A concept hierarchy organizes data into multiple levels of abstraction-ranging from detailed (low-level) values to more general (high-level) concepts. It allows users to drill down for detailed analysis or roll up for summaries, helping simplify large datasets and improving pattern discovery.
Note: Data mining refers to extracting useful patterns, relationships, and knowledge from large datasets using techniques from statistics, machine learning, and AI.
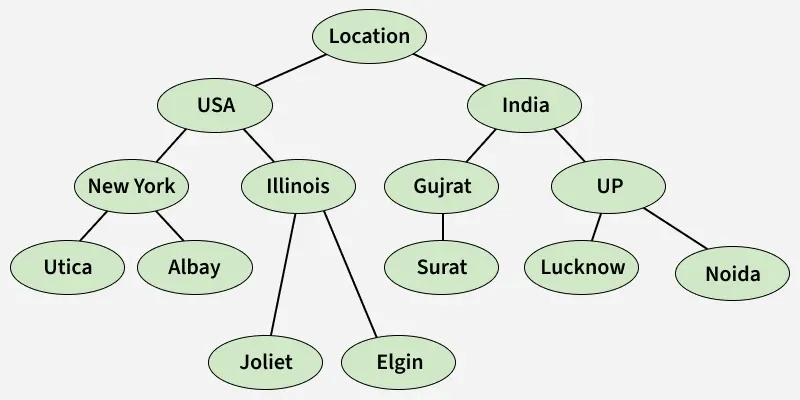
Example of a Concept Hierarchy
The diagram below shows a hierarchy for the Location dimension.
- The root node Location is generalized into Countries (USA, India).
- Countries break into States (New York, Gujarat).
- States further break down into Cities.
Such hierarchies allow a user to analyze data at the level they need—city-level detail or country-level summaries.
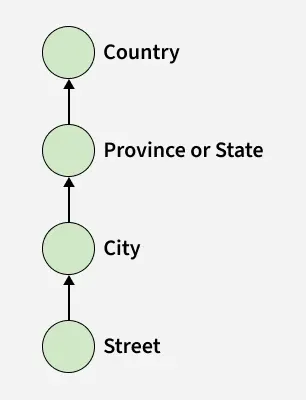
The hierarchical structure represents the abstraction level of the dimension location, which consists of various footprints of the dimension such as:
Applications of Concept Hierarchy
There are several applications of concept hierarchy in data mining, some examples are:
- Data Warehousing: Organizes data into multiple levels (e.g., city → state → country) to improve reporting and OLAP analysis.
- Business Intelligence: Helps analyze customer, sales, and market data at different abstraction levels for better decision-making.
- Online Retail: Structures products into categories and subcategories, making search, navigation, and recommendations easier.
- Healthcare: Groups patient data by diagnosis, treatment, or age range to identify patterns and support clinical analysis.
- Natural Language Processing: Builds topic hierarchies to organize text, detect themes, and extract information from unstructured data.
- Fraud Detection: Groups financial transactions into meaningful levels to spot unusual patterns and detect potential fraud.
Types of Concept Hierarchies
Concept hierarchies can be created in different ways depending on the data and the domain:
1. Schema-Based Hierarchy
Derived from the database schema (e.g., primary key → foreign key relationships). Useful in data warehouses for structuring dimensions such as:
- City → State → Country
- Day → Month → Year
2. Set-Grouping Hierarchy
Groups values based on set membership or category. Useful for:
- Identifying outliers
- Cleaning and preprocessing data
- Example: Product categories → Sub-categories → Items
3. Operation-Derived Hierarchy
Created by applying operations like:
- Aggregation
- Normalization
- Range partitioning
- Example: Age → Age Range (0–12 Child, 13–19 Teen, 20–60 Adult, >60 Senior)
4. Rule-Based Hierarchy
Defined using user-created rules or conditions. Example rule:
- IF income > 10,00,000 → High income; ELSE → Low/Medium income
5. Better Representation of Domain Knowledge
Hierarchies capture real-world relationships (e.g., Product → Brand → Category), making the data model easier to understand.
Types of Concept Hierarchies
1. Explicitly Defined Hierarchies
These are manually designed by domain experts or database designers. Example:
- Department → Faculty → University
2. Implicitly Defined Hierarchies
These are formed automatically based on:
- Attribute values
- Numerical ranges
- Data types
- Relationships in the schema
Methods to Generate Concept Hierarchies
1. Schema-Based Generation: Hierarchy is derived from the database schema itself. Examples:
- Primary key–foreign key relationships
- Aggregation levels already built in star/snowflake schemas
2. Rule-Based Generation: Hierarchies designed using user-defined rules or metadata. Example rule:
- if age < 18 → Young; if 18–60 → Adult; else → Senior
3. Data-Based Generation: Hierarchies created using data distribution. Methods include:
- Clustering
- Binning
- Range partitioning
- Frequency-based grouping
Need of Concept Hierarchy in Data Mining
There are several reasons why a concept hierarchy is useful in data mining:
- Better Data Analysis: Hierarchies organize data into manageable levels, making patterns easier to identify. They support summarization and help analysts look at data from different perspectives.
- Improved Data Exploration & Visualization: Tree-like structures make dashboards more interactive-users can move between summary and detailed views easily through drill-down or roll-up operations.
- Faster and More Accurate Algorithms: Many data mining algorithms work better on generalized data. Hierarchies reduce noise and help algorithms detect clearer patterns.
- Data Cleaning & Preprocessing: Concept hierarchies help identify: Outliers, Inconsistent values and Missing ranges, which leads to cleaner, higher-quality datasets.
- Better Representation of Domain Knowledge: Hierarchies capture real-world relationships (e.g., Product → Brand → Category), making the data model easier to understand.