N shot learning is a machine learning approach that trains models using only N data points per class, where N is very small. It is designed for situations where collecting large datasets is difficult or expensive. The model learns by seeing a few examples just like a human. It enables models to quickly adapt to new tasks especially when training data is scarce, rare or costly to obtain.

The image shows N-shot learning where the prompt includes the user input along with N example cases from a template, helping the LLM learn the pattern and produce the correct output.
How Does N-Shot Learning Work
N-Shot Learning works by training a model to learn new tasks using only a few examples.
- The model is first pre trained on large datasets to learn general patterns.
- This knowledge is transferred when adapting to a new task with limited data.
- Meta learning helps the model learn how to adapt quickly using prior experience.
- A small support set with n examples is used to guide fast learning on the new task.
Why Is N-Shot Learning Important
- It helps models adapt quickly to new categories or domains with minimal data.
- The same model becomes more flexible and reusable across many tasks.
- It reduces the need for extensive retraining and high compute costs.
- By using pre trained knowledge and meta learning, models can perform well even with limited data and limited ML expertise.
Type of N-Shot Learning
1. Zero-Shot Learning
Zero-shot learning is a technique where a model performs a task without seeing any training examples for that task. It uses pre-trained knowledge to understand and classify new, unseen data.
from transformers import pipeline
classifier = pipeline("zero-shot-classification",
model="facebook/bart-large-mnli")
text2 = "Virat Kohli scored a match-winning century against Australia at the Wankhede Stadium."
labels = ["cricket", "politics", "entertainment"]
result2 = classifier(text2, labels)
print("Classification:\n", result2)
Output:

Here we use a pre-trained model to classify sentences into labels without any task-specific training. The model predicts the most suitable label based purely on its general language understanding, demonstrating zero-shot learning.
2. One-Shot Learning
One-shot learning allows a model to learn from a single example per class. It is useful when labeled data is limited and the model must generalize from just one instance.
import numpy as np
import openai
from openai import OpenAI
from sklearn.metrics.pairwise import cosine_similarity
client = OpenAI(api_key="YOUR_OpenAI_API_KEY")
def get_embedding(text):
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return np.array(response.data[0].embedding)
def one_shot_classify(query, support_examples):
query_emb = get_embedding(query)
best_class = None
best_score = -1
for cls, example in support_examples.items():
example_emb = get_embedding(example)
score = cosine_similarity([query_emb], [example_emb])[0][0]
print(f"Similarity with {cls}: {score:.4f}")
if score > best_score:
best_class = cls
best_score = score
return best_class
support_set = {
"Sports": "A football match was played yesterday.",
"Technology": "New AI chips are becoming faster.",
"Food": "This recipe requires tomatoes and spices."
}
query_text = "Nvidia released a new graphics processor."
predicted = one_shot_classify(query_text, support_set)
print("\nPredicted class:", predicted)
Output:
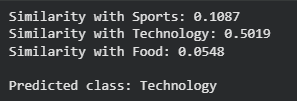
The model uses a support set with one example per class and computes embeddings for the query and each example. It predicts the class with the highest cosine similarity, demonstrating one-shot learning in action.
3. Few Shot Learning
Few-shot learning allows a model to learn from a small number of examples per class typically 2–10. It is useful when limited labeled data is available but slightly more than one-shot examples are present.
import numpy as np
import openai
from openai import OpenAI
from sklearn.metrics.pairwise import cosine_similarity
client = OpenAI(api_key="YourOpenAi_API_KEY")
def get_embedding(text):
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return np.array(response.data[0].embedding)
def few_shot_classify(query, support_examples):
query_emb = get_embedding(query)
best_class = None
best_score = -1
for cls, examples in support_examples.items():
example_embs = np.array([get_embedding(ex) for ex in examples])
class_emb = np.mean(example_embs, axis=0)
score = cosine_similarity([query_emb], [class_emb])[0][0]
print(f"Similarity with {cls}: {score:.4f}")
if score > best_score:
best_class = cls
best_score = score
return best_class
support_set = {
"Sports": [
"A football match was played yesterday.",
"The cricket team won the tournament."
],
"Technology": [
"New AI chips are becoming faster.",
"Quantum computing is the future."
],
"Food": [
"This recipe requires tomatoes and spices.",
"Pasta is cooked with fresh ingredients."
]
}
query_text = "Intel announced a new AI processor."
predicted = few_shot_classify(query_text, support_set)
print("\nPredicted class:", predicted)
Output:
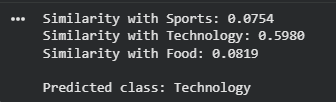
The model uses a support set with a few examples per class. It computes embeddings for the query and averages embeddings of each class. The class with the highest similarity to the query is returned, demonstrating few-shot learning.
You can download full code from here.
Advantages
- Requires very few labeled samples making it ideal for low-data scenarios.
- Enables quick adaptation to new classes or tasks.
- Reduces training time and computational cost.
- Improves model reusability across different domains.
- Works well in real-world cases where data collection is expensive.
Challenges
- Difficult for models to generalize from extremely small datasets.
- Highly sensitive to noisy or incorrectly labeled examples.
- Requires strong pre-training or meta-learning frameworks.
- Struggles when classes have high intra-class variation.
- Risk of overfitting due to limited support examples.