K‑Fold Cross Validation is a model evaluation technique that divides the dataset into K equal parts (folds) and trains the model multiple times, each time using a different fold as the test set and the remaining folds as training data. This approach provides a more reliable estimate of model performance compared to a single train‑test split.
- Reduces bias and variance in model evaluation
- Widely used to validate machine learning models for better generalisation

Step 1: Import Required Libraries
- load_iris: Loads a sample classification dataset.
- KFold: Defines the K-Fold splitting strategy.
- cross_val_score: Automatically performs training and validation.
- LogisticRegression: Machine learning model for classification task.
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold, cross_val_score
from sklearn.linear_model import LogisticRegression
Step 2: Load the Dataset
We load the Iris dataset and separate features (X) and target labels (y).
- X contains input features.
- y contains class labels.
data = load_iris()
X = data.data
y = data.target
Step 3: Initialize the Model
Here we will use Logistic Regression as our base model.
model = LogisticRegression(max_iter=200)
Step 4: Configure K Fold Strategy
- n_splits=5: Data divided into 5 folds.
- shuffle=True: Randomizes data before splitting.
- random_state=42: Ensures reproducibility.
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
Step 5: Perform Cross Validation
Now we execute cross validation and compute accuracy for each fold.
- Trains the model 5 times.
- Each time, a different fold acts as the test set.
- Returns accuracy scores for each fold.
scores = cross_val_score(model, X, y, cv=kfold, scoring='accuracy')
Step 6: Print Results
- scores: Accuracy for each fold.
- Mean Accuracy: Final performance estimate.
print("Accuracy scores for each fold:", scores)
print("Mean Accuracy:", np.mean(scores))
Output:
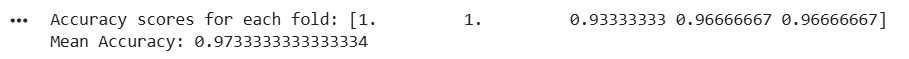
Download full code from here