Asynchronous Advantage Actor-Critic (A3C) uses a shared global network along with multiple worker agents that operate in parallel. Each worker interacts with its own environment, learns independently, and contributes updates to the global model, enabling faster and more stable training.
- A global network maintains shared parameters for both the policy (actor) and value (critic) networks.
- Multiple worker agents run in parallel, each interacting with separate environment instances.
- Workers maintain local copies of the network, collect experiences, and compute updates independently.
- Updates from workers are applied asynchronously to the global network and then synchronized back.
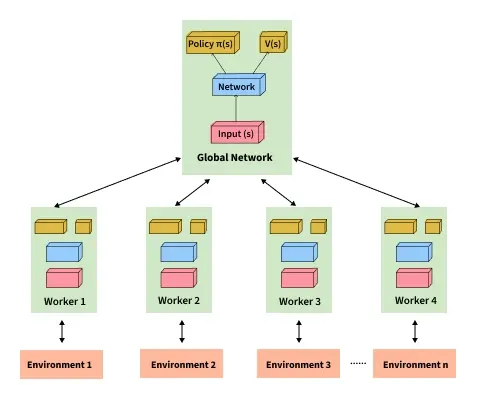
A3C Architecture: Core Elements
1. Asynchronous Training
A3C runs several agents in parallel, each interacting independently with a separate copy of the environment. These workers collect experience at different rates and send updates simultaneously to a central global network. This parallelism helps:
- Speed up training
- Provide diverse experience to avoid overfitting
- Reduce sample correlation (a common issue in reinforcement learning)
2. Actor-Critic Framework
A3C uses two interconnected models:
- Actor: Learns the policy
\pi(a \mid s) which defines the probability of taking action a in state s. - Critic: Learns the value function
V(s) which estimates how good a given state is.
The actor is responsible for action selection, while the critic evaluates those actions to help improve the policy.
3. Advantage Function
Rather than using raw rewards alone, A3C incorporates the advantage function, defined as:
A(s, a) = Q(s, a) - V(s)
This measures how much better (or worse) an action is compared to the expected value of the state. Using this helps:
- Provide clearer learning signals
- Reduce the variance in policy gradient updates.
Mathematical Intuition
The advantage function plays an important role in A3C. When an agent takes an action a in state s, the advantage function tells us whether the reward is better than expected:
- Positive advantage → reinforce this action
- Negative advantage → discourage this action.
A3C uses n-step returns to strike a balance between bias and variance:
- Shorter n → more bias, less variance (quicker updates),
- Longer n → less bias, more variance (smoother updates).
The learning objectives are:
- Actor: Increase the probability of actions with higher advantage,
- Critic: Reduce error in value prediction for better advantage estimation.
How A3C Works
- Experience Collection: Each worker interacts with its environment and collects sequences of states, actions and rewards.
- Advantage Estimation: Workers compute n-step returns and use them to estimate the advantage of each action taken.
- Gradient Calculation: Using the computed advantages, each worker calculates gradients for both the actor and critic networks.
- Asynchronous Update: Workers update the shared global network independently, without waiting for other workers to complete their updates.
This asynchronous approach eliminates bottlenecks that occur in synchronized training and allows continuous updates to the global model.
Performance and Scalability
- Faster training: Multiple agents reduce overall wall-clock time.
- Improved exploration: Independent agents explore different strategies, preventing convergence to suboptimal behavior.
- Reduced sample correlation: Parallel interactions reduce dependency between consecutive samples.
- Stable convergence: Advantage-based updates and multiple asynchronous contributions stabilize the learning process.
Comparisons with Other Algorithms
| Compared With | Key Difference | A3C Advantage |
|---|---|---|
| DQN (Deep Q-Network) | Uses discrete action spaces and suffers from maximization bias | Supports continuous actions, trains faster and avoids Q-learning’s bias |
| Basic Policy Gradient Methods | Can be unstable due to high variance in updates | Combines policy learning with value estimation for more stable training |
| A2C (Advantage Actor-Critic) | Performs synchronized updates | Enables asynchronous updates for better parallelism and training efficiency |
| PPO (Proximal Policy Optimization) | Uses trust-region-like constraints for stable updates | Offers simpler implementation with high speed, though less controlled updates |
Applications
- Game Playing: Achieved superhuman performance on Atari games in significantly less time than DQN.
- Robotics: Multiple agents learn control tasks collaboratively while maintaining exploration diversity.
- Financial Trading: Trading bots explore varied strategies and share insights through a global network.
Limitations
- Stale Gradients: Workers may use outdated global parameters, leading to less effective updates.
- Exploration Redundancy: If multiple agents converge to similar policies, exploration diversity may suffer.
- Hardware Dependency: A3C benefits most from multi-core systems; on single-core machines, its advantages may diminish.