Causal Machine Learning (Causal ML) uncovers true cause and effect relationships by combining prediction with causal inference. It goes beyond correlation to understand why outcomes occur and reasons about “what-if” scenarios to enable accurate, interpretable and actionable decisions, helping design better interventions and policies in fields like healthcare, economics and public policy.
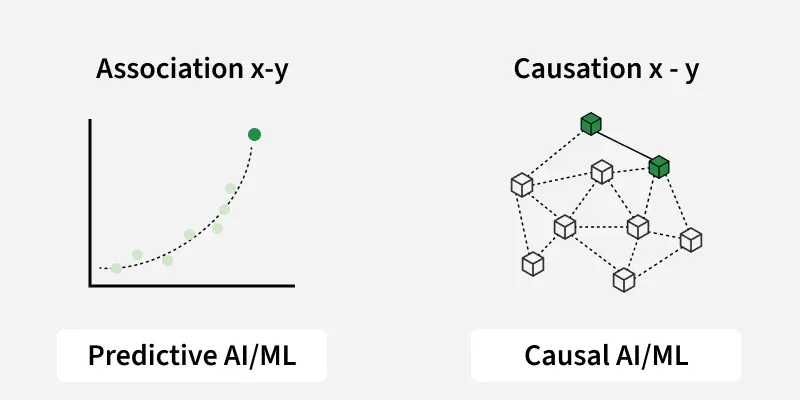
In Predictive ML, we predict outcomes using statistical relationships, whereas in Causal ML, we directly estimate the effects of actions on target outcomes by uncovering and leveraging cause-and-effect relationships.
Causal Inference
Causal Inference focuses on discovering cause and effect relationships rather than simple correlations. It answers questions like
If I change variable X, what will happen to variable Y?
This is crucial in fields such as healthcare, economics and policy where interventions aim to produce specific outcomes
Formal Causal Effect : The causal effect measures the change in outcome due to a change in treatment
\text{Causal Effect} = Y(T+1) - Y(T)
where
- Y(T): Outcome when the original condition is applied.
- Y(T+1): Outcome after applying the treatment or intervention.
Core Ideas in Causal ML
Causal Machine Learning (Causal ML) combines causal inference with machine learning to build models that can reason about cause and effect rather than just correlations. It helps improve robustness, interpretability and decision making in complex real-world problems.
Traditional Machine Learning
- Traditional ML models primarily capture correlations, not true causal relationships, leading to unreliable predictions in dynamic real-world settings.
- They fail under domain shifts, where data from new environments differ from training data.
- Hidden confounders can mislead models by introducing false correlations between unrelated variables.
- ML models struggle with interventions or policy changes, as they cannot reason about cause-and-effect beyond observed patterns.
Causal ML Approaches
- Causal ML bridges the gap between correlation and causation by embedding causal reasoning into machine learning models.
- It identifies true cause-effect relationships, improving robustness and generalization across different environments.
- By controlling for confounders, it ensures more accurate and unbiased causal effect estimation.
- It enables counterfactual and intervention-based predictions, allowing models to simulate the impact of potential actions or policy changes.
Goals of Causal ML
- Models focus on causal features, improving accuracy and robustness even under changing data conditions.
- They enable exploration of “what if” scenarios to reason about alternative outcomes.
- They provide actionable insights for decision-making across healthcare, economics, marketing and policy domains.
- They enhance trust and transparency by grounding predictions in cause and effect reasoning.
Techniques in Causal ML
Causal Machine Learning builds upon several foundational techniques that combine causal reasoning with predictive modeling:
- Causal Supervised Learning: Focuses on learning predictive models that rely on true causal features rather than spurious correlations, ensuring better generalization across different data distributions.
- Causal Data Generation: Creates synthetic data aligned with causal structures, supporting simulations of interventions and counterfactuals.
- Causal Explanations: Provides interpretable insights into model predictions by explaining how changes in specific variables would alter outcomes.
- Causal Fairness: Ensures that model predictions remain unbiased with respect to sensitive attributes such as gender or race by using causal graphs to identify and block discriminatory pathways.
- Causal Reinforcement Learning: Integrates causal reasoning into reinforcement learning agents, improving their policy learning, generalization and sample efficiency.
Step-By-Step Implementation
Here we use the DoWhy library to perform Causal Machine Learning by generating synthetic data, defining a causal graph and estimating the true causal effect of a treatment on an outcome. It identifies, estimates and validates causal relationships using methods like propensity score weighting and instrumental variables to distinguish causation from correlation.
Step 1: Install Required Library
- Install the DoWhy package from Microsoft’s GitHub repository
- It is used for causal inference and effect estimation
!pip install git+https://github.com/microsoft/dowhy.git -q
Step 2: Import Libraries
- Import numpy and pandas for numerical and data operations
- Import CausalModel and datasets from dowhy to create and analyze causal models
- Import statsmodels.api for running regression (OLS) analysis
import numpy as np
import pandas as pd
from dowhy import CausalModel
import dowhy.datasets
import statsmodels.api as sm
Step 3: Generate Synthetic Dataset
- Create a linear causal dataset using DoWhy’s built-in linear_dataset() function
- It automatically includes confounders, treatment, outcome and instruments
- The beta parameter defines treatment effect on outcome
- num_samples specifies the dataset size
data_dict = dowhy.datasets.linear_dataset(
beta=2,
num_common_causes=2,
num_discrete_common_causes=1,
num_instruments=1,
num_samples=5000,
treatment_is_binary=True
)
data_df = data_dict["df"]
Step 4: Dataset Columns
- Displays the available variable names in the dataset
- head() shows the first few rows for a quick overview
print(data_df.columns.tolist())
data_df.head()
Step 5: Define Causal Graph
- Represents relationships among variables using Directed Acyclic Graph (DAG)
- Shows how confounders, treatment and instruments influence outcome
- The graph defines causal assumptions for model identification
- Each arrow indicates the direction of causal influence
causal_graph = """
digraph {
Treatment -> Outcome;
Confounder1 -> Treatment;
Confounder2 -> Treatment;
Instrument1 -> Treatment;
Confounder1 -> Outcome;
Confounder2 -> Outcome;
}
"""
Step 6: Create Causal Model
- Builds a CausalModel object from data and graph structure
- Requires dataset, treatment variable, outcome variable and graph input
- The model is used to identify and estimate causal effects
- Uses DoWhy’s internal graph structure (gml_graph)
causal_model = CausalModel(
data=data_df,
treatment=data_dict["treatment_name"],
outcome=data_dict["outcome_name"],
graph=data_dict["gml_graph"]
)
Step 7: Perform OLS Regression
- Establishes baseline correlation between treatment and outcome.
- add_constant() adds an intercept term for regression.
- OLS() fits an ordinary least squares model.
- Helps compare correlation-based vs causal-based effects.
X = sm.add_constant(data_df[data_dict["treatment_name"]].astype(float))
Y = data_df[data_dict["outcome_name"]].astype(float)
ols_model = sm.OLS(Y, X).fit()
print(ols_model.summary().tables[1])
Output:

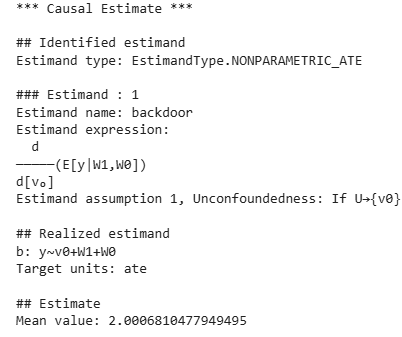
Step 8: Identify Causal Estimand
- Identifies what needs to be estimated to find causal effect.
- Output provides mathematical expression of the estimand.
identified_estimand = causal_model.identify_effect()
print(identified_estimand)
Step 9: Estimate Causal Effect
- Uses propensity score weighting method for estimation.
- Adjusts for confounders affecting both treatment and outcome.
causal_estimate = causal_model.estimate_effect(
identified_estimand,
method_name="backdoor.propensity_score_weighting"
)
print(causal_estimate)
Output:
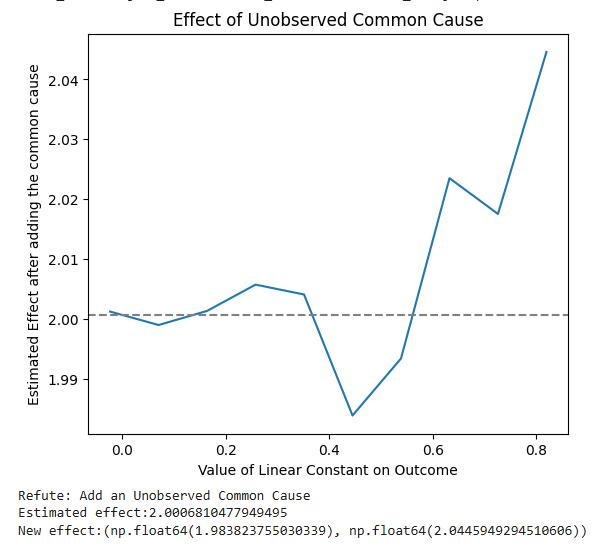
Step 10: Refute the Estimate
- Tests robustness by adding simulated unobserved confounders.
- Verifies if the estimated effect remains stable.
- Output shows whether results are sensitive to confounding.
refutation_test = causal_model.refute_estimate(
identified_estimand,
causal_estimate,
method_name="add_unobserved_common_cause"
)
print(refutation_test)
Output:
Step 12: Estimate Effect Using Instrumental Variable
- Alternative estimation method using instruments.
- Handles cases with unobserved confounding.
- Estimates causal effect via two-stage least squares (2SLS).
- Useful when valid instruments are available.
iv_estimate = causal_model.estimate_effect(
identified_estimand,
method_name="iv.instrumental_variable"
)
print(iv_estimate)
Output:

You can download full code from here.
Applications
- Marketing Decision Making: Helps assess the true impact of campaigns on customer engagement and loyalty, allowing businesses to optimize strategies based on causally effective actions.
- Operational Process Optimization: Identifies inefficiencies in manufacturing, logistics and services by uncovering the causal relationships driving system performance.
- Fraud Prevention: Detects anomalies by focusing on causal dependencies instead of surface-level correlations, leading to more reliable fraud detection.
- Personalization and Recommendations: Explains why users engage with certain products or services, enabling tailored, causally-informed recommendations.
- Healthcare and Policy: Estimates treatment or policy effects while adjusting for confounders, supporting transparent and evidence-based decision-making.
Challenges
- Benchmarking: There is a lack of standardized datasets and evaluation frameworks to consistently measure and compare causal learning methods.
- High-Dimensional Data: Many causal inference techniques face difficulties when dealing with complex data types like images, audio or video.
- Representation Learning: Extracting meaningful causal representations from raw, unstructured data continues to be an open research challenge.
- Counterfactual Reasoning: Efficient computation and validation of counterfactual outcomes within deep learning systems remain non-trivial.
- Integration with RL and Generative Models: Combining causal reasoning with reinforcement learning and generative approaches is still in early stages of development.
- Dynamic and Temporal Causality: Understanding causal relationships that change over time or within evolving systems remains largely underexplored.
Casual ML vs Predictive ML
Here we compare Causal ML and Predictive ML
Parameters | Causal Machine Learning | Predictive Machine Learning |
|---|---|---|
Goal | Understand why something happens (cause-and-effect) | Predict what will happen based on patterns |
Core Idea | Estimating the effect of interventions or actions | Minimizing prediction error on unseen data |
Data Requirement | Needs causal assumptions or structured causal graphs | Needs large amounts of labeled data |
Methods | DoWhy, CausalNex, EconML, propensity scoring, instrumental variables | Regression, classification, deep learning, ensemble methods |
Use Cases | Policy analysis, A/B testing, medical treatment effects, economics | Sales forecasting, image recognition, spam detection, NLP |