Artificial Neural Networks (ANNs) are computing systems inspired by how the human brain processes information. They use interconnected artificial neurons to analyze data, identify patterns, and make predictions. These networks learn from data over time, enabling them to solve complex problems effectively.
- Inspired by the structure and working of the human brain
- Consist of layers of interconnected artificial neurons
- Process data to identify patterns and relationships
- Learn from experience (training data)
- Used for tasks like prediction, classification and decision making
McCulloch-Pitts Model of Neuron
One of the earliest models of artificial neurons was the McCulloch-Pitts Model introduced in 1943. It is also known as the linear threshold gate.
- The neuron takes multiple inputs, each associated with a weight.
- A weighted sum of the inputs is calculated.
- If the weighted sum exceeds a threshold, the neuron fires (output = 1) otherwise it does not fire (output = 0).
Mathematically this is represented as:
f(y_{\text{in}}) = \begin{cases} 1, & \text{if } y_{\text{in}} \geq \Theta \\ 0, & \text{if } y_{\text{in}} < \Theta \end{cases}
where
y_{\text{in}} = \sum x_i w_i
This model laid the foundation for modern neural networks, though it is limited to solving only linearly separable problems.

Single-Layer Neural Networks (Perceptron)
Single-layer perceptron consists of an input layer and an output neuron that applies a threshold function to determine the final output. The perceptron is a fundamental model for binary classification problems. The perceptron follows this rule:
y = \begin{cases} 1, & \text{if } \sum w_i I_i \geq t \\ 0, & \text{if } \sum w_i I_i < t \end{cases}
- where
t is the threshold
However, a single-layer perceptron cannot solve non-linearly separable problems like XOR. This limitation led to the development of multi-layer perceptrons (MLPs).


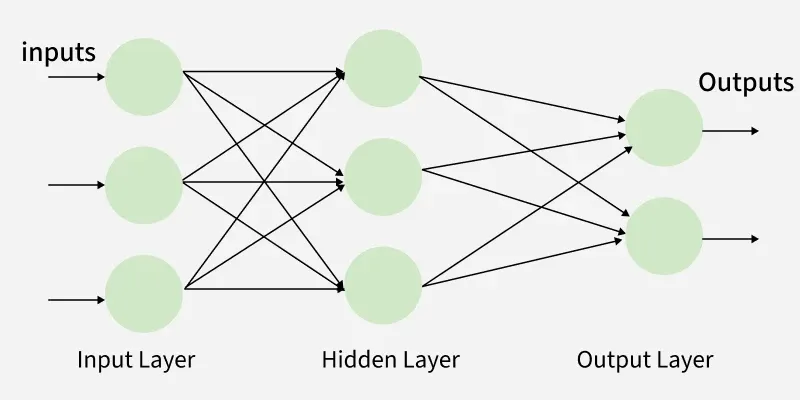
Multi-Layer Neural Networks (MLPs)
A Multi-Layer Perceptron (MLP) consists of:
- Input Layer: receives raw data
- One or more Hidden Layers: extracts features
- Output Layer: produces final predictions
Activation functions introduce non-linearity, allowing ANNs to learn complex patterns. Common activation functions include:
| Function | Formula | Range |
|---|---|---|
| Sigmoid | ||
| Tanh | ||
| ReLU |
Artificial Neural Networks Algorithm
1. Initialize Weights and Bias
The algorithm starts by initializing the weights i.e the strength of connections between neurons and biases which is additional parameters that help to adjust output. These values are usually initialized randomly.
You also set the learning rate (α) which controls how much the weights should be adjusted during training.
2. Feed Input Data
The input data is fed into the input layer of the network. Each input is a feature like an image pixel, a value from a dataset, etc.
3. Forward Propagation (Calculate Output)
The data is passed through the network from the input layer to the hidden layers and finally to the output layer. At each layer the input is multiplied by the weights and passed through an activation function like sigmoid, ReLU, etc to produce the output of that layer. The result is a prediction or an output that is compared to the actual target value.
4. Calculate Error
Once the network has made a prediction the next step is to calculate the error i.e the difference between the predicted output and the actual target. This error is often measured using a loss function like Mean Squared Error or Cross-Entropy.
5. Backpropagation (Update Weights)
Backpropagation computes the gradients i.e how much change in weights would reduce the error by using the chain rule of calculus. The weights and biases are then updated to minimize the error. The update is done using an optimization algorithm like Gradient Descent:
w = w - \alpha \times \frac{\partial \text{Error}}{\partial w}
6. Repeat (Epochs)
Steps 2 to 5 are repeated for multiple epochs which is iterations over the entire training dataset. During each epoch the weights are adjusted to reduce the error gradually.
7. Test the Network
After training, the network is tested with new data to evaluate its performance. If the accuracy is good, the training is considered complete. If not more training or adjustments may be needed.
Advantages
- Noise Resilience: It can handle noisy and incomplete data without affecting their performance. Even if there are errors in the training data they can still produce accurate results.
- Versatility: Used for a wide range of problems from real-valued to discrete-valued functions. They are widely used in image recognition, speech recognition and decision-making.
- Efficiency: Once trained ANNs can evaluate functions very quickly making them ideal for real-time applications like self-driving cars or fraud detection.
- Parallel Processing: Handle large amounts of data through distributed processing similar to how the human brain works.
Limitations
- Overfitting: ANNs can overfit to training data especially when the model is too complex or when there is insufficient data.
- Data Dependency: They require large datasets for training to generalize well.
- Computational Expense: Training deep neural networks can be computationally expensive and time-consuming hence requiring substantial hardware resources.