In the digital world, every letter, number, and symbol you see on your screen—from the "A" in "Apple" to the "@" in an email address—is ultimately represented by a series of bits, the fundamental 0s and 1s that computers understand. Character encoding is the process of converting characters (letters, numbers, symbols) into a format that computers can understand and store.
- Encoding ensures computers can store, process, and transmit text data accurately.
- Decoding reverses the process, turning binary codes back into readable text for display or use.
- The process of converting human-readable characters into these binary codes and back again is called character encoding.
Why We Need a Character Encoding System
Every letter, number, or symbol has a unique code number. When you type 'A', the computer looks it up in its codebook, finds the number for 'A', and then converts that number into 0s and 1s. When it needs to show you 'A' on the screen, it does the reverse.
Text Encoding Types
Text encoding is how computers understand our words. It turns letters, numbers, and symbols into a code computers can read, usually as binary (1) and (0). Over time, different encoding systems have been created to handle all the different languages and symbols we use, like:
ASCII
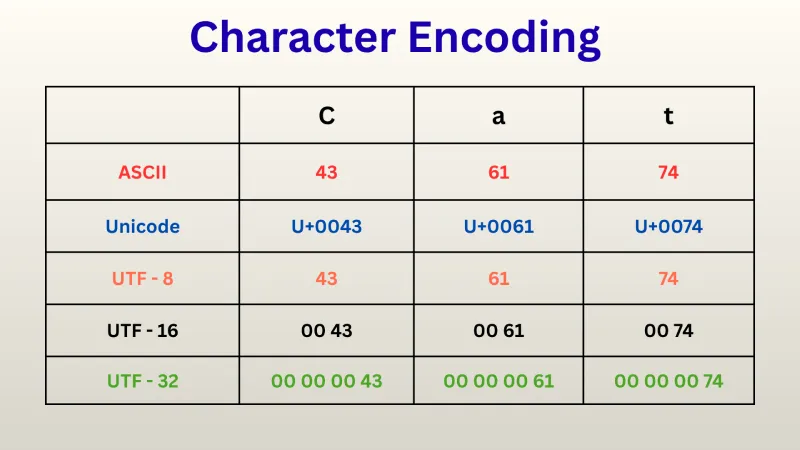
Also known as American Standard Code for Information Interchange, it is arguably the most fundamental and widely recognized character encoding. Developed in the 1960s for teletypes, it laid the groundwork for how computers worldwide communicate text. The idea is so simple just assign a number to each character, like A is assigned as 65, and so on.

ASCII is a 7-bit encoding, meaning it can represent 27= 128 different characters, like
1. Non-printable, system codes between 0 and 31.
- 8 → backspace
- 10 → new line
- 13 → carriage return
2. Lower ASCII, between 32 and 127.
- 32 → space
- 40 → (
- 65 → A
- 70 → F
- 97 → a
- 102 → f
3. Higher ASCII, between 128 and 255.
See Complete ASCII Table
Point to Know:
The 7-bit nature of ASCII limits it to English characters and a basic set of symbols. It cannot represent characters from other languages (like accented letters, Cyrillic, Arabic, Chinese, Japanese, Korean, etc.) or specialized symbols. This limitation led to the development of "extended ASCII" variants (using the 8th bit for an additional 128 characters), but these were inconsistent and caused "mojibake" (garbled text) when files were opened on systems using a different extended ASCII variant.
Unicode: The Universal Character Sets.
- Unicode is a universal encoding technique that can be used to encode any language or letter irrespective of devices, operating systems, or software.
- Unicode data can be used without generating data corruption in a variety of system.
- The Unicode Standard is completely compatible and synchronized with ISO/IEC 10646.
While Unicode defines the code points, it doesn't dictate how these code points are stored as sequences of bytes in computer memory or files. This is where Unicode Transformation Formats (UTFs) come into play.
Unicode Transformation Formats (UTFs):
It's a standardized method for encoding Unicode characters into a sequence of bytes for storage or transmission. Unicode is a universal character set that aims to represent all written languages, symbols, and emojis, while UTF defines how these characters are stored in binary form.
Common UTF Encoding
UTF-8
- Variable-length encoding (1 to 4 bytes)
- ASCII-compatible (first 128 characters are identical to ASCII)
- Most widely used encoding on the web
Example:
Character: ‘A’
Code point: U+0041
UTF-8: 41
UTF-16
- Uses 16-bit code units (2 or 4 bytes)
- Common in systems like Windows and programming languages like Java
Example (BUS):
00 42 00 55 00 53
UTF-32
- Fixed-length encoding (4 bytes per character)
- Easy indexing (each character has same size)
- Less memory-efficient