A Tensor Processing Unit (TPU) is Google’s custom chip built only for AI tasks. Unlike GPUs that handle graphics and general computing, TPUs focus purely on fast tensor and matrix operations used in neural networks. As AI grows across areas like robotics, healthcare, and language models, TPUs deliver the speed, efficiency, and scaling needed for training large, modern AI systems.
Why TPUs Matter:
- Built exclusively for matrix operations, tensor operations, and deep-learning kernels
- Offers significantly higher performance-per-watt than CPUs and GPUs
- Scales efficiently to thousands of chips for massive AI model training
- Optimized for TensorFlow, JAX, XLA, and Google’s Pathways runtime
Key Differentiators (Compared to GPUs)
1. Systolic Array Core
- A systolic array processes data in a rhythmic pipeline, reducing memory access and boosting efficiency. This structure allows TPUs to execute large matrix multiplications at extremely high throughput.
2. Precision Optimization (bfloat16)
TPUs use bfloat16, a numeric format that keeps FP32-level range but uses fewer bits.
Benefits:
- Half the memory footprint
- 2× processing speed
- Near-zero accuracy loss
3. Massive Scalability
- Thousands of TPUs can connect using Google’s optical ICI fabric, forming TPU Pods capable of exascale computing. This enables training of trillion-parameter models with near-linear scaling.
TPU Core Specifications
| Specification | Details |
|---|---|
| Developer | Google (with Broadcom; manufactured by TSMC) |
| Initial Release | 2015 (internal)/ 2016 (public) |
| Latest Version | Ironwood (v7) – 10× compute over v5p |
| Architecture | Systolic array with MXU + SparseCore |
| Datatypes | bfloat16, int8, FP32 accumulation |
| Memory | Up to 192 GB HBM3e per chip |
| Interconnect | Up to 3.2 Tbps per chip |
| Deployment | Cloud TPUs, TPU Pods (9,216 chips max), limited on-prem |
Note: TPUs routinely deliver 4–5× better performance per watt than equivalent GPUs on LLMs and recommendation workloads.
TPU Architecture
TPUs deliver high performance through a tightly integrated hardware–software stack. Components like the MXU, bf16 precision, and high-bandwidth memory work alongside compilers such as XLA and the Pathways runtime to maximize AI throughput.
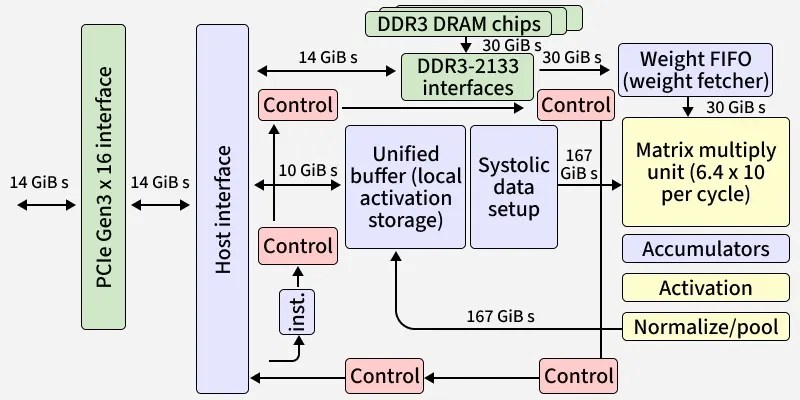
1. Systolic Array & MXU (Matrix Multiply Unit)
The MXU is the core of every TPU typically a 128×128 or 256×256 grid of arithmetic units. It processes data in a rhythmic, “heartbeat-like” flow:
- Weights move vertically
- Activations move horizontally
- Results accumulate in FP32
Why it matters:
This systolic flow drastically reduces memory access and improves energy efficiency by 50–70% compared to conventional architectures.
2. bfloat16 Precision (bf16)
TPUs use bfloat16, a lightweight floating-point format that keeps the FP32 range but cuts mantissa bits.
Benefits:
- Uses half the memory
- Delivers 2× higher throughput
- <1% accuracy impact across most deep learning tasks
bf16 is now the default precision for TensorFlow, JAX, and TPU compilers.
3. Memory Hierarchy
TPUs employ a multi-tiered memory system designed to feed data to MXUs without bottlenecks:
- HBM3e: Up to 5.2 TB/s bandwidth
- On-chip CMEM: High-speed unified buffer (e.g., 128 MiB)
- SparseCore: Specialized engine for large embedding tables
This makes TPUs ideal for LLMs, recommender systems, and multimodal models that require massive memory throughput.
4. TPU Pod & High-Speed Interconnect
TPUs can be linked to form large clusters known as TPU Pods.
Key components:
- ICI (Inter-Chip Interconnect): Up to 3.2 Tbps per chip
- Optical circuit switches: Enable dynamic scaling across racks
- Pathways runtime: Coordinates distributed execution over 10,000+ chips
- This architecture enables near-linear scaling for training trillion-parameter models.
How a TPU Works
TPUs follow a highly optimized workflow that ensures maximum throughput during training and inference. Here’s how the execution pipeline operates:
1. Compilation
The XLA compiler converts the model graph into fused, hardware-optimized operations tailored for the TPU’s systolic arrays. This reduces overhead and maximizes parallel execution.
2. Data Input
"tf.data" pipelines efficiently load, preprocess, and shard data across TPU hosts, ensuring each core receives a balanced workload with minimal latency.
3. Matrix Computation
The MXUs perform large matrix multiplications in synchronized “waves.”
For example, a 128×128 block completes in just a few cycles, enabling massive parallelism.
4. Synchronization
During training, gradient updates are combined using ultra-fast all-reduce operations over TPU ICI links, ensuring model parameters stay synchronized across thousands of chips.
5. Output Serving
For inference, the Pathways runtime dispatches requests and delivers results with low latency, enabling fast, scalable model serving.
Advantages of TPUs
TPUs offer several key benefits that make them highly effective for large-scale AI workloads:
- High Throughput: Optimized for large Transformer and CNN workloads; Trillium TPUs train Gemma-2 27B up to 4× faster than v5e.
- Energy Efficiency: Ironwood (v7) TPUs deliver up to 2× lower inference energy usage, making large-scale AI more sustainable.
- Cost Efficiency: TPU Pods offer up to 1.8× better performance-per-dollar compared to v5e TPUs.
- Strong Ecosystem Integration: Native support for TensorFlow, JAX, and vLLM ensures seamless model optimization and scaling.
Limitations of TPUs
- Ecosystem Lock-In: TPUs deliver their best performance only within Google’s ecosystem, especially TensorFlow/JAX; PyTorch via XLA still lags behind CUDA.
- Underutilization on Irregular Workloads: Models with sparse or non-matrix-heavy operations (e.g., graph neural networks) may achieve <50% utilization of the MXU.
- Limited Hardware Availability: TPUs are mostly cloud-only, with no consumer hardware versions and restricted on-prem deployments.
- Vendor & Supply Dependency: TPU production relies heavily on TSMC fabrication cycles, which can affect availability during high-demand periods.
Real-World Use Cases
Training Large Language Models (LLMs):
- Ironwood TPU superpods power next-gen models like Gemini 3.0, enabling significantly faster multimodal training and inference.
Scientific & Biological Computing:
- AlphaFold 4 uses TPUs for exascale protein-folding simulations, accelerating drug discovery and molecular research.
Image & Video Generation Models:
- Creative AI systems like Imagen 3 and Veo achieve 35% faster generation and up to 45% lower cost when running on Trillium TPUs.
Enterprise AI Deployment:
- Companies such as Midjourney and Anthropic report 3× higher throughput and drastically lower inference costs for large-scale production workloads.
Personalization & Recommendation Engines:
- SparseCore accelerators boost performance on massive embedding tables, making TPUs ideal for e-commerce, ads ranking, and content recommendation.