Decision Trees are classification models that split data into nodes based on feature values. To determine the best split, they rely on impurity metrics that evaluate how mixed a node’s class distribution is. Gini Impurity and Entropy are two measures used in decision trees to decide how to split data into branches. Both help determine how mixed or pure a dataset is, guiding the model toward splits that create cleaner groups.
Need for Impurity Measures
Some common reasons why impurity criteria are essential in decision tree learning are:
- Prevents random or uninformative splits that reduce predictive strength.
- Helps isolate class boundaries for better interpretability.
- Controls node quality and prevents over-growth of branches.
- Reduces classification ambiguity by separating noisy samples.
- Maintains model consistency across varied datasets.
1. Gini Impurity
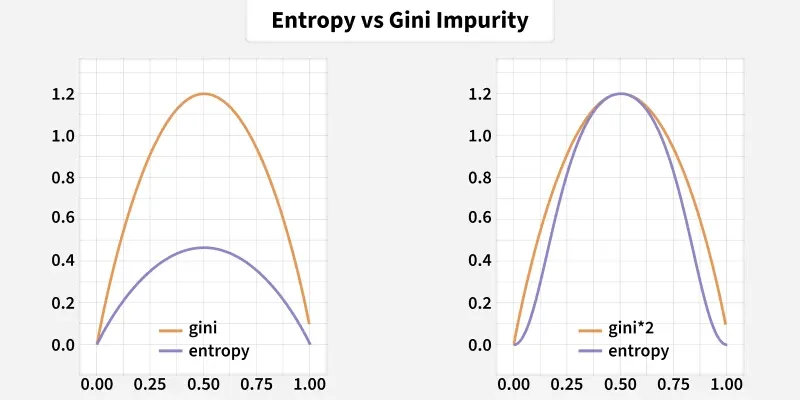
Gini Impurity checks how often a randomly selected sample would be mislabeled if assigned by class probability. It is computationally simple and used in tree-based classifiers.
Formula:
\text{Gini} = 1 - \sum_{i=1}^{n} p_i^2
Where
Properties:
- Lower values indicate cleaner and more homogeneous nodes.
- Nodes become pure when all samples belong to one class.
- Slightly biased toward dominant classes during split selection.
2. Entropy
Entropy measures uncertainty in a node’s class distribution and originates from information theory. Higher entropy indicates greater disorder among class labels.
Formula:
\text{Entropy} = -\sum_{i=1}^{n} p_i \log_{2}(p_i)
Where
Properties:
- Zero entropy corresponds to perfectly pure splits.
- Sensitive to small fluctuations across class ratios.
- Often yields balanced splits with meaningful boundaries.
When To Prefer Which Metric?
Some scenarios where one metric may be more practical are:
Scenario | Gini Impurity | Entropy |
|---|---|---|
Training Speed | Faster computation since it avoids log operations | Slightly slower due to logarithmic calculations |
Split Behavior | Creates splits quickly, favoring dominant classes | Produces more balanced node partitions |
Dataset Size | Efficient for large, high-dimensional datasets | Useful for structured datasets with balanced classes |
Sensitivity to Distribution | Less sensitive to small probability changes | More sensitive to subtle probability differences |
Common Usage | Often default in libraries like CART | Preferred when theoretical information gain matters |
Applications
Some of the use-cases of impurity metrics are:
- Fraud Detection: Helps differentiate legitimate behaviors from suspicious anomalies, supporting real-time financial monitoring.
- Customer Behavior Classification: Enables marketing segmentation by grouping users with similar interaction patterns, improving personalized outreach.
- Medical Predictions: Assists in screening symptoms or diagnostic attributes, allowing healthcare systems to classify risk more accurately.
- Quality Inspection: Detects faulty products by separating normal sensor readings from defective patterns within manufacturing pipelines.
- Document Categorization: Organizes incoming text data into relevant topics, improving search and retrieval efficiency in large content systems.
Advantages
Some benefits of impurity based splitting include:
- Clear Decision Boundaries: Each split expresses a simple logical condition, making the model inherently explainable and easy to visualize.
- Reduced Ambiguity: Sibling branches become more homogeneous, improving consistency across the tree.
- Improved Intermediate Node Quality: Refined node splits reduce the complexity needed in later branches, enhancing learning efficiency.
- Strong Multi-Class Handling: Effectively separates overlapping classes in datasets with multiple labels.
- Flexible Metric Choice: Developers can switch between metrics depending on dataset behavior and performance observations.
Disadvantages
Some disadvantages of impurity metrics are:
- Bias Toward Many Unique Values: Features with many categories may appear informative artificially, leading to misleading splits.
- Sensitivity to Noise and Imbalance: Noisy datasets or skewed class distributions can distort impurity measurements and reduce accuracy.
- Potential for Deep Trees: Without constraints, impurity-driven expansion can increase depth and complexity unnecessarily.
- Need for Pruning: Additional regularization techniques such as pruning or depth limits are required to control overfitting and maintain generalization.