Measures of distance are mathematical functions used to quantify how similar or dissimilar two objects are based on their features. These measures are critical for clustering, classification and information retrieval because they help determine relationships among data points. The choice of distance depends on the nature of the data and the application domain.
- Used to quantify similarity/dissimilarity between objects.
- Smaller distance = higher similarity, larger distance = higher dissimilarity.
- Important for clustering algorithms (e.g., K-means, hierarchical clustering).
- Choice of distance is context-dependent (numerical, categorical or text data).
Let's see few types of distances.
1. Euclidean Distance
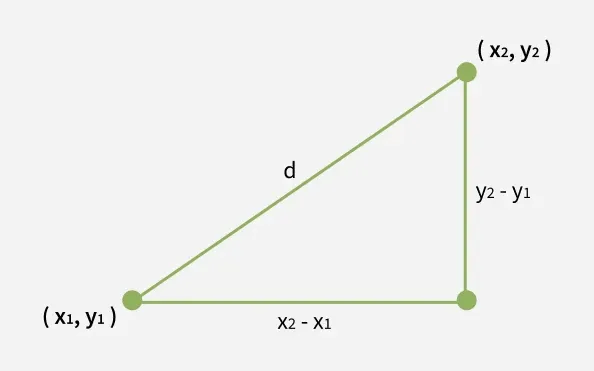
Euclidean distance is considered the traditional metric for problems with geometry. It can be simply explained as the ordinary distance between two points. It is one of the most used algorithms in the cluster analysis.
Formula:
d(x,y) = \sqrt{\sum_{i=1}^n (x_i - y_i)^2}
- Best for: Continuous numerical data (when features are normalized).
- Example: Distance between two cities on a 2D map.
2. Manhattan Distance
Manhattan Distance determines the absolute difference among the pair of the coordinates. Suppose we have two points P and Q to determine the distance between these points we simply have to calculate the perpendicular distance of the points from X-Axis and Y-Axis. In a plane with P at coordinate (x1, y1) and Q at (x2, y2). Manhattan distance between P and Q = |x1 – x2| + |y1 – y2|
Formula:
d(x,y) = \sum_{i=1}^n |x_i - y_i|
- Best for: High-dimensional data or when diagonal movement has no meaning.
- Example: Distance between blocks in a city (taxicab geometry).
3. Jaccard Index

The Jaccard distance is set-based distance that compares dissimilarity by looking at the ratio of unique to common elements.
Formula:
d(A,B) = 1 - \frac{|A \cap B|}{|A \cup B|}
- Best for: Binary or categorical data, especially sets.
- Example: Comparing similarity of shopping carts or tag sets.
4. Minkowski distance
Minkowski distance is a generalized distance measure that includes both Euclidean and Manhattan distances as special cases, controlled by a parameter p.
Formula:
d(x,y) = \left( \sum_{i=1}^n |x_i - y_i|^p \right)^{\frac{1}{p}}
- Best for: Flexible distance calculations where p is tuned.
- Example: For p=1, it becomes Manhattan; for p=2, it becomes Euclidean.
5. Cosine Similarity / Cosine Distance
Measures the cosine distance of the angle between two vectors, focusing on orientation rather than magnitude. Commonly converted to distance as 1−similarity.
Formula(Similarity):
\text{Cosine}(x,y) = \frac{x \cdot y}{||x|| \, ||y||}
Formula(Distance):
d(x,y) = 1 - \frac{x \cdot y}{||x|| \, ||y||}
- Best for: Text mining, NLP, recommendation systems.
- Example: Measuring similarity between two documents regardless of their length.
6. Hamming Distance
The number of positions where two strings (of equal length) differ. Commonly used for error detection and sequence comparison.
Formula:
d(x,y) = \sum_{i=1}^n [x_i \neq y_i]
where [
- Best for: Binary strings, DNA sequences, error correction.
- Example: Hamming distance between “karolin” and “kathrin” = 3.