Pipelining and non-pipelining are two different approaches used in computer architecture and data processing. Pipelining is widely used in modern processors to execute more instructions in less time, improving overall performance.
Pipelining
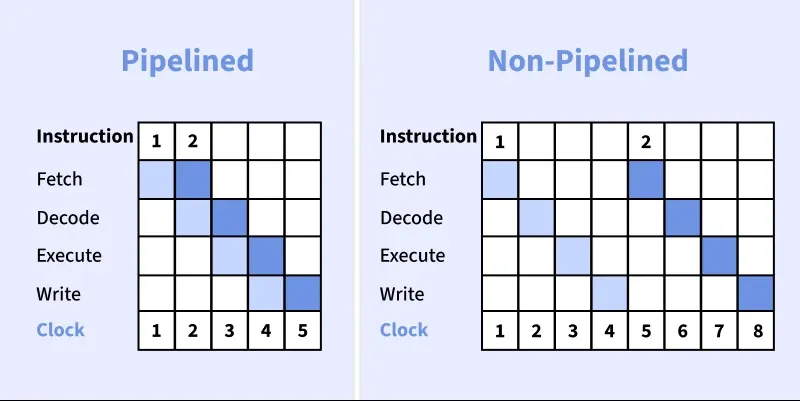
Different instructions are processed simultaneously at various stages, similar to an assembly line, which increases instruction throughput and reduces idle time in the processor. Pipelining improves throughput (instructions per second), not the latency of a single instruction.
Non-Pipelining
A non-pipelined (or sequential) processor executes one instruction completely before starting the next. All stages of instruction processing occur in a single, monolithic cycle or are performed sequentially without overlap.
This is like a single chef cooking one dish from start to finish before beginning the next — simple, but slow when handling many orders.
Pipelining vs Non-Pipelining
| Pipelining | Non-Pipelining |
|---|---|
| Multiple instructions execute in different stages simultaneously | Only one instruction executes at a time |
| Divided into stages (e.g., 5-stage pipeline: IF, ID, EX, MEM, WB) | All operations merged into one or few sequential steps |
| High — multiple instructions complete per cycle (after pipeline fill) | Low — one instruction per several cycles |
| Same as non-pipelined (or slightly higher due to stage registers) | Same or lower (no pipeline overhead) |
| Shorter — each stage does less work | Longer — entire instruction fits in one cycle |
| Higher — needs pipeline registers, hazard detection, forwarding logic | Lower — simpler control unit |
| Depends on CPU scheduler, branch prediction, and hazard resolution | Depends only on instruction selection from ready queue |
| Fewer cycles to complete n instructions (after fill) | More cycles — n × stages |
| High-performance CPUs, GPUs, embedded systems | Simple microcontrollers, early computers, educational models |