Bagging, Boosting and Stacking are popular ensemble learning approaches used to build stronger and more reliable machine learning models. By combining multiple learners in different ways, these methods help improve accuracy, robustness and generalisation compared to using a single model.
Bagging (Bootstrap Aggregating)
Bagging is an ensemble learning technique that improves model accuracy and stability by training multiple models on different random subsets of the same dataset. It is especially effective for high-variance algorithms like decision trees, helping reduce overfitting and produce more reliable predictions.
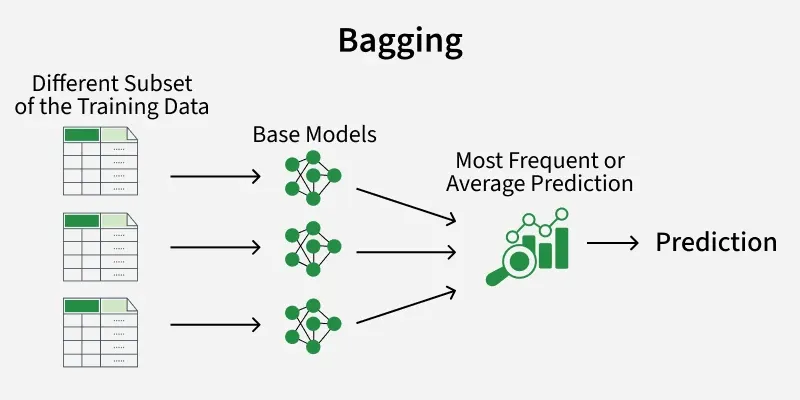
How Bagging Works
1. Bootstrapping: Multiple training subsets are created by randomly sampling the original dataset with replacement. Each subset may contain duplicate records introducing diversity among models.
2. Parallel Training: Independent models of the same type are trained in parallel on each bootstrap sample.
3. Aggregation: Predictions from all models are combined to produce the final output:
- Regression: Average of predictions
- Classification: Majority (hard) voting
Advantages
- Reduces overfitting by averaging multiple models which significantly lowers prediction variance.
- Improves overall model stability and generalization to unseen data.
- Performs well on noisy datasets and algorithms with high variability such as decision trees.
- Supports parallel training, allowing faster computation on multi-core or distributed systems.
- Highly effective when used with tree-based models that are sensitive to data fluctuations.
Limitations
- Model interpretability decreases because predictions are averaged across multiple learners.
- Training and maintaining many models increases computational and memory costs.
- Provides limited benefit for models that already have low variance or high bias.
- Not well suited for real-time or low-resource environments due to its complexity.
Boosting
Boosting is an ensemble learning approach that enhances model accuracy by training weak learners sequentially where each new model focuses on correcting the errors made by earlier ones. By continuously learning from mistakes boosting effectively reduces bias and builds highly accurate predictive models.
- Trains models in a sequential manner with each learner improving upon the previous one
- Emphasizes hard-to-classify data points by assigning them higher importance
- Combines multiple weak learners into a single strong model using weighted aggregation
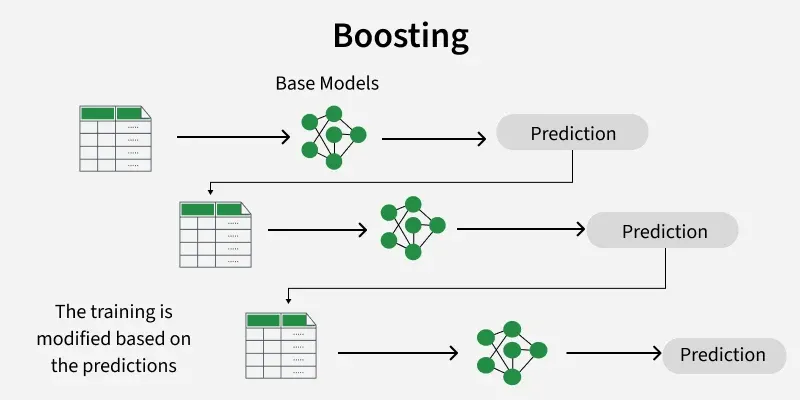
How Boosting Works
Boosting converts multiple weak learners into a single, strong predictive model through a sequential training process that focuses on reducing errors. The key steps are:
- Initialize Weights: Assign equal weights to all training instances to represent their initial importance.
- Sequential Training: Train the first weak learner and evaluate its predictions. Misclassified instances are given higher weights to ensure the next learner focuses on harder cases.
- Iterative Refinement: Repeat the process, with each new learner addressing the mistakes of the current ensemble, gradually improving overall accuracy.
- Aggregate Predictions: Combine outputs from all learners using weighted voting or averaging, giving more influence to models with higher accuracy.
Types of Boosting Algorithms
- AdaBoost: Adjusts data point weights after each iteration and is highly effective for binary classification tasks.
- Gradient Boosting: Trains new models on the residual errors of previous models using gradient descent optimization.
- XGBoost: An optimized and scalable implementation of gradient boosting known for speed and high performance on large datasets.
Advantages
- Effectively reduces bias and significantly improves predictive accuracy.
- Focuses learning on hard-to-classify instances leading to strong performance.
- Flexible and applicable to both classification and regression tasks.
- Often outperforms single models and other ensemble methods on complex datasets.
Limitations
- Sequential training makes boosting computationally expensive and harder to scale.
- Sensitive to noisy data and outliers, which can be overemphasized.
- Higher risk of overfitting if not properly regularized.
3. Stacking
Stacking is an ensemble learning technique that combines predictions from multiple base models to create a stronger, more accurate final model called the meta-model. By using the strengths of diverse models stacking often improves overall performance compared to using a single model.
- Improves predictive accuracy by combining outputs of multiple diverse models
- Uses heterogeneous base learners like decision trees, SVMs and KNN
- Employs a meta-model to learn the best way to combine base model predictions

How Stacking Works
Stacking works by training base models independently and then using their predictions to train a higher-level meta-model. The main steps are:
- Prepare Training Data: Start with the original training dataset containing features and target labels.
- Train Base Models: Train multiple base models independently on the training data.
- Generate Predictions: Each base model makes predictions on validation or out-of-fold data which are collected as new features.
- Train Meta-Model: Use the base model predictions as inputs to a meta-model that learns to optimally combine them.
- Final Prediction: On unseen data base model predictions are fed to the meta-model to produce the final output.
Advantages
- Combines multiple models to achieve higher accuracy than any single model.
- Utilizes different types of models, allowing each to contribute its unique strengths.
- Proper cross-validation helps reduce overfitting by balancing model errors.
- The meta-model learns from mistakes of base models to improve final predictions.
- Flexible in choosing base and meta-models making it adaptable to different datasets and problems.
Limitations
- Implementation is complex and requires careful setup of multiple models.
- Training is slow and computationally intensive due to multiple layers of models.
- Difficult to interpret because of the combination of several models and layers.
- Risk of overfitting if the meta-model is too complex or data leakage occurs.
Bagging vs Boosting vs Stacking
Here we compare different ensemble technique
| Feature | Bagging | Boosting | Stacking |
|---|---|---|---|
| Goal | Reduce variance and prevent overfitting | Reduce bias and improve accuracy | Improve accuracy by combining diverse models |
| Model Type | Homogeneous | Homogeneous weak learners | Heterogeneous |
| Training Approach | Parallel,independent training on bootstrap samples | Sequential correcting previous errors | Parallel base models meta-model combines outputs |
Aggregation Method | Averaging (regression), Majority voting (classification) | Weighted combination based on accuracy | Meta-model learns to combine base predictions |
| Strengths | Stable, simple, parallelizable, good with noisy data | High accuracy, focuses on hard examples | High flexibility can outperform individual models |