SemanticXR
SemanticXR builds on the object-based semantic mapping pipelines described in Section 1.3 and illustrated in Fig. 1. As discussed, these approaches are largely algorithmic: they target mapping quality on powerful GPUs and are oblivious to the power, bandwidth, and memory constraints of XR devices. As summarized in SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture, no existing approach addresses how to manage communication, execution, and memory footprint across a device-cloud boundary. SemanticXR is a device-cloud system that bridges this gap, providing real-time, open-vocabulary semantic mapping and querying for low-power XR devices.
The key insight of SemanticXR is to elevate semantically identifiable objects to first-class units of device-cloud system design, governing how semantic information is communicated, executed, and stored across the device and the server. A map object is identified by a stable object ID and consists of a semantic embedding, a class label, and a 3D point cloud. This abstraction generalizes across pipelines that produce per-object representations.
As illustrated in SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture, the XR device streams synchronized RGB and depth frames of the user’s physical space along with the associated device pose to the server, where the semantic mapping pipeline (Section 1.3) detects objects, extracts semantic embeddings, and incrementally associates observations with existing objects and adds any freshly observed objects to the map. When the network is available, queries (Section 1.3.2) are evaluated against the full server-side map. During a network outage, the device falls back to a local semantic map maintained through object-level updates from the server.
This object-level system organization enables the innovations summarized in SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture and detailed in the following subsections: object-level parallelism and geometry downsampling for improved server-side mapping latency (Section 2.1), an object-level sparse local map with incremental updates and update prioritization for network-robust querying with bounded device memory and downstream bandwidth (Section 2.2), depth-mapping co-design for lightweight upstream bandwidth reduction (Section 2.3), and per-object configurable resource usage vs. quality trade-offs that address communication, execution, and memory footprint (Section 2.4).
2.1 Mapping Latency
Open-vocabulary semantic mapping composes multiple foundation models followed by incremental 3D association, resulting in substantial server-side computational load. When execution is organized at frame or scene granularity, all computation is treated uniformly regardless of per-object variation in size and complexity, limiting opportunities for parallelism and missing potential efficiency gains available from this variability.
Object-level parallelism. SemanticXR structures server-side execution at object granularity. After object proposals are generated for a frame, subsequent processing is performed independently for each detected object (SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture). By moving away from a frame-level execution, segmentation and vision-language feature extraction are parallelized across objects within a frame, improving GPU utilization and reducing per-frame processing latency.
Object-level geometry downsampling. Projecting objects into 3D produces highly variable per-object point cloud sizes, depending on the size of the object, leading to disproportionate computational cost. Per-object geometry is needed to place each object in 3D, both for associating and merging observations by spatial proximity and for returning an object’s location in response to queries. Because object association and merging depend on spatial proximity and semantic similarity but not on high-fidelity geometric detail, SemanticXR caps the number of points per object through geometry downsampling, bounding per-object computation and improving mapping latency without degrading semantic quality. A system parameter controls this bound, enabling applications to adjust the trade-off between geometric detail and mapping latency (Table 2).
Together, object-level parallelism and geometry downsampling improve server-side mapping latency. We evaluate the resulting improvements in Section 4.1.
2.2 Query Under Network Drops: Downstream Bandwidth and Device Memory Footprint
Interactive semantic queries in XR must remain responsive even during network drops. SemanticXR supports two query modes: Server Querying (SemanticXR-SQ), where queries are evaluated against the full server-side semantic map, and Local Querying (SemanticXR-LQ), where queries are executed on the device using a local semantic map. Enabling SemanticXR-LQ requires maintaining a semantic map on the device, but a full copy of the server map is impractical: device memory would grow with scene size, and keeping the local map updated would require transferring the full map, causing downstream bandwidth to grow with scene size as well. SemanticXR addresses both constraints through three object-level innovations.
Object-level sparse local map. SemanticXR maintains a local semantic map on the device organized as a collection of per-object entries. Each entry stores a semantic embedding for query matching and a point cloud further downsampled from the server-side representation (Section 2.1) to fit device memory constraints; downsampling thus reduces a retrieved object’s geometric detail, not which objects a query retrieves, so query accuracy is unaffected and the retained geometry remains sufficient for spatial localization. Because each object’s geometry is capped at a configurable point budget rather than stored as a dense scene-wide reconstruction, per-object memory is fixed and total device memory grows only with the number of retained objects, not with scene complexity. An application visible system parameter controls the point budget per object, enabling applications and the system to adjust the memory–quality trade-off (Table 2). The number of retained objects is further bounded by update prioritization, described below.
Object-level incremental updates. Updates to the local map are transmitted as object-level incremental updates. Rather than transferring the full semantic map, the server sends only newly created or modified objects (observed from a different angle). As a result, downstream bandwidth is proportional to the number of changed objects rather than the total scene size. Updates are issued periodically and only after an object has been consistently observed across multiple frames, filtering out transient detections before they propagate to the device. A system parameter controls update frequency, enabling applications and the system to balance map freshness against downstream bandwidth (Table 2).
Object-level update prioritization. Object-level update prioritization determines which objects are maintained on the device based on semantic relevance, spatial proximity, and application-declared priority classes (for example, task-relevant categories, nearby objects, or distant landmarks), limiting the local map to the most relevant content and reducing device memory and downstream bandwidth. When the local map reaches its memory budget, admitting a higher-priority update evicts the lowest-priority retained objects, keeping the map within budget. The object-level abstraction makes richer replacement policies straightforward to add in the future.
Query mode switching. During network drops, pending updates are buffered on the server and applied upon reconnection. Network quality is monitored using latency and transmission error signals from the RGB-D stream. When network latency exceeds a configurable threshold, the system switches from SemanticXR-SQ to SemanticXR-LQ. SemanticXR-LQ may therefore operate on a slightly stale state, but staleness is bounded by the most recent successful update.
2.3 Upstream Bandwidth
Offloading semantic mapping requires the XR device to transmit synchronized RGB and depth frames of the user’s physical space, along with the associated device pose, to the server. While RGB can be efficiently compressed using hardware video encoders available on mobile XR devices, depth is typically produced as high-precision frames that cannot leverage the same hardware directly [adaPang]. While prior work has explored depth compression [adaPang], SemanticXR instead asks a co-design question: how much can depth be approximated while preserving semantic quality? This leads to a lightweight alternative – downsampling the depth frames prior to transmission and mitigating quality loss through per-object mapping decisions.
Object-level depth-mapping co-design. While depth downsampling substantially lowers transmission cost, it can degrade geometric detail if applied uniformly. Because the semantic map is organized around discrete objects, mapping decisions are made per object rather than per frame. Objects that occupy sufficient image area retain reliable depth even after downsampling and are incorporated immediately, while smaller or distant objects are deferred until additional observations improve depth reliability. A system parameter controls the minimum object area required for incorporating an observation, enabling applications to adjust the trade-off between upstream bandwidth and semantic quality (Table 2). We evaluate this trade-off in Section 4.5.
2.4 Object-Level Configurable Resource Usage vs. Quality
XR applications impose diverse requirements on semantic maps; e.g., some require broad scene coverage while others prioritize specific object categories or regions. Because SemanticXR organizes all system operations at object granularity, applications can trade off resource usage, including compute, memory, and bandwidth, against semantic quality per object or per category, without modifying the underlying mapping pipeline. Table 2 summarizes the exposed parameters and their system-level effects. This configurability cuts across all system operations: applications can adjust geometric detail vs. mapping latency via geometry downsampling (Section 2.1), control local map update frequency vs. downstream bandwidth (Section 2.2), and reduce upstream bandwidth via depth-mapping co-design while preserving semantic quality (Section 2.3).
| Configurable Trade-off | Exposed System Knobs | Effect and Trade-off | Default |
| Query latency vs. device power | net_latency_switch_threshold | Switches between SemanticXR-SQ and SemanticXR-LQ; trades device power for latency. | ms |
| Object class mapping policy | skip_mapping_set, max_object_points_server | Prioritizes selected object classes for detailed mapping; others are skipped or sparsified to reduce compute and downstream bandwidth. | Empty, pts |
| Local map geometric detail vs. memory | max_object_points_client, max_object_points_server | Enables denser local geometry for selected classes; trades memory footprint for geometric detail. | pts, pts |
| Local map freshness vs. downstream bandwidth | local_map_update_frequency | Controls the frequency of incremental local map updates, trades map freshness for downstream bandwidth. | Every frames |
| Upstream bandwidth budget | min_mapping_bbox_area, depth_downsampling_ratio | Filters small objects from mapping based on projected size, enabling depth downsampling and reduced upstream load under bandwidth constraints. | px and 5downsampling |
3 Evaluation Methodology
3.1 SemanticXR Implementation Details
We evaluate SemanticXR using the object-based semantic mapping pipeline described in Section 1.3. Per-object semantic observations are generated using off-the-shelf zero-shot models for captioning (RAM [ram]), object detection (Grounding DINO [gdino]), instance segmentation (MobileSAM [mobilesam]), and vision-language embedding (MobileCLIP [mobileclip]). The device transmits RGB, depth, and pose to the server (Section 2.3), where all semantic mapping is performed. During network drops, the device executes queries against its local semantic map (Section 2.2). We use a fixed configuration (Table 2) except when studying a specific tunable parameter (e.g., depth downsampling in Section 4.5).
3.2 Device-Cloud Baseline and Evaluation Goals
Our evaluation characterizes the effect of object-level system organization on device-cloud deployment under XR constraints. Since no existing system implements device-cloud semantic mapping, we construct a controlled and competitive device-cloud baseline to isolate this effect.
Splitting semantic mapping requires managing communication, execution, and memory footprint across the device-cloud boundary. Monolithic approaches that fuse semantics into global representations [open-fusion] tie every cost to total scene size, incurring prohibitive overhead. Other pipelines [conceptgraph, conceptfusion, clio, onlineAnySeg, openmask3d] produce discrete per-object map representations, which are a prerequisite for the object-level system organization introduced by SemanticXR. Our device-cloud baseline follows this family (Fig. 1) and uses identical perception models and mapping pipeline as SemanticXR (Section 3.1) but does not organize system operations at object granularity. The server processes frames without object-level parallelism or geometry downsampling. The device receives periodic full scene updates to support local querying, rather than incremental and sparse object-level transfers. Both SemanticXR and the device-cloud baseline transmit downsampled depth; the effect of depth-mapping co-design on upstream bandwidth is studied independently in Section 4.5. Any observed differences are therefore attributable solely to system organization.
As shown in Section 4.1, this device-cloud baseline already matches or exceeds prior open-vocabulary mapping approaches in semantic quality while achieving lower mapping latency on the evaluated (Replica) dataset [replica].
3.3 Evaluation System Setup
Our evaluation requires fine-grained power instrumentation and controlled low-power configurations to characterize system behavior under XR constraints. Commercial XR headsets do not expose these capabilities, limiting their suitability for evaluating power-sensitive system design. Therefore, for the bulk of our work, following prior XR systems work [illixr, remotevio, xrgo], we use an NVIDIA Jetson Orin configured in low-power mode as a proxy XR device. The platform provides embedded GPU compute, configurable power envelopes, and detailed system instrumentation. The configuration in Table 3 emulates a modern mobile XR headset by limiting GPU TPC count, operating frequencies, and power envelope to levels representative of all-day wearable devices.
| System Parameters | Low Power | MAXN |
| CPU Frequency (MHz) | 1728 | 2202 |
| GPU Frequency (MHz) | 1020 | 1301 |
| CPU count | 8 | 12 |
| GPU TPC count | 3 | 8 |
| Idle Power | 8.6W | 10W |
| Power Cap | 20W | 60W |
Semantic mapping and query execution run on a dedicated server equipped with an AMD Ryzen Threadripper 7960X CPU and an NVIDIA RTX 6000 Ada GPU. This configuration represents a contemporary cloud-class server and is held fixed across all experiments.
To study the impact of network conditions on system behavior, we evaluate SemanticXR under three network configurations: (1) a low-latency network with an average round-trip time (RTT) of approximately 20 ms, (2) degraded connectivity with 66 ms RTT, and (3) complete network outage to evaluate local querying (Section 2.2). These settings are used consistently across experiments unless otherwise noted.
3.4 Dataset and Evaluation Scope
We use the Replica dataset for evaluation as adopted by other prior semantic mapping works [conceptgraph, clio]. Replica consists of diverse indoor room and office scenes and provides synchronized RGB, depth, and camera pose sequences with ground-truth semantic labels, enabling controlled and reproducible evaluation of object-level semantic queries. Our evaluation focuses on indoor scenes. Outdoor environments typically require different perception models, but since SemanticXR does not assume specific model architectures, the same system design applies when paired with suitable outdoor models. We leave empirical validation of outdoor deployment to future work.
To demonstrate feasibility on commodity hardware with real sensors, we additionally deploy SemanticXR on an iPad-based prototype. This deployment is presented as an end-to-end system demonstration rather than a performance evaluation and is discussed separately in Section 5.
3.5 Evaluation Metrics
Our evaluation quantifies how object-level system organization influences device-cloud execution efficiency, and characterizes SemanticXR’s robustness to network drops.
To isolate the impact of our system design, specifically whether semantic state is managed at scene or object granularity, all experiments hold the semantic mapping pipeline constant (Section 3.1).
We evaluate SemanticXR along dimensions that correspond to the system requirements identified in SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture: device power consumption, server-side mapping latency, upstream bandwidth, query latency under network outage, downstream bandwidth, device memory, and the impact of object-level system organization on semantic quality. These metrics collectively characterize how SemanticXR’s object-level system organization addresses the requirements of device-cloud semantic mapping (Section 4).
3.5.1 Latency: Semantic Mapping and Queries
Semantic mapping latency measures the time required by the server to process a single RGB, depth, and pose frame and update the semantic map. This includes semantic perception using foundation models as well as subsequent object-level map fusion. To report throughput (Frames Per Second), we follow standard practice from the literature [onlineAnySeg, rtgslam, gpsslam]: semantic maps are incrementally refined and do not require updates for every input frame, so we sample keyframes at a fixed interval and report throughput as total input frames divided by total keyframe processing time. We use a keyframe interval of 5; prior work commonly uses intervals of 10 or higher [onlineAnySeg, gpsslam].
Query latency measures the time required to process a text query and retrieve matching objects from the semantic map (Section 1.3.2). This includes text embedding extraction and similarity computation against stored object embeddings. For server-side queries, we additionally include the network round-trip time required to transmit the query and return the resulting object geometry.
3.5.2 Semantic Quality
We evaluate semantic quality by measuring the accuracy of object retrieval from the semantic map given natural-language text queries. We follow the evaluation methodology of [conceptfusion] on the Replica dataset [replica], which provides ground-truth semantic labels and object annotations. Ground-truth labels are used to generate text queries that are issued against the semantic map constructed by SemanticXR. Retrieved object point clouds are compared against ground-truth using mean class recall (mAcc) and frequency-weighted mean Intersection-over-Union (F-mIoU). These metrics are standard in prior work [conceptfusion, conceptgraph, clio].
3.5.3 Device Memory and Query Latency under Network Outage
To evaluate how the local semantic map scales with scene complexity, we measure device memory and query latency as a function of the number of objects stored on the device. Synthetic semantic maps are constructed by incrementally inserting object point clouds with associated vision-language embeddings. We evaluate map sizes ranging from 80 objects (comparable to room-scale Replica scenes) to 1,000, 5,000, and 10,000 objects, representing increasingly large indoor environments. We additionally report results for 25,000 and 50,000 objects to characterize extreme cases. Results are discussed in Section 4.3.
3.5.4 Network Bandwidth Usage
We measure upstream bandwidth as the average data rate required to stream RGB, depth, and pose from the XR device to the server, accounting for RGB compression and configurable depth resolution. Downstream bandwidth measures the volume of semantic map data transferred during map synchronization. The resulting trade-offs are analyzed in Sections 4.5 and 4.4.
3.5.5 XR Device Power Consumption
We measure power consumption on the XR client device using tegrastats [Tegrastats], sampled at 1 ms intervals. Tegrastats reports power across major subsystems, including CPU, GPU, SoC, DRAM, and system I/O. All reported power measurements include the device’s idle power, which is approximately 8.6 W on the Jetson Orin in low-power mode. We evaluate XR device power consumption under three configurations that characterize SemanticXR’s operating regimes:
-
1.
On-device semantic mapping and querying: Measures total power when the semantic mapping pipeline executes entirely on the device in maximum power mode. This establishes the power cost that SemanticXR’s cloud offloading avoids.
-
2.
SemanticXR under network outage and heavy query rate: Measures device power when semantic mapping is offloaded to the server and the device executes local queries at one query every three seconds, emulating a plausible but heavy query rate.
-
3.
SemanticXR under continuous local querying: Although users do not issue queries continuously, some applications may generate short bursts of quick queries. We therefore measure power consumption under continuous local querying to characterize worst-case peak power on the XR device, representing (unrealistic) sustained querying during network outage.
4 Results
This section evaluates the object-level system innovations introduced by SemanticXR (SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture) along the evaluation dimensions defined in Section 3.5. All experiments compare SemanticXR against the device-cloud baseline described in Section 3.2; observed differences are attributable to system organization rather than algorithmic or model choice. We first establish that the device-cloud baseline is competitive with prior work in mapping latency and semantic quality. We then evaluate how object-level system organization affects server-side mapping latency (Section 4.1), query latency under varying network conditions (Section 4.2), device memory and query latency for large local maps (Section 4.3), downstream bandwidth (Section 4.4), upstream bandwidth and its interaction with semantic quality (Section 4.5), and device power consumption (Section 4.6).
4.1 Semantic Mapping Latency and Quality
Table 4 compares semantic quality and per-frame mapping latency across prior open-vocabulary mapping approaches, our device-cloud baseline, and SemanticXR. Most prior approaches are offline and require seconds to minutes per frame. Our device-cloud baseline exceeds all prior approaches in semantic quality except OpenMask3D, while being the only system that operates in real time. Clio-online is the only other real-time approach, but the authors report that quality degrades significantly without offline post-processing, and do not evaluate quality in online mode on Replica.
| Method | mAcc | F-mIOU | Latency (s/frame) |
| ConceptFusion [conceptfusion] | 24.16 | 31.31 | Offline |
| ConceptGraphs [conceptgraph] | 38.72 | 35.82 | Offline |
| OpenMask3D [openmask3d] | 39.54 | 49.26 | Offline |
| Clio (batch)† [clio] | 37.95 | 36.98 | Offline |
| Clio (online)‡ [clio] | N/R (bad)‡ | N/R (bad)‡ | 0.30* |
| Our device-cloud baseline | 37.0 | 47.23 | 0.57 |
| SemanticXR | 37.6 | 48.29 | 0.26 |
Fig. 2 shows how object-level parallelism and geometry downsampling reduce per-frame mapping latency over this already competitive device-cloud baseline. Object-level parallelism enables concurrent execution of segmentation and vision-language feature extraction across objects, while geometry downsampling bounds per-object point cloud size. Together, average per-frame mapping latency drops from approximately 570 ms to approximately 260 ms, a 2.2 improvement. Under the throughput methodology described in Section 3.5, SemanticXR achieves approximately 20 FPS compared to approximately 8.75 FPS for the device-cloud baseline, at equivalent semantic quality (Table 4).

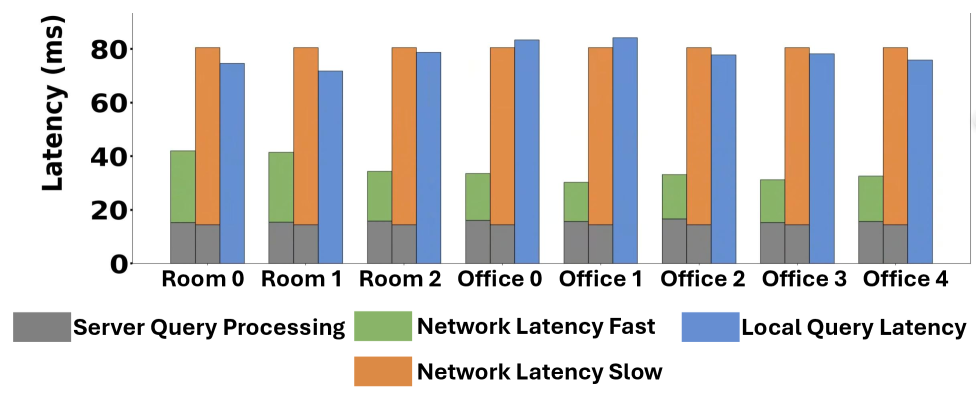
4.2 Query Latencies: Local and Server
Fig. 3 compares average query latency for server-side querying (SemanticXR-SQ) and local querying (SemanticXR-LQ) under two network conditions: a low-latency network and a higher-latency network, evaluated across multiple Replica scenes. Server-side query latency includes server computation and network round-trip time, while local query latency includes only on-device text embedding and similarity computation against the object-level sparse local map (Section 2.2).
Under low-latency network conditions, SemanticXR-SQ achieves lower end-to-end latency due to the server’s higher compute capability for text embedding, while reducing XR device power consumption (Section 4.6). Under higher-latency network conditions, network delay dominates server-side latency and introduces significant variability, causing SemanticXR-SQ to approach or slightly exceed SemanticXR-LQ latency.
In contrast, SemanticXR-LQ remains stable across network conditions because it operates entirely on the device using the object-level sparse local map. This stability comes at the cost of higher device power consumption than SemanticXR-SQ. We next examine how local query performance scales as the local semantic map grows.
4.3 Device Memory and Query Latency for Large Local Maps
We evaluate device memory footprint and local query latency as the number of objects in the local semantic map increases. Fig. 4 shows both metrics for progressively larger synthetic maps ranging from 80 objects (comparable to room-scale Replica scenes) to 50,000 objects. Because SemanticXR’s object-level sparse local map caps per-object geometry at a configurable point budget rather than storing a dense scene-wide reconstruction (Section 2.2), per-object memory is bounded and total device memory grows with the number of retained objects rather than scene complexity. SemanticXR supports local maps containing up to 50,000 objects within a 500 MB memory footprint; associated resource-quality trade-offs are configurable via the parameters in Table 2.
Local query latency consists of two components: text embedding extraction, which is independent of map size, and similarity computation against stored per-object embeddings, which grows with the number of objects. For maps containing up to 10,000 objects, end-to-end local query latency remains below 100 ms, enabling network-independent querying at interactive latency. Beyond 10,000 objects, query latency increases but remains practical for large indoor environments.

4.4 Downstream Bandwidth
The device-cloud baseline transmits the full semantic map to the device on every update, causing downstream bandwidth to grow with the total number of objects in the scene regardless of how many have changed. In contrast, SemanticXR transmits object-level incremental updates (Section 2.2), sending only newly created or modified objects.
Fig. 5 shows this effect. Downstream bandwidth for the device-cloud baseline grows proportionally with the number of mapped objects, as each update transfers the full scene. SemanticXR instead transfers only the changed object set, so per-update downstream bandwidth is proportional to the number of changed objects rather than total scene size.111Both systems apply geometry downsampling in this experiment; without it, the device-cloud baseline’s per-update transfer size would be larger. As exploration converges and fewer new objects are discovered, SemanticXR’s per-update cost decreases further, whereas the device-cloud baseline’s cost remains at its plateau.

4.5 Upstream Bandwidth
As discussed in Section 2.3, SemanticXR explores a co-design question: how aggressively can depth be downsampled before transmission while preserving semantic quality? Rather than applying compression [adaPang], SemanticXR downsamples the depth frame and mitigates the resulting geometric loss through per-object mapping decisions that defer objects with unreliable depth until additional observations are available. Table 5 reports the resulting upstream bandwidth and semantic quality when varying depth downsampling ratio and minimum object area (Table 2). Reducing depth resolution by in each spatial dimension ( overall) decreases upstream bandwidth by approximately 90% while causing only a small drop in quality (F-mIoU). Further reductions yield diminishing bandwidth savings while increasingly deferring object integration, as fewer objects meet the minimum area threshold per frame.
| Depth Down-sampling | Upstream BW (Mbps) | Quality (F-mIoU) |
| No Down-sampling | 26.4 | 48.29 |
| row, column () | 7.72 | 45.5 |
| row, column () | 4.26 | 44.26 |
| row, column () | 3.06 | 45.73 |
| row, column () | 2.5 | 45.81 |
4.6 XR Device Power Consumption
Fig. 6 reports XR device power consumption under the three configurations defined in Section 3.5. Running the full semantic mapping pipeline on-device requires approximately 50 W and takes several seconds for mapping a single frame, confirming that on-device mapping is impractical within XR power budgets and motivating SemanticXR’s cloud offloading.
Under normal operation with server-side mapping and SemanticXR-SQ, the device transmits RGB, depth, and pose and receives query results; semantic compute remains on the server. The resulting device power is approximately 8.7 W, an increase of only 2% over the 8.6 W idle baseline (Table 3). Under network outage, the device falls back to SemanticXR-LQ on the object-level sparse local map (Section 2.2). Executing local queries at a heavy rate of one query every three seconds increases average power to 9.8 W, an incremental cost of approximately 1.2 W over idle. Because SemanticXR-LQ evaluates similarity against per-object embeddings rather than a dense scene representation, the per-query compute cost remains modest. To characterize worst-case behavior, we additionally measure power under continuous query execution at the maximum achievable rate of 14.7 queries per second. Peak power reaches 13.23 W, an increase of approximately 4.6 W over idle, remaining within the power envelope of contemporary XR devices.

4.7 Summary
Across all evaluation dimensions (SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture and 3.5), object-level system organization improves server-side mapping latency by 2.2 at equivalent quality, enables sub-100 ms local queries for up to 10,000 objects within 500 MB, decouples downstream bandwidth from scene size, reduces upstream bandwidth by 90% with minor quality loss, and adds only 2% device power under normal operation.


5 Deployment Case Study: iPad-based Prototype
To validate SemanticXR with real sensors, we implemented a prototype deployment on a consumer mobile XR device to demonstrate end-to-end feasibility.
We deploy the client on an Apple iPad Pro [ipad], which provides synchronized RGB, depth, and pose streams via ARKit [arkit]. Current commercial XR headsets such as the Apple Vision Pro do not expose raw sensor streams required for semantic mapping, making the iPad a practical proxy for a mobile XR sensing stack. We deploy a custom ARKit client that captures RGB, depth, and pose at 30 FPS and streams a subset of frames to the server to match semantic mapping throughput. RGB frames () are compressed using H.264 at 5 Mbps, and transmitted with low resolution depth maps () following the depth-mapping design in Section 2.3. The system uses SemanticXR’s tunable interface to adjust frame transmission and mapping parameters under varying scene conditions.
For spatial queries, the client performs on-device speech-to-text and forwards textual queries to the server via gRPC. The server returns object-level point clouds that the client renders as world-aligned overlays in ARKit.
Although the iPad does not expose fine-grained power telemetry, this deployment demonstrates end-to-end operation with real sensors, mobile hardware, and interactive user queries. Fig. 7 shows the deployed system: the server incrementally constructs the semantic map (Fig. 6(a)), and the iPad client overlays queried objects in the user’s view (Fig. 6(b)).
6 Discussion
6.1 Applicability Across Semantic Mapping Pipelines
SemanticXR’s system innovations (SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture) are not tied to a specific perception model; they require only that the backend produce persistent, discrete object-level semantic state that can be incrementally maintained. Backends that already maintain per-object representations (e.g., [conceptgraph, conceptfusion, clio, onlineAnySeg]) can adopt SemanticXR’s abstractions directly by promoting objects to independently managed system state. Pipelines that aggregate object inference into monolithic scene representations [open-fusion, multimodal3Dfusion:ISMAR24] must first expose persistent object entities, requiring more substantial restructuring.
6.2 Query Scope
SemanticXR is evaluated on object-grounding queries, which retrieve the scene objects that best match a natural-language description. The object-centric organization extends to other query classes through targeted additions rather than a redesign: multi-object and relational queries via an external reasoning agent operating over the object map, affordance queries via additional per-object attributes, and free-space or global-layout queries via complementary representations such as occupancy.
6.3 Relationship to Model-Level Optimization
Model-level optimization, such as quantization, pruning, and distillation, is orthogonal to SemanticXR’s object-level system organization. Because the foundation models run on the server, such optimization would improve server-side mapping efficiency and concurrent-client capacity rather than device power, which offloading already holds near idle (about 2%, Section 4.6). The two are complementary: model optimization lowers the cost of each model, while object-level organization governs how that cost is communicated and stored across the device-cloud boundary.
6.4 Future Work
Future directions include server-side scalability to multiple concurrent devices, support for dynamic environments with moving objects and multi-user collaborative mapping, and extending the object-level interface to richer geometric representations such as per-object meshes with non-uniform detail. SemanticXR’s configurable knobs (Section 2.4) also motivate autotuning and dynamic control, i.e., automatically adapting resource-quality parameters to application and network conditions instead of manual configuration. Agentic integration is another direction: humans could issue complex spatial tasks that an agent resolves by issuing spatial queries against SemanticXR’s map and acting on the returned objects. Privacy-aware design for device-cloud XR systems remains an important open problem. Evaluation on commercial XR headsets and outdoor environments would further validate deployment generality.
7 Related Work
Prior work has studied semantic mapping primarily as an algorithmic perception problem, while cloud offloading in XR has largely focused on rendering or isolated perception tasks. In contrast, deploying semantic mapping as a low-power, long-running XR service requires managing communication, execution, and memory footprint across a device-cloud boundary, a problem that existing approaches do not address.
7.1 Semantic Mapping in Robotics and XR
A large body of work has explored open-vocabulary semantic mapping by embedding image- or text-derived semantics into 3D representations. Representative systems include Clio [clio], SpatialLM [spatiallm], OpenFusion [open-fusion], ConceptFusion [conceptfusion], ConceptGraph [conceptgraph], and One Map to Find Them All [onemaptofindthemall]. These approaches differ in perception models, representations, and update strategies, and collectively demonstrate the feasibility of constructing semantic maps from RGB-D observations. Many support online RGB-D processing [clio, open-fusion], while others operate offline over preprocessed point clouds. However, these systems target algorithmic quality under server-class hardware assumptions, whether through task-driven scene representations [clio] or monolithic scene-level representations [open-fusion, multimodal3Dfusion:ISMAR24], rather than system organization for device-cloud deployment under XR constraints.
Unlike these open-vocabulary systems, a related line of robotics work builds real-time hierarchical 3D scene graphs from closed-vocabulary perception, including Hydra [hydra, hydra_foundations], and SceneGraphFusion [sceneGraphFusion]. Because this perception is lightweight, these systems run on a single machine and do not address the device-cloud split that foundation-model perception forces on mobile XR. Clio [clio] extends this scene-graph line toward open-vocabulary, task-driven mapping and is the closest comparison among these systems (Table 4). Separately, 3D instance segmentation methods [openmask3d, embodSAM, onlineAnySeg, ovir3d] focus on geometric shape decomposition rather than persistent, queryable semantic state and do not target device-cloud deployment. In contrast, SemanticXR treats existing semantic mapping pipelines as backends and elevates objects to first-class units of device-cloud system design, governing communication, execution, and memory footprint across the device-cloud boundary (SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture).
7.2 VLM-based Assistants and Scene Understanding
Recent XR systems have explored natural language interaction using VLM-based assistants such as Google’s Project Astra [astra] and XaiR [xair]. These systems reason over visual observations together with short-term textual or embedding-based memory [astra], or attach per-frame features to pre-built geometry without distinguishing individual objects [xair]. Neither builds a persistent, queryable 3D semantic map with explicit object identities. SemanticXR addresses an orthogonal problem: how to build and manage such a map across a device-cloud boundary under the power, bandwidth, and memory constraints of mobile XR.
7.3 Cloud Offloading in XR
Several prior works have explored cloud offloading for XR to address the compute and power limitations of mobile devices, including offloading components such as head pose estimation, visual tracking, and rendering [remotevio, cloudxr, xrgo, renderfusion, furion, slimslam, slamshare, adaPang]. These systems primarily focus on latency-sensitive rendering pipelines or geometric reconstruction, and do not consider the challenges associated with maintaining and querying a persistent semantic map. In addition, offloading AI workloads such as object detection and segmentation has been widely studied [accumo, arise, elf, edgeAssistedObjectDetection, marvel, vips, rao]. While some of these systems operate at object granularity, they typically target task-specific domains (e.g., object detection over a limited and predefined set of categories) and do not address the requirements of open-vocabulary semantic mapping. Techniques such as keyframe sampling reduce bandwidth or server compute, but do not address the system-level challenges introduced by offloading semantic mapping in XR, including maintaining persistent semantic state and robustness to network variability.
7.4 Semantic Maps on Neural Representations
Recent work has explored semantic scene representations based on neural fields, such as NeRFs [nerf] augmented with language grounding [lerf], and Gaussian-based representations [gaussian] extended for semantic queries [langsplat, sgsslam]. While effective for dense reconstruction and semantic querying, these representations typically require optimization over accumulated observations and are not yet designed for incremental, low-latency updates under the power, bandwidth, and memory constraints of mobile XR systems.
Taken together, prior work provides strong semantic mapping backends and cloud-XR mechanisms, but does not address how to manage communication, execution, and memory footprint for semantic mapping across a device-cloud boundary under the power, bandwidth, and memory constraints of mobile XR. SemanticXR addresses this gap through object-level system organization that is compatible with a broad class of existing semantic mapping pipelines.
8 Conclusion
We presented SemanticXR, the first device-cloud system for real-time, open-vocabulary semantic mapping and querying within the power, bandwidth, and memory constraints of mobile XR. Our key insight is that semantically identifiable objects can serve as first-class units of device-cloud system design, governing how the system communicates, executes, and manages memory across the device and the server. This object-level system organization enables a family of innovations (SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture) that collectively address the requirements of XR device-cloud semantic mapping: object-level parallelism and geometry downsampling improve server-side mapping latency by 2.2 at equivalent semantic quality, object-level depth-mapping co-design reduces upstream bandwidth by 90% with a small quality loss, and an object-level sparse local map with incremental updates and update prioritization enables sub-100 ms query latency for up to 10,000 objects within 500 MB, with downstream bandwidth proportional to map changes rather than total scene size. The system adds only 2% device power during normal operation. Because SemanticXR operates on object-level semantic state rather than model-specific internals, its system innovations generalize across any semantic mapping pipeline that produces persistent per-object representations.