Theory of Computation uses Finite Automata (DFA/NFA) to recognize regular languages, but these models are not powerful enough to represent all programming languages. Languages like C, Pascal, Haskell, and C++ require more complex computational models due to their structured grammars.
- Finite Automata (DFA/NFA) are used to recognize regular languages in TOC
- Not all programming languages can be represented using finite automat
- DFA and NFA recognize only regular languages in the Chomsky hierarchy
- More powerful models are needed for complex languages
- Turing Machines provide this power, but are hard to visualize
- L-graphs offer a simpler and more visual alternative
L-graphs extend finite automata concepts to represent context-free languages. To understand L-graphs better, let’s examine an example of a language that cannot be represented by DFAs or NFAs.
Example Language
The language
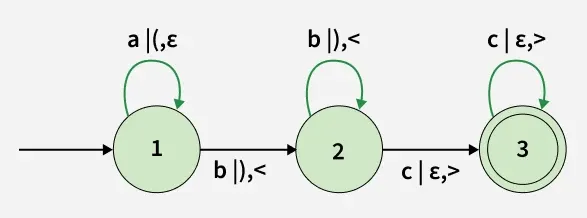
Structure of L-Graphs
An L-graph possesses two key features:
- Bracket Groups: L-graphs have up to two independent bracket groups that do not depend on input symbols.
- Dyck Language Compliance: Both bracket groups must form a valid string from a Dyck language for the input string to be accepted.
Essentially, an L-graph is a modified finite automaton with added bracket groups.
How L-Graphs Accept Strings
Consider the following transitions:
- abc:
\{\varepsilon, \varepsilon, \varepsilon\} \rightarrow \{a, (, \varepsilon\} \rightarrow \{ab, (), <\} \rightarrow \{abc, (), <>\}
- a²b²c²:
\{\varepsilon, \varepsilon, \varepsilon\} \rightarrow \{a, (, \varepsilon\} \rightarrow \{aa, ((, \varepsilon\} \rightarrow \{aab, ((), <\} \rightarrow \{aabb, (()), <<\} \rightarrow \{aabbc, (()), <<>\} \rightarrow \{aabbcc, (()), <<>>\}
- a⁵b⁵c⁵:
\{\varepsilon, \varepsilon, \varepsilon\} \rightarrow \{a, (, \varepsilon\} \rightarrow \dots \rightarrow \{aaaaa, (((((, \varepsilon\} \rightarrow \{aaaaab, (((((), <\} \rightarrow \dots \rightarrow \{aaaaabbbbb, ((((())))), <<<<<\} \rightarrow \{aaaaabbbbbc, ((((())))), <<<<<>\} \rightarrow \dots \rightarrow \{aaaaabbbbbccccc, ((((())))), <<<<<>>>>>\}
Definitions Related to L-Graphs
1. Neutral Path: A path in the L-graph is called neutral if both bracket strings are right-balanced.
2. Nest: If a neutral path T can be represented as: T = T1T2T3 where T1 and T3 are cycles and T2 is a neutral path, then T is called a nest.
3. (ω, d)-Core
A (ω, d)-core in an L-graph G, defined as Core(G, ω, D), is a set of (ω, d)-canons.
A (ω, d)-canon is a path that contains at most:
- m <= ω neutral cycles
- k <= d nests
where each path segment follows:
4. Context-Free L-Graph: An L-graph is context-free if it has only one bracket group. All rules in the L-graph follow one of the two structures:
['symbol' \mid 'bracket', ?] ['symbol' \mid ?, 'bracket']
Dyck Language
A Dyck language consists of two disjoint alphabets,
Example:
A real-life application of L-graphs can be seen in hierarchical structures such as XML parsing and dependency graphs.
Scenario:
- The main graph represents the company’s departments (Sales, Marketing, Finance, HR, etc.).
- The L-graph represents managerial relationships, where each vertex is a manager and edges show supervisory relationships.
This representation helps in understanding:
- Chain of command
- Decision-making processes