Machine learning in R enables building predictive models, discovering patterns and gaining insights using statistical methods and modern algorithms. With its rich set of packages, R supports the complete workflow from data preparation to model evaluation and visualization.
Working of Machine Learning in R
The basic steps involved in a machine learning project using R include:
- Data Cleaning: Use packages like tidyverse and dplyr to clean and prepare the data.
- Algorithm Selection: Choose algorithms available in R packages such as caret, randomForest, e1071, nnet and many others.
- Model Training: Train models using R functions like train() from the caret package or specific model functions like lm(), glm() or rpart().
- Prediction: Make predictions using predict() functions on the trained models.
- Evaluation: Evaluate model performance using metrics provided by packages like caret, yardstick and visualization packages like ggplot2.
Classification Of Machine Learning in R
Machine learning implementations are classified into 3 major categories, depending on the nature of learning.
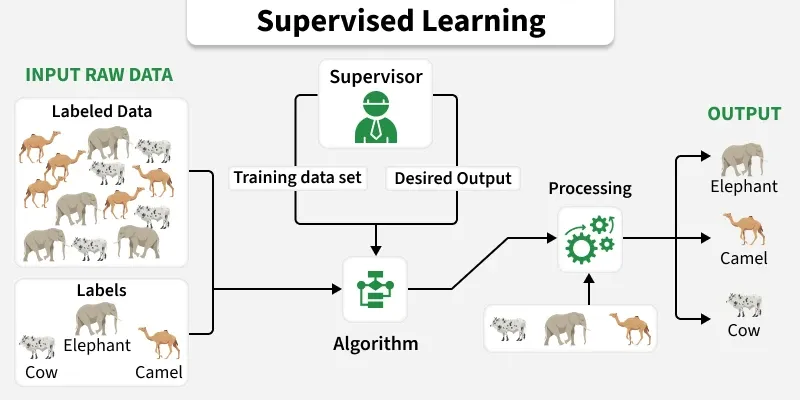
1. Supervised Learning in R
In Supervised learning, we train the model using labeled data that already contains the correct outputs. The algorithm learns patterns from this training data and uses them to make predictions on new, unseen data. In R, supervised learning involves building such models using various packages and built-in functions
Example: You can use the rpart package to create a decision tree model to classify fruits based on attributes like color and shape.
Packages and Functions:
- caret : train()
- rpart : rpart()
- e1071 : svm()
- nnet : multinom()
Types of Supervised Learning
- Classification: Predicts categories (e.g., spam or not spam) using logistic regression (glm() with family=binomial), decision trees (rpart()) or random forests (randomForest()).
- Regression: Predicts continuous outcomes (e.g., house prices) using functions like lm() or caret : train() with regression models.
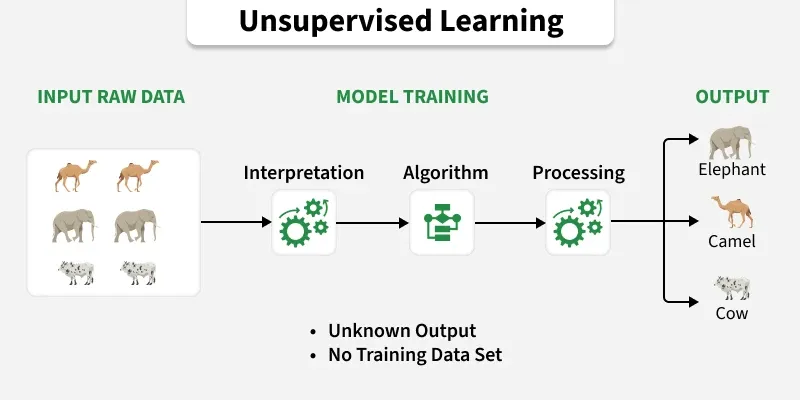
2. Unsupervised Learning in R
Unsupervised learning is the training of machines using information that is not labeled and it works without any guidance. Here the main task of the machine is to separate the data using the similarities, differences and patterns without any prior supervision. Hence unsupervised learning is performed on unlabeled data where the model identifies patterns and structures on its own.
Example:
- Use kmeans() to group customers into clusters based on their similarity in features like age, income or spending habits. Each cluster represents customers who share common patterns.
- Use agnes() for hierarchical clustering, which builds a tree-like structure showing how groups of similar customers are progressively merged based on their similarity
Packages and Functions:
- stats : kmeans()
- cluster : agnes()
- factoextra for visualizing clusters
- arules : apriori() for association rule mining
Types of Unsupervised Learning:
- Clustering: Grouping similar data points using kmeans() or hierarchical clustering.
- Association: Finding rules with arules : apriori() to identify co-occurring items.
3. Reinforcement Learning in R
The reinforcement learning method is all about taking suitable action to maximize reward in a particular situation. While reinforcement learning is not as heavily supported as supervised and unsupervised learning, R still offers packages such as ReinforcementLearning for basic implementations.
Example: Use the ReinforcementLearning package to train an agent for optimal decision-making based on reward feedback.

Some main points in reinforcement learning:
- Input: Initial environment state.
- Output: Possible actions.
- Training: Learn policies based on reward signals.
Types of Machine Learning Problems in R
- Regression: Used to predict continuous numeric values based on input data. Example: Predicting house prices based on area, location and amenities using lm() or caret : train().
- Classification: Assigns inputs into predefined categories or classes. Example: Classifying emails as "spam" or "not spam" using randomForest() or svm().
- Clustering: Groups similar data points together based on patterns in the data. Example: Segmenting patients based on their medical readings using kmeans() or agnes().
- Association: Identifies relationships between items or events that frequently occur together. Example: Market basket analysis to find items often bought together using apriori().
- Anomaly Detection: Detects unusual or abnormal patterns in data. Example: Identifying fraudulent credit card transactions using anomalize.
- Sequence Mining: Discovers patterns in sequential data. Example: Predicting next webpage clicks in a user's browsing session using TraMineR.
- Recommendation: Suggests items to users based on their behavior or preferences. Example: Recommending movies or songs based on past user interactions using recommenderlab.
Popular R Packages
- caret: Unified interface for model training and evaluation.
- randomForest: Implements Random Forest algorithms.
- e1071: Support Vector Machines (SVM), Naive Bayes, etc.
- xgboost: Gradient boosting machine learning.
- glmnet: Regularized regression (LASSO, Ridge).
- rpart: Decision tree models.
- DataExplorer: Automates exploratory data analysis.
- Dalex: Model explanations.
- dplyr and janitor: Data cleaning and transformation.
- ggplot2: Data visualization.
Example of Machine Learning Applications in R
- Voice Assistants: Siri, Alexa, Google Assistant for speech recognition
- Social Media: Friend suggestions and content recommendations
- Customer Support: Chatbots for automated assistance
- Gaming: Intelligent and adaptive non-player characters
- Recommendations: Product and content suggestions
- Fraud Detection: Identifying unusual or suspicious activities
- Healthcare: Disease prediction and data analysis
- Traffic Alerts: Real-time traffic updates and route suggestions
- Real-world Example: YouTube recommends similar videos based on your search history.
Advantages of Using Machine Learning in R
- Concise, readable and expressive code.
- Powerful statistical modeling capabilities.
- Extensive package ecosystem for every ML stage.
- Superior data visualization options.
- Active community support and documentation.