The MNIST dataset is a widely used benchmark in machine learning for handwritten digit recognition. It contains preprocessed handwritten digit images derived from the original NIST dataset, making it suitable for research and experimentation.
- The MNIST dataset consists of 70,000 grayscale images in total.
- It is divided into 60,000 training images and 10,000 testing images.
- Each image represents a single handwritten digit.
- The images have a fixed resolution of 28 × 28 pixels.
- Each image contains 784 numerical features (28 × 28).
- The dataset has a standardized structure with clearly labeled classes.
- It serves as a benchmark dataset for testing classification algorithms.
How the MNIST Dataset Was Created
- The MNIST dataset was created using handwritten digit datasets from the National Institute of Standards and Technology (NIST).
- NIST Special Database 1 (SD-1) contains handwriting samples from U.S. Census Bureau employees, which are generally neat and consistent.
- NIST Special Database 3 (SD-3) includes handwritten digits from high-school students, showing greater variation in writing styles.
- Using SD-1 only for training and SD-3 for testing could introduce bias in model performance.
- To reduce this bias, samples from both datasets were combined and preprocessed (resizing, centering, normalization).
- The final data was split into balanced training and testing sets, forming the MNIST dataset.
MNIST in Machine Learning
The MNIST dataset holds significant value in the field of machine learning for multiple reasons:
- Benchmarking Models: It provides a simple and standardized dataset to evaluate and compare the performance of machine learning and image recognition algorithms.
- Learning and Education: Its small size and simplicity make it ideal for beginners to practice and understand core concepts of machine learning and pattern recognition.
- Research Reference: MNIST remains a widely used reference dataset for testing and validating new algorithms and techniques in machine learning.
Methods to load MNIST dataset in Python
Loading the MNIST dataset in Python can be done in several ways, depending on the libraries and tools you prefer to use. Below are some of the most common methods to load the MNIST dataset using different Python libraries:
Loading MNIST dataset using TensorFlow/Keras
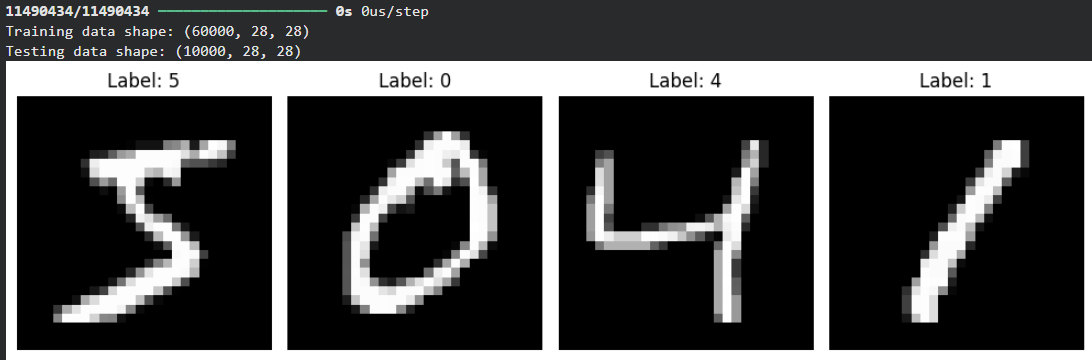
This code shows how to loads the MNIST dataset using TensorFlow/Keras, normalizes the images, prints dataset shapes, and displays the first four training images with their labels.
- Loads the MNIST handwritten digit dataset and splits it into training and testing sets.
- Normalizes pixel values of the images to the range 0–1 by dividing by 255 for better model performance.
- Prints the shapes of the training and testing datasets to verify their dimensions.
- Displays the first four training images with their corresponding digit labels using Matplotlib.
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
import numpy as np
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train / 255.0
X_test = X_test / 255.0
print("Training data shape:", X_train.shape)
print("Testing data shape:", X_test.shape)
plt.figure(figsize=(10, 3))
for i in range(4):
plt.subplot(1, 4, i + 1)
plt.imshow(X_train[i], cmap="gray")
plt.title(f"Label: {y_train[i]}")
plt.axis("off")
plt.tight_layout()
plt.show()
Output:
Loading MNIST dataset Using PyTorch
This code shows how to load the MNIST handwritten digit dataset using PyTorch and visualize a few sample images. It helps in understanding how images and labels are accessed through a DataLoader before training a model.
- Imports required libraries for data loading, tensor transformation and visualization.
- Applies a transformation to convert MNIST images into PyTorch tensors.
- Loads the MNIST training dataset and uses a DataLoader to fetch images in batches.
- Displays a few sample digit images along with their corresponding labels using Matplotlib.
import matplotlib.pyplot as plt
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
def load_mnist(batch_size=5):
transform = transforms.ToTensor()
dataset = datasets.MNIST(
root="./data",
train=True,
download=True,
transform=transform
)
return DataLoader(dataset, batch_size=batch_size, shuffle=True)
def visualize_samples(dataloader, num_samples=5):
images, labels = next(iter(dataloader))
plt.figure(figsize=(15, 3))
for i in range(num_samples):
plt.subplot(1, num_samples, i + 1)
plt.imshow(images[i].squeeze(), cmap="gray")
plt.title(f"Label: {labels[i].item()}")
plt.axis("off")
plt.tight_layout()
plt.show()
train_loader = load_mnist(batch_size=5)
visualize_samples(train_loader)

You can download full code from here
Variants of the MNIST Dataset
- Fashion-MNIST: A grayscale dataset of 10 clothing and accessory categories, used as a more realistic alternative to handwritten digits.
- 3D MNIST: An extension of MNIST with RGB images, suitable for introducing color-based and 3D vision tasks.
- EMNIST: A dataset of handwritten letters (and digits) with the same structure as MNIST, used for character recognition.
- Sign Language MNIST: Images of hand gestures representing English alphabets, used for sign language and gesture recognition.
- Colorectal Histology MNIST: Medical images of colorectal tissue classified into multiple cancer-related categories.
- Skin Cancer MNIST: A medical dataset of skin lesion images used for skin cancer classification and diagnosis.
Applications
The MNIST dataset is widely used for education, benchmarking, and real-world digit recognition tasks.
- Banking: Automatically reads handwritten digits on checks to reduce errors and speed processing.
- Postal Services: Recognizes zip codes on envelopes for faster and accurate mail sorting.
- Document Management: Extracts numbers from invoices, receipts, and forms for automated data entry.
- Retail and Inventory: Identifies handwritten numbers on product labels or stock sheets for efficient inventory management.
Limitations
- Too Simple: The dataset consists of small 28×28 grayscale images which are much simpler than real-world image recognition tasks.
- Limited Variety: Handwriting styles are limited so models trained on MNIST may not generalize well to more complex or diverse datasets.
- Overfitting Risk: Because of its small size deep learning models can easily overfit without proper regularization.
- Not Suitable for Modern Benchmarks: Modern datasets like CIFAR-10, CIFAR-100 and ImageNet provide more complex, color images for evaluating advanced models.
- Lacks Real-World Noise: MNIST images are clean and preprocessed so models trained on it may fail on noisy or unprocessed real-world data.