Dimensionality reduction is a technique used to reduce the number of features in a dataset while preserving important information. It transforms high-dimensional data into a lower-dimensional space for simpler representation.
- Reduces computation time by lowering the number of features
- Helps prevent overfitting by removing irrelevant data
- Improves data visualization and understanding
For example, when you are building a model to predict house prices with features like bedrooms, square footage and location. If you add too many features such as room condition or flooring type, the dataset becomes large and complex.
Working
Lets understand how dimensionality Reduction is used with the help of example. Imagine a dataset where each data point exists in a 3D space defined by axes X, Y and Z. If most of the data variance occurs along X and Y then the Z-dimension may contribute very little to understanding the structure of the data.
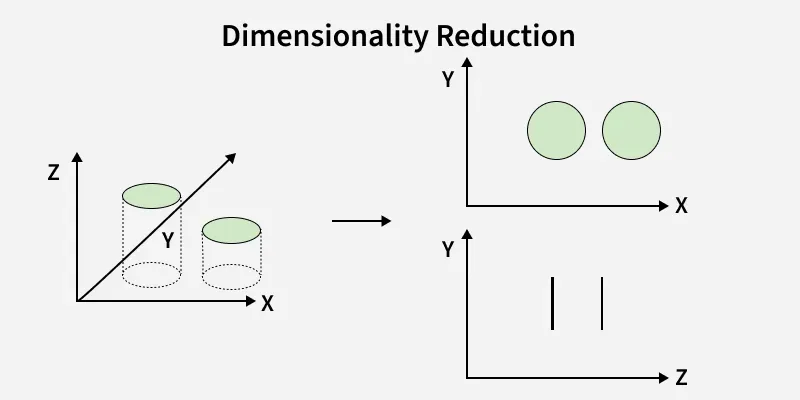
- Before Reduction we can see that data exist in 3D (X,Y,Z). It has high redundancy and Z contributes little meaningful information
- On the right after reducing the dimensionality the data is represented in lower-dimensional spaces. The top plot (X-Y) maintains the meaningful structure while the bottom plot (Z-Y) shows that the Z-dimension contributed little useful information.
This process makes data analysis more efficient hence improving computation speed and visualization while minimizing redundancy
Dimensionality Reduction Techniques
Dimensionality reduction techniques can be broadly divided into two categories:
1. Feature Selection
Feature selection chooses the most relevant features from the dataset without altering them. It helps remove redundant or irrelevant features, improving model efficiency. Some common methods are:
- Filter methods: Rank the features based on their relevance to the target variable.
- Wrapper methods: Use the model performance as the criteria for selecting features.
- Embedded methods: Combine feature selection with the model training process.
- Missing Value Ratio: Variables with missing data beyond a set threshold are removed, improving dataset reliability.
- Backward Feature Elimination: Starts with all features and removes the least significant ones in each iteration. The process continues until only the most impactful features remain, optimizing model performance.
- Forward Feature Selection: It begins with one feature, adds others incrementally and keeps those improving model performance.
- Random Forest: It uses decision trees to evaluate feature importance, automatically selecting the most relevant features without the need for manual coding, enhancing model accuracy.
2. Feature Extraction
Feature extraction involves creating new features by combining or transforming the original features. These new features retain most of the dataset’s important information in fewer dimensions. Common feature extraction methods are:
- Principal Component Analysis (PCA): Converts correlated variables into uncorrelated principal components hence reducing dimensionality while maintaining as much variance as possible enabling more efficient analysis.
- Factor Analysis: Groups variables by correlation and keeps the most relevant ones for further analysis.
- Independent Component Analysis (ICA): Identifies statistically independent components, ideal for applications like ‘blind source separation’ where traditional correlation-based methods fall short.
Real World Use Case
- Text categorization: Reduces feature space (words/phrases) to classify documents accurately from large datasets.
- Image retrieval: Uses visual features like color, texture, and shape to improve search in large image databases.
- Gene expression analysis: Identifies key features to classify samples like leukemia with better speed and accuracy.
- Intrusion detection: Analyzes activity patterns to detect threats by selecting important features for monitoring.
Advantages
- Reduces computation time as models process fewer features.
- Makes data easier to visualize and understand patterns.
- Helps reduce overfitting and improves model generalization.
Disadvantages
- May lead to loss of important information from the data.
- Choosing the right number of dimensions can be challenging.
- Excessive reduction can negatively affect model accuracy.