Bias Drift refers to the gradual change in a model’s fairness or bias characteristics over time, even if its overall accuracy remains stable. It means the model’s predictions start to favour or disadvantage certain groups due to evolving real-world conditions.

Here Model A shows stable bias over time, remaining close to its initial value. In contrast, Model B demonstrates significant bias drift, with its bias metric diverging substantially and erratically from its starting point. Bias drift occurs when a model fairness metrics shift over time making it less equitable toward specific groups. Unlike accuracy drift which affects performance bias drift affects ethical behaviour and fairness.
Credit scoring models can become unfair to certain groups of people when the economy changes. For example, big shifts in the market might eventually make the model think some people's income is worth less than it really is.
How to Calculate Bias Drift
Bias Drift can be expressed as the change in a model’s fairness metric over time compared to its baseline value at deployment.
\Delta \text{bias}(t) = f_{\text{bias}}(t) - f_{\text{bias}}(t_0)
where
f_{\text{bias}}(t) : Fairness metric at time tf_{\text{bias}}(t_0) : Baseline fairness metric at deployment\Delta \text{bias}(t) : Change in fairness (drift) since deployment
A larger value of
How to Detect Bias Drift in Machine Learning
Detecting bias drift means checking if a model’s fairness across groups changes over time. Here are some key methods.
1. Monitor Fairness Metrics
Regularly evaluate fairness metrics to identify changes in model behaviour across groups.
- Track metrics like Demographic Parity Difference (DPD), Equal Opportunity Difference (EOD and Disparate Impact Ratio (DIR).
- Compare current values with baseline metrics to detect fairness degradation.
- Consistent deviation from zero or ideal ratios signals bias drift.
2. Statistical Drift Detection
Use statistical methods to find hidden data or prediction shifts that can cause bias drift.
- Apply tests like Kolmogorov Smirnov (KS) and Population Stability Index (PSI).
- PSI > 0.25 or low KS p values indicate significant drift.
- Helps detect changes even before fairness metrics are visibly affected.
3. Explainability Based Monitoring
Monitor how feature importance or model explanations evolve over time.
- Use SHAP or LIME values to analyze changing feature influence.
- A rise in importance of sensitive features suggests potential bias.
- Ensures transparency and early detection of unfair model behaviour.
4. Automated Monitoring Pipelines
Integrate automated tools to continuously track bias and trigger alerts.
- Tools like AWS SageMaker Clarify, IBM Watson OpenScale and Evidently AI support real time bias detection.
- Automate metric computation, reporting and retraining triggers.
- Keeps deployed models fair, transparent and compliant over time.
Step-by-Step Implementation of Bias Drift
Here we used a pretrained model to measure and visualize bias drift over time by tracking fairness metrics across demographic groups and detecting any significant deviation from the baseline fairness.
Step 1: Setup Environment and Imports
- Install and import all required libraries for model inference and data visualization.
- Use Hugging Face transformers to load pretrained models easily.
- Import numpy, pandas and matplotlib for numerical and plotting operations.
!pip install -q transformers
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from transformers import pipeline
import random
Step 2: Load a Pretrained Model
- Select a open source model .
- Use the Hugging Face sentiment analysis pipeline to generate model predictions easily.
- Pretrained models allow bias testing without training from scratch.
nlp = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english")
Output:
Step 3: Define Fairness Metric
- Bias is measured through Demographic Parity Difference (DPD) a standard fairness metric.
- DPD calculates the absolute difference in positive prediction rates between two demographic groups.
- Lower DPD values indicate fairer model behaviour higher values suggest bias.
def demographic_parity_difference(y_probs, sensitive_attr, threshold=0.5):
preds = (np.array(y_probs) >= threshold).astype(int)
g0 = preds[np.array(sensitive_attr) == 0].mean() if (sensitive_attr==0).any() else 0.0
g1 = preds[np.array(sensitive_attr) == 1].mean() if (sensitive_attr==1).any() else 0.0
return abs(g0 - g1)
Step 4: Prepare Baseline Data for Two Sensitive Groups
- Create sample inputs differing only in the sensitive attribute.
- This helps test whether the model treats both groups equally under similar contexts.
- Combine group data into a single dataset with group labels.
- Run the model to calculate the baseline fairness metric.
base_sentences_A = ["He is a doctor.", "He is a teacher.", "He is a leader."]
base_sentences_B = ["She is a doctor.", "She is a teacher.", "She is a leader."]
sentences = (base_sentences_A * 200) + (base_sentences_B * 200)
sensitive_attr = np.array([0]* (len(base_sentences_A)*200) + [1]* (len(base_sentences_B)*200))
probs = []
for out in nlp(sentences, truncation=True, batch_size=32):
prob = out['score'] if out['label'].lower().startswith('pos') else 1 - out['score']
probs.append(prob)
baseline_dpd = demographic_parity_difference(probs, sensitive_attr, threshold=0.5)
print(f"Baseline DPD: {baseline_dpd:.4f}")
Step 5: Simulate Model Predictions Over Time
- Real world data changes continuously so we simulate new data batches over time.
- Each time period represents a new data distribution entering production.
- These batches will help track how fairness evolves across time.
T = 12
time_sentences = []
time_sensitive = []
for t in range(T):
noise_phrase = "" if t < 4 else (" very" if t < 8 else " extremely")
groupA = [f"He is{noise_phrase} a professional." for _ in range(200)]
groupB = [f"She is{noise_phrase} a professional." for _ in range(200)]
time_sentences.append(groupA + groupB)
time_sensitive.append(np.array([0]*200 + [1]*200))
Step 6: Compute Fairness Metrics for Each Time Period
- For each simulated dataset run the pretrained model and compute DPD.
- Collect fairness scores for all time periods in a structured DataFrame.
- Calculate the change in fairness compared to the baseline.
- This quantifies bias drift numerically over time.
dpd_list = []
for t in range(T):
batch = time_sentences[t]
sens = time_sensitive[t]
probs_t = []
for out in nlp(batch, truncation=True, batch_size=64):
prob = out['score'] if out['label'].lower().startswith('pos') else 1 - out['score']
probs_t.append(prob)
dpd_t = demographic_parity_difference(probs_t, sens, threshold=0.5)
dpd_list.append(dpd_t)
df = pd.DataFrame({
'time_period': np.arange(1, T+1),
'DPD': dpd_list
})
df['baseline_DPD'] = df['DPD'].iloc[0]
df['delta_bias'] = df['DPD'] - df['baseline_DPD']
df['abs_delta_bias'] = df['delta_bias'].abs()
df.head()
Step 7: Visualize Bias Drift Over Time
- Plot fairness metric and bias drift trends for better understanding.
- The graph visually highlights fairness deterioration across months.
- A rising bias line indicates an increase in unfairness over time.
plt.figure(figsize=(10,5))
plt.plot(df['time_period'], df['DPD'], marker='o', label='DPD (Fairness Metric)')
plt.plot(df['time_period'], df['delta_bias'], marker='o', linestyle='--', label='Bias Drift (Δbias)')
plt.axhline(df['baseline_DPD'].iloc[0], color='gray', linestyle=':', label='Baseline DPD')
plt.xlabel('Time Period')
plt.ylabel('DPD / Δbias')
plt.title('Bias Drift Over Time (Using Pretrained Model)')
plt.legend()
plt.grid(True)
plt.show()
Output:
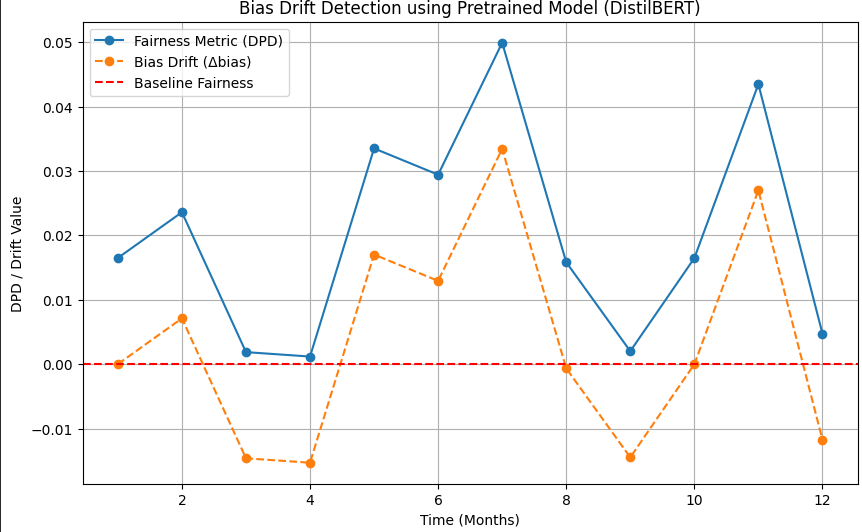
The graph shows how Bias Drift changes over time the blue line (DPD) represents fairness differences between groups, while the orange dashed line (bias) shows deviation from the baseline.
Smaller and stable bias values indicate the model fairness remains consistent with minimal drift.
Step 8: Detect Significant Bias Drift
- After computing and visualizing bias drift, we assess the latest drift value.
- The absolute bias change from the baseline helps decide model stability.
- If bias exceeds the defined threshold, it indicates fairness degradation.
latest_drift = abs(bias_drift[-1])
if latest_drift > 0.05:
print(f"Significant Bias Drift Detected! | Δbias = {latest_drift:.3f}")
else:
print(f"Model Fairness Stable | Δbias = {latest_drift:.3f}")
Output:
You can download full code from here.
Preventing Bias Drift in AI Systems
1. Periodic Model Retraining : Regularly retrain your model with updated, diverse and representative data.
- New data helps the model adapt to evolving real world conditions.
- Automated retraining workflows can be triggered when fairness metrics cross thresholds.
2. Fairness Aware Learning Techniques : Integrate fairness constraints at different stages of the ML pipeline.
- Pre processing: Balance or reweight training samples to ensure equal representation.
- In processing: Add fairness terms to the loss function.
- Post processing: Adjust output thresholds or probabilities to align outcomes across groups.
3. Adaptive Decision Thresholds : Fine tune prediction thresholds dynamically for different demographic groups.
- Helps reduce unfair outcomes when retraining is costly or infeasible.
- Should be treated as a short term mitigation rather than a long term fix.
4. Data and Feature Refinement : Continuously review and improve your dataset and features.
- Remove outdated or biased features that no longer reflect current realities.
- Add new contextual variables to capture real world shifts.
- Helps the model stay both accurate and fair over time.
5. Human and Ethical Oversight : Keep humans in the loop for fairness governance.
- Regularly review fairness reports with data scientists and domain experts.
- Not all bias drift can be fixed technically some require policy or business level interventions.
- Ensures accountability, transparency and trustworthiness.
Types of Drift in Machine Learning
- Concept Drift : The relationship between input features and target variable changes over time.
- Data Drift : The distribution of input features changes, even if the target relationship remains the same.
- Bias Drift : Fairness or bias in model predictions changes over time across sensitive groups.
- Model Drift : The overall model performance degrades over time due to any type of drift .
Challenges
- Hidden Nature: Bias drift often occurs gradually, making early detection difficult.
- Evolving Data: Changing data patterns can unintentionally amplify existing biases.
- Limited Monitoring: Most systems track accuracy but ignore fairness over time.
- Complex Fairness Metrics: Measuring and interpreting bias across groups is challenging.
- Ethical Risks: Drift can lead to unfair or discriminatory model decisions.