A Snowflake Schema is a data warehouse modeling technique where dimension tables are normalized into multiple related sub-tables. It is an extension of the Star Schema, designed to handle complex hierarchies and reduce data redundancy. The snowflake effect applies only to dimension tables, not the fact table.
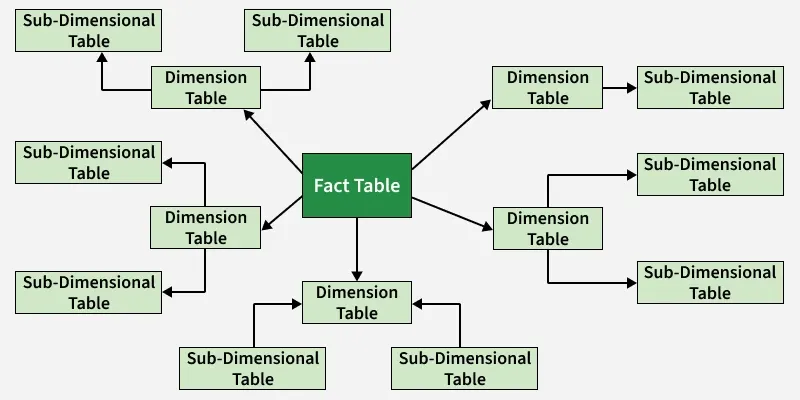
- Dimension tables are normalized into multiple related tables, creating a hierarchical or "snowflake" structure.
- Fact table is still located at the center of the schema, surrounded by the dimension tables. However, each dimension table is further broken down into multiple related tables, creating a hierarchical structure that resembles a snowflake.
For example: a Customer Dimension may contain a CityID that links to a separate City Dimension table storing City, State, Country, etc.
Features of the Snowflake Schema
- Normalization: Snowflake schema uses normalized tables to reduce redundancy and improve consistency.
- Hierarchical Structure: Built around a central fact table with connected dimension tables.
- Multiple Levels: Dimensions can be split into multiple levels, allowing detailed drill-down analysis.
- Joins: Requires more joins, which can slow performance on large datasets.
- Scalability: Scales well for large data, but its complexity makes it harder to manage.
Example of Snowflake Schema
Below is a simplified representation of how a snowflake schema model looks
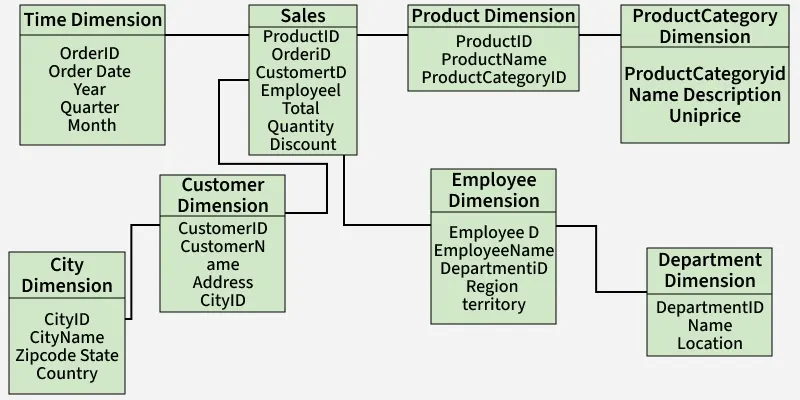
- Employee dimension includes attributes like EmployeeID, Name, DepartmentID, Region, and Territory. DepartmentID links to the Department table, which holds department details like Name and Location.
- Customer dimension includes CustomerID, Name, Address, and CityID. CityID links to the City table, which stores City Name, Zipcode, State, and Country.
- Product dimension includes ProductID, ProductName, ProductCategoryID. ProductCategoryID links to the Product Category Dimension: Category Name, Description, Unit Price.
These hierarchical connections form the "snowflake" structure.
What is Snowflaking
Snowflaking refers to the process of further normalizing a dimension table into additional sub-tables.
For example:
- Customer → City
- Product → Category
- Employee → Department
Although this reduces redundancy, too much snowflaking is discouraged because:
- It increases query complexity.
- It requires more joins.
- It may slow down performance.
Note: Normalization should only be applied where it truly adds value.
Characteristics of Snowflake Schema
- Requires less storage because dimension data is structured.
- Supports multiple hierarchies within a dimension.
- Performance decreases because of extra joins.
- Dimensions can be sourced from different systems and integrated cleanly.
- Good when dimension tables contain attributes at different grains.
Difference Between Snowflake and Star Schema
| Feature | Star Schema | Snowflake Schema |
|---|---|---|
| Dimension Structure | Denormalized | Normalized (multiple levels) |
| Query Performance | Faster (fewer joins) | Slower (more joins) |
| Storage Requirement | Higher | Lower |
| Complexity | Simple | More complex |
| Use Case | Simpler analytics, performance-heavy systems | Complex hierarchies, storage optimization |
Advantages
- Improves data integrity through normalization.
- Reduces redundancy and storage usage.
- Supports detailed hierarchical drill-down.
Disadvantages
- Increased schema complexity.
- More joins, leading to slower query performance.
- Normalization may offer minimal storage savings compared to the entire warehouse.
- Not recommended unless the hierarchy is essential and widely used in queries.