Value Iteration and Policy Iteration are two popular techniques used in dynamic programming to solve Markov Decision Processes (MDPs). Both methods aim to find the best possible strategy known as the optimal policy for an agent to follow in a given environment. Understanding the differences, strengths and weaknesses of these two methods is important to choose the right approach for specific RL problems.
What is Value Iteration?
- Value Iteration is an iterative algorithm used to compute the optimal value function
V^*(s) for each state s in an MDP. The value function is a measure of the expected return (reward) from a given state under the optimal policy. - In Value Iteration the Bellman Optimality Equation is used to iteratively update the value of each state until it converges to the optimal value function:
V^*(s) = \max_a \left[ R(s, a) + \gamma \sum_{s'} P(s'|s, a) V^*(s') \right]
Where:
R(s, a) is the immediate reward,P(s'|s, a) is the transition probability,γ is the discount factor ands' represents the next state.
Once the value function converges, the optimal policy can be derived by selecting the action
\pi^*(s) = \arg\max_a \left[ R(s, a) + \gamma \sum_{s'} P(s'|s, a) V^*(s') \right]
What is Policy Iteration?
Policy Iteration is another dynamic programming algorithm used to compute the optimal policy. It alternates between two steps:
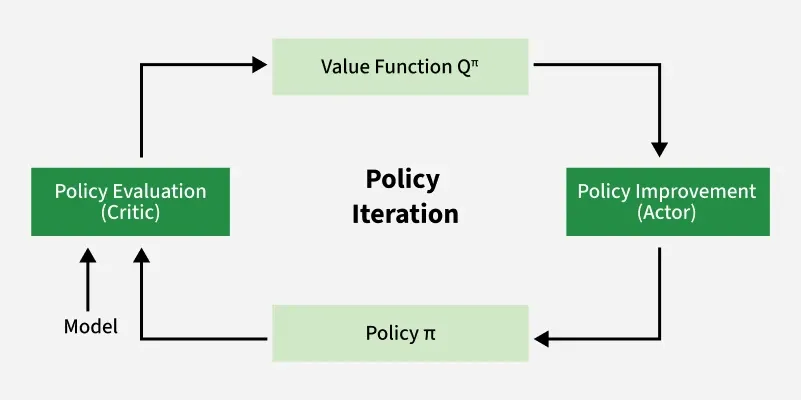
- Policy Evaluation: For a given policy
\pi , the value functionV^\pi(s) is computed using the Bellman Expectation Equation:
V^\pi(s) = R(s, \pi(s)) + \gamma \sum_{s'} P(s'|s, \pi(s)) V^\pi(s')
- Policy Improvement: Once the value function for the current policy is calculated the policy is updated to improve it by selecting the action that maximizes the expected return from each state:
\pi'(s) = \arg\max_a \left[ R(s, a) + \gamma \sum_{s'} P(s'|s, a) V^\pi(s') \right]
This process repeats until the policy converges meaning it no longer changes between iterations.
Comparison Between Value Iteration and Policy Iteration
| Feature | Value Iteration | Policy Iteration |
|---|---|---|
| Approach | Updates the value function iteratively until convergence. | Alternates between policy evaluation and policy improvement. |
| Convergence | Converges when the value function converges. | Converges when the policy stops changing. |
| Computational Cost | More computationally expensive per iteration due to full evaluation of all states. | Requires more iterations but may converge faster in terms of fewer iterations. |
| Policy Output | The policy is derived after the value function has converged. | The policy is updated during each iteration. |
| Speed of Convergence | May require many iterations for convergence, especially in large state spaces. | Tends to converge faster in practice, especially when the policy improves significantly at each iteration. |
| State Space | Typically suited for smaller state spaces due to computational complexity. | Can handle larger state spaces more efficiently. |
When to Use Value Iteration and Policy Iteration
Use Value Iteration:
- When you have a small state space and can afford the computational cost of updating the value function for each state.
- When you want to compute the value function first and derive the policy later.
Use Policy Iteration:
- When you have a larger state space and want to reduce the number of iterations for convergence.
- When you can afford the computational cost of policy evaluation but want faster policy improvement.
Value Iteration is simpler and more direct in its approach and Policy Iteration often converges faster in practice by improving the policy iteratively. The choice between the two methods depends largely on the problem’s scale and the computational resources available. In many real-world applications Policy Iteration may be preferred for its faster convergence especially in problems with large state spaces.