Classification in data mining is a supervised learning approach used to assign data points into predefined classes based on their features. By analysing labelled historical data, classification algorithms learn patterns and relationships that enable them to categorize new, unseen data accurately. Let's see some key characteristics about classification:
- Predicts discrete, categorical outputs.
- Learns from labelled datasets using supervised learning.
- Identifies meaningful relationships among features.
- Supports various algorithms based on rules, probability, distance or boundaries.
- Used widely for automation, risk detection and pattern recognition.
Types of Classification Techniques
Classification techniques can be divided into:
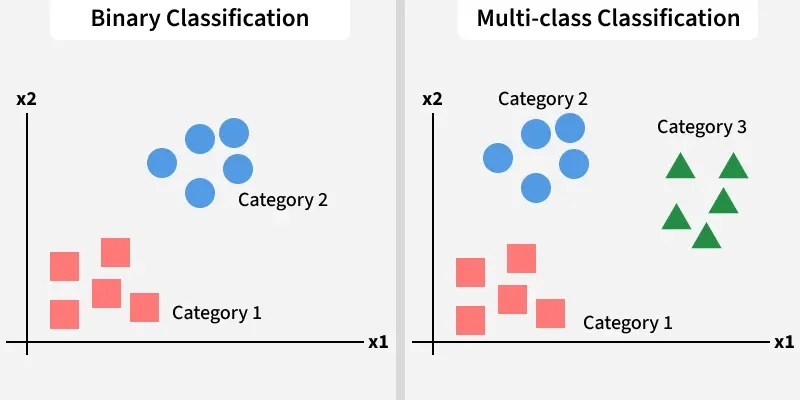
1. Binary Classification: Binary classification assigns data into one of two possible categories. It is commonly used when the outcome is a simple yes/no or true/false decision.
- Used for tasks like spam vs. not spam, disease vs. no disease.
- Simpler decision boundaries and lower computational complexity.
- Can utilize algorithms like Logistic Regression, SVM or Decision Trees.
2. Multi-Class Classification: Multi-class classification deals with problems where the output can belong to more than two categories, requiring more complex decision boundaries.
- Used in image classification, sentiment classification or product categorization.
- Models use strategies like One-vs-One or One-vs-All for separation.
- Algorithms: Random Forests, Neural Networks, Multiclass SVMs.
Building a Classification Model
There are several steps involved in building a classification model, let's understand them:

1. Data Preparation
- Collect, clean and transform raw data into usable form.
- Handle missing values, outliers and convert categorical data as needed.
2. Feature Selection
- Identify the most relevant variables influencing the outcome.
- Use correlation, feature importance scores or domain knowledge.
3. Prepare Train & Test Data
- Split dataset into training and testing portions.
- Helps evaluate generalization and avoid overfitting.
4. Model Selection
- Choose an appropriate algorithm based on data type and complexity.
- Examples: Decision Tree, SVM, Logistic Regression, KNN.
5. Model Training
- Feed training data to the algorithm to learn relationships.
- Parameters adjust to minimize prediction error.
6. Model Evaluation
- Evaluate using the test dataset with metrics like accuracy, precision, recall and F1-score.
- Use confusion matrix or ROC curve for deeper assessment.
7. Model Tuning
- Adjust hyperparameters or switch algorithms to improve accuracy.
- Techniques include grid search and cross-validation.
8. Model Deployment
- Implement the finalized model into production systems.
- Monitor performance over time to detect data drift.
Categorization of Classification
There are different types of classification algorithms based on their approach, complexity and performance. Here are some common categorizations of classification in data mining:
1. Logistic Regression Classification: A statistical model that estimates the probability of class membership using a logistic function. It is efficient, interpretable, and commonly used for binary classification.
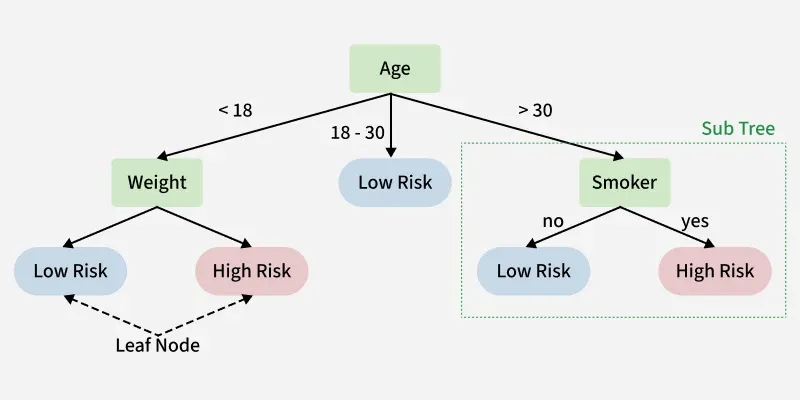
2. Decision Tree Classification: Uses a hierarchical tree structure where internal nodes represent tests on features and leaves represent class labels. Offers high interpretability and works well for mixed data types.
3. Random Forest Classification: An ensemble method that builds multiple decision trees and combines their outputs. It improves accuracy, handles overfitting well and works effectively with large feature sets.
4. Naive Bayes Classification: Based on Bayes’ theorem, it calculates the probability of each class given the input data. Known for simplicity, speed and effectiveness with large datasets.
5. Rule-Based Classification: Generates if–then rules derived from patterns in the dataset. Provides ease of interpretation and transparency in decision-making.
6. Nearest Neighbor (KNN) Classification: k-NN classification classifies new data by comparing it to the k closest existing data points. Effective for non-linear problems but sensitive to noise and scaling.
7. Neural Network Classification: Uses interconnected layers of neurons to learn complex, non-linear relationships. Highly accurate but computationally intensive.
8. Ensemble-Based Classification: Combines multiple weak learners to form a strong predictive model. Improves accuracy, reduces overfitting and handles complex patterns.
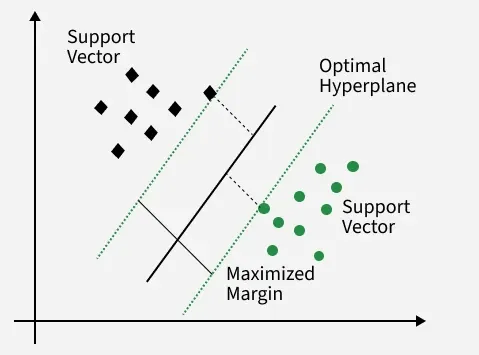
9. Support Vector Machine (SVM) Classification: Finds an optimal boundary (hyperplane) that separates classes. Works well in high-dimensional spaces and supports kernel-based non-linear decision-making.
Classification vs Regression
Let's compare the classification and regression in Data Mining:
| Aspect | Classification | Regression |
|---|---|---|
| Output Type | Categorical labels | Continuous numeric values |
| Example | Spam detection, disease classification | Price prediction, temperature forecasting |
| Decision Basis | Class boundaries | Best-fit line or curve |
| Evaluation Metrics | Accuracy, precision, recall, F1-score | MAE, MSE, RMSE |
| Use Cases | Discrete decision-making | Numeric forecasting and trend estimation |
Applications
- Fraud Detection: Used to classify transactions as fraudulent or legitimate in banking systems.
- Medical Diagnosis: Helps identify diseases based on patient symptoms and medical reports.
- Email & Spam Filtering: Automatically categorizes emails into spam or non-spam.
- Customer Segmentation: Classifies users into behavioural groups to improve marketing strategies.
- Sentiment & Text Classification: Identifies sentiment polarity in reviews, comments and social media posts.
Advantages
- High Predictive Accuracy: Performs effectively across numerous real-world domains.
- Supports Many Algorithms: Flexibility to choose based on data type and complexity.
- Handles Large Datasets: Modern algorithms scale efficiently with big data.
- Offers Interpretability: Decision Trees and Rule-based systems provide transparent decisions.
- Automates Complex Decision Processes: Useful for repetitive, high-volume classification tasks.
Limitations
- Requires Labelled Data: Obtaining quality labels is often expensive and time-consuming.
- Sensitive to Data Quality: Noise, imbalance and missing values reduce accuracy.
- Overfitting Risk: Complex models may memorize training data instead of generalizing.
- Bias Toward Majority Class: Imbalanced data leads to poor minority-class prediction.
- High Computational Costs: Neural networks and SVM can be intensive in training and tuning.