Multilevel indexing is a technique used when a single-level index becomes too large to store in main memory. To make searching faster and more efficient, the index is divided into multiple levels similar to a tree structure. The multilevel indexing separates the main block into various smaller blocks so that the same data can be stored in a single block.
- It speeds up searching because the system can quickly move through smaller index levels instead of scanning one large index.
- Uses memory efficiently, only when the top-level indexes stay in memory while lower levels remain on disk, making it ideal for large databases.
Need of Multilevel Indexing
- Single-level indexes become too large for big databases and require many disk accesses.
- Multilevel indexing reduces disk I/Os by creating indexes on top of indexes.
- The higher levels of the index remain in memory, reducing the need to read multiple levels from the disk.
- Dividing the index into smaller blocks ensures every block fits in one disk block, reducing access time.
- With fewer blocks to scan, the system can retrieve results more quickly.
- Commonly used in B+ Tree structures, making searches efficient even when the data keeps updating.
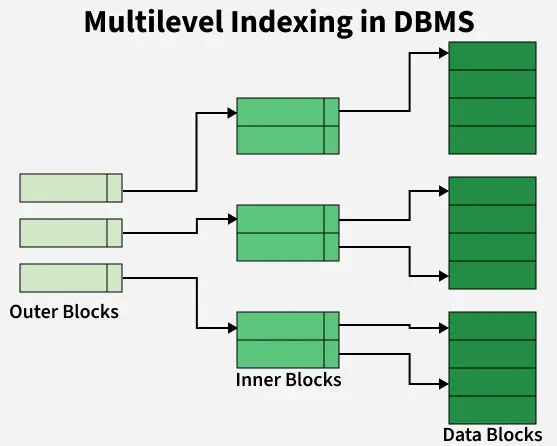
Types of Multilevel Indexing
There are two main types of multilevel indexing are : B-Tree and B+ tree
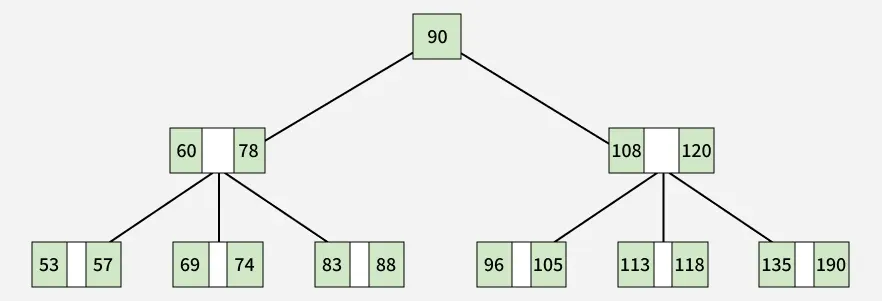
B-Tree
A B-Tree is a specialized m-way tree designed to optimize data access, especially on disk-based storage systems.
- In a B-Tree of order m, each node can have up to m children and m-1 keys, allowing it to efficiently manage large datasets.
- B Trees allow faster data retrieval and updates, making them an ideal choice for systems requiring efficient and scalable data management.
- B Trees deliver consistent and efficient performance for critical operations such as search, insertion, and deletion.
- All leaf nodes in a B-Tree are always at the same level, meaning they have the same depth or height.
- A non-leaf node with n-1 key values should have n non NULL children.
- Keys inside each B-Tree node are stored in ascending sorted order, especially when a node contains multiple keys.
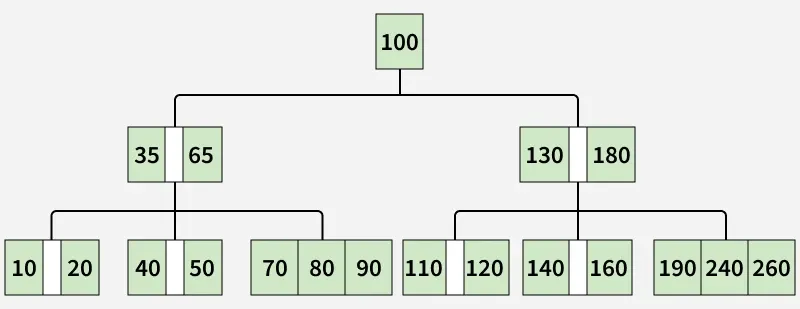
B+ tree
A B+ Tree is an advanced data structure used in database systems and file systems to maintain sorted data for fast retrieval, especially from disk.
- Leaf nodes store all the key values and pointers to the actual data.
- Internal nodes store only the keys that guide searches.
- All leaf nodes are linked together, supporting efficient sequential and range queries.
- B+ trees are balanced, auto-adjusting when data is added or removed to keep search time efficient.
- They are Multi-level, consisting of a root, internal nodes, and leaf nodes that store the actual data.
- B+ trees feature high fan-out, where each node has many children, keeping the tree short and fast.
B Tree vs. B+ Tree
Basis of Comparison | B Tree | B+ Tree |
|---|---|---|
Pointers | All internal and leaf nodes have data pointers | Only leaf nodes have data pointers |
Search | All keys are not available at leaf, search often takes more time. | All keys are at leaf nodes, hence search is faster and more accurate. |
Redundant Keys | No duplicate of keys is maintained in the tree. | Duplicate of keys are maintained and all nodes are present at the leaf. |
Insertion | Insertion takes more time and it is not predictable sometimes. | Insertion is easier and the results are always the same. |
Deletion | Deletion of the internal node is very complex and the tree has to undergo a lot of transformations. | Deletion of any node is easy because all node are found at leaf. |
Leaf Nodes | Leaf nodes are not stored as structural linked list. | Leaf nodes are stored as structural linked list. |
Number of Nodes | Number of nodes at any intermediary level ‘l’ is 2l. | Each intermediary node can have n/2 to n children. |
Application | General balanced trees; less common for indexing | Multilevel indexing, databases (e.g., MySQL InnoDB) for range queries |
Features of Multilevel Indexing
- Hierarchical Structure: Index is arranged in multiple levels (tree-like), reducing the search space step-by-step.
- Efficient Searching: Higher-level indexes reduce the number of disk accesses, making data lookups faster.
- Supports Large Databases: Easily handles very large index files that cannot fit into memory as a single index.
- Reduced Disk I/O: Upper index levels stay in memory, so fewer disk reads are needed.
- Balanced Tree-like Design: Works similar to B-Tree/B+ Tree where all leaf nodes stay at the same level.
- Faster Range Queries: Especially with B+ Trees, it supports quick sequential and range-based searches.
- Supports Dynamic Updates: Can manage insertions and deletions without rebuilding the whole index.
Applications:
- Relational databases: Used to build primary, clustering, and secondary indexes so key lookups and range queries on large tables need only a few block accesses.
- File systems: Multilevel index blocks where a first-level block points to lower-level index blocks, which finally point to data blocks with file contents or metadata.
- Search and information systems: Use multilevel tree-like indexes over sorted lists to support fast term lookup and range-based access on huge datasets.
- Library and catalog systems: Multilevel indexes on fields like title, author, or ID to quickly locate items in large catalogs.
- Data warehousing: In multilevel indexes on large fact tables to speed up range queries, joins, and aggregations instead of doing full table scans.
- Operating systems: Multilevel paging uses a similar hierarchy of page tables to efficiently map large virtual address spaces to physical memory frames.
Comparison with Single-Level Indexing
Single-level indexing is suitable for small datasets, but as the database grows, it becomes inefficient due to high disk I/O. Multilevel indexing overcomes this by organizing indexes into a hierarchical structure, enabling faster and more efficient searches.
- Single-level indexing: high disk I/O, slower searches for large datasets.
- Multilevel indexing: fewer disk accesses, faster searches, and better memory utilization.
Example with Practical Numbers:
Suppose we have a table with 1 million records and a single-level index.
If each index block can hold 100 entries, we would need 10,000 index blocks.
Searching for a record could require reading up to 10,000 disk blocks, which is very slow.
With multilevel indexing, we create a two-level index:
- Level 1 (Top-level index): Contains pointers to level 2 blocks (say 100 entries per block).
- Level 2 (Leaf-level index): Contains the actual key entries.
Now, a search only requires reading 1 top-level block + 1 leaf block, reducing disk accesses to just 2–3 reads.