In this article, we demonstrate how a MapReduce program can process large-scale weather datasets to identify temperature extremes. By harnessing Hadoop’s parallel processing capabilities, program efficiently pinpoints hot and cold days an essential step for climate trend analysis, anomaly detection and building reliable forecasting systems.
Problem Statement
Analyze semi-structured weather data collected by sensors globally. We will focus on temperature values (maximum and minimum) and identify hot days (temperature > 30°C) and cold days (temperature < 15°C) using MapReduce.
Dataset Overview
We used weather data from the NCEI, available in line-based ASCII text format. Each file contains fields like Date, Latitude, Longitude, Max Temp and Min Temp.
FileName: CRND0103-2020-AK_Fairbanks_11_NE.txt. Download the file from here.
Step-by-Step Implementation
This section walks you through the implementation of the MapReduce program to extract hot and cold days from large-scale weather data using Hadoop.
Step 1: Understand Data Format
Below is the example of our dataset where column 6 and column 7 is showing Maximum and Minimum temperature, respectively.

Step 2: Set Up Java Project
Make a project in Eclipse with below steps:
First Open Eclipse -> then, select File -> New -> Java Project -> Name it MyProject -> then, select use an execution environment -> choose, JavaSE-1.8 then, next -> Finish.

In this Project Create Java class with name MyMaxMin -> then, click Finish.

Step 3: Java Source Code
Copy the below source code to this MyMaxMin java class
// Required imports for Hadoop MapReduce
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.conf.Configuration;
// Main class
public class MyMaxMin {
// Mapper class: Extracts max and min temperature from each line
public static class MaxTemperatureMapper extends Mapper<LongWritable, Text, Text, Text> {
// Sentinel value used in dataset to represent missing temperature
public static final int MISSING = 9999;
// Map method called for each line in the input file
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString(); // Convert line to string
if (line.length() != 0) { // Skip empty lines
// Extract date from line (characters 6 to 14)
String date = line.substring(6, 14);
// Extract and trim max and min temperatures
float temp_Max = Float.parseFloat(line.substring(39, 45).trim());
float temp_Min = Float.parseFloat(line.substring(47, 53).trim());
// If max temperature is valid and > 30°C, consider it a hot day
if (temp_Max != MISSING && temp_Max > 30.0) {
context.write(new Text("Hot Day: " + date), new Text(String.valueOf(temp_Max)));
}
// If min temperature is valid and < 15°C, consider it a cold day
if (temp_Min != MISSING && temp_Min < 15.0) {
context.write(new Text("Cold Day: " + date), new Text(String.valueOf(temp_Min)));
}
}
}
}
// Reducer class: Simply passes through the (key, value) pairs from mapper
public static class MaxTemperatureReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// Write each value to the output (usually only one value per key in this case)
for (Text val : values) {
context.write(key, val);
}
}
}
// Driver method: Configures and starts the MapReduce job
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); // Create Hadoop job configuration
Job job = Job.getInstance(conf, "Weather Analysis"); // Initialize job with name
job.setJarByClass(MyMaxMin.class); // Set main class
job.setMapperClass(MaxTemperatureMapper.class); // Set mapper class
job.setReducerClass(MaxTemperatureReducer.class); // Set reducer class
// Set output types for mapper
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// Set input/output formats
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
// Set input and output file paths from command-line arguments
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// Submit job and exit based on completion status
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Step 4: Add External JARs
To ensure imported packages work correctly, you need to add external JAR files to your project. Download the Hadoop Common and Hadoop MapReduce Core JAR files that match your installed Hadoop version.
Check Hadoop version with below command:
hadoop version

Now, to add external jars to MyProject:
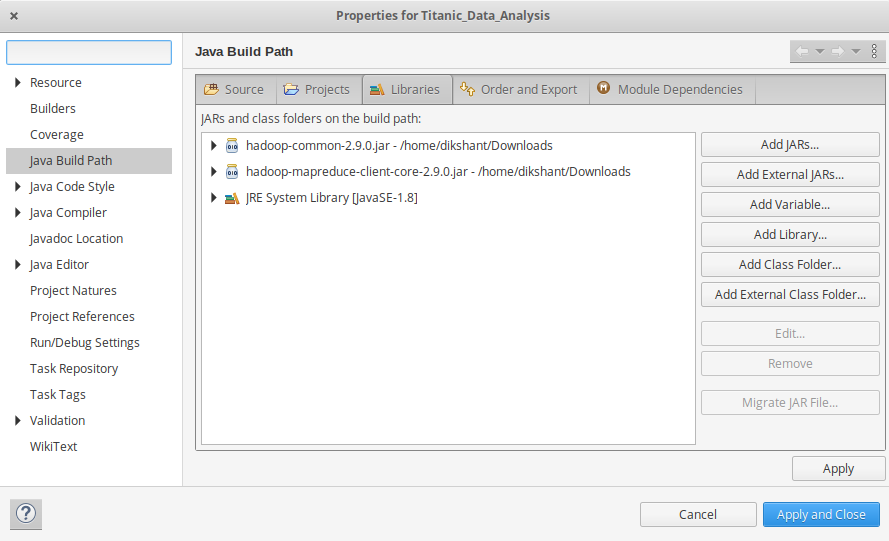
Right Click on MyProject -> then, Build Path -> Click on, Configure Build Path and select Add External jars then Add jars from it's download location then click -> Apply and Close.
Step 5: Export Project as JAR
Now export the project as jar file.
Right-click on MyProject choose Export -> go to, Java -> JAR file -> click, Next then, choose your export destination then click -> Next.

Choose Main Class as MyMaxMin by clicking -> Browse and then click -> Finish -> Ok.

Step 6: Start Hadoop Services
Start HDFS and YARN daemons:
start-dfs.sh
start-yarn.sh
Step 7: Move Dataset to HDFS
Command:
hdfs dfs -put /path/to/CRND0103-2020-AK_Fairbanks_11_NE.txt /
To verify:
hdfs dfs -ls /

Step 8: Run the MapReduce Job
Now Run your Jar File with below command and produce the output in MyOutput File.
Syntax:
hadoop jar /path/to/Project.jar /input_file_in_HDFS /output_directory
Example:
hadoop jar /home/user/Documents/Project.jar /CRND0103-2020-AK_Fairbanks_11_NE.txt /MyOutput

Step 9: View Output
After the MapReduce job completes, you can check the final results through the Hadoop web interface.
Visit:
http://localhost:50070/
Then navigate to: Utilities -> Browse the file system -> /MyOutput -> part-r-00000.


Download the result file.
Step 10: Interpret Output
Each line in the output shows:
- Label: Hot Day or Cold Day
- Date: yyyyMMdd format (e.g., 20200101 = Jan 1, 2020)
- Temperature reading
