- Courses
- Tutorials
- Interview Prep
GATE DA Machine Learning Quiz
Question 1
Let the minimum, maximum, mean and standard deviation values for the attribute income of data scientists be₹ 46000, ₹170000, ₹96000, and₹ 21000, respectively. The z - score normalized income value of ₹106000 is closest to which ONE of the following options ?
0.217
0.476
0.623
2.304
Question 2
The naive Bayes classifier is used to solve a two-class classification problem with class-labels y1, y2. Suppose the prior probabilities are P(y1) = 1/3 and P(y2) = 2/3. Assuming a discrete feature space with P(x|y1) = 3/4 and P(x|y2) = 1/4 for a specific feature vector x. The probability of misclassifying x is __________. (Round off to two decimal places)
0.20
0.60
0.40
0.80
Question 3
Given data {(−1, 1), (2, −5), (3, 5)} of the form (x, y), we fit a model y = wx using linear least-squares regression. The optimal value of w is ______________. (Round off to three decimal places)
0.356
0.46
0.286
0.467
Question 4
Given a dataset with 𝐾 binary-valued attributes (where 𝐾>2) for a two-class classification task, the number of parameters to be estimated for learning a naïve Bayes classifier is
2k+1
2K+1
2k+1+1
K2+1
Question 5
Consider the two neural networks (NNs) shown in Figures 1 and 2, with 𝑅𝑒𝐿𝑈 activation (𝑅𝑒𝐿𝑈(𝑧) = max{0, 𝑧}, ∀𝑧 ∈ ℝ). ℝ denotes the set of real numbers. The connections and their corresponding weights are shown in the Figures. The biases at every neuron are set to 0. For what values of 𝑝, 𝑞, 𝑟 in Figure 2 are the two NNs equivalent, when 𝑥1 ,𝑥2 , 𝑥3 are positive?
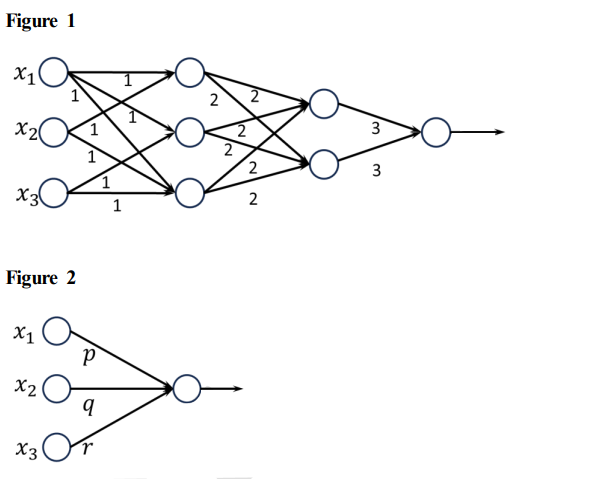
(A) 𝑝 = 36, 𝑞 = 24,𝑟 = 24
(B) 𝑝 = 24, 𝑞 = 24,𝑟 = 36
(C) 𝑝 = 18, 𝑞 = 36,𝑟 = 24
(D) 𝑝 = 36, 𝑞 = 36,𝑟 = 36
Question 6
Consider the following figures representing datasets consisting of two-dimensional features with two classes denoted by circles and squares.

Which of the following is/are TRUE?
(i) is linearly separable
(ii) is linearly separable
(iii) is linearly separable
(iv) is linearly separable
Question 7
Details of ten international cricket games between two teams “Green” and “Blue” are given in Table C. This table consists of matches played on different pitches, across formats along with their winners. The attribute Pitch can take one of two values: spin-friendly (represented as 𝑆) or pace-friendly (represented as 𝐹). The attribute Format can take one of two values: one-day match (represented as 𝑂) or test match (represented as 𝑇).
A cricket organization would like to use the information given in Table C to develop a decision-tree model to predict outcomes of future games between these two teams.
To develop such a model, the computed Information Gain(C, Pitch) with respect to the Target is ______ (rounded off to two decimal places). (GATE DA 2024 MCQ) [2 Marks]
Table C
Match Number | Pitch | Format | Winner(Target) |
|---|---|---|---|
1 | S | T | Green |
2 | S | T | Blue |
3 | F | O | Blue |
4 | S | O | Blue |
5 | F | T | Green |
6 | F | O | Blue |
7 | S | O | Green |
8 | F | T | Blue |
9 | F | O | Blue |
10 | S | O | Green |
0.34
0.12
0.56
0.78
Question 8
Given the two-dimensional dataset consisting of 5 data points from two classes (circles and squares) and assume that the Euclidean distance is used to measure the distance between two points. The minimum odd value of 𝑘 in 𝑘-nearest neighbor algorithm for which the diamond (⋄) shaped data point is assigned the label square is ______ (GATE DA 2024 MCQ)[2 Marks]

5
4
6
3
Question 9
Consider the dataset with six datapoints: [Tex](x_1, y_1), (x_2, y_2),...,(x_6, y_6)[/Tex], where [Tex]x_1 = \begin{bmatrix} 1 \\ 0 \end{bmatrix}[/Tex], [Tex]x_2 = \begin{bmatrix} 0 \\ 1 \end{bmatrix}[/Tex], [Tex]x_3 = \begin{bmatrix} 0 \\ -1 \end{bmatrix}[/Tex], [Tex]x_4 = \begin{bmatrix} -1 \\ 0 \end{bmatrix}[/Tex], [Tex]x_5 = \begin{bmatrix} 2 \\ 2 \end{bmatrix}[/Tex], [Tex]x_6 = \begin{bmatrix} -2 \\ -2 \end{bmatrix}[/Tex] and the labels are given by [Tex]y_1 = y_2 = y_5 = 1[/Tex], and [Tex]y_3 = y_4 = y_6 = -1[/Tex]. A hard margin linear support vector machine is trained on the above dataset. Which ONE of the following sets is a possible set of support vectors?
{𝒙𝟏 , 𝒙𝟐 ,𝒙𝟓 }
{𝒙𝟑 , 𝒙𝟒 ,𝒙𝟓 }
{𝒙𝟒 , 𝒙𝟓 }
{𝒙𝟏 , 𝒙𝟐 ,𝒙𝟑 , 𝒙𝟒}
Question 10
Match the items in Column 1 with the items in Column 2 in the following table:
Column 1 | Column 2 |
|---|---|
(p) Principal Component Analysis | (i) Discriminative Model |
(q) Naïve Bayes Classification | (ii) Dimensionality Reduction |
(r) Logistic Regression | (iii) Generative Mode |
(A)(p) − (iii), (q) − (i), (r) − (ii)
(B) (p) − (ii), (q) − (i), (r) − (iii)
(C) (p) − (ii), (q) − (iii), (r) − (i)
(D) (p) − (iii), (q) − (ii), (r)− (i)
There are 19 questions to complete.