Overfitting occurs when a machine learning model learns the training data too well, including noise and irrelevant patterns, leading to poor performance on new, unseen data. Avoiding overfitting is essential to build models that generalize well and make accurate predictions in real‑world scenarios.
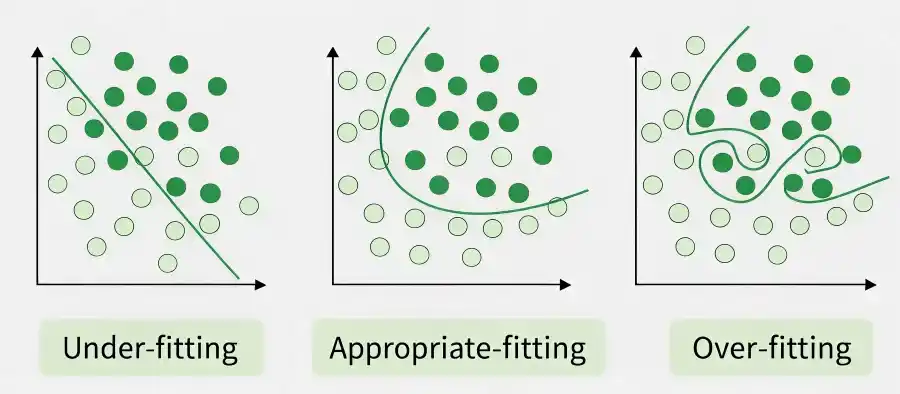
For example: Think of overfitting like a student who memorizes answers instead of understanding concepts. The student may score well on familiar questions but fails when a new question appears. Similarly, an overfitted model struggles with unseen data.
Problems Caused by Overfitting
Overfitting reduces the reliability and practical usefulness of a machine learning model. When a model learns noise instead of true patterns, its real world performance suffers.
- Poor generalization to new data: The model performs well on training data but fails when tested on unseen data.
- Reduced predictive accuracy: Predictions become less accurate outside the training dataset.
- High sensitivity to noise: Even small changes in input data can cause large changes in predictions.
- Memorization instead of learning: The model remembers specific training examples instead of understanding general patterns.
- Increased model complexity: The model becomes harder to understand, maintain and improve.
Causes of Overfitting
Overfitting happens when a model becomes too focused on the training data instead of learning general patterns. This usually occurs due to issues related to model design and data quality.
- Model is too complex: A model with too many parameters can easily fit noise along with real patterns.
- Training data is too small: With limited data, the model may memorize examples instead of learning general rules.
- Noisy data or outliers: If the dataset contains errors or unusual values, the model may try to learn them as real patterns.
- No regularization: Without regularization, there is nothing to control model complexity.
- Irrelevant features: Including unnecessary features increases complexity and makes overfitting more likely.
How to Prevent Overfitting
To prevent overfitting, the main objective is to make the model generalize well to new data instead of memorizing the training set. This can be achieved by controlling model complexity and improving data usage.
- Cross Validation: Instead of evaluating the model on just one split of data, cross validation tests it on multiple splits. This gives a more reliable estimate of performance.
- Proper Data Splitting: Divide the dataset into training, validation, and testing sets. The model learns from the training set, tuning happens on the validation set and final evaluation is done on the test set to check real-world performance.
- Regularization (L1 / L2): Regularization adds a penalty to the model’s loss function. This discourages overly large coefficients and prevents the model from becoming too complex. L1 can remove less important features, while L2 reduces their influence.
- Reduce Model Complexity: Choosing a simpler model with fewer parameters reduces the chance of fitting noise. Complex models are useful but more likely to overfit small datasets.
- Feature Selection Removing irrelevant or redundant features helps the model focus only on meaningful information. Too many unnecessary features increase complexity and variance.
- Ensemble Methods: Techniques like Random Forest combine multiple models to reduce variance. By averaging predictions, ensembles make the final model more stable and less sensitive to noise.