Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements
| Lists: | pgsql-hackers |
|---|
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2023-12-15 19:07:29 |
| Message-ID: | CANtu0oiLc-+7h9zfzOVy2cv2UuYk_5MUReVLnVbOay6OgD_KGg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, hackers!
I think about revisiting (1) ({CREATE INDEX, REINDEX} CONCURRENTLY
improvements) in some lighter way.
Yes, a serious bug was (2) caused by this optimization and now it reverted.
But what about a more safe idea in that direction:
1) add new horizon which ignores PROC_IN_SAFE_IC backends and standbys queries
2) use this horizon for settings LP_DEAD bit in indexes (excluding
indexes being built of course)
Index LP_DEAD hints are not used by standby in any way (they are just
ignored), also heap scan done by index building does not use them as
well.
But, at the same time:
1) index scans will be much faster during index creation or standby
reporting queries
2) indexes can keep them fit using different optimizations
3) less WAL due to a huge amount of full pages writes (which caused by
tons of LP_DEAD in indexes)
The patch seems more-less easy to implement.
Does it worth being implemented? Or to scary?
[1]: https://postgr.es/m/20210115133858.GA18931@alvherre.pgsql
[2]: https://postgr.es/m/17485-396609c6925b982d%40postgresql.org
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2023-12-15 21:11:59 |
| Message-ID: | CAEze2WgW6pj48xJhG_YLUE1QS+n9Yv0AZQwaWeb-r+X=HAxU_g@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 15 Dec 2023, 20:07 Michail Nikolaev, <michail(dot)nikolaev(at)gmail(dot)com>
wrote:
> Hello, hackers!
>
> I think about revisiting (1) ({CREATE INDEX, REINDEX} CONCURRENTLY
> improvements) in some lighter way.
>
> Yes, a serious bug was (2) caused by this optimization and now it reverted.
>
> But what about a more safe idea in that direction:
> 1) add new horizon which ignores PROC_IN_SAFE_IC backends and standbys
> queries
> 2) use this horizon for settings LP_DEAD bit in indexes (excluding
> indexes being built of course)
>
> Index LP_DEAD hints are not used by standby in any way (they are just
> ignored), also heap scan done by index building does not use them as
> well.
>
> But, at the same time:
> 1) index scans will be much faster during index creation or standby
> reporting queries
> 2) indexes can keep them fit using different optimizations
> 3) less WAL due to a huge amount of full pages writes (which caused by
> tons of LP_DEAD in indexes)
>
> The patch seems more-less easy to implement.
> Does it worth being implemented? Or to scary?
>
I hihgly doubt this is worth the additional cognitive overhead of another
liveness state, and I think there might be other issues with marking index
tuples dead in indexes before the table tuple is dead that I can't think of
right now.
I've thought about alternative solutions, too: how about getting a new
snapshot every so often?
We don't really care about the liveness of the already-scanned data; the
snapshots used for RIC are used only during the scan. C/RIC's relation's
lock level means vacuum can't run to clean up dead line items, so as long
as we only swap the backend's reported snapshot (thus xmin) while the scan
is between pages we should be able to reduce the time C/RIC is the one
backend holding back cleanup of old tuples.
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
> [1]: https://postgr.es/m/20210115133858.GA18931@alvherre.pgsql
> [2]: https://postgr.es/m/17485-396609c6925b982d%40postgresql.org
>
>
>
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2023-12-17 20:14:27 |
| Message-ID: | CANtu0oizNtPUrPB0Mh+2vyjdijTX=LZvO5_dZN3+NqvE-CFPtw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
> I've thought about alternative solutions, too: how about getting a new snapshot every so often?
> We don't really care about the liveness of the already-scanned data; the snapshots used for RIC
> are used only during the scan. C/RIC's relation's lock level means vacuum can't run to clean up
> dead line items, so as long as we only swap the backend's reported snapshot (thus xmin) while
> the scan is between pages we should be able to reduce the time C/RIC is the one backend
> holding back cleanup of old tuples.
Hm, it looks like an interesting idea! It may be more dangerous, but
at least it feels much more elegant than an LP_DEAD-related way.
Also, feels like we may apply this to both phases (first and the second scans).
The original patch (1) was helping only to the second one (after call
to set_indexsafe_procflags).
But for the first scan we allowed to do so only for non-unique indexes
because of:
> * The reason for doing that is to avoid
> * bogus unique-index failures due to concurrent UPDATEs (we might see
> * different versions of the same row as being valid when we pass over them,
> * if we used HeapTupleSatisfiesVacuum). This leaves us with an index that
> * does not contain any tuples added to the table while we built the index.
Also, (1) was limited to indexes without expressions and predicates
(2) because such may execute queries to other tables (sic!).
One possible solution is to add some checks to make sure no
user-defined functions are used.
But as far as I understand, it affects only CIC for now and does not
affect the ability to use the proposed technique (updating snapshot
time to time).
However, I think we need some more-less formal proof it is safe - it
is really challenging to keep all the possible cases in the head. I’ll
try to do something here.
Another possible issue may be caused by the new locking pattern - we
will be required to wait for all transaction started before the ending
of the phase to exit.
[1]: https://postgr.es/m/20210115133858.GA18931@alvherre.pgsql
[2]: https://www.postgresql.org/message-id/flat/CAAaqYe_tq_Mtd9tdeGDsgQh%2BwMvouithAmcOXvCbLaH2PPGHvA%40mail.gmail.com#cbe3997b75c189c3713f243e25121c20
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2023-12-17 23:53:34 |
| Message-ID: | CAEze2Wi3BFLkFBcZ+Brfbr-mGBCcWXcWuHucnCnw5ZOQotc6Eg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, 17 Dec 2023, 21:14 Michail Nikolaev, <michail(dot)nikolaev(at)gmail(dot)com> wrote:
>
> Hello!
>
> > I've thought about alternative solutions, too: how about getting a new snapshot every so often?
> > We don't really care about the liveness of the already-scanned data; the snapshots used for RIC
> > are used only during the scan. C/RIC's relation's lock level means vacuum can't run to clean up
> > dead line items, so as long as we only swap the backend's reported snapshot (thus xmin) while
> > the scan is between pages we should be able to reduce the time C/RIC is the one backend
> > holding back cleanup of old tuples.
>
> Hm, it looks like an interesting idea! It may be more dangerous, but
> at least it feels much more elegant than an LP_DEAD-related way.
> Also, feels like we may apply this to both phases (first and the second scans).
> The original patch (1) was helping only to the second one (after call
> to set_indexsafe_procflags).
>
> But for the first scan we allowed to do so only for non-unique indexes
> because of:
>
> > * The reason for doing that is to avoid
> > * bogus unique-index failures due to concurrent UPDATEs (we might see
> > * different versions of the same row as being valid when we pass over them,
> > * if we used HeapTupleSatisfiesVacuum). This leaves us with an index that
> > * does not contain any tuples added to the table while we built the index.
Yes, for that we'd need an extra scan of the index that validates
uniqueness. I think there was a proposal (though it may only have been
an idea) some time ago, about turning existing non-unique indexes into
unique ones by validating the data. Such a system would likely be very
useful to enable this optimization.
> Also, (1) was limited to indexes without expressions and predicates
> (2) because such may execute queries to other tables (sic!).
Note that the use of such expressions would be a violation of the
function's definition; it would depend on data from other tables which
makes the function behave like a STABLE function, as opposed to the
IMMUTABLE that is required for index expressions. So, I don't think we
should specially care about being correct for incorrectly marked
function definitions.
> One possible solution is to add some checks to make sure no
> user-defined functions are used.
> But as far as I understand, it affects only CIC for now and does not
> affect the ability to use the proposed technique (updating snapshot
> time to time).
>
> However, I think we need some more-less formal proof it is safe - it
> is really challenging to keep all the possible cases in the head. I’ll
> try to do something here.
I just realised there is one issue with this design: We can't cheaply
reset the snapshot during the second table scan:
It is critically important that the second scan of R/CIC uses an index
contents summary (made with index_bulk_delete) that was created while
the current snapshot was already registered. If we didn't do that, the
following would occur:
1. The index is marked ready for inserts from concurrent backends, but
not yet ready for queries.
2. We get the bulkdelete data
3. A concurrent backend inserts a new tuple T on heap page P, inserts
it into the index, and commits. This tuple is not in the summary, but
has been inserted into the index.
4. R/CIC resets the snapshot, making T visible.
5. R/CIC scans page P, finds that tuple T has to be indexed but is not
present in the summary, thus inserts that tuple into the index (which
already had it inserted at 3)
This thus would be a logic bug, as indexes assume at-most-once
semantics for index tuple insertion; duplicate insertion are an error.
So, the "reset the snapshot every so often" trick cannot be applied in
phase 3 (the rescan), or we'd have to do an index_bulk_delete call
every time we reset the snapshot. Rescanning might be worth the cost
(e.g. when using BRIN), but that is very unlikely.
Alternatively, we'd need to find another way to prevent us from
inserting these duplicate entries - maybe by storing the scan's data
in a buffer to later load into the index after another
index_bulk_delete()? Counterpoint: for BRIN indexes that'd likely
require a buffer much larger than the result index would be.
Either way, for the first scan (i.e. phase 2 "build new indexes") this
is not an issue: we don't care about what transaction adds/deletes
tuples at that point.
For all we know, all tuples of the table may be deleted concurrently
before we even allow concurrent backends to start inserting tuples,
and the algorithm would still work as it does right now.
> Another possible issue may be caused by the new locking pattern - we
> will be required to wait for all transaction started before the ending
> of the phase to exit.
What do you mean by "new locking pattern"? We already keep an
ShareUpdateExclusiveLock on every heap table we're accessing during
R/CIC, and that should already prevent any concurrent VACUUM
operations, right?
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2023-12-20 09:56:33 |
| Message-ID: | CANtu0ojRX=osoiXL9JJG6g6qOowXVbVYX+mDsN+2jmFVe=eG7w@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
> Also, feels like we may apply this to both phases (first and the second scans).
> The original patch (1) was helping only to the second one (after call
> to set_indexsafe_procflags).
Oops, I was wrong here. The original version of the patch was also applied to
both phases.
> Note that the use of such expressions would be a violation of the
> function's definition; it would depend on data from other tables which
> makes the function behave like a STABLE function, as opposed to the
> IMMUTABLE that is required for index expressions. So, I don't think we
> should specially care about being correct for incorrectly marked
> function definitions.
Yes, but such cases could probably cause crashes also...
So, I think it is better to check them for custom functions. But I
still not sure -
if such limitations still required for proposed optimization or not.
> I just realised there is one issue with this design: We can't cheaply
> reset the snapshot during the second table scan:
> It is critically important that the second scan of R/CIC uses an index
> contents summary (made with index_bulk_delete) that was created while
> the current snapshot was already registered.
> So, the "reset the snapshot every so often" trick cannot be applied in
> phase 3 (the rescan), or we'd have to do an index_bulk_delete call
> every time we reset the snapshot. Rescanning might be worth the cost
> (e.g. when using BRIN), but that is very unlikely.
Hm, I think it is still possible. We could just manually recheck the
tuples we see
to the snapshot currently used for the scan. If an "old" snapshot can see
the tuple also (HeapTupleSatisfiesHistoricMVCC) then search for it in the
index summary.
> What do you mean by "new locking pattern"? We already keep an
> ShareUpdateExclusiveLock on every heap table we're accessing during
> R/CIC, and that should already prevent any concurrent VACUUM
> operations, right?
I was thinking not about "classical" locking, but about waiting for
other backends
by WaitForLockers(heaplocktag, ShareLock, true). But I think
everything should be
fine.
Best regards,
Michail.
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2023-12-20 11:14:32 |
| Message-ID: | CAEze2Wg03Ps_StwEhgCdSn7VXY9ZUM=zCrf-m1dRZpTWv6wD_A@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 20 Dec 2023 at 10:56, Michail Nikolaev
<michail(dot)nikolaev(at)gmail(dot)com> wrote:
> > Note that the use of such expressions would be a violation of the
> > function's definition; it would depend on data from other tables which
> > makes the function behave like a STABLE function, as opposed to the
> > IMMUTABLE that is required for index expressions. So, I don't think we
> > should specially care about being correct for incorrectly marked
> > function definitions.
>
> Yes, but such cases could probably cause crashes also...
> So, I think it is better to check them for custom functions. But I
> still not sure -
> if such limitations still required for proposed optimization or not.
I think contents could be inconsistent, but not more inconsistent than
if the index was filled across multiple transactions using inserts.
Either way I don't see it breaking more things that are not already
broken in that way in other places - at most it will introduce another
path that exposes the broken state caused by mislabeled functions.
> > I just realised there is one issue with this design: We can't cheaply
> > reset the snapshot during the second table scan:
> > It is critically important that the second scan of R/CIC uses an index
> > contents summary (made with index_bulk_delete) that was created while
> > the current snapshot was already registered.
>
> > So, the "reset the snapshot every so often" trick cannot be applied in
> > phase 3 (the rescan), or we'd have to do an index_bulk_delete call
> > every time we reset the snapshot. Rescanning might be worth the cost
> > (e.g. when using BRIN), but that is very unlikely.
>
> Hm, I think it is still possible. We could just manually recheck the
> tuples we see
> to the snapshot currently used for the scan. If an "old" snapshot can see
> the tuple also (HeapTupleSatisfiesHistoricMVCC) then search for it in the
> index summary.
That's an interesting method.
How would this deal with tuples not visible to the old snapshot?
Presumably we can assume they're newer than that snapshot (the old
snapshot didn't have it, but the new one does, so it's committed after
the old snapshot, making them newer), so that backend must have
inserted it into the index already, right?
> HeapTupleSatisfiesHistoricMVCC
That function has this comment marker:
"Only usable on tuples from catalog tables!"
Is that correct even for this?
Should this deal with any potential XID wraparound, too?
How does this behave when the newly inserted tuple's xmin gets frozen?
This would be allowed to happen during heap page pruning, afaik - no
rules that I know of which are against that - but it would create
issues where normal snapshot visibility rules would indicate it
visible to both snapshots regardless of whether it actually was
visible to the older snapshot when that snapshot was created...
Either way, "Historic snapshot" isn't something I've worked with
before, so that goes onto my "figure out how it works" pile.
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2023-12-20 16:18:18 |
| Message-ID: | CANtu0oj66JjAq8xyRSeO=MuRHYS2XsYbhHRRESHtOcLJs=3+Sw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
> How would this deal with tuples not visible to the old snapshot?
> Presumably we can assume they're newer than that snapshot (the old
> snapshot didn't have it, but the new one does, so it's committed after
> the old snapshot, making them newer), so that backend must have
> inserted it into the index already, right?
Yes, exactly.
>> HeapTupleSatisfiesHistoricMVCC
> That function has this comment marker:
> "Only usable on tuples from catalog tables!"
> Is that correct even for this?
Yeah, we just need HeapTupleSatisfiesVisibility (which calls
HeapTupleSatisfiesMVCC) instead.
> Should this deal with any potential XID wraparound, too?
Yeah, looks like we should care about such case somehow.
Possible options here:
1) Skip vac_truncate_clog while CIC is running. In fact, I think it's
not that much worse than the current state - datfrozenxid is still
updated in the catalog and will be considered the next time
vac_update_datfrozenxid is called (the next VACCUM on any table).
2) Delay vac_truncate_clog while CIC is running.
In such a case, if it was skipped, we will need to re-run it using the
index builds backend later.
3) Wait for 64-bit xids :)
4) Any ideas?
In addition, for the first and second options, we need logic to cancel
the second phase in the case of ForceTransactionIdLimitUpdate.
But maybe I'm missing something and the tuples may be frozen, ignoring
the set datfrozenxid values (over some horizon calculated at runtime
based on the xmin backends).
> How does this behave when the newly inserted tuple's xmin gets frozen?
> This would be allowed to happen during heap page pruning, afaik - no
> rules that I know of which are against that - but it would create
> issues where normal snapshot visibility rules would indicate it
> visible to both snapshots regardless of whether it actually was
> visible to the older snapshot when that snapshot was created...
Yes, good catch.
Assuming we have somehow prevented vac_truncate_clog from occurring
during CIC, we can leave frozen and potentially frozen
(xmin<frozenXID) for the second phase.
So, first phase processing items:
* not frozen
* xmin>frozenXID (may not be frozen)
* visible by snapshot
second phase:
* frozen
* xmin>frozenXID (may be frozen)
* not in the index summary
* visible by "old" snapshot
You might also think – why is the first stage needed at all? Just use
batch processing during initial index building?
Best regards,
Mikhail.
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2023-12-20 16:53:27 |
| Message-ID: | CANtu0ogT2Qn7-q_jK6+DqBQvFoTt69eQJDKxJARXV9pdWjd0Gg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
> Yes, good catch.
> Assuming we have somehow prevented vac_truncate_clog from occurring
> during CIC, we can leave frozen and potentially frozen
> (xmin<frozenXID) for the second phase.
Just realized that we can leave this for the first stage to improve efficiency.
Since the ID is locked, anything that can be frozen will be visible in
the first stage.
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2023-12-21 13:14:19 |
| Message-ID: | CANtu0ogXgNkEuxbDRwznAZpxEXRmj3NzOen3y-RGHDwig0YBRw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello.
Realized my last idea is invalid (because tuples are frozen by using
dynamically calculated horizon) - so, don't waste your time on it :)
Need to think a little bit more here.
Thanks,
Mikhail.
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2023-12-25 14:12:41 |
| Message-ID: | CANtu0oi+FTMqDb+6Bv8w7VHiTFVMB1uAAip_P841WQH+ktPixw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
It seems like the idea of "old" snapshot is still a valid one.
> Should this deal with any potential XID wraparound, too?
As far as I understand in our case, we are not affected by this in any way.
Vacuum in our table is not possible because of locking, so, nothing
may be frozen (see below).
In the case of super long index building, transactional limits will
stop new connections using current
regular infrastructure because it is based on relation data (but not
actual xmin of backends).
> How does this behave when the newly inserted tuple's xmin gets frozen?
> This would be allowed to happen during heap page pruning, afaik - no
> rules that I know of which are against that - but it would create
> issues where normal snapshot visibility rules would indicate it
> visible to both snapshots regardless of whether it actually was
> visible to the older snapshot when that snapshot was created...
As I can see, heap_page_prune never freezes any tuples.
In the case of regular vacuum, it used this way: call heap_page_prune
and then call heap_prepare_freeze_tuple and then
heap_freeze_execute_prepared.
Merry Christmas,
Mikhail.
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-01-04 11:24:04 |
| Message-ID: | CAEze2WgeyVnDb_j4gJQYC4+HcSsYQAdeRA1-F0KDnJ=Y0A_TzA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 25 Dec 2023 at 15:12, Michail Nikolaev
<michail(dot)nikolaev(at)gmail(dot)com> wrote:
>
> Hello!
>
> It seems like the idea of "old" snapshot is still a valid one.
>
> > Should this deal with any potential XID wraparound, too?
>
> As far as I understand in our case, we are not affected by this in any way.
> Vacuum in our table is not possible because of locking, so, nothing
> may be frozen (see below).
> In the case of super long index building, transactional limits will
> stop new connections using current
> regular infrastructure because it is based on relation data (but not
> actual xmin of backends).
>
> > How does this behave when the newly inserted tuple's xmin gets frozen?
> > This would be allowed to happen during heap page pruning, afaik - no
> > rules that I know of which are against that - but it would create
> > issues where normal snapshot visibility rules would indicate it
> > visible to both snapshots regardless of whether it actually was
> > visible to the older snapshot when that snapshot was created...
>
> As I can see, heap_page_prune never freezes any tuples.
> In the case of regular vacuum, it used this way: call heap_page_prune
> and then call heap_prepare_freeze_tuple and then
> heap_freeze_execute_prepared.
Correct, but there are changes being discussed where we would freeze
tuples during pruning as well [0], which would invalidate that
implementation detail. And, if I had to choose between improved
opportunistic freezing and improved R/CIC, I'd probably choose
improved freezing over R/CIC.
As an alternative, we _could_ keep track of concurrent index inserts
using a dummy index (with the same predicate) which only holds the
TIDs of the inserted tuples. We'd keep it as an empty index in phase
1, and every time we reset the visibility snapshot we now only need to
scan that index to know what tuples were concurrently inserted. This
should have a significantly lower IO overhead than repeated full index
bulkdelete scans for the new index in the second table scan phase of
R/CIC. However, in a worst case it could still require another
O(tablesize) of storage.
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-01-04 12:45:06 |
| Message-ID: | CANtu0oga9zqqEFhdmcWyJTK4d6EGMJsMB_LMgVSE8ar0xVm7Ew@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
> Correct, but there are changes being discussed where we would freeze
> tuples during pruning as well [0], which would invalidate that
> implementation detail. And, if I had to choose between improved
> opportunistic freezing and improved R/CIC, I'd probably choose
> improved freezing over R/CIC.
As another option, we could extract a dedicated horizon value for an
opportunistic freezing.
And use some flags in R/CIC backend to keep it at the required value.
Best regards,
Michail.
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-01-09 17:00:28 |
| Message-ID: | CANtu0oirtBK_g4jxtw3jehSop3b0WSQaek5Sv5OGSXwxgcHwZQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Melanie!
Sorry to interrupt you, just a quick question.
> Correct, but there are changes being discussed where we would freeze
> tuples during pruning as well [0], which would invalidate that
> implementation detail. And, if I had to choose between improved
> opportunistic freezing and improved R/CIC, I'd probably choose
> improved freezing over R/CIC.
Do you have any patches\threads related to that refactoring
(opportunistic freezing of tuples during pruning) [0]?
This may affect the idea of the current thread (latest version of it
mostly in [1]) - it may be required to disable such a feature for
particular relation temporary or affect horizon used for pruning
(without holding xmin).
Just no sure - is it reasonable to start coding right now, or wait for
some prune-freeze-related patch first?
[0] https://www.postgresql.org/message-id/CAAKRu_a+g2oe6aHJCbibFtNFiy2aib4E31X9QYJ_qKjxZmZQEg@mail.gmail.com
[1] https://www.postgresql.org/message-id/flat/CANtu0ojRX%3DosoiXL9JJG6g6qOowXVbVYX%2BmDsN%2B2jmFVe%3DeG7w%40mail.gmail.com#a8ff53f23d0fc7edabd446b4d634e7b5
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-02-01 16:06:28 |
| Message-ID: | CANtu0oijWPRGRpaRR_OvT2R5YALzscvcOTFh-=uZKUpNJmuZtw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
> > > I just realised there is one issue with this design: We can't cheaply
> > > reset the snapshot during the second table scan:
> > > It is critically important that the second scan of R/CIC uses an index
> > > contents summary (made with index_bulk_delete) that was created while
> > > the current snapshot was already registered.
> >
> > > So, the "reset the snapshot every so often" trick cannot be applied in
> > > phase 3 (the rescan), or we'd have to do an index_bulk_delete call
> > > every time we reset the snapshot. Rescanning might be worth the cost
> > > (e.g. when using BRIN), but that is very unlikely.
> >
> > Hm, I think it is still possible. We could just manually recheck the
> > tuples we see
> > to the snapshot currently used for the scan. If an "old" snapshot can see
> > the tuple also (HeapTupleSatisfiesHistoricMVCC) then search for it in the
> > index summary.
> That's an interesting method.
>
> How would this deal with tuples not visible to the old snapshot?
> Presumably we can assume they're newer than that snapshot (the old
> snapshot didn't have it, but the new one does, so it's committed after
> the old snapshot, making them newer), so that backend must have
> inserted it into the index already, right?
I made a draft of the patch and this idea is not working.
The problem is generally the same:
* reference snapshot sees tuple X
* reference snapshot is used to create index summary (but there is no
tuple X in the index summary)
* tuple X is updated to Y creating a HOT-chain
* we started scan with new temporary snapshot (it sees Y, X is too old for it)
* tuple X is pruned from HOT-chain because it is not protected by any snapshot
* we see tuple Y in the scan with temporary snapshot
* it is not in the index summary - so, we need to check if
reference snapshot can see it
* there is no way to understand if the reference snapshot was able
to see tuple X - because we need the full HOT chain (with X tuple) for
that
Best regards,
Michail.
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-02-17 21:48:44 |
| Message-ID: | CAEze2WgHFnYdxkNUmvqxOc-cFUNEYaTqL7+Pei=CtA-ZrTOFyw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, 1 Feb 2024, 17:06 Michail Nikolaev, <michail(dot)nikolaev(at)gmail(dot)com> wrote:
>
> > > > I just realised there is one issue with this design: We can't cheaply
> > > > reset the snapshot during the second table scan:
> > > > It is critically important that the second scan of R/CIC uses an index
> > > > contents summary (made with index_bulk_delete) that was created while
> > > > the current snapshot was already registered.
I think the best way for this to work would be an index method that
exclusively stores TIDs, and of which we can quickly determine new
tuples, too. I was thinking about something like GIN's format, but
using (generation number, tid) instead of ([colno, colvalue], tid) as
key data for the internal trees, and would be unlogged (because the
data wouldn't have to survive a crash). Then we could do something
like this for the second table scan phase:
0. index->indisready is set
[...]
1. Empty the "changelog index", resetting storage and the generation number.
2. Take index contents snapshot of new index, store this.
3. Loop until completion:
4a. Take visibility snapshot
4b. Update generation number of the changelog index, store this.
4c. Take index snapshot of "changelog index" for data up to the
current stored generation number. Not including, because we only need
to scan that part of the index that were added before we created our
visibility snapshot, i.e. TIDs labeled with generation numbers between
the previous iteration's generation number (incl.) and this
iteration's generation (excl.).
4d. Combine the current index snapshot with that of the "changelog"
index, and save this.
Note that this needs to take care to remove duplicates.
4e. Scan segment of table (using the combined index snapshot) until we
need to update our visibility snapshot or have scanned the whole
table.
This should give similar, if not the same, behavour as that which we
have when we RIC a table with several small indexes, without requiring
us to scan a full index of data several times.
Attemp on proving this approach's correctness:
In phase 3, after each step 4b:
All matching tuples of the table that are in the visibility snapshot:
* Were created before scan 1's snapshot, thus in the new index's snapshot, or
* Were created after scan 1's snapshot but before index->indisready,
thus not in the new index's snapshot, nor in the changelog index, or
* Were created after the index was set as indisready, and committed
before the previous iteration's visibility snapshot, thus in the
combined index snapshot, or
* Were created after the index was set as indisready, after the
previous visibility snapshot was taken, but before the current
visibility snapshot was taken, and thus definitely included in the
changelog index.
Because we hold a snapshot, no data in the table that we should see is
removed, so we don't have a chance of broken HOT chains.
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-02-20 23:33:26 |
| Message-ID: | CANtu0oipL3e8fLnejbH4HnByMW6G_auR4v+ns8j-UHhuPW=9og@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
> I think the best way for this to work would be an index method that
> exclusively stores TIDs, and of which we can quickly determine new
> tuples, too. I was thinking about something like GIN's format, but
> using (generation number, tid) instead of ([colno, colvalue], tid) as
> key data for the internal trees, and would be unlogged (because the
> data wouldn't have to survive a crash)
Yeah, this seems to be a reasonable approach, but there are some
doubts related to it - it needs new index type as well as unlogged
indexes to be introduced - this may make the patch too invasive to be
merged. Also, some way to remove the index from the catalog in case of
a crash may be required.
A few more thoughts:
* it is possible to go without generation number - we may provide a
way to do some kind of fast index lookup (by TID) directly during the
second table scan phase.
* one more option is to maintain a Tuplesorts (instead of an index)
with TIDs as changelog and merge with index snapshot after taking a
new visibility snapshot. But it is not clear how to share the same
Tuplesort with multiple inserting backends.
* crazy idea - what is about to do the scan in the index we are
building? We have tuple, so, we have all the data indexed in the
index. We may try to do an index scan using that data to get all
tuples and find the one with our TID :) Yes, in some cases it may be
too bad because of the huge amount of TIDs we need to scan + also
btree copies whole page despite we need single item. But some
additional index method may help - feels like something related to
uniqueness (but it is only in btree anyway).
Thanks,
Mikhail.
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-02-21 08:35:40 |
| Message-ID: | CANtu0ojmVw8GW5bJknnqSp7Dp1xEuoBewdu2imtQ2tGnWpiWEg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
One more idea - is just forbid HOT prune while the second phase is
running. It is not possible anyway currently because of snapshot held.
Possible enhancements:
* we may apply restriction only to particular tables
* we may apply restrictions only to part of the tables (not yet
scanned by R/CICs).
Yes, it is not an elegant solution, limited, not reliable in terms of
architecture, but a simple one.
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-02-21 11:01:45 |
| Message-ID: | CAEze2WiV9OaY71x3RxyKN+7YCL1jstde55Pm3AcYHjLhMfzO5A@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 21 Feb 2024 at 00:33, Michail Nikolaev
<michail(dot)nikolaev(at)gmail(dot)com> wrote:
>
> Hello!
> > I think the best way for this to work would be an index method that
> > exclusively stores TIDs, and of which we can quickly determine new
> > tuples, too. I was thinking about something like GIN's format, but
> > using (generation number, tid) instead of ([colno, colvalue], tid) as
> > key data for the internal trees, and would be unlogged (because the
> > data wouldn't have to survive a crash)
>
> Yeah, this seems to be a reasonable approach, but there are some
> doubts related to it - it needs new index type as well as unlogged
> indexes to be introduced - this may make the patch too invasive to be
> merged.
I suppose so, though persistence is usually just to keep things
correct in case of crashes, and this "index" is only there to support
processes that don't expect to survive crashes.
> Also, some way to remove the index from the catalog in case of
> a crash may be required.
That's less of an issue though, we already accept that a crash during
CIC/RIC leaves unusable indexes around, so "needs more cleanup" is not
exactly a blocker.
> A few more thoughts:
> * it is possible to go without generation number - we may provide a
> way to do some kind of fast index lookup (by TID) directly during the
> second table scan phase.
While possible, I don't think this would be more performant than the
combination approach, at the cost of potentially much more random IO
when the table is aggressively being updated.
> * one more option is to maintain a Tuplesorts (instead of an index)
> with TIDs as changelog and merge with index snapshot after taking a
> new visibility snapshot. But it is not clear how to share the same
> Tuplesort with multiple inserting backends.
Tuplesort requires the leader process to wait for concurrent backends
to finish their sort before it can start consuming their runs. This
would make it a very bad alternative to the "changelog index" as the
CIC process would require on-demand actions from concurrent backends
(flush of sort state). I'm not convinced that's somehow easier.
> * crazy idea - what is about to do the scan in the index we are
> building? We have tuple, so, we have all the data indexed in the
> index. We may try to do an index scan using that data to get all
> tuples and find the one with our TID :)
We can't rely on that, because we have no guarantee we can find the
tuple quickly enough. Equality-based indexing is very much optional,
and so are TID-based checks (outside the current vacuum-related APIs),
so finding one TID can (and probably will) take O(indexsize) when the
tuple is not in the index, which is one reason for ambulkdelete() to
exist.
Kind regards,
Matthias van de Meent
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-02-21 11:19:29 |
| Message-ID: | CAEze2WgNHTWfw_bP6O0zW_=vi1D-yi1nh6-JDj9kd=8UaB-zLA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 21 Feb 2024 at 09:35, Michail Nikolaev
<michail(dot)nikolaev(at)gmail(dot)com> wrote:
>
> One more idea - is just forbid HOT prune while the second phase is
> running. It is not possible anyway currently because of snapshot held.
>
> Possible enhancements:
> * we may apply restriction only to particular tables
> * we may apply restrictions only to part of the tables (not yet
> scanned by R/CICs).
>
> Yes, it is not an elegant solution, limited, not reliable in terms of
> architecture, but a simple one.
How do you suppose this would work differently from a long-lived
normal snapshot, which is how it works right now?
Would it be exclusively for that relation? How would this be
integrated with e.g. heap_page_prune_opt?
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-02-21 11:36:48 |
| Message-ID: | CANtu0ojA5=rT8BN5==OAiQJZh8CAxD_U8thFhZ3mwrZQ6roNOA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi!
> How do you suppose this would work differently from a long-lived
> normal snapshot, which is how it works right now?
Difference in the ability to take new visibility snapshot periodically
during the second phase with rechecking visibility of tuple according
to the "reference" snapshot (which is taken only once like now).
It is the approach from (1) but with a workaround for the issues
caused by heap_page_prune_opt.
> Would it be exclusively for that relation?
Yes, only for that affected relation. Other relations are unaffected.
> How would this be integrated with e.g. heap_page_prune_opt?
Probably by some flag in RelationData, but not sure here yet.
If the idea looks sane, I could try to extend my POC - it should be
not too hard, likely (I already have tests to make sure it is
correct).
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-03-05 20:08:08 |
| Message-ID: | CAEze2Wh3eSAnXFdY_6roNPb3WD-YsKbNLiKf=cPmAGHkPUd22w@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 21 Feb 2024 at 12:37, Michail Nikolaev
<michail(dot)nikolaev(at)gmail(dot)com> wrote:
>
> Hi!
>
> > How do you suppose this would work differently from a long-lived
> > normal snapshot, which is how it works right now?
>
> Difference in the ability to take new visibility snapshot periodically
> during the second phase with rechecking visibility of tuple according
> to the "reference" snapshot (which is taken only once like now).
> It is the approach from (1) but with a workaround for the issues
> caused by heap_page_prune_opt.
>
> > Would it be exclusively for that relation?
> Yes, only for that affected relation. Other relations are unaffected.
I suppose this could work. We'd also need to be very sure that the
toast relation isn't cleaned up either: Even though that's currently
DELETE+INSERT only and can't apply HOT, it would be an issue if we
couldn't find the TOAST data of a deleted for everyone (but visible to
us) tuple.
Note that disabling cleanup for a relation will also disable cleanup
of tuple versions in that table that are not used for the R/CIC
snapshots, and that'd be an issue, too.
> > How would this be integrated with e.g. heap_page_prune_opt?
> Probably by some flag in RelationData, but not sure here yet.
>
> If the idea looks sane, I could try to extend my POC - it should be
> not too hard, likely (I already have tests to make sure it is
> correct).
I'm not a fan of this approach. Changing visibility and cleanup
semantics to only benefit R/CIC sounds like a pain to work with in
essentially all visibility-related code. I'd much rather have to deal
with another index AM, even if it takes more time: the changes in
semantics will be limited to a new plug in the index AM system and a
behaviour change in R/CIC, rather than behaviour that changes in all
visibility-checking code.
But regardless of second scan snapshots, I think we can worry about
that part at a later moment: The first scan phase is usually the most
expensive and takes the most time of all phases that hold snapshots,
and in the above discussion we agreed that we can already reduce the
time that a snapshot is held during that phase significantly. Sure, it
isn't great that we have to scan the table again with only a single
snapshot, but generally phase 2 doesn't have that much to do (except
when BRIN indexes are involved) so this is likely less of an issue.
And even if it is, we would still have reduced the number of
long-lived snapshots by half.
-Matthias
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-03-07 18:36:53 |
| Message-ID: | CANtu0og_=ypCbH2ZFayn44i=CL0HAXKW390LfZhQ1F56HoFXtQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
> I'm not a fan of this approach. Changing visibility and cleanup
> semantics to only benefit R/CIC sounds like a pain to work with in
> essentially all visibility-related code. I'd much rather have to deal
> with another index AM, even if it takes more time: the changes in
> semantics will be limited to a new plug in the index AM system and a
> behaviour change in R/CIC, rather than behaviour that changes in all
> visibility-checking code.
Technically, this does not affect the visibility logic, only the
clearing semantics.
All visibility related code remains untouched.
But yes, still an inelegant and a little strange-looking option.
At the same time, perhaps it can be dressed in luxury
somehow - for example, add as a first class citizen in ComputeXidHorizonsResult
a list of blocks to clear some relations.
> But regardless of second scan snapshots, I think we can worry about
> that part at a later moment: The first scan phase is usually the most
> expensive and takes the most time of all phases that hold snapshots,
> and in the above discussion we agreed that we can already reduce the
> time that a snapshot is held during that phase significantly. Sure, it
> isn't great that we have to scan the table again with only a single
> snapshot, but generally phase 2 doesn't have that much to do (except
> when BRIN indexes are involved) so this is likely less of an issue.
> And even if it is, we would still have reduced the number of
> long-lived snapshots by half.
Hmm, but it looks like we don't have the infrastructure to "update" xmin
propagating to the horizon after the first snapshot in a transaction is taken.
One option I know of is to reuse the
d9d076222f5b94a85e0e318339cfc44b8f26022d (1) approach.
But if this is the case, then there is no point in re-taking the
snapshot again during the first
phase - just apply this "if" only for the first phase - and you're done.
Do you know any less-hacky way? Or is it a nice way to go?
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-03-12 11:50:24 |
| Message-ID: | CAEze2WghpUS29bJJh5GCZ+WtpO4qWmxiFF-CTWFiP4Qq62G58w@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, 7 Mar 2024 at 19:37, Michail Nikolaev
<michail(dot)nikolaev(at)gmail(dot)com> wrote:
>
> Hello!
>
> > I'm not a fan of this approach. Changing visibility and cleanup
> > semantics to only benefit R/CIC sounds like a pain to work with in
> > essentially all visibility-related code. I'd much rather have to deal
> > with another index AM, even if it takes more time: the changes in
> > semantics will be limited to a new plug in the index AM system and a
> > behaviour change in R/CIC, rather than behaviour that changes in all
> > visibility-checking code.
>
> Technically, this does not affect the visibility logic, only the
> clearing semantics.
> All visibility related code remains untouched.
Yeah, correct. But it still needs to update the table relations'
information after finishing creating the indexes, which I'd rather not
have to do.
> But yes, still an inelegant and a little strange-looking option.
>
> At the same time, perhaps it can be dressed in luxury
> somehow - for example, add as a first class citizen in ComputeXidHorizonsResult
> a list of blocks to clear some relations.
Not sure what you mean here, but I don't think
ComputeXidHorizonsResult should have anything to do with actual
relations.
> > But regardless of second scan snapshots, I think we can worry about
> > that part at a later moment: The first scan phase is usually the most
> > expensive and takes the most time of all phases that hold snapshots,
> > and in the above discussion we agreed that we can already reduce the
> > time that a snapshot is held during that phase significantly. Sure, it
> > isn't great that we have to scan the table again with only a single
> > snapshot, but generally phase 2 doesn't have that much to do (except
> > when BRIN indexes are involved) so this is likely less of an issue.
> > And even if it is, we would still have reduced the number of
> > long-lived snapshots by half.
>
> Hmm, but it looks like we don't have the infrastructure to "update" xmin
> propagating to the horizon after the first snapshot in a transaction is taken.
We can just release the current snapshot, and get a new one, right? I
mean, we don't actually use the transaction for much else than
visibility during the first scan, and I don't think there is a need
for an actual transaction ID until we're ready to mark the index entry
with indisready.
> One option I know of is to reuse the
> d9d076222f5b94a85e0e318339cfc44b8f26022d (1) approach.
> But if this is the case, then there is no point in re-taking the
> snapshot again during the first
> phase - just apply this "if" only for the first phase - and you're done.
Not a fan of that, as it is too sensitive to abuse. Note that
extensions will also have access to these tools, and I think we should
build a system here that's not easy to break, rather than one that is.
> Do you know any less-hacky way? Or is it a nice way to go?
I suppose we could be resetting the snapshot every so often? Or use
multiple successive TID range scans with a new snapshot each?
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-05-04 15:51:20 |
| Message-ID: | CANtu0oiuuGRvYRsH-y0iQjfc+JpT9o4mPUXVkz97+sW9BXA+FA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Matthias!
> We can just release the current snapshot, and get a new one, right? I
> mean, we don't actually use the transaction for much else than
> visibility during the first scan, and I don't think there is a need
> for an actual transaction ID until we're ready to mark the index entry
> with indisready.
> I suppose we could be resetting the snapshot every so often? Or use
> multiple successive TID range scans with a new snapshot each?
It seems like it is not so easy in that case. Because we still need to hold
catalog snapshot xmin, releasing the snapshot which used for the scan does
not affect xmin propagated to the horizon.
That's why d9d076222f5b94a85e0e318339cfc44b8f26022d(1) affects only the
data horizon, but not the catalog's one.
So, in such a situation, we may:
1) starts scan from scratch with some TID range multiple times. But such an
approach feels too complex and error-prone for me.
2) split horizons propagated by `MyProc` to data-related xmin and
catalog-related xmin. Like `xmin` and `catalogXmin`. We may just mark
snapshots as affecting some of the horizons, or both. Such a change feels
easy to be done but touches pretty core logic, so we need someone's
approval for such a proposal, probably.
3) provide some less invasive (but less non-kludge) way: add some kind of
process flag like `PROC_IN_SAFE_IC_XMIN` and function like
`AdvanceIndexSafeXmin` which changes the way backend affect horizon
calculation. In the case of `PROC_IN_SAFE_IC_XMIN` `ComputeXidHorizons`
uses value from `proc->safeIcXmin` which is updated by
`AdvanceIndexSafeXmin` while switching scan snapshots.
So, with option 2 or 3, we may avoid holding data horizon during the first
phase scan by resetting the scan snapshot every so often (and, optionally,
using `AdvanceIndexSafeXmin` in case of 3rd approach).
The same will be possible for the second phase (validate).
We may do the same "resetting the snapshot every so often" technique, but
there is still the issue with the way we distinguish tuples which were
missed by the first phase scan or were inserted into the index after the
visibility snapshot was taken.
So, I see two options here:
1) approach with additional index with some custom AM proposed by you.
It looks correct and reliable but feels complex to implement and
maintain. Also, it negatively affects performance of table access (because
of an additional index) and validation scan (because we need to merge
additional index content with visibility snapshot).
2) one more tricky approach.
We may add some boolean flag to `Relation` about information of index
building in progress (`indexisbuilding`).
It may be easily calculated using `(index->indisready &&
!index->indisvalid)`. For a more reliable solution, we also need to somehow
check if backend/transaction building the index still in progress. Also, it
is better to check if index is building concurrently using the "safe_index"
way.
I think there is a non too complex and expensive way to do so, probably by
addition of some flag to index catalog record.
Once we have such a flag, we may "legally" prohibit `heap_page_prune_opt`
affecting the relation updating `GlobalVisHorizonKindForRel` like this:
if (rel != NULL && rel->rd_indexvalid && rel->rd_indexisbuilding)
return VISHORIZON_CATALOG;
So, in common it works this way:
* backend building the index affects catalog horizon as usual, but data
horizon is regularly propagated forward during the scan. So, other
relations are processed by vacuum and `heap_page_prune_opt` without any
restrictions
* but our relation (with CIC in progress) accessed by `heap_page_prune_opt`
(or any other vacuum-like mechanics) with catalog horizon to honor CIC
work. Therefore, validating scan may be sure what none of the HOT-chain
will be truncated. Even regular vacuum can't affect it (but yes, it can't
be anyway because of relation locking).
As a result, we may easily distinguish tuples missed by first phase scan,
just by testing them against reference snapshot (which used to take
visibility snapshot).
So, for me, this approach feels non-kludge enough, safe and effective and
the same time.
I have a prototype of this approach and looks like it works (I have a good
test catching issues with index content for CIC).
What do you think about all this?
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-05-05 23:37:20 |
| Message-ID: | CANtu0og6P+O10XLm-AsoqOhZYEjr8SEHFETadSJ8ifO01YP1qg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Matthias!
I just realized there is a much simpler and safe way to deal with the
problem.
So, d9d076222f5b94a85e0e318339cfc44b8f26022d(1) had a bug because the scan
was not protected by a snapshot. At the same time, we want this snapshot to
affect not all the relations, but only a subset of them. And there is
already a proper way to achieve that - different types of visibility
horizons!
So, to resolve the issue, we just need to create a separated horizon value
for such situation as building an index concurrently.
For now, let's name it `VISHORIZON_BUILD_INDEX_CONCURRENTLY` for example.
By default, its value is equal to `VISHORIZON_DATA`. But in some cases it
"stops" propagating forward while concurrent index is building, like this:
h->create_index_concurrently_oldest_nonremovable
=TransactionIdOlder(h->create_index_concurrently_oldest_nonremovable, xmin);
if (!(statusFlags & PROC_IN_SAFE_IC))
h->data_oldest_nonremovable =
TransactionIdOlder(h->data_oldest_nonremovable, xmin);
The `PROC_IN_SAFE_IC` marks backend xmin as ignored by `VISHORIZON_DATA`
but not by `VISHORIZON_BUILD_INDEX_CONCURRENTLY`.
After, we need to use appropriate horizon for relations which are processed
by `PROC_IN_SAFE_IC` backends. There are a few ways to do it, we may start
prototyping with `rd_indexisbuilding` from previous message:
static inline GlobalVisHorizonKind
GlobalVisHorizonKindForRel(Relation rel)
........
if (rel != NULL && rel->rd_indexvalid &&
rel->rd_indexisbuilding)
return VISHORIZON_BUILD_INDEX_CONCURRENTLY;
There are few more moments need to be considered:
* Does it move the horizon backwards?
It is allowed for the horizon to move backwards (like said in
`ComputeXidHorizons`) but anyway - in that case the horizon for particular
relations just starts to lag behind the horizon for other relations.
Invariant is like that: `VISHORIZON_BUILD_INDEX_CONCURRENTLY` <=
`VISHORIZON_DATA` <= `VISHORIZON_CATALOG` <= `VISHORIZON_SHARED`.
* What is about old cached versions of `Relation` objects without
`rd_indexisbuilding` yet set?
This is not a problem because once the backend registers a new index, it
waits for all transactions without that knowledge to end
(`WaitForLockers`). So, new ones will also get information about new
horizon for that particular relation.
* What is about TOAST?
To keep TOAST horizon aligned with relation building the index, we may do
the next thing (as first implementation iteration):
else if (rel != NULL && ((rel->rd_indexvalid &&
rel->rd_indexisbuilding) || IsToastRelation(rel)))
return VISHORIZON_BUILD_INDEX_CONCURRENTLY;
For the normal case, `VISHORIZON_BUILD_INDEX_CONCURRENTLY` is equal to
`VISHORIZON_DATA` - nothing is changed at all. But while the concurrent
index is building, the TOAST horizon is guaranteed to be aligned with its
parent relation. And yes, it is better to find an easy way to affect only
TOAST relations related to the relation with index building in progress.
New horizon adds some complexity, but not too much, in my opinion. I am
pretty sure it is worth being done because the ability to rebuild indexes
without performance degradation is an extremely useful feature.
Things to be improved:
* better way to track relations with concurrent indexes being built (with
mechanics to understood what index build was failed)
* better way to affect TOAST tables only related to concurrent index build
* better naming
Patch prototype in attachment.
Also, maybe it is worth committing test separately - it was based on Andrey
Borodin work (2). The test fails well in the case of incorrect
implementation.
[1]:
https://github.com/postgres/postgres/commit/d9d076222f5b94a85e0e318339cfc44b8f26022d#diff-8879f0173be303070ab7931db7c757c96796d84402640b9e386a4150ed97b179R1779-R1793
[2]: https://github.com/x4m/postgres_g/commit/d0651e7d0d14862d5a4dac076355
| Attachment | Content-Type | Size |
|---|---|---|
| v1-0001-WIP-fix-d9d076222f5b-VACUUM-ignore-indexing-opera.patch | text/x-patch | 17.5 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-05-07 12:35:13 |
| Message-ID: | CANtu0oj0pakvxXhHJhsiKgk=ywY57m623G=OvhJnLVFWe9JCpg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Matthias and others!
Updated WIP in attach.
Changes are:
* Renaming, now it feels better for me
* More reliable approach in `GlobalVisHorizonKindForRel` to make sure we
have not missed `rd_safeindexconcurrentlybuilding` by calling
`RelationGetIndexList` if required
* Optimization to avoid any additional `RelationGetIndexList` if zero of
concurrently indexes are being built
* TOAST moved to TODO, since looks like it is out of scope - but not sure
yet, need to dive dipper
TODO:
* TOAST
* docs and comments
* make sure non-data tables are not affected
* Per-database scope of optimization
* Handle index building errors correctly in optimization code
* More tests: create index, multiple re-indexes, multiple tables
Thanks,
Michail.
| Attachment | Content-Type | Size |
|---|---|---|
| v2-0001-WIP-fix-d9d076222f5b-VACUUM-ignore-indexing-opera.patch | text/x-patch | 22.6 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-05-07 20:23:23 |
| Message-ID: | CANtu0oiOj65kZqP8ngnsc9O+gywUJATgOjOP6pUARXWsmS9cBQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi again!
Made an error in `GlobalVisHorizonKindForRel` logic, and it was caught by a
new test.
Fixed version in attach.
>
| Attachment | Content-Type | Size |
|---|---|---|
| v3-0001-WIP-fix-d9d076222f5b-VACUUM-ignore-indexing-opera.patch | text/x-patch | 22.6 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-05-09 13:00:00 |
| Message-ID: | CANtu0oiT9SPFhs=h8DR4YVPox7TJ6jkfR9JgqT-0L+=uy=Lxng@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Matthias and others!
Realized new horizon was applied only during validation phase (once index
is marked as ready).
Now it applied if index is not marked as valid yet.
Updated version in attach.
--------------------------------------------------
> I think the best way for this to work would be an index method that
> exclusively stores TIDs, and of which we can quickly determine new
> tuples, too. I was thinking about something like GIN's format, but
> using (generation number, tid) instead of ([colno, colvalue], tid) as
> key data for the internal trees, and would be unlogged (because the
> data wouldn't have to survive a crash). Then we could do something
> like this for the second table scan phase:
Regarding that approach to dealing with validation phase and resetting of
snapshot:
I was thinking about it and realized: once we go for an additional index -
we don't need the second heap scan at all!
We may do it this way:
* create target index, not marked as indisready yet
* create a temporary unlogged index with the same parameters to store tids
(optionally with the indexes columns data, see below), marked as indisready
(but not indisvalid)
* commit them both in a single transaction
* wait for other transaction to know about them and honor in HOT
constraints and new inserts (for temporary index)
* now our temporary index is filled by the tuples inserted to the table
* start building out target index, resetting snapshot every so often (if it
is "safe" index)
* finish target index building phase
* mark target index as indisready
* now, start validation of the index:
* take the reference snapshot
* take a visibility snapshot of the target index, sort it (as it done
currently)
* take a visibility snapshot of our temporary index, sort it
* start merging loop using two synchronized cursors over both
visibility snapshots
* if we encountered tid which is not present in target visibility
snapshot
* insert it to target index
* if a temporary index contains the column's data - we may
even avoid the tuple fetch
* if temporary index is tid-only - we fetch tuple from the
heap, but as plus we are also skipping dead tuples from insertion to the
new index (I think it is better option)
* commit everything, release reference snapshot
* wait for transactions older than reference snapshot (as it done currently)
* mark target index as indisvalid, drop temporary index
* done
So, pros:
* just a single heap scan
* snapshot is reset periodically
Cons:
* we need to maintain the additional index during the main building phase
* one more tuplesort
If the temporary index is unlogged, cheap to maintain (just append-only
mechanics) this feels like a perfect tradeoff for me.
This approach will work perfectly with low amount of tuple inserts during
the building phase. And looks like even in the worst case it still better
than the current approach.
What do you think? Have I missed something?
Thanks,
Michail.
| Attachment | Content-Type | Size |
|---|---|---|
| v4-0001-WIP-fix-d9d076222f5b-VACUUM-ignore-indexing-opera.patch | text/x-patch | 22.6 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-06-11 08:58:05 |
| Message-ID: | CANtu0ogBOtd9ravu1CUbuZWgq6qvn1rny38PGKDPk9zzQPH8_A@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello.
I did the POC (1) of the method described in the previous email, and it
looks promising.
It doesn't block the VACUUM, indexes are built about 30% faster (22 mins vs
15 mins). Additional index is lightweight and does not produce any WAL.
I'll continue the more stress testing for a while. Also, I need to
restructure the commits (my path was no direct) into some meaningful and
reviewable patches.
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-08-06 23:40:51 |
| Message-ID: | CAEze2Wj9SgwOpe_1CWnS_D-txQaQyXArR=dm4DTnha93=yua4g@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 11 Jun 2024 at 10:58, Michail Nikolaev
<michail(dot)nikolaev(at)gmail(dot)com> wrote:
>
> Hello.
>
> I did the POC (1) of the method described in the previous email, and it looks promising.
>
> It doesn't block the VACUUM, indexes are built about 30% faster (22 mins vs 15 mins).
That's a nice improvement.
> Additional index is lightweight and does not produce any WAL.
That doesn't seem to be what I see in the current patchset:
https://github.com/postgres/postgres/compare/master...michail-nikolaev:postgres:new_index_concurrently_approach#diff-cc3cb8968cf833c4b8498ad2c561c786099c910515c4bf397ba853ae60aa2bf7R311
> I'll continue the more stress testing for a while. Also, I need to restructure the commits (my path was no direct) into some meaningful and reviewable patches.
While waiting for this, here are some initial comments on the github diffs:
- I notice you've added a new argument to
heapam_index_build_range_scan. I think this could just as well be
implemented by reading the indexInfo->ii_Concurrent field, as the
values should be equivalent, right?
- In heapam_index_build_range_scan, it seems like you're popping the
snapshot and registering a new one while holding a tuple from
heap_getnext(), thus while holding a page lock. I'm not so sure that's
OK, expecially when catalogs are also involved (specifically for
expression indexes, where functions could potentially be updated or
dropped if we re-create the visibility snapshot)
- In heapam_index_build_range_scan, you pop the snapshot before the
returned heaptuple is processed and passed to the index-provided
callback. I think that's incorrect, as it'll change the visibility of
the returned tuple before it's passed to the index's callback. I think
the snapshot manipulation is best added at the end of the loop, if we
add it at all in that function.
- The snapshot reset interval is quite high, at 500ms. Why did you
configure it that low, and didn't you make this configurable?
- You seem to be using WAL in the STIR index, while it doesn't seem
that relevant for the use case of auxiliary indexes that won't return
any data and are only used on the primary. It would imply that the
data is being sent to replicas and more data being written than
strictly necessary, which to me seems wasteful.
- The locking in stirinsert can probably be improved significantly if
we use things like atomic operations on STIR pages. We'd need an
exclusive lock only for page initialization, while share locks are
enough if the page's data is modified without WAL. That should improve
concurrent insert performance significantly, as it would further
reduce the length of the exclusively locked hot path.
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-08-08 13:53:00 |
| Message-ID: | CANtu0ohFr7OzNSbxqBhUpR0mXDYyt0Xt6+=Tbq0EC7as7kr+Lg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Matthias!
> While waiting for this, here are some initial comments on the github
diffs:
Thanks for your review!
While stress testing the POC, I found some issues unrelated to the patch
that need to be fixed first.
This is [1] and [2].
>> Additional index is lightweight and does not produce any WAL.
> That doesn't seem to be what I see in the current patchset:
Persistence is passed as parameter [3] and set to RELPERSISTENCE_UNLOGGED
for auxiliary indexes [4].
> - I notice you've added a new argument to
> heapam_index_build_range_scan. I think this could just as well be
> implemented by reading the indexInfo->ii_Concurrent field, as the
> values should be equivalent, right?
Not always; currently, it is set by ResetSnapshotsAllowed[5].
We fall back to regular index build if there is a predicate or expression
in the index (which should be considered "safe" according to [6]).
However, we may remove this check later.
Additionally, there is no sense in resetting the snapshot if we already
have an xmin assigned to the backend for some reason.
> In heapam_index_build_range_scan, it seems like you're popping the
> snapshot and registering a new one while holding a tuple from
> heap_getnext(), thus while holding a page lock. I'm not so sure that's
> OK, expecially when catalogs are also involved (specifically for
> expression indexes, where functions could potentially be updated or
> dropped if we re-create the visibility snapshot)
Yeah, good catch.
Initially, I implemented a different approach by extracting the catalog
xmin to a separate horizon [7]. It might be better to return to this option.
> In heapam_index_build_range_scan, you pop the snapshot before the
> returned heaptuple is processed and passed to the index-provided
> callback. I think that's incorrect, as it'll change the visibility of
> the returned tuple before it's passed to the index's callback. I think
> the snapshot manipulation is best added at the end of the loop, if we
> add it at all in that function.
Yes, this needs to be fixed as well.
> The snapshot reset interval is quite high, at 500ms. Why did you
> configure it that low, and didn't you make this configurable?
It is just a random value for testing purposes.
I don't think there is a need to make it configurable.
Getting a new snapshot is a cheap operation now, so we can do it more often
if required.
Internally, I was testing it with a 0ms interval.
> You seem to be using WAL in the STIR index, while it doesn't seem
> that relevant for the use case of auxiliary indexes that won't return
> any data and are only used on the primary. It would imply that the
> data is being sent to replicas and more data being written than
> strictly necessary, which to me seems wasteful.
It just looks like an index with WAL, but as mentioned above, it is
unlogged in actual usage.
> The locking in stirinsert can probably be improved significantly if
> we use things like atomic operations on STIR pages. We'd need an
> exclusive lock only for page initialization, while share locks are
> enough if the page's data is modified without WAL. That should improve
> concurrent insert performance significantly, as it would further
> reduce the length of the exclusively locked hot path.
Hm, good idea. I'll check it later.
Best regards & thanks again,
Mikhail
[1]:
https://www.postgresql.org/message-id/CANtu0ohHmYXsK5bxU9Thcq1FbELLAk0S2Zap0r8AnU3OTmcCOA%40mail.gmail.com
[2]:
https://www.postgresql.org/message-id/CANtu0ojga8s9%2BJ89cAgLzn2e-bQgy3L0iQCKaCnTL%3Dppot%3Dqhw%40mail.gmail.com
[3]:
https://github.com/postgres/postgres/compare/master...michail-nikolaev:postgres:new_index_concurrently_approach#diff-50abc48efcc362f0d3194aceba6969429f46fa1f07a119e555255545e6655933R93
[4]:
https://github.com/michail-nikolaev/postgres/blob/e2698ca7c814a5fa5d4de8a170b7cae83034cade/src/backend/catalog/index.c#L1600
[5]:
https://github.com/michail-nikolaev/postgres/blob/e2698ca7c814a5fa5d4de8a170b7cae83034cade/src/backend/catalog/index.c#L2657
[6]:
https://github.com/michail-nikolaev/postgres/blob/e2698ca7c814a5fa5d4de8a170b7cae83034cade/src/backend/commands/indexcmds.c#L1129
[7]:
https://github.com/postgres/postgres/commit/38b243d6cc7358a44cb1a865b919bf9633825b0c
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-09-01 21:19:00 |
| Message-ID: | CANtu0oh4PwBn_h+4p_MxFigRAyJvF-0nA9Tm5NFRwfsWWjZQiA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Matthias!
Just wanted to update you with some information about the next steps in
work.
> In heapam_index_build_range_scan, it seems like you're popping the
> snapshot and registering a new one while holding a tuple from
> heap_getnext(), thus while holding a page lock. I'm not so sure that's
> OK, expecially when catalogs are also involved (specifically for
> expression indexes, where functions could potentially be updated or
> dropped if we re-create the visibility snapshot)
I have returned to the solution with a dedicated catalog_xmin for backends
[1].
Additionally, I have added catalog_xmin to pg_stat_activity [2].
> In heapam_index_build_range_scan, you pop the snapshot before the
> returned heaptuple is processed and passed to the index-provided
> callback. I think that's incorrect, as it'll change the visibility of
> the returned tuple before it's passed to the index's callback. I think
> the snapshot manipulation is best added at the end of the loop, if we
> add it at all in that function.
Now it's fixed, and the snapshot is reset between pages [3].
Additionally, I resolved the issue with potential duplicates in unique
indexes. It looks a bit clunky, but it works for now [4].
Single commit from [5] also included, just for stable stress testing.
Full diff is available at [6].
Best regards,
Mikhail.
[1]:
https://github.com/michail-nikolaev/postgres/commit/01a47623571592c52c7a367f85b1cff9d8b593c0
[2]:
https://github.com/michail-nikolaev/postgres/commit/d3345d60bd51fe2e0e4a73806774b828f34ba7b6
[3]:
https://github.com/michail-nikolaev/postgres/commit/7d1dd4f971e8d03f38de95f82b730635ffe09aaf
[4]:
https://github.com/michail-nikolaev/postgres/commit/4ad56e14dd504d5530657069068c2bdf172e482d
[5]: https://commitfest.postgresql.org/49/5160/
[6]:
https://github.com/postgres/postgres/compare/master...michail-nikolaev:postgres:new_index_concurrently_approach?diff=split&w=
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-09-08 15:18:00 |
| Message-ID: | CANtu0ojHEVU9U_bxgViRmtqNTJ92LnF+76-yzn4axYjGsK2kqQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Matthias!
>> - I notice you've added a new argument to
>> heapam_index_build_range_scan. I think this could just as well be
>> implemented by reading the indexInfo->ii_Concurrent field, as the
>> values should be equivalent, right?
> Not always; currently, it is set by ResetSnapshotsAllowed[5].
> We fall back to regular index build if there is a predicate or expression
in the index (which should be considered "safe" according to [6]).
> However, we may remove this check later.
> Additionally, there is no sense in resetting the snapshot if we already
have an xmin assigned to the backend for some reason.
I realized you were right. It's always possible to reset snapshots for
concurrent index building without any limitations related to predicates or
expressions.
Additionally, the PROC_IN_SAFE_IC flag is no longer necessary since
snapshots are rotating quickly, and it's possible to wait for them without
requiring any special exceptions for CREATE/REINDEX INDEX CONCURRENTLY.
Currently, it looks like this [1]. I've also attached a single large patch
just for the case.
I plan to restructure the patch into the following set:
* Introduce catalogXmin as a separate value to calculate the horizon for
the catalog.
* Add the STIR access method.
* Modify concurrent build/reindex to use an aux-index approach without
snapshot rotation.
* Add support for snapshot rotation for non-parallel and non-unique cases.
* Extend support for snapshot rotation in parallel index builds.
* Implement snapshot rotation support for unique indexes.
Best regards,
Mikhail
>
| Attachment | Content-Type | Size |
|---|---|---|
| create_index_concurrently_with_aux_index_or_rotated_snapshots.patch | text/x-patch | 207.6 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-11-12 15:00:00 |
| Message-ID: | CANtu0ogS871NkdUnZW9P_LVpLzhSJ1+cETK0b55cYjs=v2qbPA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
With winter approaching, it’s the perfect time to dive back into work on
this patch! :)
The first attached patch implements Matthias's idea of periodically
resetting the snapshot during the initial heap scan. The next step will be
to add support for parallel builds.
Additionally, here are a few comments on previous emails:
> In heapam_index_build_range_scan, it seems like you're popping the
> snapshot and registering a new one while holding a tuple from
> heap_getnext(), thus while holding a page lock. I'm not so sure that's
> OK, expecially when catalogs are also involved (specifically for
> expression indexes, where functions could potentially be updated or
> dropped if we re-create the visibility snapshot)
Now, visibility snapshots are updated between pages.
As for the catalog snapshot:
* Dropping functions isn’t possible due to dependencies and locking
constraints.
* Updating functions is possible, but it offers the same level of isolation
as we have now:
1) Functions are already converted into an execution state and aren’t
re-read from the catalog during the scan.
2) During the validation phase, the latest version of a function will be
used.
3) Even in the initial phase, predicates and expressions could be read
using different catalog snapshots, as it’s possible to receive a cache
invalidation message before the first FormIndexDatum is created.
Best regards,
Mikhail.
>
| Attachment | Content-Type | Size |
|---|---|---|
| v1-0001-Allow-advancing-xmin-during-non-unique-non-parall.patch | text/x-patch | 31.8 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-12-02 01:39:00 |
| Message-ID: | CANtu0ohRVBDf4x7Ge3oVzgf4NzMb_DhmTM1ae0u1WUA+CD0UqA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
Added support for parallel builds (resetting in the first phase), next step
- support for unique indexes.
Best regards,
Mikhail.
>
| Attachment | Content-Type | Size |
|---|---|---|
| v2-0004-Allow-snapshot-resets-during-parallel-concurrent-.patch | text/plain | 29.2 KB |
| v2-0001-this-is-https-commitfest.postgresql.org-50-5160-m.patch | text/plain | 61.5 KB |
| v2-0003-Allow-advancing-xmin-during-non-unique-non-parall.patch | text/plain | 35.8 KB |
| v2-0002-Add-stress-tests-for-concurrent-index-operations.patch | text/plain | 20.3 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-12-09 20:53:00 |
| Message-ID: | CANtu0ogTfyng-H4yWr3Pm_+PXX+XvDx1AM1sXTy1V7DM6jJ+Bw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Matthias!
Added support for unique indexes.
So, now your initial idea about resetting during the first phase appears to
be ready.
Next step - use single-scan and auxiliary index for concurrent index build.
Also, I have updated the stress tests accordingly to [0].
Best regards,
Mikhail.
| Attachment | Content-Type | Size |
|---|---|---|
| v5-0005-Allow-snapshot-resets-in-concurrent-unique-index-.patch | application/x-patch | 32.5 KB |
| v5-0003-Allow-advancing-xmin-during-non-unique-non-parall.patch | application/x-patch | 35.8 KB |
| v5-0001-this-is-https-commitfest.postgresql.org-50-5160-m.patch | application/x-patch | 61.5 KB |
| v5-0002-Add-stress-tests-for-concurrent-index-operations.patch | application/x-patch | 20.2 KB |
| v5-0004-Allow-snapshot-resets-during-parallel-concurrent-.patch | application/x-patch | 29.2 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-12-17 23:29:13 |
| Message-ID: | CANtu0oi+nbipJUsMZcoUfodCyuTN_DAXD22UstjMTYWG=tJ4jw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
After [0] fix, I simplified stress tests to single pgbench run without any
forks.
[0]: https://commitfest.postgresql.org/51/5439/
>
| Attachment | Content-Type | Size |
|---|---|---|
| v6-0005-Allow-snapshot-resets-during-parallel-concurrent-.patch | application/octet-stream | 29.2 KB |
| v6-0004-Allow-advancing-xmin-during-non-unique-non-parall.patch | application/octet-stream | 35.8 KB |
| v6-0002-this-is-https-commitfest.postgresql.org-50-5160-m.patch | application/octet-stream | 61.5 KB |
| v6-0003-Add-stress-tests-for-concurrent-index-operations.patch | application/octet-stream | 6.5 KB |
| v6-0006-Allow-snapshot-resets-in-concurrent-unique-index-.patch | application/octet-stream | 32.5 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-12-21 18:00:01 |
| Message-ID: | CANtu0oiuUF7L0wTGxOHfumyoVge3n7C4rAjdmFo=efeEwobXbg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
Added STIR access method, next step is validating indexes using it.
Best regards,
Mikhail.
>
| Attachment | Content-Type | Size |
|---|---|---|
| v7-0001-this-is-https-commitfest.postgresql.org-50-5160-m.patch | application/octet-stream | 61.5 KB |
| v7-0003-Allow-advancing-xmin-during-non-unique-non-parall.patch | application/octet-stream | 36.3 KB |
| v7-0002-Add-stress-tests-for-concurrent-index-operations.patch | application/octet-stream | 6.5 KB |
| v7-0004-Allow-snapshot-resets-during-parallel-concurrent-.patch | application/octet-stream | 29.5 KB |
| v7-0005-Allow-snapshot-resets-in-concurrent-unique-index-.patch | application/octet-stream | 32.5 KB |
| v7-0006-Add-STIR-Short-Term-Index-Replacement-access-meth.patch | application/octet-stream | 37.3 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-12-24 13:06:26 |
| Message-ID: | CANtu0oiD-AvXdygYqYP-WkFq=7vSL78Wj8UU-PUX+3huPNqroQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
Now STIR used for validation (but without resetting of snapshot during
that phase for now).
Best regards,
Mikhail.
>
| Attachment | Content-Type | Size |
|---|---|---|
| v8-0004-Allow-snapshot-resets-during-parallel-concurrent-.patch | application/octet-stream | 30.1 KB |
| v8-0001-this-is-https-commitfest.postgresql.org-50-5160-m.patch | application/octet-stream | 61.5 KB |
| v8-0005-Allow-snapshot-resets-in-concurrent-unique-index-.patch | application/octet-stream | 33.7 KB |
| v8-0003-Allow-advancing-xmin-during-non-unique-non-parall.patch | application/octet-stream | 36.3 KB |
| v8-0002-Add-stress-tests-for-concurrent-index-operations.patch | application/octet-stream | 6.5 KB |
| v8-0006-Add-STIR-Short-Term-Index-Replacement-access-meth.patch | application/octet-stream | 37.3 KB |
| v8-0007-Improve-CREATE-REINDEX-INDEX-CONCURRENTLY-using-a.patch | application/octet-stream | 76.3 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-12-24 19:39:23 |
| Message-ID: | CANtu0ogfGHUQpHgkGXAv0wamD=kW_NcEep8ZAp9SKvFRNz0FLQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
Rebased + snapshot resetting during validation + removed PROC_IN_SAFE_IC.
Going to do some benchmarks soon.
Best regards,
Mikhail.
>
| Attachment | Content-Type | Size |
|---|---|---|
| v9-0005-Allow-snapshot-resets-in-concurrent-unique-index-.patch | application/octet-stream | 35.1 KB |
| v9-0002-Add-stress-tests-for-concurrent-index-operations.patch | application/octet-stream | 6.5 KB |
| v9-0004-Allow-snapshot-resets-during-parallel-concurrent-.patch | application/octet-stream | 30.1 KB |
| v9-0003-Allow-advancing-xmin-during-non-unique-non-parall.patch | application/octet-stream | 36.3 KB |
| v9-0001-this-is-https-commitfest.postgresql.org-50-5160-m.patch | application/octet-stream | 61.5 KB |
| v9-0006-Add-STIR-Short-Term-Index-Replacement-access-meth.patch | application/octet-stream | 37.3 KB |
| v9-0007-Improve-CREATE-REINDEX-INDEX-CONCURRENTLY-using-a.patch | application/octet-stream | 76.2 KB |
| v9-0008-Concurrently-built-index-validation-uses-fresh-sn.patch | application/octet-stream | 10.6 KB |
| v9-0009-concurrent-index-build-Remove-PROC_IN_SAFE_IC-opt.patch | application/octet-stream | 20.5 KB |
| From: | Michael Paquier <michael(at)paquier(dot)xyz> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-12-25 05:19:21 |
| Message-ID: | Z2uV2TIpYisYPipp@paquier.xyz |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Dec 24, 2024 at 02:06:26PM +0100, Michail Nikolaev wrote:
> Now STIR used for validation (but without resetting of snapshot during
> that phase for now).
Perhaps I am the only one, but what you are doing here is confusing.
There is a dependency between one patch and the follow-up ones, but
while the first patch is clear regarding its goal of improving the
interactions between REINDEX CONCURRENTLY and INSERT ON CONFLICT
regarding the selection of arbiter index in the executor in 0001 in
the scope of the other thread you have created about this problem, it
is unclear what's the goal of what you are trying to do with 0003~, if
any of the follow-up patches help with that, and even why they have a
need to be posted on this thread. So perhaps you should split things
and explain what your goals are for each patch, or articulate better
why things are done this way? It looks like more things just keep
piling each time a new patch series is sent to the lists. Posting
300kB worth of patches every 3 days is not going to help potential
reviewers, just confuse them.
Note that 0002, that attempts to introduce new tests, is costly. This
is not acceptable for integration. I'd suggest to replace that with
tests that have controlled and successive steps as these lead to
predictible results, rather than have something that runs an arbitrary
amount of time to stress the friction of concurrent activity (this is
still useful to prove your point, though). That's something related
to the other thread, but in passing..
--
Michael
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Michael Paquier <michael(at)paquier(dot)xyz> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2024-12-25 15:14:00 |
| Message-ID: | CANtu0og-4pvn4+TCWH6U9ghyd7x7NBAZSgi4ZWyBZdBWH6OpWA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Michael!
Thank you for your comments and feedback!
Yes, this patch set contains a significant amount of code, which makes it
challenging to review. Some details are explained in the commit messages,
but I’m doing my best to structure the patch set in a way that is as
committable as possible. Once all the parts are ready, I plan to write a
detailed letter explaining everything, including benchmark results and
other relevant information.
Meanwhile, here’s a quick overview of the patch structure. If you have
suggestions for an alternative decomposition approach, I’d be happy to hear.
The primary goals of the patch set are to:
* Enable the xmin horizon to propagate freely during concurrent index
builds
* Build concurrent indexes with a single heap scan
The patch set is split into the following parts. Technically, each part
could be committed separately, but all of them are required to achieve the
goals.
Part 1: Stress tests
- 0001: Yes, this patch is from another thread and not directly required,
it’s included here as a single commit because it’s necessary for stress
testing this patch set. Without it, issues with concurrent reindexing and
upserts cause failures.
- 0002: Yes, I agree these tests need to be refactored or moved into a
separate task. I’ll address this later.
Part 2: During the first phase of concurrently building a index, reset the
snapshot used for heap scans between pages, allowing xmin to go forward.
- 0003: Implement such snapshot resetting for non-parallel and non-unique
cases
- 0004: Extends snapshot resetting to parallel builds
- 0005: Extends snapshot resetting to unique indexes
Part 3: Build concurrent indexes in a single heap scan
- 0006: Introduces the STIR (Short-Term Index Replacement) access method, a
specialized method for auxiliary indexes during concurrent builds
- 0007: Implements the auxiliary index approach, enabling concurrent index
builds to use a single heap scan.
In a few words, it works like this: create an empty auxiliary
STIR index to track new tuples, scan heap and build new index, merge STIR
tuples into new index, drop auxiliary index.
- 0008: Enhances the auxiliary index approach by resetting snapshots during
the merge phase, allowing xmin to propagate
Part 4: This part depends on all three previous parts being committed to
make sense (other parts are possible to apply separately).
- 0009: Remove PROC_IN_SAFE_IC logic, as it is no more required
I have a plan to add a few additional small things (optimizations) and then
do some scaled stress-testing and benchmarking. I think that without it, no
one is going to spend his time for such an amount of code :)
Merry Christmas,
Mikhail.
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Michael Paquier <michael(at)paquier(dot)xyz> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-01-01 16:16:00 |
| Message-ID: | CANtu0oj6EXRq2US8gkz7ehELeECDsVAXq4R0iRfOaRW9GK=5Dw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
I’ve added several updates to the patch set:
* Automatic auxiliary index removal where applicable.
* Documentation updates to reflect recent changes.
* Optimization for STIR indexes: skipping datum setup, as they store only
TIDs.
* Numerous assertions to ensure that MyProc->xmin is invalid where
necessary.
I’d like to share some initial benchmark results (see attached graphs).
This involves building a B-tree index on (aid, abalance) in a pgbench setup
with scale 2000 (with WAL), while running a concurrent pgbench workload.
The patched version built the index in 68 seconds, compared to 117 seconds
with the master branch (mostly because of a single heap scan).
There appears to be no effect on the throughput of the concurrent pgbench.
The maximum snapshot age remains near zero.
I am going to continue to benchmark with different options: different HOT
setup, unique index, different index types and DB size (100+ GB).
If someone has some ideas about possible benchmark scenarios - please share.
Best regards,
Mikhail.
[image: image.png]
> [image: image.png]
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Michael Paquier <michael(at)paquier(dot)xyz> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-01-01 17:53:24 |
| Message-ID: | CANtu0oik59r6wTahK5FEEOKECYba2tg5tKZvRebSM=80UkC57Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello everyone,
My apologies, I probably forgot to attach the images with the benchmark
results in my previous email.
Please find them attached to this message.
Best regards,
Mikhail
| Attachment | Content-Type | Size |
|---|---|---|
.png)
|
image/png | 34.1 KB |
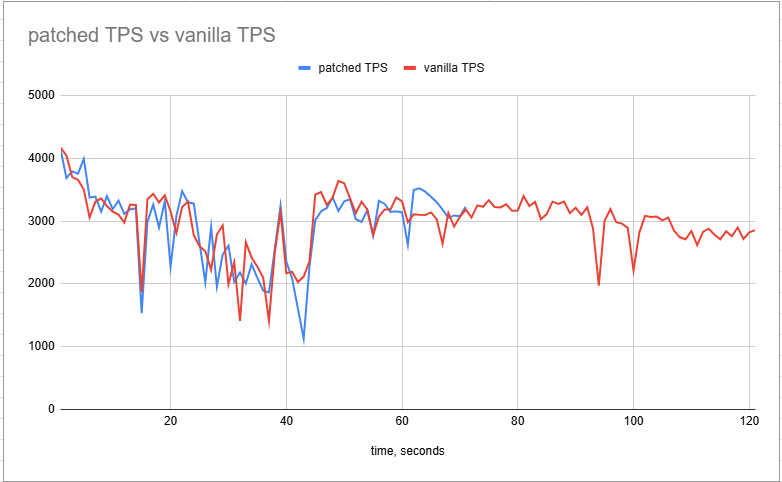
|
image/png | 48.3 KB |
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-01-04 01:12:58 |
| Message-ID: | CAEze2Wj1sY+A6zKJtWhdXSmA9wjmP8jiazHgyH1O37NnSjH5SQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 1 Jan 2025 at 17:17, Michail Nikolaev
<michail(dot)nikolaev(at)gmail(dot)com> wrote:
>
> Hello, everyone!
>
> I’ve added several updates to the patch set:
>
> * Automatic auxiliary index removal where applicable.
> * Documentation updates to reflect recent changes.
> * Optimization for STIR indexes: skipping datum setup, as they store only TIDs.
> * Numerous assertions to ensure that MyProc->xmin is invalid where necessary.
>
> I’d like to share some initial benchmark results (see attached graphs).
> This involves building a B-tree index on (aid, abalance) in a pgbench setup with scale 2000 (with WAL), while running a concurrent pgbench workload.
>
> The patched version built the index in 68 seconds, compared to 117 seconds with the master branch (mostly because of a single heap scan).
> There appears to be no effect on the throughput of the concurrent pgbench.
> The maximum snapshot age remains near zero.
Thank you for continuing working on this, these are some nice results.
I'm sorry I can't spend the time I want on this every time, but I
still think it's important this can eventually get committed, so thank
you for your work.
> (mostly because of a single heap scan).
Isn't there a second heap scan, or do you consider that an index scan?
> I am going to continue to benchmark with different options: different HOT setup, unique index, different index types and DB size (100+ GB).
> If someone has some ideas about possible benchmark scenarios - please share.
I think a good benchmark could show how bloat is actually prevented,
i.e. through result table size comparisons on an update-heavy
workload, both with and without the patch.
I think it shouldn't be too difficult to show how such workloads
quickly regress to always extending the table as no cleanup can
happen, while patched they'd have much more leeway due to page
pruning. Presumably a table with a fillfactor <100 would show the best
results.
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-01-06 13:36:00 |
| Message-ID: | CANtu0ojHAputNCH73TEYN_RUtjLGYsEyW1aSXmsXyvwf=3U4qQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
Some benchmark results are ready. You can access them via [0] or check the
attachments. The benchmark code is available at [1].
A few words about the environments and tests:
There are two environments:
* local: AMD Ryzen 7 7700X (8-Core), 32GB RAM, local high-performance NVMe
SSD [2].
* io2: AWS t2.2xlarge, 8 vCPUs, 32GB RAM, 300GB io2 with 64,000 IOPS (the
fastest available).
There are few tests:
* btree_abalance - A basic new index on a frequently modified field
query: CREATE INDEX CONCURRENTLY idx ON pgbench_accounts (abalance)
* btree_unique - A simple unique index
query: CREATE UNIQUE INDEX CONCURRENTLY idx ON pgbench_accounts (aid)
* btree_unique_hot - A unique index with multiple tuples sharing the same
value, caused by another index
schema: CREATE INDEX idx2 ON pgbench_accounts (abalance)
query: CREATE UNIQUE INDEX CONCURRENTLY idx ON pgbench_accounts (aid)
* brin - A basic BRIN index
query: CREATE INDEX CONCURRENTLY idx ON pgbench_accounts USING
brin(abalance)
* hash - A basic hash index
query: CREATE INDEX CONCURRENTLY idx ON pgbench_accounts USING hash(bid)
* gist - A simple GiST index
schema: CREATE EXTENSION btree_gist
query: CREATE INDEX CONCURRENTLY idx ON pgbench_accounts using
gist(abalance)
* gin - A simple GIN index
schema: CREATE EXTENSION btree_gin
query: CREATE INDEX CONCURRENTLY idx ON pgbench_accounts using
gin(abalance)
The tests were executed on the pgbench schema with a scale factor of 2000
(approximately 30GB) and a fill factor of 95.
Two types of concurrent loads were tested:
* IO-bound scenario: pgbench with 8 clients.
* CPU-bound scenario: pgbench with 50 clients.
As you can see, the index build time results are quite impressive—up to 4x
faster in some cases!
However, there’s something unusual with the GiST index. Occasionally,
sometimes it takes more time to build. I'll investigate that.
The auxiliary index size is relatively small, typically less than 1MB.
You can also observe the typical comparison results of TPS and oldest xmin
during index builds in the provided images (except for GiST, which shows
some anomalies).
>> (mostly because of a single heap scan).
> Isn't there a second heap scan, or do you consider that an index scan?
It is something between.
First phase: a regular heap scan is performed (with snapshot resetting).
Second phase: we collect all TIDs from target and auxiliary indexes, sort
them, and fetch from heap only records which are not present in the target
index (new tuples created during the first phase).
> I think a good benchmark could show how bloat is actually prevented,
> i.e. through result table size comparisons on an update-heavy
> workload, both with and without the patch.
> I think it shouldn't be too difficult to show how such workloads
> quickly regress to always extending the table as no cleanup can
> happen, while patched they'd have much more leeway due to page
> pruning. Presumably a table with a fillfactor <100 would show the best
> results.
I can’t see any significant differences from these tests so far. However, I
think this might be due to the random selection of tuples—there’s almost
always space available to place a new version on the same page.
I’ll try running the tests with a different distribution. Additionally, to
produce bloat comparable to a ~30GB table, updates will need to run for a
longer period.
Best regards,
Mikhail.
[0]:
https://docs.google.com/spreadsheets/d/1UYaqpsWSfYdZdQxaqY4gVo0RW6KrT0d-U1VDNJB8lVk/edit?usp=sharing
[1]:
https://gist.github.com/michail-nikolaev/b33fb0ac1f35729388c89f72db234b0f
[2]:
https://www.harddrivebenchmark.net/hdd.php?hdd=WD%20PC%20SN810%20SDCPNRZ%202TB&id=29324
| Attachment | Content-Type | Size |
|---|---|---|
| PG benchmark 2 - summary.pdf | application/pdf | 417.4 KB |

|
image/png | 68.8 KB |
| graphs.png | image/png | 108.8 KB |

|
image/png | 26.0 KB |
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-01-08 02:12:00 |
| Message-ID: | CANtu0ogGSjUBuuyjMX3bhNThMGQwOhBTKdMHVNY4O8JjH47-_A@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
Some updates:
* Rebased.
* Resolved the issue with integer overflow in memory calculation, which
caused a performance drop during sorting.
* Fixed a broken tag in the documentation.
* Added per-tuple progress tracking in the validation phase.
Additionally, the anomaly with the GIST index has been clarified.
It occurs because the first phase is slow, and many tuples need to be
inserted during the validation phase.
For each tuple, heapam_index_fetch_tuple is called, even for those on the
same page.
It might be possible to implement a batched version of
heapam_index_fetch_tuple to handle multiple tuples on the same page and
mitigate this issue.
Best regards,
Mikhail.
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-01-18 14:18:00 |
| Message-ID: | CANtu0ogtWQvWry72crtt7ZHq22ZLRprFYC_FW3VZ7qtQc1MwpQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
This is an updated version, contains some optimization into STIR index
access method, related to the fact it is never used with WAL.
> The locking in stirinsert can probably be improved significantly if
> we use things like atomic operations on STIR pages. We'd need an
> exclusive lock only for page initialization, while share locks are
> enough if the page's data is modified without WAL. That should improve
> concurrent insert performance significantly, as it would further
> reduce the length of the exclusively locked hot path.
Mathias, you were proposed to use just shared locking to writes, but how is
it possible if it is required to mark page as dirty, and it requires
exclusive lock?
> It occurs because the first phase is slow, and many tuples need to be
inserted during the validation phase.
> For each tuple, heapam_index_fetch_tuple is called, even for those on the
same page.
> It might be possible to implement a batched version of
heapam_index_fetch_tuple to handle multiple tuples on the same page and
mitigate this issue.
It was a wrong assumption. It looks like it is happening because of
prefetching. I'll try to add it in the validation phase.
Best regards,
Mikhail.
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-01-30 01:00:00 |
| Message-ID: | CANtu0oi7d0_8oHpDPi_vFsuD0h71LNL4U2XXg0kq7iY_Ys3+SA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
> It was a wrong assumption. It looks like it is happening because of
prefetching. I'll try to add it in the validation phase.
This is an updated patch set, now prefetching is implemented.
Not validation works that way:
1) TIDs which are present in STIR auxiliary index but not present in target
index are loaded into tuplestore in sorted way
2) Then tuples from tuplestore are fetched one by one, but with underlying
prefetching of corresponding pages
Benchmark setups are the same as in [0].
Results show it works really well (see attachments).
I was unable to achieve consistent results for a few tests on the AWS (io2)
environment (and it was costly :) )
So, my next plan is:
1) wait a little bit for some comments from someone who still watches that
1-year going mainly solo thread :)
2) prepare a fresh new letter with patches, explanation, benchmark results
and so on.
Best regards,
Mikhail.
>


| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | alvherre(at)alvh(dot)no-ip(dot)org |
| Cc: | Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-02-04 01:38:00 |
| Message-ID: | CANtu0ojiVez054rKvwZzKNhneS2R69UXLnw8N9EdwQwqfEoFdQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Alvaro!
I want to bring your attention to that patch because I think (and hope :P)
you might be interested in it since it all began with your work in 2021 [0].
That feature (ability to create\reindex indexes concurrently without
impacting vacuum horizon) made my life better :) Unfortunately, due to [1]
only for short period.
As you said in [3] :
> Deciding to revert makes me sad, because this feature is extremely
valuable for users
so, I highly agree with you here.
It is started with some ideas about the smaller patch scope but ended as:
• [CREATE|RE]INDEX CONCURRENTLY affects vacuum just for a few transactions
(snapshots are reset regularly)
• CI/RC is achieved in (almost) single heap scan (yes, about 3x-2x faster
in many cases)
• all core MVCC-related code is unaffected, everything is protected using
regular snapshots (as I remember Anders was against any changes into that
part)
• feature was actively tested for correctness - I have found five other
issues trying to find bugs in the patch (including [4] - bug is amcheck
itself, which I was using for testing indexes for correctness under the
stress, it was a tough story).
• benchmark shows great results (see attachments) and [2] and [5] and [6]
for more results, details and explanations
In a few words, it works like this:
• before building the index, an auxiliary index of the new empty STIR
(short-term index replacement) access method is created (for the same
columns, predicates, etc.). STIR in unlogged and only stores TIDs of new
coming tuples (datums are not even prepared for it during insert if
possible)
• during the first scan of heap, snapshot used for scan is being reset
every few pages, allowing xmin to propagate (in case of unique index we
also need some additional logic to handle correctness)
• instead of the second heap scan – we just check tids of target and
auxiliary indexes - and insert everything present in STIR but absent in the
target index (also with resetting snapshots every few pages during that)
• auxiliary STIR index then dropped (it also dropped in other cases to
avoid burden for DB administrators)
I have split the patch into 12 commits, some parts may be committed
separately. Some explanation about separation of patches may be found at
[7]. I have tried to structure them as much as possible (each improves some
small part of the whole set). Commit messages explain changes (I hope).
I may provide any additional details you may need – feel free to ask. Also,
I have some infrastructure for benchmarks and validation tests, so, you if
you want to check/test – I am happy to help.
I know it may feel like a naïve “miracle” patch from a dummy (2x index
building speedup without affecting horizon, aha) – but give it a chance.
Also, the last version of the patch in attach.
Best regards,
Mikhail.
[0]:
https://www.postgresql.org/message-id/20210115133858.GA18931@alvherre.pgsql
[1]:
https://www.postgresql.org/message-id/17485-396609c6925b982d%40postgresql.org
[2]:
https://discord.com/channels/1258108670710124574/1259884843165155471/1334565506149253150
[3]:
https://www.postgresql.org/message-id/flat/202205251643.2py5jjpaw7wy%40alvherre.pgsql#589508d30b480b905619dcb93dac8cf8
[4]:
https://www.postgresql.org/message-id/flat/CAH2-WzmcFDK2OzziTgdHxPTmaRQmSFLoDjS-C06uWGTsXibx9g%40mail.gmail.com#e4f4e414363944fc50c383c2a7dc5582
[5]:
https://www.postgresql.org/message-id/flat/CANtu0ojHAputNCH73TEYN_RUtjLGYsEyW1aSXmsXyvwf%3D3U4qQ%40mail.gmail.com#b18fb8efab086bc22af1cb015e187cb7
[6]:
https://www.postgresql.org/message-id/flat/CANtu0oi7d0_8oHpDPi_vFsuD0h71LNL4U2XXg0kq7iY_Ys3%2BSA%40mail.gmail.com#bc1c6f6718b6a7598c1f8e859399a889
[7]:
https://www.postgresql.org/message-id/flat/CANtu0og-4pvn4%2BTCWH6U9ghyd7x7NBAZSgi4ZWyBZdBWH6OpWA%40mail.gmail.com#1f000e705dc1968e8512d649c2923144

| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | alvherre(at)alvh(dot)no-ip(dot)org, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-02-20 14:56:20 |
| Message-ID: | CADzfLwV-6q=6P4GeSWgn3HFDkVNq+fnd9-Qe1VG+jQ-GEiKVCw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone.
Just rebased.
Also, this is Discord thread:
https://discordapp.com/channels/1258108670710124574/1259884843165155471/1334565506149253150
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | alvherre(at)alvh(dot)no-ip(dot)org, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-03-07 22:58:51 |
| Message-ID: | CANtu0ogiQ8xXncFmWTC5LJS65o6nTaVVb84q4f_S_GxCjVsDVw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
Rebased + new parallel GIN builds supported.
Best regards,
MIkhail.
>
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | alvherre(at)alvh(dot)no-ip(dot)org, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-04-06 23:45:00 |
| Message-ID: | CADzfLwWMtQuCtSUJys5EJoZH+31_p1rcfR8xEqGtK7Etr4ubnw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
Rebased, updated accordingly to some changes.
Best regards,
Mikhail.
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | alvherre(at)alvh(dot)no-ip(dot)org, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-04-30 20:01:24 |
| Message-ID: | CADzfLwVOcZ9mg8gOG+KXWurt=MHRcqNv3XSECYoXyM3ENrxyfQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Andres!
This is a gentle ping [1] about the patch related to optimization of
RE|CREATE INDEX CONCURRENTLY. Below is an explanation of the patch
set.
QUICK INTRO
What patch set does in a few words: "CIC/RIC are 2x-3x faster and does
not prevent xmin horizon to advance, without any dirty tricks, even
with removing one of them".
How it works in a few words: "Reset snapshot between pages during the
first phase. Replaces the second phase using a special auxiliary index
to collect TIDs of tuples that need to be inserted into the target
index after the first phase".
What are drawbacks: "some additional complexity + additional auxiliary
index-like structure involved."
SOME HISTORY
In 2021 Álvaro proposed [2] and committed [3] the feature: VACUUM
ignores snapshots involved into concurrent indexing operations. This
was a great feature in PG14.
But in 2022 a bug related to the tuples missing in indexes was
detected, and a little bit later explained by Andres [4]. As a result,
feature was reverted [5] with Álvaro's comment[6]:
> Deciding to revert makes me sad, because this feature is extremely
> valuable for users. However, I understand the danger and I don't
> disagree with the rationale so I can't really object.
There were some proposals, like introducing a special horizon for
HOT-pruning or stopping it during the CIC, but after some discussions
Andres said [7]:
> I'm also doubtful it's the right approach.
> The problem here comes from needing a snapshot for the entire duration of the validation scan
> ISTM that we should work on not needing that snapshot, rather than trying to reduce the consequences of holding that snapshot.
> I think it might be possible to avoid it.
So, given these two ideas I began the work on the patch.
STRUCTURE
Patch itself contains 4 parts, some of them may be reviewed/committed
separately. All commit messages are detailed and contain additional
explanation of changes.
To not confuse CFBot, commits are presented in the following way: part
1, 2, 3 and 4. If you want only part 3 to test/review – check the
files with "patch_" extensions. They differ a little bit, but changes
are minor.
PART 1
Test set (does not depend on anything)
This is a set of stress tests and some fixes required for those tests
to reliably succeed (even on current master branch). That part is not
required for any other parts – its goal is to make sure everything is
still working correctly while applying other parts/commits.
It includes:
- fixes related to races in case of ON CONFLICT UPDATE + REINDEX
CONCURRENTLY (issue was discovered during testing of that patch) [8]
- fixes in bt_index_parent_check (issue was discovered during testing
of that patch with enormous amount of pain – I was looking for months
for error in patch because of single fail of bt_index_parent_check but
it was an issue with bt_index_parent_check itself) [9].
PART 2
Resetting snapshots during the first phase of CIC (does not depend on anything)
It is based on Matthias' idea [10] - to just reset snapshots every so
often during a concurrent index build. It may work only during the
first scan (because we'll miss some tuples anyway during validation
scan with such approach).
Logic is simple – since the index built by the first scan already
misses a lot of tuples – we may not worry to miss a few more – the
validation phase is going to fix it anyway. Of course it is not so
simple in case of unique indexes, but still possible.
Once committed: xmin is advanced at least during the first phase of
concurrent index build.
Commits are:
- Reset snapshots periodically in non-unique non-parallel concurrent
index builds
Apply this technique to the simplest case – non-unique and
non-parallel. Snapshot is changed "between" pages.
One possible place here to worry about – to ensure xmin advanced we
need to call InvalidateCatalogSnapshot during each snapshot switch.
So, theoretically it may cause some issues, but the table is locked to
changes during the process. At least commit [3] (which ignored xmin of
CIC backend) did the same thing actually.
Another more "clear" option here - we may just extract a separate
catalog snapshot horizon (one more field near xmin specially only for
catalog snapshot), it seems to be a pretty straightforward change).
- Support snapshot resets in parallel concurrent index builds
Extend that technique to parallel builds. It is mostly about ensuring
workers have an initial snapshot restored from the leader before the
leader goes to reset it.
- Support snapshot resets in concurrent builds of unique indexes
The most tricky commit in the second part – apply that to unique
indexes. Changing of snapshots may cause issues with validation of
unique constraints. Currently validation is done during the sorting of
tuples, but that doesn't work with tuples read with different
snapshots (some of them are dead already). To deal with it:
- in case we see two identical tuples during tuplesort – ignore if
some of them are dead according to SnapshotSelf, but fail if two are
alive. It is not a required part, it is just mechanics for fail-fast
behavior and may be removed.
- to provide the guarantee – during _bt_load compare the inserted
index value with previously inserted. If they are equal – make sure
only a single SnapshotSelf alive tuple exists in the whole equal
"group" (it may include more than two tuples in general).
Theoretically it may affect performance of _bt_load because of
_bt_keep_natts(_fast) call for each tuple, but I was unable to notice
any significant difference here. Anyway it is compensated by Part 3
for sure.
PART 3
STIR-based validation phase CIC (does not depend on anything)
That part is about a way to replace the second phase of CIC in a more
effective way (and with the ability to allow horizon advance as an
additional bonus).
The role of the second phase is to find tuples which are not present
in the index built by the first scan, because:
- some of them were too new for the snapshot used during the first phase
- even if we were to use SnapshotSelf to accept all alive tuples –
some of them may be inserted in pages already visited by the scan
The main idea is:
- before starting the first scan lets prepare a special auxiliary
super-lightweight index (it is not even an index or access method,
just pretends to be) with the same columns, expressions and predicates
- that access method (Short Term Index Replacement – STIR) just
appends TID of new coming tuples, without WAL, minimum locking,
simplest append-only structure, without actual indexed data
- it remembers all new TIDs inserted to the table during the first phase
- once our main (target) index receives updates itself we may safely
clear "ready" flag on STIR
- if our first phase scan missed something – it is guaranteed to be
present in that STIR index
- so, instead of requirement to compare the whole table to the index,
we need only to compare to TIDs stored in the STIR
- as a bonus we may reset snapshots during the comparison without risk
of any issues caused by HOT pruning (the issue [4] caused revert of
[3]).
That approach provides a significant performance boost in terms of
time required to build the index. STIR itself theoretically causes
some performance impact, but I was not able to detect it. Also, some
optimizations are applied to it (see below). Details of benchmarks are
presented below as well.
Commits are:
- Add STIR access method and flags related to auxiliary indexes
This one adds STIR code and some flags to distinguish real and
auxiliary indexes.
- Add Datum storage support to tuplestore
Add ability to store Datum in tuplestore. It is used by the following
commits to leverage performance boost from prefetching of the pages
during validation phase.
- Use auxiliary indexes for concurrent index operations
The main part is here. It contains all the logic for creation of
auxiliary index, managing its lifecycle, new validation phase and so
on (including progress reporting, some documentation updates, ability
to have unlogged index for logged table, etc). At the same time it
still relies on a single referenced snapshot during the validation
phase.
- Track and drop auxiliary indexes in DROP/REINDEX
That commit adds different techniques to avoid any additional
administration requirements to deal with auxiliary indexes in case of
error during the index build (junk auxiliary indexes). It adds
dependency tracking, special logic for handling REINDEX calls and
other small things to make administrator's life a little bit easier.
- Optimize auxiliary index handling
Since the STIR index does not contain any actual data we may skip
preparation of that during tuple insert. Commit implements such
optimization.
- Refresh snapshot periodically during index validation
Adds logic to the new validation phase to reset the snapshot every so
often. Currently it does it every 4096 pages visited.
PART 4 (depends on part 2 and part 3)
Commits are:
- Remove PROC_IN_SAFE_IC optimization
This is a small part which makes sense in case both parts 2 and 3 were
applied. Once it's done – CIC does not prevent the horizon from
advancing regularly.
It makes the PROC_IN_SAFE_IC optimization [11] obsolete, because one
CIC now has no issue waiting for the xmin of the other (because it
advances regularly).
BENCHMARKS
I have spent a lot of time benchmarking the patch in different
environments (local SSD, local SSD with 1ms delay, io2 AWS) and the
results look impressive.
I can't measure any performance (or significant space usage)
degradation because of STIR index presence, but performance boost
because of new validation phases gives up to 3x -4x time boost. And
without any VACUUM-related issues during that time (so, other
operations on the databases will benefit from that easily compensating
additional STIR-related cost).
Description of benchmarks are available here [12].
Some results are here: [13] and here [14], code is here [15].
There is also a Discord thread here [16].
Feel free to ask any question and request benchmarks for some scenarios.
Best regards,
Mikhail.
[1]: https://discord.com/channels/1258108670710124574/1334565506149253150/1339368558408372264
[2]: https://www.postgresql.org/message-id/flat/20210115142926.GA19300%40alvherre.pgsql#0988173cb0cf4b8eb710a6cdaa88fcac
[3]: https://github.com/postgres/postgres/commit/d9d076222f5b94a85e0e318339cfc44b8f26022d
[4]: https://www.postgresql.org/message-id/flat/20220524190133.j6ee7zh4f5edt5je%40alap3.anarazel.de#1781408f40034c414ad6738140c118ef
[5]: https://github.com/postgres/postgres/commit/e28bb885196916b0a3d898ae4f2be0e38108d81b
[6]: https://www.postgresql.org/message-id/flat/202205251643.2py5jjpaw7wy%40alvherre.pgsql#589508d30b480b905619dcb93dac8cf8
[7]: https://www.postgresql.org/message-id/flat/20220525170821.rf6r4dnbbu4baujp%40alap3.anarazel.de#accf63164fd552b6ad68ff0a870e60c0
[8]: https://commitfest.postgresql.org/patch/5160/
[9]: https://commitfest.postgresql.org/patch/5438/
[10]: https://www.postgresql.org/message-id/flat/CAEze2WgW6pj48xJhG_YLUE1QS%2Bn9Yv0AZQwaWeb-r%2BX%3DHAxU_g%40mail.gmail.com#b3809c158de4481bb1b29894aaa63fae
[11]: https://github.com/postgres/postgres/commit/c98763bf51bf610b3ee7e209fc76c3ff9a6b3163
[12]: https://www.postgresql.org/message-id/flat/CANtu0ojHAputNCH73TEYN_RUtjLGYsEyW1aSXmsXyvwf%3D3U4qQ%40mail.gmail.com#b18fb8efab086bc22af1cb015e187cb7
[13]: https://www.postgresql.org/message-id/flat/CANtu0ojiVez054rKvwZzKNhneS2R69UXLnw8N9EdwQwqfEoFdQ%40mail.gmail.com#02b4ee45a5a5c1ccac6d168052173952
[14]: https://docs.google.com/spreadsheets/d/1UYaqpsWSfYdZdQxaqY4gVo0RW6KrT0d-U1VDNJB8lVk/edit?usp=sharing
[15]: https://gist.github.com/michail-nikolaev/b33fb0ac1f35729388c89f72db234b0f
[16]: https://discord.com/channels/1258108670710124574/1259884843165155471/1334565506149253150

{kind=link}
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | alvherre(at)alvh(dot)no-ip(dot)org, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-05-18 15:09:00 |
| Message-ID: | CADzfLwW9QczZW-E=McxcjUv0e5VMDctQNETbgao0K-SimVhFPA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
Rebased version + materials from PGConf.dev 2025 Poster Session :)
Best regards,
Mikhail.
| From: | Álvaro Herrera <alvherre(at)kurilemu(dot)de> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-05-18 15:56:54 |
| Message-ID: | 202505181556.3n6oiowvntyr@alvherre.pgsql |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello Mihail,
On 2025-May-18, Mihail Nikalayeu wrote:
> Hello, everyone!
>
> Rebased version + materials from PGConf.dev 2025 Poster Session :)
I agree with Matthias that this work is important, so thank you for
persisting on it.
I didn't understand why you have a few "v19" patches and also a separate
series of "v19-only-part-3-" patches. Is there duplication? How do
people know which series comes first?
I think it would be better to get the PDF poster in a wiki page ... in
fact I would suggest to Andrey that he could start a wiki page with all
the PDFs presented at the conference. Distributing a bunch of 2 MB pdf
via the mailing list doesn't sound too great an idea to me. A few
people are having trouble with email quotas in cloud services, and the
list server gets bothered because of it. Kindly don't do that anymore.
Regards
--
Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Álvaro Herrera <alvherre(at)kurilemu(dot)de> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-05-18 16:09:29 |
| Message-ID: | CADzfLwXKtriMnfCNVGNH2ahwXaByjo-QOMWiDTU-9WZqh+zQ5g@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Álvaro!
> I didn't understand why you have a few "v19" patches and also a separate
> series of "v19-only-part-3-" patches. Is there duplication? How do
> people know which series comes first?
This was explained in the previous email [0]:
> Patch itself contains 4 parts, some of them may be reviewed/committed
> separately. All commit messages are detailed and contain additional
> explanation of changes.
> To not confuse CFBot, commits are presented in the following way: part
> 1, 2, 3 and 4. If you want only part 3 to test/review – check the
> files with "patch_" extensions. They differ a little bit, but changes
> are minor.
If you have an idea of a better way to handle it, please share. Yes,
the current approach is a bit odd.
> I think it would be better to get the PDF poster in a wiki page ... in
> fact I would suggest to Andrey that he could start a wiki page with all
> the PDFs presented at the conference. Distributing a bunch of 2 MB pdf
> via the mailing list doesn't sound too great an idea to me. A few
> people are having trouble with email quotas in cloud services, and the
> list server gets bothered because of it. Kindly don't do that anymore.
Oh, you're right—I just didn't think of that. My bad, sorry about that.
Best regards,
Mikhail.
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Álvaro Herrera <alvherre(at)kurilemu(dot)de> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-05-23 21:59:00 |
| Message-ID: | CADzfLwW5bDWSxjHK7mqX8Lewki3+5FBydBC+nVcxg4xMGKscyw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
Rebased, patch structure and comments available here [0]. Quick
introduction poster - here [1].
Best regards,
Mikhail.
[0]: https://www.postgresql.org/message-id/flat/CADzfLwVOcZ9mg8gOG%2BKXWurt%3DMHRcqNv3XSECYoXyM3ENrxyfQ%40mail.gmail.com#52c97e004b8f628473124c05e3bf2da1
[1]: https://www.postgresql.org/message-id/attachment/176651/STIR-poster.pdf
| From: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-06-16 16:17:33 |
| Message-ID: | CAMAof6-4xaV3QE2ErYJaJhu6qjFn99sWyo_HQeBhHikZM3GexA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hey Mihail,
I've started looking at the patches today, mostly the STIR part. Seems
solid, but I've got a question about validation. Why are we still grabbing
tids from the main index and sorting them?
I think it's to avoid duplicate errors when adding tuples from STIP to the
main index, but couldn't we just suppress that error during validation and
skip the new tuple insertion if it already exists?
The main index may get huge after building, and iterating over it in a
single thread and then sorting tids can be time consuming.
At least I guess one can skip it when STIP is empty. But, I think we could
skip it altogether by figuring out what to do with duplicates, making
concurrent and non-concurrent index creation almost identical in speed
(only locking and atomicity would differ).
p.s. I noticed that `stip.c` has a lot of functions that don't follow the
Postgres coding style of return type on separate line.
On Mon, Jun 16, 2025, 6:41 PM Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>
wrote:
> Hello, everyone!
>
> Rebased, patch structure and comments available here [0]. Quick
> introduction poster - here [1].
>
> Best regards,
> Mikhail.
>
> [0]:
> https://www.postgresql.org/message-id/flat/CADzfLwVOcZ9mg8gOG%2BKXWurt%3DMHRcqNv3XSECYoXyM3ENrxyfQ%40mail.gmail.com#52c97e004b8f628473124c05e3bf2da1
> [1]:
> https://www.postgresql.org/message-id/attachment/176651/STIR-poster.pdf
>
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-06-16 20:00:59 |
| Message-ID: | CADzfLwXocKhpW3eFP1oScz+m+1XJ3bpi9QmVpoqC9RX9oyX=UA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Sergey!
> I think it's to avoid duplicate errors when adding tuples from STIP to the main index,
> but couldn't we just suppress that error during validation and skip the new tuple insertion if it already exists?
In some cases, it is not possible:
– Some index types (GiST, GIN, BRIN) do not provide an easy way to
detect such duplicates.
– When we are building a unique index, we cannot simply skip
duplicates, because doing so would also skip the rows that should
prevent the unique index from being created (unless we add extra logic
for B-tree indexes to compare TIDs as well).
> The main index may get huge after building, and iterating over it in a single thread and then sorting tids can be time consuming.
My tests indicate that the overhead is minor compared with the time
spent scanning the heap and building the index itself.
> At least I guess one can skip it when STIP is empty.
Yes, that’s a good idea; I’ll add it later.
> p.s. I noticed that `stip.c` has a lot of functions that don't follow the Postgres coding style of return type on separate line.
Hmm... I’ll fix that as well.
Best regards,
Mikhail.
| From: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-06-16 20:21:47 |
| Message-ID: | CAMAof695VA+mbVRhWCTus=E0WnsMAQyqXxfOTohbcb7VUHSP4g@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Thank you for the information. Tomorrow, I will also run a few tests to
measure the time required to collect tids from the index; however, since I
do not work with vanilla postgres, the results may vary.
If the results indicate that this procedure is time-consuming, I maybe will
develop an additional patch specifically for b-tree indexes, as they are
the default and most commonly used type.
Best regards,
Sergey
On Mon, Jun 16, 2025, 11:01 PM Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>
wrote:
> Hello, Sergey!
>
> > I think it's to avoid duplicate errors when adding tuples from STIP to
> the main index,
> > but couldn't we just suppress that error during validation and skip the
> new tuple insertion if it already exists?
>
> In some cases, it is not possible:
> – Some index types (GiST, GIN, BRIN) do not provide an easy way to
> detect such duplicates.
> – When we are building a unique index, we cannot simply skip
> duplicates, because doing so would also skip the rows that should
> prevent the unique index from being created (unless we add extra logic
> for B-tree indexes to compare TIDs as well).
>
> > The main index may get huge after building, and iterating over it in a
> single thread and then sorting tids can be time consuming.
> My tests indicate that the overhead is minor compared with the time
> spent scanning the heap and building the index itself.
>
> > At least I guess one can skip it when STIP is empty.
> Yes, that’s a good idea; I’ll add it later.
>
> > p.s. I noticed that `stip.c` has a lot of functions that don't follow
> the Postgres coding style of return type on separate line.
> Hmm... I’ll fix that as well.
>
> Best regards,
> Mikhail.
>
| From: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-06-17 15:55:54 |
| Message-ID: | CAMAof69JSL8MYWG2qRScs3RQDpfcyZT_wFwW4SoAvftW+K_p1g@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello Mihail,
In patch v20-0006-Add-STIR-access-method-and-flags-related-to-auxi.patch,
within the "StirMarkAsSkipInserts" function, a critical section appears to
be left unclosed. This resulted in an assertion failure during ANALYZE of a
table containing a leftover STIR index.
Best regards,
Sergey
On Mon, Jun 16, 2025, 11:21 PM Sergey Sargsyan <
sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> wrote:
> Thank you for the information. Tomorrow, I will also run a few tests to
> measure the time required to collect tids from the index; however, since I
> do not work with vanilla postgres, the results may vary.
>
> If the results indicate that this procedure is time-consuming, I maybe
> will develop an additional patch specifically for b-tree indexes, as they
> are the default and most commonly used type.
>
> Best regards,
> Sergey
>
>
> On Mon, Jun 16, 2025, 11:01 PM Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>
> wrote:
>
>> Hello, Sergey!
>>
>> > I think it's to avoid duplicate errors when adding tuples from STIP to
>> the main index,
>> > but couldn't we just suppress that error during validation and skip the
>> new tuple insertion if it already exists?
>>
>> In some cases, it is not possible:
>> – Some index types (GiST, GIN, BRIN) do not provide an easy way to
>> detect such duplicates.
>> – When we are building a unique index, we cannot simply skip
>> duplicates, because doing so would also skip the rows that should
>> prevent the unique index from being created (unless we add extra logic
>> for B-tree indexes to compare TIDs as well).
>>
>> > The main index may get huge after building, and iterating over it in a
>> single thread and then sorting tids can be time consuming.
>> My tests indicate that the overhead is minor compared with the time
>> spent scanning the heap and building the index itself.
>>
>> > At least I guess one can skip it when STIP is empty.
>> Yes, that’s a good idea; I’ll add it later.
>>
>> > p.s. I noticed that `stip.c` has a lot of functions that don't follow
>> the Postgres coding style of return type on separate line.
>> Hmm... I’ll fix that as well.
>>
>> Best regards,
>> Mikhail.
>>
>
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-06-18 10:49:51 |
| Message-ID: | CADzfLwVMtwjHh8KY9kP=_vcYPqHs=JDzuexO4RFQ2fM8VoqovA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Sergey!
> In patch v20-0006-Add-STIR-access-method-and-flags-related-to-auxi.patch, within the "StirMarkAsSkipInserts" function, a critical section appears to be left unclosed. This resulted in an assertion failure during ANALYZE of a table containing a leftover STIR index.
Thanks, good catch. I'll add it to batch fix with the other things.
Best regards,
Mikhail.
| From: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-06-18 16:33:07 |
| Message-ID: | CAMAof68L0GO0F0bwuXtLZAjh9k_Hj+o0-8mqfO6iEQyXr4PuVA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
Today I encountered a segmentation fault caused by the patch
v20-0007-Add-Datum-storage-support-to-tuplestore.patch. During the merge
phase, I inserted some tuples into the table so that STIR would have data
for the validation phase. The segfault occurred during a call to
tuplestore_end().
The root cause is that a few functions in the tuplestore code still assume
that all stored data is a pointer and thus attempt to pfree it. This
assumption breaks when datumByVal is used, as the data is stored directly
and not as a pointer. In particular, tuplestore_end(), tuplestore_trim(),
and tuplestore_clear() incorrectly try to free such values.
When addressing this, please also ensure that context memory accounting is
handled properly: we should not increment or decrement the remaining
context memory size when cleaning or trimming datumByVal entries, since no
actual memory was allocated for them.
Interestingly, I’m surprised you haven’t hit this segfault yourself. Are
you perhaps testing on an older system where INT8OID is passed by
reference? Or is your STIR always empty during the validation phase?
One more point: I noticed you modified the index_create() function
signature. You added the relpersistence parameter, which seems
unnecessary—this can be determined internally by checking if it’s an
auxiliary index, in which case the index should be marked as unlogged. You
also added an auxiliaryIndexOfOid argument (do not remember exact naming,
but was used for dependency). It might be cleaner to pass this via the
IndexInfo structure instead. index_create() already has dozens of mouthful
arguments, and external extensions (like pg_squeeze) still rely on the old
signature, so minimizing changes to the function interface would improve
compatibility.
Best regards,
Sergey
On Wed, Jun 18, 2025, 1:50 PM Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>
wrote:
> Hello, Sergey!
>
> > In patch
> v20-0006-Add-STIR-access-method-and-flags-related-to-auxi.patch, within the
> "StirMarkAsSkipInserts" function, a critical section appears to be left
> unclosed. This resulted in an assertion failure during ANALYZE of a table
> containing a leftover STIR index.
> Thanks, good catch. I'll add it to batch fix with the other things.
>
> Best regards,
> Mikhail.
>
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-06-18 21:15:28 |
| Message-ID: | CADzfLwUrodAcOggK+3j3LbPLaSXemgHxa-n=LhZTwRAsaakL2g@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Sergey!
> Today I encountered a segmentation fault caused by the patch v20-0007-Add-Datum-storage-support-to-tuplestore.patch. During the merge phase, I inserted some tuples into the table so that STIR would have data for the validation phase. The segfault occurred during a call to tuplestore_end().
>
> The root cause is that a few functions in the tuplestore code still assume that all stored data is a pointer and thus attempt to pfree it. This assumption breaks when datumByVal is used, as the data is stored directly and not as a pointer. In particular, tuplestore_end(), tuplestore_trim(), and tuplestore_clear() incorrectly try to free such values.
>
> When addressing this, please also ensure that context memory accounting is handled properly: we should not increment or decrement the remaining context memory size when cleaning or trimming datumByVal entries, since no actual memory was allocated for them.
>
> Interestingly, I’m surprised you haven’t hit this segfault yourself. Are you perhaps testing on an older system where INT8OID is passed by reference? Or is your STIR always empty during the validation phase?
Thanks for pointing that out. It looks like tuplestore_trim and
tuplestore_clear are broken, while tuplestore_end seems to be correct
but fails due to previous heap corruption.
In my case, tuplestore_trim and tuplestore_clear aren't called at all
- that's why the issue wasn't detected. I'm not sure why; perhaps some
recent changes in your codebase are affecting that?
Please run a stress test (if you've already applied the in-place fix
for the tuplestore):
ninja && meson test --suite setup && meson test
--print-errorlogs --suite pg_amcheck *006*
This will help ensure everything else is working correctly on your system.
> One more point: I noticed you modified the index_create() function signature. You added the relpersistence parameter, which seems unnecessary—
> this can be determined internally by checking if it’s an auxiliary index, in which case the index should be marked as unlogged. You also added an
> auxiliaryIndexOfOid argument (do not remember exact naming, but was used for dependency). It might be cleaner to pass this via the IndexInfo structure
> instead. index_create() already has dozens of mouthful arguments, and external extensions
> (like pg_squeeze) still rely on the old signature, so minimizing changes to the function interface would improve compatibility.
Yes, that’s probably a good idea. I was trying to keep it simple from
the perspective of parameters to avoid dealing with some of the tricky
internal logic.
But you're right - it’s better to stick with the old signature.
Best regards,
Mikhail.
| From: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-06-18 21:36:43 |
| Message-ID: | CAMAof691D4O=3QTuPwJXBYxYpG6s3A=tVhL9vN=T3eeRTMnaig@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
My bad, my fork's based on pg15, and over there tuplestore_end() does this,
void
tuplestore_end(Tuplestorestate *state)
{
int i;
if (state->myfile)
BufFileClose(state->myfile);
if (state->memtuples)
{
for (i = state->memtupdeleted; i < state->memtupcount; i++)
pfree(state->memtuples[i]);
pfree(state->memtuples);
}
pfree(state->readptrs);
pfree(state);
}
It lets each tuple go one by one, but in pg18, it just nukes the whole
memory context instead.
Therefore, over pg18 patch presents no issues; however, incorporating
`_clean` and `_trim` functions for datum cases is recommended to prevent
future developers from encountering segmentation faults when utilizing the
interface. This minor adjustment should ensure expected functionality.
Best regards,
S
On Thu, Jun 19, 2025, 12:16 AM Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>
wrote:
> Hello, Sergey!
>
> > Today I encountered a segmentation fault caused by the patch
> v20-0007-Add-Datum-storage-support-to-tuplestore.patch. During the merge
> phase, I inserted some tuples into the table so that STIR would have data
> for the validation phase. The segfault occurred during a call to
> tuplestore_end().
> >
> > The root cause is that a few functions in the tuplestore code still
> assume that all stored data is a pointer and thus attempt to pfree it. This
> assumption breaks when datumByVal is used, as the data is stored directly
> and not as a pointer. In particular, tuplestore_end(), tuplestore_trim(),
> and tuplestore_clear() incorrectly try to free such values.
> >
> > When addressing this, please also ensure that context memory accounting
> is handled properly: we should not increment or decrement the remaining
> context memory size when cleaning or trimming datumByVal entries, since no
> actual memory was allocated for them.
> >
> > Interestingly, I’m surprised you haven’t hit this segfault yourself. Are
> you perhaps testing on an older system where INT8OID is passed by
> reference? Or is your STIR always empty during the validation phase?
>
> Thanks for pointing that out. It looks like tuplestore_trim and
> tuplestore_clear are broken, while tuplestore_end seems to be correct
> but fails due to previous heap corruption.
> In my case, tuplestore_trim and tuplestore_clear aren't called at all
> - that's why the issue wasn't detected. I'm not sure why; perhaps some
> recent changes in your codebase are affecting that?
>
> Please run a stress test (if you've already applied the in-place fix
> for the tuplestore):
> ninja && meson test --suite setup && meson test
> --print-errorlogs --suite pg_amcheck *006*
>
> This will help ensure everything else is working correctly on your system.
>
> > One more point: I noticed you modified the index_create() function
> signature. You added the relpersistence parameter, which seems unnecessary—
> > this can be determined internally by checking if it’s an auxiliary
> index, in which case the index should be marked as unlogged. You also added
> an
> > auxiliaryIndexOfOid argument (do not remember exact naming, but was used
> for dependency). It might be cleaner to pass this via the IndexInfo
> structure
> > instead. index_create() already has dozens of mouthful arguments, and
> external extensions
> > (like pg_squeeze) still rely on the old signature, so minimizing changes
> to the function interface would improve compatibility.
>
> Yes, that’s probably a good idea. I was trying to keep it simple from
> the perspective of parameters to avoid dealing with some of the tricky
> internal logic.
> But you're right - it’s better to stick with the old signature.
>
> Best regards,
> Mikhail.
>
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-06-21 20:32:44 |
| Message-ID: | CADzfLwVT3Y14g6Maz2y92sP2L7rPvpznt+MHM++xiy-U3XMLZQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Sergey!
I have addressed your comments:
* skip TID scan in case of empty STIR index
* fix for critical section
* formatting
* index_create signature
Rebased, patch structure and comments available here [0]. Quick
introduction poster - here [1].
Best regards,
Mikhail.
[0]:
https://www.postgresql.org/message-id/flat/CADzfLwVOcZ9mg8gOG%2BKXWurt%3DMHRcqNv3XSECYoXyM3ENrxyfQ%40mail.gmail.com#52c97e004b8f628473124c05e3bf2da1
[1]: https://www.postgresql.org/message-id/attachment/176651/STIR-poster.pdf
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-07-03 00:23:09 |
| Message-ID: | CADzfLwXQe9XfQfJs3W-DCPqeqG4rq-6FoYUpGbbpgjcT1Eotpg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
Rebased again, patch structure and comments available here [0]. Quick
introduction poster - here [1].
Best regards,
Mikhail.
[0]: https://www.postgresql.org/message-id/flat/CADzfLwVOcZ9mg8gOG%2BKXWurt%3DMHRcqNv3XSECYoXyM3ENrxyfQ%40mail.gmail.com#52c97e004b8f628473124c05e3bf2da1
[1]: https://www.postgresql.org/message-id/attachment/176651/STIR-poster.pdf
| From: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-07-07 12:00:37 |
| Message-ID: | CAMAof68kNgwWdkhmZd1ysfyU3PF66Wz+UaUr9g-LJg-_0xBV_Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I’ve tested the patch across several thousand test cases, and no faults of
any kind have been observed.
Additionally, I independently built a closed banking transaction system to
verify consistency during REINDEX CONCURRENTLY while multiple backends were
writing simultaneously. The results showed no missing transactions, and the
validation logic worked exactly as expected. On large tables, I observed a
significant speedup—often several times faster.
I believe this patch is highly valuable, as REINDEX CONCURRENTLY is a
common maintenance operation. I also noticed that there is a separate
thread working on adding support for concurrent reindexing of partitioned
indexes. Without this patch, that feature would likely suffer from serious
performance issues due to the need to reindex many indexes in one go—making
the process both time-consuming and lock-intensive.
Best regards,
S
On Thu, Jul 3, 2025, 3:24 AM Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>
wrote:
> Hello!
>
> Rebased again, patch structure and comments available here [0]. Quick
> introduction poster - here [1].
>
> Best regards,
> Mikhail.
>
> [0]:
> https://www.postgresql.org/message-id/flat/CADzfLwVOcZ9mg8gOG%2BKXWurt%3DMHRcqNv3XSECYoXyM3ENrxyfQ%40mail.gmail.com#52c97e004b8f628473124c05e3bf2da1
> [1]:
> https://www.postgresql.org/message-id/attachment/176651/STIR-poster.pdf
>
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-07-10 14:30:15 |
| Message-ID: | CADzfLwUtLqYrupZp4QQuWwv4W_LgYWBRStybvQ+S0SZiHrp62A@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
Added patch to the offer book of review marketplace [0].
Best regards,
Mikhail.
[0]: https://wiki.postgresql.org/wiki/Review_Marketplace#Offer_book
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-09-05 00:25:56 |
| Message-ID: | CADzfLwVYUBb8cUVQ_1mzVzNMyJH84VZKFCRyATvBZKbLW377CA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
Rebased, patch structure and comments available here [0].
Quick introduction poster - here [1].
[0]: https://www.postgresql.org/message-id/flat/CADzfLwVOcZ9mg8gOG%2BKXWurt%3DMHRcqNv3XSECYoXyM3ENrxyfQ%40mail.gmail.com#52c97e004b8f628473124c05e3bf2da1
[1]: https://www.postgresql.org/message-id/attachment/176651/STIR-poster.pdf
Best regards,
Mikhail.
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-09-28 09:26:00 |
| Message-ID: | CADzfLwWbV1i7+cP_Hqr3qgQnBXkAqgrCQxd5PFzqp2AOTK=40w@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, everyone!
Rebased, patch structure and comments available here [0].
Quick introduction poster - here [1].
[0]: https://www.postgresql.org/message-id/flat/CADzfLwVOcZ9mg8gOG%2BKXWurt%3DMHRcqNv3XSECYoXyM3ENrxyfQ%40mail.gmail.com#52c97e004b8f628473124c05e3bf2da1
[1]: https://www.postgresql.org/message-id/attachment/176651/STIR-poster.pdf
Best regards,
Mikhail.
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-10-28 18:37:00 |
| Message-ID: | CADzfLwXJc0jdDDS43-Fj0gKmwX-FURS3eY7MyLQ89qDPA6T5Ug@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Fixed and assert caused
https://cirrus-ci.com/task/4890065790304256?logs=test_world#L157 to
fail.
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-09 18:02:00 |
| Message-ID: | CADzfLwVaV15R2rUNZmKqLKweiN3SnUBg=6_qGE_ERb7cdQUD8g@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
This is a rebased version.
Also I decided to keep only part 3 for now, because we need some
common solution to keep the horizon advance for both INDEX and REPACK
operations [0].
More complex solution description and benchmark results are available at [3].
PART 3
STIR-based validation phase CIC
That part is about a way to replace the second phase of CIC in a more
effective way (and with the ability to allow horizon advance as an
additional bonus).
The role of the second phase is to find tuples which are not present
in the index built by the first scan, because:
- some of them were too new for the snapshot used during the first phase
- even if we were to use SnapshotSelf to accept all alive tuples –
some of them may be inserted in pages already visited by the scan
The main idea is:
- before starting the first scan lets prepare a special auxiliary
super-lightweight index (it is not even an index or access method,
just pretends to be) with the same columns, expressions and predicates
- that access method (Short Term Index Replacement – STIR) just
appends TID of new coming tuples, without WAL, minimum locking,
simplest append-only structure, without actual indexed data
- it remembers all new TIDs inserted to the table during the first phase
- once our main (target) index receives updates itself we may safely
clear "ready" flag on STIR
- if our first phase scan missed something – it is guaranteed to be
present in that STIR index
- so, instead of requirement to compare the whole table to the index,
we need only to compare to TIDs stored in the STIR
- as a bonus we may reset snapshots during the comparison without risk
of any issues caused by HOT pruning (the issue [2] caused revert of
[1]).
That approach provides a significant performance boost in terms of
time required to build the index. STIR itself theoretically causes
some performance impact, but I was not able to detect it. Also, some
optimizations are applied to it (see below). Details of benchmarks are
presented below as well.
Commits are:
- Add STIR access method and flags related to auxiliary indexes
This one adds STIR code and some flags to distinguish real and
auxiliary indexes.
- Add Datum storage support to tuplestore
Add ability to store Datum in tuplestore. It is used by the following
commits to leverage performance boost from prefetching of the pages
during the validation phase.
- Use auxiliary indexes for concurrent index operations
The main part is here. It contains all the logic for creation of
auxiliary index, managing its lifecycle, new validation phase and so
on (including progress reporting, some documentation updates, ability
to have an unlogged index for logged tables, etc). At the same time it
still relies on a single referenced snapshot during the validation
phase.
- Track and drop auxiliary indexes in DROP/REINDEX
That commit adds different techniques to avoid any additional
administration requirements to deal with auxiliary indexes in case of
error during the index build (junk auxiliary indexes). It adds
dependency tracking, special logic for handling REINDEX calls and
other small things to make the administrator's life a little bit easier.
- Optimize auxiliary index handling
Since the STIR index does not contain any actual data we may skip
preparation of that during tuple insert. Commit implements such
optimization.
- Refresh snapshot periodically during index validation
Adds logic to the new validation phase to reset the snapshot every so
often. Currently it does it every 4096 pages visited.
Probably a caveat here is the requirement to call
InvalidateCatalogSnapshot to make sure xmin propagates.
But AFAIK the same may happen between transaction boundaries in CIC
anyway - and ShareUpdateExclusiveLock on table is enough.
[0]: https://www.postgresql.org/message-id/flat/202510301734.pj4uds3mqxx4%40alvherre.pgsql#fd20662912580a89b860790f9729aaff
[1]: https://github.com/postgres/postgres/commit/d9d076222f5b94a85e0e318339cfc44b8f26022d
[2]: https://www.postgresql.org/message-id/flat/20220524190133.j6ee7zh4f5edt5je%40alap3.anarazel.de#1781408f40034c414ad6738140c118ef
[3]: https://www.postgresql.org/message-id/CADzfLwVOcZ9mg8gOG+KXWurt=MHRcqNv3XSECYoXyM3ENrxyfQ@mail.gmail.com
Best regards,
Mikhail.
| Attachment | Content-Type | Size |
|---|---|---|
| v26-0005-Use-auxiliary-indexes-for-concurrent-index-opera.patch | text/plain | 94.4 KB |
| v26-0001-This-is-https-commitfest.postgresql.org-50-5160-.patch | text/plain | 23.2 KB |
| v26-0003-Add-STIR-access-method-and-flags-related-to-auxi.patch | text/plain | 37.3 KB |
| v26-0002-Add-stress-tests-for-concurrent-index-builds.patch | text/plain | 9.1 KB |
| v26-0004-Add-Datum-storage-support-to-tuplestore.patch | text/plain | 19.0 KB |
| v26-0006-Track-and-drop-auxiliary-indexes-in-DROP-REINDEX.patch | text/plain | 30.5 KB |
| v26-0007-Optimize-auxiliary-index-handling.patch | text/plain | 2.4 KB |
| v26-0008-Refresh-snapshot-periodically-during-index-valid.patch | text/plain | 20.8 KB |
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com> |
| Cc: | Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-22 17:08:00 |
| Message-ID: | CADzfLwWrGYGE8=cg+6C57Nypv1Y-1mBv8BVzzPWVJy5EfR6YfQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Reduced memory used by stress-test to avoid OOM in CI.
Best regards,
Mikhail.
| Attachment | Content-Type | Size |
|---|---|---|
| v27-0007-Optimize-auxiliary-index-handling.patch | text/plain | 2.4 KB |
| v27-0008-Refresh-snapshot-periodically-during-index-valid.patch | text/plain | 20.8 KB |
| v27-0006-Track-and-drop-auxiliary-indexes-in-DROP-REINDEX.patch | text/plain | 30.5 KB |
| v27-0005-Use-auxiliary-indexes-for-concurrent-index-opera.patch | text/plain | 94.4 KB |
| v27-0004-Add-Datum-storage-support-to-tuplestore.patch | text/plain | 19.0 KB |
| v27-0003-Add-STIR-access-method-and-flags-related-to-auxi.patch | text/plain | 37.3 KB |
| v27-0001-This-is-https-commitfest.postgresql.org-50-5160-.patch | text/plain | 23.2 KB |
| v27-0002-Add-stress-tests-for-concurrent-index-builds.patch | text/plain | 9.3 KB |
| From: | Antonin Houska <ah(at)cybertec(dot)at> |
|---|---|
| To: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-27 16:56:25 |
| Message-ID: | 17483.1764262585@localhost |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> wrote:
> I think about revisiting (1) ({CREATE INDEX, REINDEX} CONCURRENTLY
> improvements) in some lighter way.
I haven't read the whole thread yet, but the effort to minimize the impact of
C/RIC on VACUUM seems to prevail. Following is one more proposal. The core
idea is that C/RIC should avoid indexing dead tuples, however snapshot is not
necessary to distinguish dead tuple from a live one. And w/o snapshot, the
backend executing C/RIC does not restrict VACUUM on other tables.
Concurrent (re)build of unique index appears to be another topic of this
thread, but I think this approach should handle the problem too. The workflow
is:
1. Create an empty index.
2. Wait until all transactions are aware of the index, so they take the new
index into account when deciding on new HOT chains. (This is already
implemented.)
3. Set the 'indisready' flag so the index is ready for insertions.
4. While other transactions can insert their tuples into the index now,
process the table one page at a time this way:
4.1 Acquire (shared) content lock on the buffer.
4.3 Collect the root tuples of HOT chains - these and only these need to be
inserted into the index.
4.4 Unlock the buffer.
5. Once the whole table is processed, insert the collected tuples into the
index.
To avoid insertions of tuples that concurrent transactions have just
inserted, we'd need something like index.c:validate_index() (i.e. insert
into the index only the tuples that it does not contain yet), but w/o
snapshot because we already have the heap tuples collected.
Also it'd make sense to wait for completion of all the transactions that
currently have the table locked for INSERT/UPDATE: some of these might have
inserted their tuples into the heap, but not yet into the index. If we
included some of those tuples into our collection and insert them into the
index first, the other transactions could end up with ERROR when inserting
those tuples again.
6. Set the 'indisvalid' flag so that the index can be used by queries.
Note on pruning: As we only deal with the root tuples of HOT chains (4.3),
page pruning triggered by queries (heap_page_prune_opt) should not be
disruptive. Actually C/RIC can do the pruning itself it it appears to be
useful. For example, if whole HOT chain should be considered DEAD by the next
VACUUM, pruning is likely (depending on the OldestXid) to remove it so that we
do not insert TID of the root tuple into the index unnecessarily.
I can even think of letting VACUUM run on the same table that C/RIC is
processing. In that case, interlocking would take place at page level: either
C/RIC or VACUUM can acquire lock for particular page, but not both. This would
be useful in cases C/RIC takes very long time.
In this case, C/RIC *must not* insert TIDs of dead tuples into the index at
all. Otherwise there could be race conditions such that VACUUM removes dead
tuples from the index and marks the corresponding heap items as UNUSED, but
C/RIC then re-inserts the index tuples.
To avoid this problem, C/RIC needs to re-check each TID before it inserts it
into the index and skip the insertion if the tuple (or the whole HOT-chain
starting at this tuple) it points to is DEAD according to the OldestXmin that
the most recent VACUUM used. (VACUUM could perhaps advertise its OldestXmin
for C/RIC via shared memory.)
Also, before this re-checking starts, it must be ensured that VACUUM does not
start again, until the index creation is complete: a new run of VACUUM implies
a new value of OldestXmin, i.e. need for more stringent re-checking of the
heap tuples.
Related question is which OldestXmin to use in the step 4.3. One option is to
use *exactly* the OldestXmin shared VACUUM. However that wouldn't work if
VACUUM starts while C/RIC is already in progress. (Which seems like a
significant restriction.)
Another option is to get the OldestXmin in the same way as VACUUM
does. However, the value can thus be different from the one used by VACUUM:
older if retrieved before VACUUM started and newer if retrieved while VACUUM
was already running. The first case can be handled by the heap tuple
re-checking (see above). The latter implies that, before setting 'indisvalid',
C/RIC has to wait until all snapshots have their xmin >= this (more recent)
OldestXmin. Otherwise some snapshots could miss data they should see.
(An implication of the rule that C/RIC must not insert TIDs of dead tuples
into the index is that VACUUM does not have to call the index AM bulk delete
while C/RIC is running for that index. This would be just an optimization.)
Of course, I could have missed some important point, so please explain why
this concept is broken :-) Or let me know if something needs to be explained
more in detail. Thanks.
--
Antonin Houska
Web: https://www.cybertec-postgresql.com
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Antonin Houska <ah(at)cybertec(dot)at> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-27 17:40:34 |
| Message-ID: | CADzfLwWkYi3r-CD_Bbkg-Mx0qxMBzZZFQTL2ud7yHH2KDb1hdw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Antonin!
> I haven't read the whole thread yet, but the effort to minimize the impact of
> C/RIC on VACUUM seems to prevail
Yes, the thread is super long and probably you missed annotations to
most important emails in [0].
> Of course, I could have missed some important point, so please explain why
> this concept is broken :-) Or let me know if something needs to be explained
> more in detail. Thanks.
Looks like your idea is not broken, but... It is actually an almost
1-1 to idea used in the "full" version of the patch.
Explanations are available in [1] and [2].
In [3] I reduced the patch scope to find a solution compatible with REPACK.
Few comments:
> 1. Create an empty index.
Yes, patch does exactly the same, introducing special lightweight AM -
STIR (Short Term Index Replacement) to collect new tuples.
> 4.1 Acquire (shared) content lock on the buffer.
> 4.3 Collect the root tuples of HOT chains - these and only these need to be
inserted into the index.
> 4.4 Unlock the buffer.
Instead of such technique essentially the same is used - it keeps the
snapshot to be used, it just rotates it every few pages for a fresh
one.
It solves some of the issues with selection of alive tuples you
mentioned without any additional logic.
> Concurrent (re)build of unique index appears to be another topic of this
> thread, but I think this approach should handle the problem too.
It is solved with a special commit in the original patchset.
You know, clever people think the same :)
Interesting fact, it is not the first time - at [4] Sergey also
proposed an idea of an "empty" index to collect tuples (which gives
the single scan).
So, it is very good knews the approach feels valid for multiple people
(also Mathias introduced the idea about "fresh snapshot"~"no snapshot"
initially).
One thing I am not happy about - it is not applicable to the REPACK case.
Best regards,
Mikhail.
[0]: https://commitfest.postgresql.org/patch/4971/
[1]: https://www.postgresql.org/message-id/CADzfLwVOcZ9mg8gOG+KXWurt=MHRcqNv3XSECYoXyM3ENrxyfQ@mail.gmail.com
[2]: https://www.postgresql.org/message-id/CADzfLwW9QczZW-E=McxcjUv0e5VMDctQNETbgao0K-SimVhFPA@mail.gmail.com
[3]: https://www.postgresql.org/message-id/CADzfLwVaV15R2rUNZmKqLKweiN3SnUBg=6_qGE_ERb7cdQUD8g@mail.gmail.com
[4]: https://www.postgresql.org/message-id/flat/CAMAof6_FY0MrNJOuBrqvQqJKiwskFvjRtgpVHf-D7A%3DKvTtYXg%40mail.gmail.com
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Antonin Houska <ah(at)cybertec(dot)at> |
| Cc: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-27 18:22:46 |
| Message-ID: | CAEze2WigOH5Cyxo-oPjHebkfrohbe1H7sESKcDMi92vNUingWA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, 27 Nov 2025 at 17:56, Antonin Houska <ah(at)cybertec(dot)at> wrote:
>
> Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> wrote:
>
> > I think about revisiting (1) ({CREATE INDEX, REINDEX} CONCURRENTLY
> > improvements) in some lighter way.
>
> I haven't read the whole thread yet, but the effort to minimize the impact of
> C/RIC on VACUUM seems to prevail. Following is one more proposal. The core
> idea is that C/RIC should avoid indexing dead tuples, however snapshot is not
> necessary to distinguish dead tuple from a live one. And w/o snapshot, the
> backend executing C/RIC does not restrict VACUUM on other tables.
>
> Concurrent (re)build of unique index appears to be another topic of this
> thread, but I think this approach should handle the problem too. The workflow
> is:
>
> 1. Create an empty index.
>
> 2. Wait until all transactions are aware of the index, so they take the new
> index into account when deciding on new HOT chains. (This is already
> implemented.)
>
> 3. Set the 'indisready' flag so the index is ready for insertions.
>
> 4. While other transactions can insert their tuples into the index now,
> process the table one page at a time this way:
>
> 4.1 Acquire (shared) content lock on the buffer.
>
> 4.3 Collect the root tuples of HOT chains - these and only these need to be
> inserted into the index.
>
> 4.4 Unlock the buffer.
> 5. Once the whole table is processed, insert the collected tuples into the
> index.
>
> To avoid insertions of tuples that concurrent transactions have just
> inserted, we'd need something like index.c:validate_index() (i.e. insert
> into the index only the tuples that it does not contain yet), but w/o
> snapshot because we already have the heap tuples collected.
>
> Also it'd make sense to wait for completion of all the transactions that
> currently have the table locked for INSERT/UPDATE: some of these might have
> inserted their tuples into the heap, but not yet into the index. If we
> included some of those tuples into our collection and insert them into the
> index first, the other transactions could end up with ERROR when inserting
> those tuples again.
>
> 6. Set the 'indisvalid' flag so that the index can be used by queries.
>
> Note on pruning: As we only deal with the root tuples of HOT chains (4.3),
> page pruning triggered by queries (heap_page_prune_opt) should not be
> disruptive. Actually C/RIC can do the pruning itself it it appears to be
> useful. For example, if whole HOT chain should be considered DEAD by the next
> VACUUM, pruning is likely (depending on the OldestXid) to remove it so that we
> do not insert TID of the root tuple into the index unnecessarily.
[...]
> Of course, I could have missed some important point, so please explain why
> this concept is broken :-) Or let me know if something needs to be explained
> more in detail. Thanks.
1. When do you select and insert tuples that aren't part of a hot
chain into the index, i.e. tuples that were never updated after they
got inserted into the table? Or is every tuple "part of a hot chain"
even if the tuple wasn't ever updated?
2. HOT chains can be created while the index wasn't yet present, and
thus the indexed attributes of the root tuples can be different from
the most current tuple of a chain. If you only gather root tuples, we
could index incorrect data for that HOT chain. The correct approach
here is to index only the visible tuples, as those won't have been
updated in a non-HOT manner without all indexed attributes being
unchanged.
3. Having the index marked indisready before it contains any data is
going to slow down the indexing process significantly:
a. The main index build now must go through shared memory and buffer
locking, instead of being able to use backend-local memory
b. The tuple-wise insertion path (IndexAmRoutine->aminsert) can have a
significantly higher overhead than the bulk insertion logic in
ambuild(); in metrics of WAL, pages accessed (IO), and CPU cycles
spent.
So, I don't think moving away from ambuild() as basis for initially
building the index this is such a great idea.
(However, I do think that having an _option_ to build the index using
ambuildempty()+aminsert() instead of ambuild() might be useful, if
only to more easily compare "natural grown" indexes vs freshly built
ones, but that's completely orthogonal to CIC snapshotting
improvements.)
Kind regards,
Matthias van de Meent
Databricks (https://www.databricks.com)
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-27 18:40:59 |
| Message-ID: | CAEze2WgBffcC_SKGLmVxW8uRTEsrwWOHDQujN6zyxy1tSYLJ=Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, 9 Nov 2025 at 19:02, Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> wrote:
>
> Hello!
>
> This is a rebased version.
>
> Also I decided to keep only part 3 for now, because we need some
> common solution to keep the horizon advance for both INDEX and REPACK
> operations [0].
I'm not sure a complete and common approach is that easy between CIC
and REPACK CONCURRENTLY.
Specifically, indexes don't need to deal with the exact visibility
info of a tuple, and can let VACUUM take care of any false positives
(now-dead tuples), while REPACK does need to deal with all of that
that (xmin/xmax/xcid). Considering that REPACK is still going to rely
on primitives provided by logical replication, it would be not much
different from reducing the lifetime of the snapshots used by Logical
Replication's initial sync, and I'd rather not have to wait for that
to get implemented.
The only thing I can think of that might be shareable between the two
is the tooling in heapscan to every so often call into a function that
registers a new snapshot, but I think that's a comparatively minor
change on top of what was implemented for CIC, one that REPACK can
deal with on its own.
Kind regards,
Matthias van de Meent
Databricks (https://www.databricks.com)
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Antonin Houska <ah(at)cybertec(dot)at> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-27 18:57:23 |
| Message-ID: | CADzfLwV7Fm9uc7D5YEhnjvMUYTBGg4-wcu4KVOeTBCi1-z=96w@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi, Antonin!
On Thu, Nov 27, 2025 at 6:40 PM Mihail Nikalayeu
<mihailnikalayeu(at)gmail(dot)com> wrote:
> > 1. Create an empty index.
> Yes, patch does exactly the same, introducing special lightweight AM -
> STIR (Short Term Index Replacement) to collect new tuples.
Initially understood incorrectly - in your solution you propose to use
a single index.
But STIR is used to collect new coming tuples, while the main index is
built using a batched way.
> To avoid insertions of tuples that concurrent transactions have just
> inserted, we'd need something like index.c:validate_index() (i.e. insert
> into the index only the tuples that it does not contain yet), but w/o
> snapshot because we already have the heap tuples collected.
And later main and STIR are merged.
Best regards,
Mikhail.
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-27 18:59:55 |
| Message-ID: | CADzfLwVon8ESWOkg+8KU0F9=Hg7QKriNVX-hqcm-v-XZmHkzig@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Mathias!
On Thu, Nov 27, 2025 at 7:41 PM Matthias van de Meent
<boekewurm+postgres(at)gmail(dot)com> wrote:
> I'm not sure a complete and common approach is that easy between CIC
> and REPACK CONCURRENTLY.
Yes, you're right, but I hope something like [0] may work.
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-27 20:07:34 |
| Message-ID: | CAEze2WiXYx1LKr=9d7PLsZOYrGytY9AN__tFFw4p_Ysgm1-e5g@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, 27 Nov 2025 at 20:00, Mihail Nikalayeu
<mihailnikalayeu(at)gmail(dot)com> wrote:
>
> Hello, Mathias!
>
> On Thu, Nov 27, 2025 at 7:41 PM Matthias van de Meent
> <boekewurm+postgres(at)gmail(dot)com> wrote:
> > I'm not sure a complete and common approach is that easy between CIC
> > and REPACK CONCURRENTLY.
>
> Yes, you're right, but I hope something like [0] may work.
While it might not break, and might not hold back other tables'
visibility horizons, it'll still hold back pruning on the table we're
acting on, and that's likely one which already had bloat issues if
you're running RIC (or REPACK).
Hence the approach with properly taking a new snapshot every so often
in CIC/RIC -- that way pruning is allowed up to a relatively recent
point in every table, including the one we're acting on; potentially
saving us from a vicious cycle where RIC causes table bloat in the
table it's working on due to long-held snapshots and a high-churn
workload in that table.
Kind regards,
Matthias van de Meent
Databricks (https://www.databricks.com)
PS. When I checked the code you linked to on that thread, I noticed
there is a stale pointer dereference issue in
GetPinnedOldestNonRemovableTransactionId, where it pulls data from a
hash table entry that could've been released by that point.
| From: | Antonin Houska <ah(at)cybertec(dot)at> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-28 09:05:24 |
| Message-ID: | 8837.1764320724@localhost |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> wrote:
> On Thu, 27 Nov 2025 at 17:56, Antonin Houska <ah(at)cybertec(dot)at> wrote:
> >
> > Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> wrote:
> >
> > > I think about revisiting (1) ({CREATE INDEX, REINDEX} CONCURRENTLY
> > > improvements) in some lighter way.
> >
> > I haven't read the whole thread yet, but the effort to minimize the impact of
> > C/RIC on VACUUM seems to prevail. Following is one more proposal. The core
> > idea is that C/RIC should avoid indexing dead tuples, however snapshot is not
> > necessary to distinguish dead tuple from a live one. And w/o snapshot, the
> > backend executing C/RIC does not restrict VACUUM on other tables.
> >
> > Concurrent (re)build of unique index appears to be another topic of this
> > thread, but I think this approach should handle the problem too. The workflow
> > is:
> >
> > 1. Create an empty index.
> >
> > 2. Wait until all transactions are aware of the index, so they take the new
> > index into account when deciding on new HOT chains. (This is already
> > implemented.)
> >
> > 3. Set the 'indisready' flag so the index is ready for insertions.
> >
> > 4. While other transactions can insert their tuples into the index now,
> > process the table one page at a time this way:
> >
> > 4.1 Acquire (shared) content lock on the buffer.
> >
> > 4.3 Collect the root tuples of HOT chains - these and only these need to be
> > inserted into the index.
> >
> > 4.4 Unlock the buffer.
>
>
> > 5. Once the whole table is processed, insert the collected tuples into the
> > index.
> >
> > To avoid insertions of tuples that concurrent transactions have just
> > inserted, we'd need something like index.c:validate_index() (i.e. insert
> > into the index only the tuples that it does not contain yet), but w/o
> > snapshot because we already have the heap tuples collected.
> >
> > Also it'd make sense to wait for completion of all the transactions that
> > currently have the table locked for INSERT/UPDATE: some of these might have
> > inserted their tuples into the heap, but not yet into the index. If we
> > included some of those tuples into our collection and insert them into the
> > index first, the other transactions could end up with ERROR when inserting
> > those tuples again.
> >
> > 6. Set the 'indisvalid' flag so that the index can be used by queries.
> >
> > Note on pruning: As we only deal with the root tuples of HOT chains (4.3),
> > page pruning triggered by queries (heap_page_prune_opt) should not be
> > disruptive. Actually C/RIC can do the pruning itself it it appears to be
> > useful. For example, if whole HOT chain should be considered DEAD by the next
> > VACUUM, pruning is likely (depending on the OldestXid) to remove it so that we
> > do not insert TID of the root tuple into the index unnecessarily.
> [...]
> > Of course, I could have missed some important point, so please explain why
> > this concept is broken :-) Or let me know if something needs to be explained
> > more in detail. Thanks.
>
> 1. When do you select and insert tuples that aren't part of a hot
> chain into the index, i.e. tuples that were never updated after they
> got inserted into the table? Or is every tuple "part of a hot chain"
> even if the tuple wasn't ever updated?
Right, I considered "standalone tuple" a HOT chain of length 1. So it'll be
picked too.
> 2. HOT chains can be created while the index wasn't yet present, and
> thus the indexed attributes of the root tuples can be different from
> the most current tuple of a chain. If you only gather root tuples, we
> could index incorrect data for that HOT chain. The correct approach
> here is to index only the visible tuples, as those won't have been
> updated in a non-HOT manner without all indexed attributes being
> unchanged.
Good point.
> 3. Having the index marked indisready before it contains any data is
> going to slow down the indexing process significantly:
> a. The main index build now must go through shared memory and buffer
> locking, instead of being able to use backend-local memory
> b. The tuple-wise insertion path (IndexAmRoutine->aminsert) can have a
> significantly higher overhead than the bulk insertion logic in
> ambuild(); in metrics of WAL, pages accessed (IO), and CPU cycles
> spent.
>
> So, I don't think moving away from ambuild() as basis for initially
> building the index this is such a great idea.
>
> (However, I do think that having an _option_ to build the index using
> ambuildempty()+aminsert() instead of ambuild() might be useful, if
> only to more easily compare "natural grown" indexes vs freshly built
> ones, but that's completely orthogonal to CIC snapshotting
> improvements.)
The retail insertions are not something this proposal depends on. I think it'd
be possible to build a separate index locally and then "merge" it with the
regular one. I just tried to propose a solution that does not need snapshots.
--
Antonin Houska
Web: https://www.cybertec-postgresql.com
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Antonin Houska <ah(at)cybertec(dot)at> |
| Cc: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-28 09:51:16 |
| Message-ID: | CAEze2WjE=LJ_m_uWFDHgwXaxvqN-wna7A40=XWJ4727NpmTQ2w@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 28 Nov 2025 at 10:05, Antonin Houska <ah(at)cybertec(dot)at> wrote:
> Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> wrote:
> > 3. Having the index marked indisready before it contains any data is
> > going to slow down the indexing process significantly:
> > a. The main index build now must go through shared memory and buffer
> > locking, instead of being able to use backend-local memory
> > b. The tuple-wise insertion path (IndexAmRoutine->aminsert) can have a
> > significantly higher overhead than the bulk insertion logic in
> > ambuild(); in metrics of WAL, pages accessed (IO), and CPU cycles
> > spent.
> >
> > So, I don't think moving away from ambuild() as basis for initially
> > building the index this is such a great idea.
> >
> > (However, I do think that having an _option_ to build the index using
> > ambuildempty()+aminsert() instead of ambuild() might be useful, if
> > only to more easily compare "natural grown" indexes vs freshly built
> > ones, but that's completely orthogonal to CIC snapshotting
> > improvements.)
>
> The retail insertions are not something this proposal depends on. I think it'd
> be possible to build a separate index locally and then "merge" it with the
> regular one. I just tried to propose a solution that does not need snapshots.
I'm not sure we can generalize indexes to the point where merging two
built indexes is always both possible and efficient.
For example, the ANN indexes of pgvector (both HNSW and IVF) could
possibly have merge operations between indexes of the same type and
schema, but it would require a lot of effort on the side of the AM to
support merging; there is no trivial merge operation that also retains
the quality of the index without going through the aminsert() path.
Conversely, the current approach to CIC doesn't require additional
work on the index AM's side, and that's a huge enabler for every kind
of index.
Kind regards,
Matthias van de Meent
Databricks (https://www.databricks.com)
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-28 14:50:00 |
| Message-ID: | CADzfLwUKXcXKZgX+e8ACsOXe_CgtWmNJY_6dyn8EO0AXYOn2pA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
On Thu, Nov 27, 2025 at 9:07 PM Matthias van de Meent
<boekewurm+postgres(at)gmail(dot)com> wrote:
> While it might not break, and might not hold back other tables'
> visibility horizons, it'll still hold back pruning on the table we're
> acting on, and that's likely one which already had bloat issues if
> you're running RIC (or REPACK).
Yes, a good point about REPACK, agreed.
BTW, what is about using the same reset snapshot technique for REPACK also?
I thought it is impossible, but what if we:
* while reading the heap we "remember" our current page position into
shared memory
* preserve all xmin/max/cid into newly created repacked table (we need
it for MVCC-safe approach anyway)
* in logical decoding layer - we check TID of our tuple and looking at
"current page" we may correctly decide what to do with at apply phase:
- if it in "non-yet read pages" - ignore (we will read it later) - but
signal scan to ensure it will reset snapshot before that page
(reset_before = min(reset_before, tid))
- if it in "already read pages" - remember the apply operation (with
exact target xmin/xmax and resulting xmin/xmax)
Before switching table - use the same "limit_xmin" logic to wait for
other transactions the same way CIC does.
It may involve some tricky locking, maybe I missed some cases, but it
feels like it is possible to do it correctly by combining information
of scan state and xmin/xmax/tid/etc...
PS.
> PS. When I checked the code you linked to on that thread, I noticed
> there is a stale pointer dereference issue in
> GetPinnedOldestNonRemovableTransactionId, where it pulls data from a
> hash table entry that could've been released by that point.
Thanks!
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-28 16:57:55 |
| Message-ID: | CAEze2WiiR2PeXg_vaURjjiiwvjQ=Um8wxWi1BcVS0BGyxiD2gQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 28 Nov 2025 at 15:50, Mihail Nikalayeu
<mihailnikalayeu(at)gmail(dot)com> wrote:
>
> Hello!
>
> On Thu, Nov 27, 2025 at 9:07 PM Matthias van de Meent
> <boekewurm+postgres(at)gmail(dot)com> wrote:
> > While it might not break, and might not hold back other tables'
> > visibility horizons, it'll still hold back pruning on the table we're
> > acting on, and that's likely one which already had bloat issues if
> > you're running RIC (or REPACK).
>
> Yes, a good point about REPACK, agreed.
>
> BTW, what is about using the same reset snapshot technique for REPACK also?
>
> I thought it is impossible, but what if we:
>
> * while reading the heap we "remember" our current page position into
> shared memory
> * preserve all xmin/max/cid into newly created repacked table (we need
> it for MVCC-safe approach anyway)
> * in logical decoding layer - we check TID of our tuple and looking at
> "current page" we may correctly decide what to do with at apply phase:
>
> - if it in "non-yet read pages" - ignore (we will read it later) - but
> signal scan to ensure it will reset snapshot before that page
> (reset_before = min(reset_before, tid))
> - if it in "already read pages" - remember the apply operation (with
> exact target xmin/xmax and resulting xmin/xmax)
Yes, exactly - keep track of which snapshot was used for which part of
the table, and all updates that add/remove tuples from the scanned
range after that snapshot are considered inserts/deletes, similar to
how it'd work if LR had a filter on `ctid BETWEEN '(0, 0)' AND
'(end-of-snapshot-scan)'` which then gets updated every so often.
I'm a bit worried, though, that LR may lose updates due to commit
order differences between WAL and PGPROC. I don't know how that's
handled in logical decoding, and can't find much literature about it
in the repo either.
Kind regards,
Matthias van de Meent
Databricks (https://www.databricks.com)
| From: | Hannu Krosing <hannuk(at)google(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-28 17:58:46 |
| Message-ID: | CAMT0RQQP9JiGqqB+pVBzPT7unG1BMBuLj=kGPk4BeS3g6VyT1A@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Nov 28, 2025 at 5:58 PM Matthias van de Meent
<boekewurm+postgres(at)gmail(dot)com> wrote:
>
...
> I'm a bit worried, though, that LR may lose updates due to commit
> order differences between WAL and PGPROC. I don't know how that's
> handled in logical decoding, and can't find much literature about it
> in the repo either.
Now the reference to logical decoding made me think that maybe to real
fix for CIC would be to leverage logical decoding for the 2nd pass of
CIC and not wore about in-page visibilities at all.
---
Hannu
| From: | Hannu Krosing <hannuk(at)google(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-28 18:05:12 |
| Message-ID: | CAMT0RQSbFJCpetFy22=O=gKR2ZfH=tMTQeCM743T4o3rMjaeTQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Nov 28, 2025 at 6:58 PM Hannu Krosing <hannuk(at)google(dot)com> wrote:
>
> On Fri, Nov 28, 2025 at 5:58 PM Matthias van de Meent
> <boekewurm+postgres(at)gmail(dot)com> wrote:
> >
> ...
> > I'm a bit worried, though, that LR may lose updates due to commit
> > order differences between WAL and PGPROC. I don't know how that's
> > handled in logical decoding, and can't find much literature about it
> > in the repo either.
>
> Now the reference to logical decoding made me think that maybe to real
> fix for CIC would be to leverage logical decoding for the 2nd pass of
> CIC and not worry about in-page visibilities at all.
And if we are concerned about having possibly to scan more WAL than we
would have had to scan the table, we can start a
tuple-to-index-collector immediately after starting the CIC.
For extra efficiency gains the collector itself should have two phases
1. While the first pass of CIC is collecting the visible tuple for
index the logical decoding collector also collects any new tuples
added after the CIC start.
2. When the first pass collection finishes, it also gets the indexes
collected so far by the logical decoding collectoir and adds them to
the first set before the sorting and creating the index.
3. once the initial index is created, the CIC just gets whatever else
was collected after 2. and adds these to the index
---
Hannu
>
> ---
> Hannu
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Hannu Krosing <hannuk(at)google(dot)com> |
| Cc: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-28 18:31:17 |
| Message-ID: | CAEze2WjMFSefMtweYQFDV-iG9W=3r2BsQmkM7GWmYmi6-AH+7A@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 28 Nov 2025 at 18:58, Hannu Krosing <hannuk(at)google(dot)com> wrote:
>
> On Fri, Nov 28, 2025 at 5:58 PM Matthias van de Meent
> <boekewurm+postgres(at)gmail(dot)com> wrote:
> >
> ...
> > I'm a bit worried, though, that LR may lose updates due to commit
> > order differences between WAL and PGPROC. I don't know how that's
> > handled in logical decoding, and can't find much literature about it
> > in the repo either.
>
> Now the reference to logical decoding made me think that maybe to real
> fix for CIC would be to leverage logical decoding for the 2nd pass of
> CIC and not wore about in-page visibilities at all.
-1: Requiring the logical decoding system just to reindex an index
without O(tablesize) lock time adds too much overhead, and removes
features we currently have (CIC on unlogged tables). wal_level=logical
*must not* be required for these tasks if we can at all avoid it.
I'm also not sure whether logical decoding gets access to the HOT
information of the updated tuples involved, and therefore whether the
index build can determine whether it must or can't insert the tuple.
I don't think logical decoding is sufficient, because we don't know
which tuples were already inserted into the index by their own
backends, so we don't know which tuples' index entries we must skip.
Kind regards,
Matthias van de Meent.
PS. I think the same should be true for REPACK CONCURRENTLY, but
that's a new command with yet-to-be-determined semantics, unlike CIC
which has been part of PG for 6 years.
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Hannu Krosing <hannuk(at)google(dot)com> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-28 18:40:45 |
| Message-ID: | CADzfLwX7u5P=Utt4kj-KOjgC_8fhsinpmLtadqkHrohE5Y5H+Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
On Fri, Nov 28, 2025 at 7:05 PM Hannu Krosing <hannuk(at)google(dot)com> wrote:
> 1. While the first pass of CIC is collecting the visible tuple for
> index the logical decoding collector also collects any new tuples
> added after the CIC start.
> 2. When the first pass collection finishes, it also gets the indexes
> collected so far by the logical decoding collectoir and adds them to
> the first set before the sorting and creating the index.
>
> 3. once the initial index is created, the CIC just gets whatever else
> was collected after 2. and adds these to the index
It feels very similar to the approach with STIR (upper in that thread)
- instead of doing the second scan - just collect all the new-coming
TIDs in short-term-index-replacement access method.
I think STIR lightweight AM (contains just TID) is a better option
here than logical replication due several reason (Mathias already
mentioned some of them).
Anyway, it looks like things\threads became a little bit mixed-up,
I'll try to structure it a little bit.
For CIC/RC approach with resetting snapshot during heap scan - it is
enough to achieve vacuum-friendly state in phase 1.
For phase 2 (validation) - we need an additional thing - something to
collect incoming tuples (STIR index AM is proposed). In that case we
achieve vacuum-friendly for both phases + single heap scan.
STIR at the same time may be used as just way to make CIC faster
(single scan) - without any improvements related to VACUUM.
You may check [0] for links.
Another topic is REPACK CONCURRENTLY, which itself leaves in [1]. It
is already based on LR.
I was talking about a way to use the same tech (reset snapshot during
the scan) for REPACK also, leveraging the already introduced LR
decoding part.
Mikhail.
[0]: https://www.postgresql.org/message-id/flat/CADzfLwWkYi3r-CD_Bbkg-Mx0qxMBzZZFQTL2ud7yHH2KDb1hdw%40mail.gmail.com
[1]: https://www.postgresql.org/message-id/flat/202507262156.sb455angijk6%40alvherre.pgsql
| From: | Hannu Krosing <hannuk(at)google(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-28 19:08:12 |
| Message-ID: | CAMT0RQR7J+mQ=3ufSVV5VhChrhaSGgYSk2Zwe9e=_EOc-v-cwQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Nov 28, 2025 at 7:31 PM Matthias van de Meent
<boekewurm+postgres(at)gmail(dot)com> wrote:
>
> On Fri, 28 Nov 2025 at 18:58, Hannu Krosing <hannuk(at)google(dot)com> wrote:
> >
> > On Fri, Nov 28, 2025 at 5:58 PM Matthias van de Meent
> > <boekewurm+postgres(at)gmail(dot)com> wrote:
> > >
> > ...
> > > I'm a bit worried, though, that LR may lose updates due to commit
> > > order differences between WAL and PGPROC. I don't know how that's
> > > handled in logical decoding, and can't find much literature about it
> > > in the repo either.
> >
> > Now the reference to logical decoding made me think that maybe to real
> > fix for CIC would be to leverage logical decoding for the 2nd pass of
> > CIC and not wore about in-page visibilities at all.
>
> -1: Requiring the logical decoding system just to reindex an index
> without O(tablesize) lock time adds too much overhead, and removes
> features we currently have (CIC on unlogged tables). wal_level=logical
> *must not* be required for these tasks if we can at all avoid it.
> I'm also not sure whether logical decoding gets access to the HOT
> information of the updated tuples involved, and therefore whether the
> index build can determine whether it must or can't insert the tuple.
There are more and more cases (not just CIC here) where using logical
decoding would be the most efficient solution, so why not instead
start improving it instead of complicating the system in various
places?
We could even start selectively logging UNLOGGED and TEMP tables when
we start CIC if CIC has enough upsides.
> I don't think logical decoding is sufficient, because we don't know
> which tuples were already inserted into the index by their own
> backends, so we don't know which tuples' index entries we must skip.
The premise of pass2 in CIC is that we collect all the rows that were
inserted after CIC started for which we are not 100% sure that they
are inserted in the index. We can only be sure they are inserted for
transactions started after pass1 completed and the index became
visible and available for inserts.
I am sure that it is possible to avoid inserting duplicate entry (same
value and tid) at insert time.
And we do not care about hot update chains dusing normal CREATE INDEX
or first pass of CIC - we just index what is visible NOW wit no regard
of weather the tuple is at the end of HOT update chain.
> Kind regards,
>
> Matthias van de Meent.
>
> PS. I think the same should be true for REPACK CONCURRENTLY, but
> that's a new command with yet-to-be-determined semantics, unlike CIC
> which has been part of PG for 6 years.
CIC has been around way longer, since 8.2 released in 2006, so more
like 20 years :)
---
Cheers
Hannu
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Hannu Krosing <hannuk(at)google(dot)com> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Antonin Houska <ah(at)cybertec(dot)at> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-28 20:41:15 |
| Message-ID: | CADzfLwXL6cCksMeouTFhXcJJexCw5RqE6qCn79OL=P8BwoNjFw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi, Hannu!
I think you pressed "Reply" instead of "Reply All" - so, I put it to
the list (looks like nothing is secret here).
Mostly it is because of my opinion at the end of the mail which I want
to share with the list.
On Fri, Nov 28, 2025 at 8:33 PM Hannu Krosing <hannuk(at)google(dot)com> wrote:
> If it is an *index AM* then this may not solve HOT chains issue (see
> below), if we put it on top of *table AM* as some kind of pass-through
> collector then likely yes, though you may still want to do final sort
> in commit order to know which one is the latest version of updated
> tuples which needs to go in the index. The latter is not strictly
> needed, but would be a nice optimisation for oft-updated rows.
It is AM which is added as an index (with the same
columns/expressions/predicates) to the table before phase 1 starts.
So, all new tuples are inserted into it.
> And I would not collect just TID, but also the indexes value, as else
> we end up accessing the table in some random order for getting the
> value (and possibly do visibility checks)
Just TIDs - it is ordered at validation phase (while merging with an
main index) and read using AIO - pretty fast.
> I am not sure where we decide that tuple is HOT-updatable, but I
> suspect that it is before we call any index AMs, so STIR ios not
> guaranteed to solve the issues with HOT chains.
I am not sure what the HOT-chains issue is, but it actually works
correctly already, including stress tests.
It is even merged into one commercial fork of PG (I am not affiliated
with it in any way).
> (And yes, I have a patch in works to include old and new tids> as part
> of logical decoding - they are "almost there", just not passed through
> - which would help here too to easily keep just the last value)
Yes, at least it is required for the REPACK case.
But....
Antonin already has a prototype of patch to enable logical decoding
for all kinds of tables in [0] (done in scope of REPACK).
So, if we have such mechanics in place, it looks nice (and almost the
same) for both CIC and REPACK:
* in both cases we create temporary slot to collect incoming tuples
* in both cases scan the table resetting snapshot every few pages to
keep xmin horizon propagate
* in both cases the process already collected part every few megabytes
* just the logic of using collected tuples is different...
So, yes, from terms of effectiveness STIR seems to be better, but such
a common approach like LD looks tempting to have for both REPACK/CIC.
On Fri, Nov 28, 2025 at 5:58 PM Matthias van de Meent
<boekewurm+postgres(at)gmail(dot)com> wrote:
> -1: Requiring the logical decoding system just to reindex an index
> without O(tablesize) lock time adds too much overhead,
How big is the additional cost of maintaining logical decoding for a
table? Could you please evolve a little bit?
Best regards,
Mikhail.
[0]: https://www.postgresql.org/message-id/152010.1751307725%40localhost
(v15-0007-Enable-logical-decoding-transiently-only-for-REPACK-.patch)
| From: | Hannu Krosing <hannuk(at)google(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, Antonin Houska <ah(at)cybertec(dot)at> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-11-28 21:01:04 |
| Message-ID: | CAMT0RQS3EkCu3+gUpD-ywE+nDjSw13ZJ8uQVuLE0kTCMDscUFw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Nov 28, 2025 at 9:42 PM Mihail Nikalayeu
<mihailnikalayeu(at)gmail(dot)com> wrote:
>
> Hi, Hannu!
>
> I think you pressed "Reply" instead of "Reply All" - so, I put it to
> the list (looks like nothing is secret here).
> Mostly it is because of my opinion at the end of the mail which I want
> to share with the list.
Thanks, and yes, it was meant for the list.
> On Fri, Nov 28, 2025 at 8:33 PM Hannu Krosing <hannuk(at)google(dot)com> wrote:
> > If it is an *index AM* then this may not solve HOT chains issue (see
> > below), if we put it on top of *table AM* as some kind of pass-through
> > collector then likely yes, though you may still want to do final sort
> > in commit order to know which one is the latest version of updated
> > tuples which needs to go in the index. The latter is not strictly
> > needed, but would be a nice optimisation for oft-updated rows.
>
> It is AM which is added as an index (with the same
> columns/expressions/predicates) to the table before phase 1 starts.
> So, all new tuples are inserted into it.
>
> > And I would not collect just TID, but also the indexes value, as else
> > we end up accessing the table in some random order for getting the
> > value (and possibly do visibility checks)
> Just TIDs - it is ordered at validation phase (while merging with an
> main index) and read using AIO - pretty fast.
It is a space vs work compromise - you either collect it at once or
have to read it again later. Even pretty fast is still slower than
doing nothing :)
> > I am not sure where we decide that tuple is HOT-updatable, but I
> > suspect that it is before we call any index AMs, so STIR ios not
> > guaranteed to solve the issues with HOT chains.
>
> I am not sure what the HOT-chains issue is, but it actually works
> correctly already, including stress tests.
> It is even merged into one commercial fork of PG (I am not affiliated
> with it in any way).
It was about a simplistic approach for VACUUM to just ignore the CIC
backends and then missing some inserts.
> > (And yes, I have a patch in works to include old and new tids> as part
> > of logical decoding - they are "almost there", just not passed through
> > - which would help here too to easily keep just the last value)
>
> Yes, at least it is required for the REPACK case.
>
> But....
>
> Antonin already has a prototype of patch to enable logical decoding
> for all kinds of tables in [0] (done in scope of REPACK).
>
> So, if we have such mechanics in place, it looks nice (and almost the
> same) for both CIC and REPACK:
> * in both cases we create temporary slot to collect incoming tuples
> * in both cases scan the table resetting snapshot every few pages to
> keep xmin horizon propagate
> * in both cases the process already collected part every few megabytes
> * just the logic of using collected tuples is different...
>
> So, yes, from terms of effectiveness STIR seems to be better, but such
> a common approach like LD looks tempting to have for both REPACK/CIC.
My reasoning was mainly that using something that already exists, and
must work correctly in any case, is a better long-term strategy than
adding complexity in multiple places.
After looking up when CIC appeared (v 8.2) and when logical decoding
came along (v9.4) I start to think that CIC probably would have used
LD if it had been available when CIC was added.
> On Fri, Nov 28, 2025 at 5:58 PM Matthias van de Meent
> <boekewurm+postgres(at)gmail(dot)com> wrote:
> > -1: Requiring the logical decoding system just to reindex an index
> > without O(tablesize) lock time adds too much overhead,
>
> How big is the additional cost of maintaining logical decoding for a
> table? Could you please evolve a little bit?
>
> Best regards,
> Mikhail.
>
>
> [0]: https://www.postgresql.org/message-id/152010.1751307725%40localhost
> (v15-0007-Enable-logical-decoding-transiently-only-for-REPACK-.patch)
| From: | Antonin Houska <ah(at)cybertec(dot)at> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-01 09:09:29 |
| Message-ID: | 5784.1764580169@localhost |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> wrote:
> I'm a bit worried, though, that LR may lose updates due to commit
> order differences between WAL and PGPROC. I don't know how that's
> handled in logical decoding, and can't find much literature about it
> in the repo either.
Can you please give me an example of this problem? I understand that two
transactions do this
T1: RecordTransactionCommit()
T2: RecordTransactionCommit()
T2: ProcArrayEndTransaction()
T1: ProcArrayEndTransaction()
but I'm failing to imagine this if both transactions are trying to update the
same row. For example, if T1 is updating a row that T2 wants to update as
well, then T2 has to wait for T1's call of ProcArrayEndTransaction() before it
can perform its update, and therefore it (T2) cannot start its commit sequence
before T1 has completed it:
T1: RecordTransactionCommit()
T1: ProcArrayEndTransaction()
T2: RecordTransactionCommit()
T2: ProcArrayEndTransaction()
--
Antonin Houska
Web: https://www.cybertec-postgresql.com
| From: | Antonin Houska <ah(at)cybertec(dot)at> |
|---|---|
| To: | Hannu Krosing <hannuk(at)google(dot)com> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-01 10:29:49 |
| Message-ID: | 8010.1764584989@localhost |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hannu Krosing <hannuk(at)google(dot)com> wrote:
> On Fri, Nov 28, 2025 at 6:58 PM Hannu Krosing <hannuk(at)google(dot)com> wrote:
> >
> > On Fri, Nov 28, 2025 at 5:58 PM Matthias van de Meent
> > <boekewurm+postgres(at)gmail(dot)com> wrote:
> > >
> > ...
> > > I'm a bit worried, though, that LR may lose updates due to commit
> > > order differences between WAL and PGPROC. I don't know how that's
> > > handled in logical decoding, and can't find much literature about it
> > > in the repo either.
> >
> > Now the reference to logical decoding made me think that maybe to real
> > fix for CIC would be to leverage logical decoding for the 2nd pass of
> > CIC and not worry about in-page visibilities at all.
>
> And if we are concerned about having possibly to scan more WAL than we
> would have had to scan the table, we can start a
> tuple-to-index-collector immediately after starting the CIC.
>
> For extra efficiency gains the collector itself should have two phases
>
> 1. While the first pass of CIC is collecting the visible tuple for
> index the logical decoding collector also collects any new tuples
> added after the CIC start.
> 2. When the first pass collection finishes, it also gets the indexes
> collected so far by the logical decoding collectoir and adds them to
> the first set before the sorting and creating the index.
>
> 3. once the initial index is created, the CIC just gets whatever else
> was collected after 2. and adds these to the index
The core problem here is that the snapshot you need for the first pass
restricts VACUUM on all tables in the database. The same problem exists for
REPACK (CONCURRENTLY) and we haven't resolved it yet.
With logical replication, we cannot really use multiple snapshots as Mihail is
proposing elsewhere in the thread, because the logical decoding system only
generates the snapshot for non-catalog tables once (LR uses that snapshot for
the initial table synchronization). Only snapshots for system catalog tables
are then built as the WAL decoding progresses. It can be worked around by
considering regular table as catalog during the processing, but it currently
introduces quite some overhead:
https://www.postgresql.org/message-id/178741.1743514291%40localhost
Perhaps we could enhance the logical decoding so that it gathers the
information needed to build snapshots (AFAICS it's mostly about the
XLOG_HEAP2_NEW_CID record) not only for catalog tables, but also for
particular non-catalog table(s). However, for these non-catalog tables, the
actual snapshot build should only take place when the snapshot is actually
needed. (For catalog tables, each data change triggers the build of a new
snapshot.)
So in general I agree with what you say elsewhere in the thread that it might
be worth to enhance the logical decoding a bit.
Transient enabling of the decoding, only for specific tables (i.e. not
requiring wal_level=logical), is another problem. I proposed a patch for that,
but not sure it has been reviewed yet:
https://www.postgresql.org/message-id/152010.1751307725%40localhost
(See the 0007 part.)
--
Antonin Houska
Web: https://www.cybertec-postgresql.com
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Antonin Houska <ah(at)cybertec(dot)at> |
| Cc: | Hannu Krosing <hannuk(at)google(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-01 10:49:37 |
| Message-ID: | CADzfLwUjgOxk8dd8XLv3jn05gAxxwEZoAA7-2Owb2CczkSb6Tw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Antonin!
On Mon, Dec 1, 2025 at 11:29 AM Antonin Houska <ah(at)cybertec(dot)at> wrote:
> With logical replication, we cannot really use multiple snapshots as Mihail is
> proposing elsewhere in the thread, because the logical decoding system only
> generates the snapshot for non-catalog tables once (LR uses that snapshot for
> the initial table synchronization). Only snapshots for system catalog tables
> are then built as the WAL decoding progresses. It can be worked around by
> considering regular table as catalog during the processing, but it currently
> introduces quite some overhead:
My idea related to REPACK is a little bit different. I am not talking
about snapshots generated by LR - just GetLatestSnapshot.
> The core problem here is that the snapshot you need for the first pass
> restricts VACUUM on all tables in the database
We might use it only for a few seconds - it is required only to
*start* the scan (to ensure we will not miss anything in the table).
After we may throw it away and ask GetLatestSnapshot a fresh one for
next N pages. We just need to synchronize scan position in the table
and logical decoding.
The same is possible for CIC too. In that case we should do the same
and just store all incoming tuples the same way as STIR does it.
Best regards,
Mikhail.
| From: | Antonin Houska <ah(at)cybertec(dot)at> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Hannu Krosing <hannuk(at)google(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-02 07:28:00 |
| Message-ID: | 5778.1764660480@localhost |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> wrote:
> Hello, Antonin!
>
> On Mon, Dec 1, 2025 at 11:29 AM Antonin Houska <ah(at)cybertec(dot)at> wrote:
> > With logical replication, we cannot really use multiple snapshots as Mihail is
> > proposing elsewhere in the thread, because the logical decoding system only
> > generates the snapshot for non-catalog tables once (LR uses that snapshot for
> > the initial table synchronization). Only snapshots for system catalog tables
> > are then built as the WAL decoding progresses. It can be worked around by
> > considering regular table as catalog during the processing, but it currently
> > introduces quite some overhead:
>
> My idea related to REPACK is a little bit different. I am not talking
> about snapshots generated by LR - just GetLatestSnapshot.
>
> > The core problem here is that the snapshot you need for the first pass
> > restricts VACUUM on all tables in the database
>
> We might use it only for a few seconds - it is required only to
> *start* the scan (to ensure we will not miss anything in the table).
> After we may throw it away and ask GetLatestSnapshot a fresh one for
> next N pages. We just need to synchronize scan position in the table
> and logical decoding.
>
> The same is possible for CIC too. In that case we should do the same
> and just store all incoming tuples the same way as STIR does it.
I suppose you don't want to use logical decoding for CIC, do you? How can then
it be "the same" like in REPACK (CONCURRENTLY)? Or do you propose to rework
REPACK (CONCURRENTLY) from scratch so that it does not use logical decoding
either?
--
Antonin Houska
Web: https://www.cybertec-postgresql.com
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Antonin Houska <ah(at)cybertec(dot)at> |
| Cc: | Hannu Krosing <hannuk(at)google(dot)com>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-02 10:27:00 |
| Message-ID: | CADzfLwXMzv4_2Mc54qpASJ7FrKwQ6OsG0d9GxiYDxEKZ2KqHSA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Antonin!
On Tue, Dec 2, 2025 at 8:28 AM Antonin Houska <ah(at)cybertec(dot)at> wrote:
> I suppose you don't want to use logical decoding for CIC, do you? How can then
> it be "the same" like in REPACK (CONCURRENTLY)? Or do you propose to rework
> REPACK (CONCURRENTLY) from scratch so that it does not use logical decoding
> either?
My logic here chain is next:
* looks like we may reuse snapshot reset technique for REPACK, using
LR+some tricks
* if it worked, why should we use reset technique + STIR (not LR too) in CIC?
* mostly because it is not possible to active LR for some of tables
* but there is (your) patch what aims to add the ability to activate
LR for any table
* if it worked - it feels natural to replace STIR by LR to keep things
looking the same and working the same way
While STIR may be more efficient and simple for CIC - it is still an
additional entity in the PG domain, so LR may be a better solution
from a system design perspective.
But it is only thought so far, because I have not yet proved reset
snapshot is possible for REPACK (need to do some POC at least).
What do you think?
Also, I think I'll extract reset-snapshot for CIC in a separate CF
entry, since it still may be used with or without either STIR or LR.
Best regards,
MIkhail,
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Antonin Houska <ah(at)cybertec(dot)at> |
| Cc: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-02 10:51:06 |
| Message-ID: | CAEze2Wi_wZqxzZE0g==XuROUUnhpLwZM6=9Snkxbo7-ZH2J2yg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 1 Dec 2025 at 10:09, Antonin Houska <ah(at)cybertec(dot)at> wrote:
>
> Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> wrote:
>
> > I'm a bit worried, though, that LR may lose updates due to commit
> > order differences between WAL and PGPROC. I don't know how that's
> > handled in logical decoding, and can't find much literature about it
> > in the repo either.
>
> Can you please give me an example of this problem? I understand that two
> transactions do this
>
> T1: RecordTransactionCommit()
> T2: RecordTransactionCommit()
> T2: ProcArrayEndTransaction()
> T1: ProcArrayEndTransaction()
>
> but I'm failing to imagine this if both transactions are trying to update the
> same row.
Correct, it doesn't have anything to do with two transactions updating
the same row; but instead the same transaction getting applied twice;
related to issues described in (among others) [0]:
Logical replication applies transactions in WAL commit order, but
(normal) snapshots on the primary use the transaction's persistence
requirements (and procarray lock acquisition) as commit order.
This can cause the snapshot to see T2 as committed before T1, whilst
logical replication will apply transactions in T1 -> T2 order. This
can break the exactly-once expectations of commits, because a normal
snapshot taken between T2 and T1 on the primary (i.e., T2 is
considered committed, but T1 not) will have T2 already applied. LR
would have to apply changes of T1, which also implies it'd eventually
get to T2's commit and apply that too. Alternatively, it'd skip past
T2 because that's already present in the snapshot, and lose the
changes that were committed with T1.
I can't think of an ordering that applies all changes correctly
without either filtering which transactions to include in LR apply
steps, or LR's sync scan snapshots being different from normal
snapshots on the primary.
Kind regards,
Matthias van de Meent
Databricks (https://www.databricks.com)
[0] https://jepsen.io/analyses/amazon-rds-for-postgresql-17.4
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-02 11:12:17 |
| Message-ID: | CAEze2Wg6d2M8hop4uwdQXeH-YkOmEHyqp83+aE7vEzKdmu7w-A@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2 Dec 2025 at 11:27, Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> wrote:
>
> Hello, Antonin!
>
> On Tue, Dec 2, 2025 at 8:28 AM Antonin Houska <ah(at)cybertec(dot)at> wrote:
> > I suppose you don't want to use logical decoding for CIC, do you? How can then
> > it be "the same" like in REPACK (CONCURRENTLY)? Or do you propose to rework
> > REPACK (CONCURRENTLY) from scratch so that it does not use logical decoding
> > either?
>
> My logic here chain is next:
> * looks like we may reuse snapshot reset technique for REPACK, using
> LR+some tricks
> * if it worked, why should we use reset technique + STIR (not LR too) in CIC?
Because it's more easy to reason about STIR than it is to reason about
LR, especially when it concerns things like "overhead in heavily
loaded systems".
For CIC, you know that the amount of IO required is proportional only
to the table's data. With LR, that guarantee is gone; concurrent
workloads may bloat the WAL that needs to be scanned to many times the
size of the data you didn't have to scan.
> * mostly because it is not possible to active LR for some of tables
> * but there is (your) patch what aims to add the ability to activate
> LR for any table
> * if it worked - it feels natural to replace STIR by LR to keep things
> looking the same and working the same way
>
> While STIR may be more efficient and simple for CIC - it is still an
> additional entity in the PG domain, so LR may be a better solution
> from a system design perspective.
LR is a very complicated system that depends on WAL and various other
subsystems to work; and has a significant amount of overhead.
I disagree with any work to make (concurrent) index creation depend on
WAL; it is _not_ the right approach. Don't shoe-horn this into that.
> But it is only thought so far, because I have not yet proved reset
> snapshot is possible for REPACK (need to do some POC at least).
> What do you think?
I don't think we should be worrying about REPACK here and now.
> Also, I think I'll extract reset-snapshot for CIC in a separate CF
> entry, since it still may be used with or without either STIR or LR.
Thanks!
Kind regards,
Matthias van de Meent
Databricks (https://www.databricks.com)
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Hannu Krosing <hannuk(at)google(dot)com> |
| Cc: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-02 12:02:32 |
| Message-ID: | CAEze2Wiv_hb-1vOdceoMH0P+i+ATv-YZQEweuK0Fdib55eqXkg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 28 Nov 2025 at 20:08, Hannu Krosing <hannuk(at)google(dot)com> wrote:
>
> On Fri, Nov 28, 2025 at 7:31 PM Matthias van de Meent
> <boekewurm+postgres(at)gmail(dot)com> wrote:
> >
> > On Fri, 28 Nov 2025 at 18:58, Hannu Krosing <hannuk(at)google(dot)com> wrote:
> > >
> > > On Fri, Nov 28, 2025 at 5:58 PM Matthias van de Meent
> > > <boekewurm+postgres(at)gmail(dot)com> wrote:
> > > >
> > > ...
> > > > I'm a bit worried, though, that LR may lose updates due to commit
> > > > order differences between WAL and PGPROC. I don't know how that's
> > > > handled in logical decoding, and can't find much literature about it
> > > > in the repo either.
> > >
> > > Now the reference to logical decoding made me think that maybe to real
> > > fix for CIC would be to leverage logical decoding for the 2nd pass of
> > > CIC and not wore about in-page visibilities at all.
> >
> > -1: Requiring the logical decoding system just to reindex an index
> > without O(tablesize) lock time adds too much overhead, and removes
> > features we currently have (CIC on unlogged tables). wal_level=logical
> > *must not* be required for these tasks if we can at all avoid it.
> > I'm also not sure whether logical decoding gets access to the HOT
> > information of the updated tuples involved, and therefore whether the
> > index build can determine whether it must or can't insert the tuple.
>
> There are more and more cases (not just CIC here) where using logical
> decoding would be the most efficient solution, so why not instead
> start improving it instead of complicating the system in various
> places?
Because Logical Replication implies Replication, which in turn implies
(more) WAL generation. And if an unlogged table still generates WAL in
DML, then it's not really an unlogged table, in which case we've
broken a promise to the user [see: CREATE TABLE's UNLOGGED
description]. Adding features to WAL which replicas can't (mustn't!)
do anything with is always going to be bloat in my view.
I also don't know how you measure efficiency, but I don't consider LR
to be particularly efficient in any metric, apart from maybe "wasting
DBA time with abandoned slots". LR parses WAL, which is a conveyor
belt with _all_ changes, and given that WAL has no real upper boundary
on how large it can grow, LR would have to touch an unbounded amount
of data to get only the changes it needs. We already have ways to get
those changes without parsing an unbounded amount of data, so why not
use that instead?
> We could even start selectively logging UNLOGGED and TEMP tables when
> we start CIC if CIC has enough upsides.
Which is why I hate this idea. There can't be enough upsides to
counteract the enormous downside of increasing the size of the data we
need to ship to replicas when the replicas can't ever use that data.
Replicas were able to use the added data of LR before 17 when they
were promoted, so it wasn't terrible to include more data in the WAL,
but what's proposed here is to add data that literally nobody on the
replica can use; wasting WAL storage and replication bandwidth.
Lastly, LR requires replication slots, which are very expensive to
maintain. Currently, you can do CIC/RIC with any number of backends
you want up to max_backends, but this doesn't work if you'd want to
use LR, as you'd now need to have max_replication_slots proportional
to max_connections.
Again, -1 on LR for UNLOGGED/TEMP tables. Or LR in general when the
user explicitly asked for `wal_level NOT IN ('logical')`
> > I don't think logical decoding is sufficient, because we don't know
> > which tuples were already inserted into the index by their own
> > backends, so we don't know which tuples' index entries we must skip.
>
> The premise of pass2 in CIC is that we collect all the rows that were
> inserted after CIC started for which we are not 100% sure that they
> are inserted in the index. We can only be sure they are inserted for
> transactions started after pass1 completed and the index became
> visible and available for inserts.
I'm not sure this is true; wouldn't it be possible for a transaction
to start before the index became visible, but because of READ
COMMITTED get access to the index after one statement? I.e. two
statements that straddle the index becoming visible? That way, a
transaction could start to see the index after it first modified some
tuples; creating a hybrid visibility state.
> And we do not care about hot update chains dusing normal CREATE INDEX
> or first pass of CIC - we just index what is visible NOW wit no regard
> of weather the tuple is at the end of HOT update chain.
We do care about HOT update chains, because the TID of the HOT root is
indexed, and not necessarily the TID of the scanned tuple.
> > PS. I think the same should be true for REPACK CONCURRENTLY, but
> > that's a new command with yet-to-be-determined semantics, unlike CIC
> > which has been part of PG for 6 years.
>
> CIC has been around way longer, since 8.2 released in 2006, so more
> like 20 years :)
Ah, so RIC wasn't introduced together with CIC? TIL.
Kind regards,
Matthias van de Meent
Databricks (https://www.databricks.com)
| From: | Antonin Houska <ah(at)cybertec(dot)at> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-04 08:34:54 |
| Message-ID: | 5293.1764837294@localhost |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> wrote:
> On Mon, 1 Dec 2025 at 10:09, Antonin Houska <ah(at)cybertec(dot)at> wrote:
> >
> > Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> wrote:
> >
> > > I'm a bit worried, though, that LR may lose updates due to commit
> > > order differences between WAL and PGPROC. I don't know how that's
> > > handled in logical decoding, and can't find much literature about it
> > > in the repo either.
> >
> > Can you please give me an example of this problem? I understand that two
> > transactions do this
> >
> > T1: RecordTransactionCommit()
> > T2: RecordTransactionCommit()
> > T2: ProcArrayEndTransaction()
> > T1: ProcArrayEndTransaction()
> >
> > but I'm failing to imagine this if both transactions are trying to update the
> > same row.
>
> Correct, it doesn't have anything to do with two transactions updating
> the same row; but instead the same transaction getting applied twice;
> related to issues described in (among others) [0]:
> Logical replication applies transactions in WAL commit order, but
> (normal) snapshots on the primary use the transaction's persistence
> requirements (and procarray lock acquisition) as commit order.
>
> This can cause the snapshot to see T2 as committed before T1, whilst
> logical replication will apply transactions in T1 -> T2 order. This
> can break the exactly-once expectations of commits, because a normal
> snapshot taken between T2 and T1 on the primary (i.e., T2 is
> considered committed, but T1 not) will have T2 already applied. LR
> would have to apply changes of T1, which also implies it'd eventually
> get to T2's commit and apply that too. Alternatively, it'd skip past
> T2 because that's already present in the snapshot, and lose the
> changes that were committed with T1.
ISTM that what you consider a problem is copying the table using PGPROC-based
snapshot and applying logically decoded commits to the result - is that what
you mean?
In fact, LR (and also REPACK) uses snapshots generated by the logical decoding
system. The information on running/committed transactions is based here on
replaying WAL, not on PGPROC. Thus if the snapshot sees T2 already applied, it
means that the T2's COMMIT record was already decoded, and therefore no data
change of that transaction should be passed to the output plugin (and
consequently applied to the new table).
--
Antonin Houska
Web: https://www.cybertec-postgresql.com
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Antonin Houska <ah(at)cybertec(dot)at> |
| Cc: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-04 16:32:48 |
| Message-ID: | CAEze2WgCuzsFpH_=ySAToT7bAFyj_cb82ZFnMeexnd-NYiVeOw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, 4 Dec 2025 at 09:34, Antonin Houska <ah(at)cybertec(dot)at> wrote:
>
> Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> wrote:
>
> > On Mon, 1 Dec 2025 at 10:09, Antonin Houska <ah(at)cybertec(dot)at> wrote:
> > >
> > > Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> wrote:
> > >
> > > > I'm a bit worried, though, that LR may lose updates due to commit
> > > > order differences between WAL and PGPROC. I don't know how that's
> > > > handled in logical decoding, and can't find much literature about it
> > > > in the repo either.
> > >
> > > Can you please give me an example of this problem? I understand that two
> > > transactions do this
> > >
> > > T1: RecordTransactionCommit()
> > > T2: RecordTransactionCommit()
> > > T2: ProcArrayEndTransaction()
> > > T1: ProcArrayEndTransaction()
> > >
> > > but I'm failing to imagine this if both transactions are trying to update the
> > > same row.
> >
> > Correct, it doesn't have anything to do with two transactions updating
> > the same row; but instead the same transaction getting applied twice;
> > related to issues described in (among others) [0]:
> > Logical replication applies transactions in WAL commit order, but
> > (normal) snapshots on the primary use the transaction's persistence
> > requirements (and procarray lock acquisition) as commit order.
> >
> > This can cause the snapshot to see T2 as committed before T1, whilst
> > logical replication will apply transactions in T1 -> T2 order. This
> > can break the exactly-once expectations of commits, because a normal
> > snapshot taken between T2 and T1 on the primary (i.e., T2 is
> > considered committed, but T1 not) will have T2 already applied. LR
> > would have to apply changes of T1, which also implies it'd eventually
> > get to T2's commit and apply that too. Alternatively, it'd skip past
> > T2 because that's already present in the snapshot, and lose the
> > changes that were committed with T1.
>
> ISTM that what you consider a problem is copying the table using PGPROC-based
> snapshot and applying logically decoded commits to the result - is that what
> you mean?
Correct.
> In fact, LR (and also REPACK) uses snapshots generated by the logical decoding
> system. The information on running/committed transactions is based here on
> replaying WAL, not on PGPROC.
OK, that's good to know. For reference, do you know where this is
documented, explained, or implemented?
I'm asking, because the code that I could find didn't seem use any
special snapshot (tablesync.c uses
`PushActiveSnapshot(GetTransactionSnapshot())`), and the other
reference to LR's snapshots (snapbuild.c, and inside
`GetTransactionSnapshot()`) explicitly said that its snapshots are
only to be used for catalog lookups, never for general-purpose
queries.
Kind regards,
Matthias van de Meent
Databricks (https://www.databricks.com)
| From: | Antonin Houska <ah(at)cybertec(dot)at> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-04 19:15:44 |
| Message-ID: | 120851.1764875744@localhost |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> wrote:
> On Thu, 4 Dec 2025 at 09:34, Antonin Houska <ah(at)cybertec(dot)at> wrote:
> >
> > ISTM that what you consider a problem is copying the table using PGPROC-based
> > snapshot and applying logically decoded commits to the result - is that what
> > you mean?
>
> Correct.
>
> > In fact, LR (and also REPACK) uses snapshots generated by the logical decoding
> > system. The information on running/committed transactions is based here on
> > replaying WAL, not on PGPROC.
>
> OK, that's good to know. For reference, do you know where this is
> documented, explained, or implemented?
All my knowledge of these things is from source code.
> I'm asking, because the code that I could find didn't seem use any
> special snapshot (tablesync.c uses
> `PushActiveSnapshot(GetTransactionSnapshot())`),
My understanding is that this is what happens on the subscription side. Some
lines above that however, walrcv_create_slot(..., CRS_USE_SNAPSHOT, ...) is
called which in turn calls CreateReplicationSlot(..., CRS_USE_SNAPSHOT, ...)
on the publication side and it sets that snapshot for the transaction on the
remote (publication) side:
else if (snapshot_action == CRS_USE_SNAPSHOT)
{
Snapshot snap;
snap = SnapBuildInitialSnapshot(ctx->snapshot_builder);
RestoreTransactionSnapshot(snap, MyProc);
}
> and the other
> reference to LR's snapshots (snapbuild.c, and inside
> `GetTransactionSnapshot()`) explicitly said that its snapshots are
> only to be used for catalog lookups, never for general-purpose
> queries.
I think the reason is that snapbuild.c only maintains snapshots for catalog
scans, because in logical decoding you only need to scan catalog tables. This
is especially to find out which tuple descriptor was valid when particular
data change (INSERT / UPDATE / DELETE) was WAL-logged - the output plugin
needs the correct version of tuple descriptor to deform each tuple. However
there is no need to scan non-catalog tables: as long as wal_level=logical, the
WAL records contains all the information needed for logical replication
(including key values). So snapbuild.c only keeps track of transactions that
modify system catalog and uses this information to create the snapshots.
A special case is if you pass need_full_snapshot=true to
CreateInitDecodingContext(). In this case the snapshot builder tracks commits
of all transactions, but only does so until SNAPBUILD_CONSISTENT state is
reached. Thus, just before the actual decoding starts, you can get a snapshot
to scan even non-catalog tables (SnapBuildInitialSnapshot() creates that, like
in the code above). (For REPACK, I'm trying to teach snapbuild.c recognize
that transaction changed one particular non-catalog table, so it can build
snapshots to scan this one table anytime.)
Another reason not to use those snapshots for non-catalog tables is that
snapbuild.c creates snapshots of the kind SNAPSHOT_HISTORIC_MVCC. If you used
this for non-catalog tables, HeapTupleSatisfiesHistoricMVCC() would be used
for visibility checks instead of HeapTupleSatisfiesMVCC(). The latter can
handle tuples surviving from older version of postgres, but the earlier
cannot:
/* Used by pre-9.0 binary upgrades */
if (tuple->t_infomask & HEAP_MOVED_OFF)
No such tuples should appear in the catalog because initdb always creates it
from scratch.
For LR, SnapBuildInitialSnapshot() takes care of the conversion from
SNAPSHOT_HISTORIC_MVCC to SNAPSHOT_MVCC.
--
Antonin Houska
Web: https://www.cybertec-postgresql.com
| From: | Hannu Krosing <hannuk(at)google(dot)com> |
|---|---|
| To: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | Antonin Houska <ah(at)cybertec(dot)at>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-04 21:03:33 |
| Message-ID: | CAMT0RQRT2wjMtH0iDLkzqAh9=SSo+Oed7jDT3jvsHXOgjY91Gw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I just sent a small patch for logical decoding to pgsql-hackers@
exposing to logical decoding old and new tuple ids and a boolean
telling if an UPDATE is HOT.
Feel free to test if this helps here as well
On Thu, Dec 4, 2025 at 8:15 PM Antonin Houska <ah(at)cybertec(dot)at> wrote:
>
> Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> wrote:
>
> > On Thu, 4 Dec 2025 at 09:34, Antonin Houska <ah(at)cybertec(dot)at> wrote:
> > >
> > > ISTM that what you consider a problem is copying the table using PGPROC-based
> > > snapshot and applying logically decoded commits to the result - is that what
> > > you mean?
> >
> > Correct.
> >
> > > In fact, LR (and also REPACK) uses snapshots generated by the logical decoding
> > > system. The information on running/committed transactions is based here on
> > > replaying WAL, not on PGPROC.
> >
> > OK, that's good to know. For reference, do you know where this is
> > documented, explained, or implemented?
>
> All my knowledge of these things is from source code.
>
> > I'm asking, because the code that I could find didn't seem use any
> > special snapshot (tablesync.c uses
> > `PushActiveSnapshot(GetTransactionSnapshot())`),
>
> My understanding is that this is what happens on the subscription side. Some
> lines above that however, walrcv_create_slot(..., CRS_USE_SNAPSHOT, ...) is
> called which in turn calls CreateReplicationSlot(..., CRS_USE_SNAPSHOT, ...)
> on the publication side and it sets that snapshot for the transaction on the
> remote (publication) side:
>
> else if (snapshot_action == CRS_USE_SNAPSHOT)
> {
> Snapshot snap;
>
> snap = SnapBuildInitialSnapshot(ctx->snapshot_builder);
> RestoreTransactionSnapshot(snap, MyProc);
> }
>
> > and the other
> > reference to LR's snapshots (snapbuild.c, and inside
> > `GetTransactionSnapshot()`) explicitly said that its snapshots are
> > only to be used for catalog lookups, never for general-purpose
> > queries.
>
> I think the reason is that snapbuild.c only maintains snapshots for catalog
> scans, because in logical decoding you only need to scan catalog tables. This
> is especially to find out which tuple descriptor was valid when particular
> data change (INSERT / UPDATE / DELETE) was WAL-logged - the output plugin
> needs the correct version of tuple descriptor to deform each tuple. However
> there is no need to scan non-catalog tables: as long as wal_level=logical, the
> WAL records contains all the information needed for logical replication
> (including key values). So snapbuild.c only keeps track of transactions that
> modify system catalog and uses this information to create the snapshots.
>
> A special case is if you pass need_full_snapshot=true to
> CreateInitDecodingContext(). In this case the snapshot builder tracks commits
> of all transactions, but only does so until SNAPBUILD_CONSISTENT state is
> reached. Thus, just before the actual decoding starts, you can get a snapshot
> to scan even non-catalog tables (SnapBuildInitialSnapshot() creates that, like
> in the code above). (For REPACK, I'm trying to teach snapbuild.c recognize
> that transaction changed one particular non-catalog table, so it can build
> snapshots to scan this one table anytime.)
>
> Another reason not to use those snapshots for non-catalog tables is that
> snapbuild.c creates snapshots of the kind SNAPSHOT_HISTORIC_MVCC. If you used
> this for non-catalog tables, HeapTupleSatisfiesHistoricMVCC() would be used
> for visibility checks instead of HeapTupleSatisfiesMVCC(). The latter can
> handle tuples surviving from older version of postgres, but the earlier
> cannot:
>
> /* Used by pre-9.0 binary upgrades */
> if (tuple->t_infomask & HEAP_MOVED_OFF)
>
> No such tuples should appear in the catalog because initdb always creates it
> from scratch.
>
> For LR, SnapBuildInitialSnapshot() takes care of the conversion from
> SNAPSHOT_HISTORIC_MVCC to SNAPSHOT_MVCC.
>
> --
> Antonin Houska
> Web: https://www.cybertec-postgresql.com
>
>
| From: | Heikki Linnakangas <hlinnaka(at)iki(dot)fi> |
|---|---|
| To: | Hannu Krosing <hannuk(at)google(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | Antonin Houska <ah(at)cybertec(dot)at>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-16 13:43:53 |
| Message-ID: | 4b368c17-a614-401b-a335-398450249c47@iki.fi |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Didn't know which part of this thread to quote and reply to, so I'll
comment on the whole thing. This is a mix of a summary of the ideas
already discussed, and a new proposal.
Firstly, I think the STIR approach is the right approach at the high
level. I don't like the logical decoding idea, for the reasons Matthias
and Mikhail already mentioned. Maybe there's some synergy with REPACK,
but it feels different enough that I doubt it. Let's focus on the STIR
approach.
Summary of CIC as it is today
-----------------------------
To recap, the CIC approach at very high level is:
1. Build the index, while backends are modifying the table concurrently
2. Retail insert all the tuples that we missed in step 1.
A lot of logic and coordination goes into determining what was missed in
step 1. Currently, it involves snapshots, waiting for concurrent
transactions to finish, and re-scanning the index and the table.
The STIR idea is to maintain a little data structure on the side where
we collect items that are inserted between steps 1 and 2, to avoid
re-scanning the table.
Shmem struct
------------
One high-level observation:
We're using the catalog for inter-process communication, with the
indisready and indisvalid flags, and now with STIR by having a special,
ephemeral index AM. That feels unnecessarily difficult. I propose that
we introduce a little shared memory struct to keep track of in-progress
CONCURRENTLY index builds.
In the first transaction that inserts the catalog entry with
indisready=false, also create a shmem struct. In that struct, we can
store information about what state the build is in, and whether
insertions should go to the STIR or to the real index.
Avoid one wait-for-all-transactions step using the shmem struct
---------------------------------------------------------------
As one small incremental improvement, we could use the shmem struct to
avoid one of the "wait for all transactions" steps in the current
implementation. In validate_index(), after we mark the index as
'indisready' we have to wait for all transactions to finish, to ensure
that all subsequent insertions have seen the indisready=true change. We
could avoid that by setting a flag in the shmem struct instead, so that
all backends would see instantly that the flag is flipped.
Improved STIR approach
----------------------
Here's another proposal using the STIR approach. It's a little different
from the patches so far:
- Instead of having an ephemeral index AM, I'm imagining that
index_insert() has access to the shmem struct, and knows about the STIR
and can redirect insertions to it.
- I want to avoid re-scanning the index as well as the heap. To
accomplish that, track more precisely which tuples are already in the
index and which are not, by storing XID cutoffs in the shmem struct.
The proposal:
1. Insert the catalog entry with indisvalid = false and indisready =
false. Commit the transaction.
2. Wait for all transactions to finish.
- Now we know that all subsequently-started transactions will see the
index and will take it into account when deciding HOT chains. (No
changes to current implementation so far)
- All subsequently-started transactions will now also check the shmem
struct for the status of the index build, in index_insert(). We'll use
the shmem struct to coordinate the later steps.
3. Atomically do the following:
3.1 Take snapshot A
3.2 Store the snapshot's xmax in the shmem struct where all concurrent
backends can see it. Let's call this "cutoff A".
After this step, whenever a backend inserts a new tuple, it will append
its TID to the STIR if the transaction's XID >= cutoff A. (No insertions
to the actual index yet)
4. Build the index using snapshot A. It will include all tuples visible
or in-progress according to the snapshot.
5. Atomically do the following:
5.1. Take snapshot B
5.2. Store the snapshot's xmax in the shmem struct. We'll call this
cutoff B.
From now on, backends insert all tuples >= cutoff B directly to the
index. Tuples between A and B continue to be appended to the STIR.
6. Wait for all transactions < B to finish.
At this stage:
- All tuples < A are in the index. They were included in the bulk ambuild.
- All tuples between A and B are in the STIR.
- All tuples >= B are inserted to the index by the backends
7. Retail insert all the tuples from the STIR to the index.
Snapshot refreshing
-------------------
The above proposal doesn't directly accomplish the original goal of
advancing the global xmin horizon. You still need two long-lived
snapshots. It does however make CIC faster, by eliminating the full
index scan and table scan in the validate_index() stage. That already
helps a little.
I believe it can be extended to also advance xmin horizon:
- In step 4, while we are building the index, we can periodically get a
new snapshot, update the cutoff in the shmem struct, and drain the STIR
of the tuples that are already in it.
- In step 7, we can take a new snapshot as often as we like. The
snapshot is only used to evaluate expressions.
- Heikki
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnaka(at)iki(dot)fi> |
| Cc: | Hannu Krosing <hannuk(at)google(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Antonin Houska <ah(at)cybertec(dot)at>, Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-16 21:58:00 |
| Message-ID: | CADzfLwWUM2H2+daMv9q0+roX_NGe3cPT+AgvQ60Vh_J-e3ts6Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Heikki!
On Tue, Dec 16, 2025 at 2:43 PM Heikki Linnakangas <hlinnaka(at)iki(dot)fi> wrote:
> Firstly, I think the STIR approach is the right approach at the high
> level. I don't like the logical decoding idea, for the reasons Matthias
> and Mikhail already mentioned. Maybe there's some synergy with REPACK,
> but it feels different enough that I doubt it. Let's focus on the STIR
> approach.
Thanks for checking that thread.
> In the first transaction that inserts the catalog entry with
> indisready=false, also create a shmem struct. In that struct, we can
> store information about what state the build is in, and whether
> insertions should go to the STIR or to the real index.
Yes, it might look simpler, but from other point of view:
* we need to check that shmem for each index insert (whenever we build
something or not)
* or we need to put something into an index list with information
"write instead of that index into that shmem"
* currently we have some proven mechanics related to transactions,
catalog snapshots, relcache, invalidation etc. Some tricky
synchronization may be required here (to avoid any drift of way
transaction see shmem and relcache).
> As one small incremental improvement, we could use the shmem struct to
> avoid one of the "wait for all transactions" steps in the current
> implementation. In validate_index(), after we mark the index as
> 'indisready' we have to wait for all transactions to finish, to ensure
> that all subsequent insertions have seen the indisready=true change. We
> could avoid that by setting a flag in the shmem struct instead, so that
> all backends would see instantly that the flag is flipped.
That may be tricky. If I set a flag - what if someone checked it 1ns
ago and decided it is not required to write something in the index?
How to ensure that now everyone really knows about it without heavy
locking?
In all current maintenance operations we ensure in some way (by
locking\unlocking a relation or waiting for transactions) everyone has
fresh enough relcache. Don't think we should involve anything special
for the CIC scenario here.
But some universal solution (like ensuring that every other
transaction that had an outdated relcache is ended) may benefit all
related scenarios.
> Improved STIR approach
>
> Here's another proposal using the STIR approach. It's a little different
> from the patches so far:
> ....
> 7. Retail insert all the tuples from the STIR to the index.
Hm, that clever idea...
At the same time my tests show what index scan is light compared to
heap scans (especially second one - it is not paralleled).
> Snapshot refreshing
> -------------------
> - In step 4, while we are building the index, we can periodically get a
> new snapshot, update the cutoff in the shmem struct, and drain the STIR
> of the tuples that are already in it.
But together with snapshot resetting such an approach is still more
effective (in terms of index scan) but feels much more complex,
including some complex locking.
Need to think a little bit here.
Best regards,
Mikhail.
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnaka(at)iki(dot)fi> |
| Cc: | Hannu Krosing <hannuk(at)google(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Antonin Houska <ah(at)cybertec(dot)at>, Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2025-12-17 18:22:56 |
| Message-ID: | CAEze2WjjL2Uee7ZZzFr+sDe9jdFtaoX6TWdry6NRvGr2FX0ASw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 16 Dec 2025 at 14:43, Heikki Linnakangas <hlinnaka(at)iki(dot)fi> wrote:
>
> Summary of CIC as it is today
> -----------------------------
>
> To recap, the CIC approach at very high level is:
>
> 1. Build the index, while backends are modifying the table concurrently
>
> 2. Retail insert all the tuples that we missed in step 1.
>
> A lot of logic and coordination goes into determining what was missed in
> step 1. Currently, it involves snapshots, waiting for concurrent
> transactions to finish, and re-scanning the index and the table.
>
> The STIR idea is to maintain a little data structure on the side where
> we collect items that are inserted between steps 1 and 2, to avoid
> re-scanning the table.
During step 1, up to step 2, indeed.
> Shmem struct
> ------------
>
> One high-level observation:
>
> We're using the catalog for inter-process communication, with the
> indisready and indisvalid flags, and now with STIR by having a special,
> ephemeral index AM. That feels unnecessarily difficult. I propose that
> we introduce a little shared memory struct to keep track of in-progress
> CONCURRENTLY index builds.
>
> In the first transaction that inserts the catalog entry with
> indisready=false, also create a shmem struct. In that struct, we can
> store information about what state the build is in, and whether
> insertions should go to the STIR or to the real index.
>
> Avoid one wait-for-all-transactions step using the shmem struct
> ---------------------------------------------------------------
>
> As one small incremental improvement, we could use the shmem struct to
> avoid one of the "wait for all transactions" steps in the current
> implementation. In validate_index(), after we mark the index as
> 'indisready' we have to wait for all transactions to finish, to ensure
> that all subsequent insertions have seen the indisready=true change. We
> could avoid that by setting a flag in the shmem struct instead, so that
> all backends would see instantly that the flag is flipped.
>
>
> Improved STIR approach
> ----------------------
>
> Here's another proposal using the STIR approach. It's a little different
> from the patches so far:
> [many steps]
I am not convinced that this new approach is correct, as it introduces
too many new moving components into concurent index creation. I'm
quite concerned about the correctness around snapshot xmax checks:
while the approach is in a different system than that of PG14.0's CIC
changes, I can't help but think that this will open another can of
worms that is similar to that bug; it also changes expectations about
snapshot contents (by conditionally including tuples in the
"visibility" of STIR data structure), and I'm not even sure that it
guarantees that STIR contains all possibly-visible-after-CIC tuples
that aren't visible in the snapshot(s) of the main table scan.
So, let's not complicate these changes more than what they already are.
> Snapshot refreshing
> -------------------
>
> The above proposal doesn't directly accomplish the original goal of
> advancing the global xmin horizon. You still need two long-lived
> snapshots. It does however make CIC faster, by eliminating the full
> index scan and table scan in the validate_index() stage. That already
> helps a little.
>
> I believe it can be extended to also advance xmin horizon:
>
> - In step 4, while we are building the index, we can periodically get a
> new snapshot, update the cutoff in the shmem struct, and drain the STIR
> of the tuples that are already in it.
I'm against periodic draining of STIR:
1. With these periodic index scans, each heap page may be accessed
many more times than the current 2 times, as heap pages may be updated
at least once every time STIR is drained (up to MaxHeapTuplesPerPage);
thus strictly increasing the heap IO requirement compared to only
using STIR at phase 2.
2. The STIR index will contain TIDs of pages we have yet to scan; we'd
have to filter these out if we want to prevent duplicate TID insertion
(or we would risk having the STIR TID visible in an upcoming
visibility snapshot and inserting it twice).
3. The STIR would contain TIDs that may already be dead by the end of
the first phase, scanning the STIR index early could mean we'd still
have added it to the index.
4. The current approach to re-snapshotting happens completely inside
the table AM. Adding STIR draining to this phase would require
completely new code inside tableAMs or inside index AMs. It doesn't
make much sense for a tableAM to know about this.
All together I think those drawbacks for periodically draining STIR
are too significant to consider right now.
> - In step 7, we can take a new snapshot as often as we like. The
> snapshot is only used to evaluate expressions.
We shouldn't try to insert dead tuples into the index, so shouldn't we
also use some visibility checks in that step?
Kind regards,
Matthias van de Meent
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Heikki Linnakangas <hlinnaka(at)iki(dot)fi>, Hannu Krosing <hannuk(at)google(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Antonin Houska <ah(at)cybertec(dot)at>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, alvherre(at)kurilemu(dot)de, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-01-12 14:12:00 |
| Message-ID: | CADzfLwWoPxq0vRuW1fUc3FMujYE7bzgpRtG46VKmSd_dEffG3Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
This is a rebased version + some fixes + some comment/typos.
Best regards,
Mikhail.
| Attachment | Content-Type | Size |
|---|---|---|
| v28-0007-Refresh-snapshot-periodically-during-index-valid.patch | application/octet-stream | 21.3 KB |
| v28-0005-Track-and-drop-auxiliary-indexes-in-DROP-REINDEX.patch | application/octet-stream | 30.8 KB |
| v28-0003-Add-Datum-storage-support-to-tuplestore.patch | application/octet-stream | 19.9 KB |
| v28-0006-Optimize-auxiliary-index-handling.patch | application/octet-stream | 2.3 KB |
| v28-0004-Use-auxiliary-indexes-for-concurrent-index-opera.patch | application/octet-stream | 94.9 KB |
| v28-0001-Add-stress-tests-for-concurrent-index-builds.patch | application/octet-stream | 9.3 KB |
| v28-0002-Add-STIR-access-method-and-flags-related-to-auxi.patch | application/octet-stream | 36.3 KB |
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-01-15 22:04:19 |
| Message-ID: | CADzfLwVPQOF7m5x4d6=1tRJO==FUZdc3LeO=N_TpmOzii7iH_Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>:
> > Also, I think I'll extract reset-snapshot for CIC in a separate CF
> > entry, since it still may be used with or without either STIR or LR.
>
> Thanks!
>
Registered here: https://commitfest.postgresql.org/patch/6401/
Mikhail.
>
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-02-24 19:48:00 |
| Message-ID: | CADzfLwVHzfdD3WB0iNDKJtXQ37VCWrYnCULz3QKzwM7jJFHt-A@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello! Rebased.
Mikhail.
| Attachment | Content-Type | Size |
|---|---|---|
| v29-0005-Track-and-drop-auxiliary-indexes-in-DROP-REINDEX.patch | text/x-patch | 30.9 KB |
| v29-0002-Add-STIR-access-method-and-flags-related-to-auxi.patch | text/x-patch | 36.2 KB |
| v29-0004-Use-auxiliary-indexes-for-concurrent-index-opera.patch | text/x-patch | 94.9 KB |
| v29-0001-Add-stress-tests-for-concurrent-index-builds.patch | text/x-patch | 9.3 KB |
| v29-0003-Add-Datum-storage-support-to-tuplestore-Extend-t.patch | text/x-patch | 19.7 KB |
| v29-0007-Refresh-snapshot-periodically-during-index-valid.patch | text/x-patch | 21.3 KB |
| v29-0006-Optimize-auxiliary-index-handling.patch | text/x-patch | 2.1 KB |
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-03-09 00:09:00 |
| Message-ID: | CADzfLwU4oHR9gMV+OHgerp2ZLi3BSfLRZcBsG8g3G0f_RLPrGg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Rebased.
| Attachment | Content-Type | Size |
|---|---|---|
| v30-0006-Optimize-auxiliary-index-handling.patch | application/x-patch | 2.1 KB |
| v30-0002-Add-STIR-access-method-and-flags-related-to-auxi.patch | application/x-patch | 36.3 KB |
| v30-0004-Use-auxiliary-indexes-for-concurrent-index-opera.patch | application/x-patch | 94.9 KB |
| v30-0005-Track-and-drop-auxiliary-indexes-in-DROP-REINDEX.patch | application/x-patch | 30.9 KB |
| v30-0007-Refresh-snapshot-periodically-during-index-valid.patch | application/x-patch | 21.5 KB |
| v30-0003-Add-Datum-storage-support-to-tuplestore-Extend-t.patch | application/x-patch | 19.7 KB |
| v30-0001-Add-stress-tests-for-concurrent-index-builds.patch | application/x-patch | 9.3 KB |
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-03-23 22:08:00 |
| Message-ID: | CADzfLwVeQikArGV885zRMiSDW2-y=h=bvQiROvdq1Re1ojx9QA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
Fixed compilation, updates stress test, fixed few potential issues
with tuplestore, some style fixes around.
Best regards,
Mikhail.
| Attachment | Content-Type | Size |
|---|---|---|
| v31-0003-Add-Datum-storage-support-to-tuplestore-Extend-t.patch | application/octet-stream | 21.0 KB |
| v31-0002-Add-STIR-access-method-and-flags-related-to-auxi.patch | application/octet-stream | 36.4 KB |
| v31-0004-Use-auxiliary-indexes-for-concurrent-index-opera.patch | application/octet-stream | 94.9 KB |
| v31-0005-Track-and-drop-auxiliary-indexes-in-DROP-REINDEX.patch | application/octet-stream | 30.9 KB |
| v31-0001-Add-stress-tests-for-concurrent-index-builds.patch | application/octet-stream | 11.9 KB |
| v31-0006-Optimize-auxiliary-index-handling.patch | application/octet-stream | 2.1 KB |
| v31-0007-Refresh-snapshot-periodically-during-index-valid.patch | application/octet-stream | 22.5 KB |
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-03-28 19:17:00 |
| Message-ID: | CADzfLwVWEgcC2s4Fgrr1j8y4-MM2wXdcgg4_LxPprgDes2v8ew@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
Small fixes, comments, support for high isolation level, etc.
| Attachment | Content-Type | Size |
|---|---|---|
| v32-0001-Add-stress-tests-for-concurrent-index-builds.patch | application/octet-stream | 11.9 KB |
| v32-0005-Track-and-drop-auxiliary-indexes-in-DROP-REINDEX.patch | application/octet-stream | 31.7 KB |
| v32-0004-Use-auxiliary-indexes-for-concurrent-index-opera.patch | application/octet-stream | 98.0 KB |
| v32-0003-Add-Datum-storage-support-to-tuplestore-Extend-t.patch | application/octet-stream | 21.0 KB |
| v32-0002-Add-STIR-access-method-and-flags-related-to-auxi.patch | application/octet-stream | 36.6 KB |
| v32-0007-Refresh-snapshot-periodically-during-index-valid.patch | application/octet-stream | 27.0 KB |
| v32-0006-Optimize-auxiliary-index-handling.patch | application/octet-stream | 3.0 KB |
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-03-31 22:11:40 |
| Message-ID: | CADzfLwWJGCRJsWdNH8x1nh_5anbCbGQDLSL3hA2+bj+--29ahg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello!
Just rebased.
| Attachment | Content-Type | Size |
|---|---|---|
| v33-0001-Add-stress-tests-for-concurrent-index-builds.patch | application/x-patch | 11.9 KB |
| v33-0003-Add-Datum-storage-support-to-tuplestore-Extend-t.patch | application/x-patch | 21.0 KB |
| v33-0004-Use-auxiliary-indexes-for-concurrent-index-opera.patch | application/x-patch | 98.0 KB |
| v33-0005-Track-and-drop-auxiliary-indexes-in-DROP-REINDEX.patch | application/x-patch | 31.7 KB |
| v33-0002-Add-STIR-access-method-and-flags-related-to-auxi.patch | application/x-patch | 36.6 KB |
| v33-0007-Refresh-snapshot-periodically-during-index-valid.patch | application/x-patch | 27.0 KB |
| v33-0006-Optimize-auxiliary-index-handling.patch | application/x-patch | 3.0 KB |
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
| Cc: | Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-04-06 18:21:00 |
| Message-ID: | CADzfLwWQ4DKRRF5w2XUR9dFUtkxvKxKzWa5ARw7O9mSYdoufRg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Rebased once again.
| Attachment | Content-Type | Size |
|---|---|---|
| v34-0002-Add-STIR-access-method-and-flags-related-to-auxi.patch | application/octet-stream | 36.6 KB |
| v34-0001-Add-stress-tests-for-concurrent-index-builds.patch | application/octet-stream | 12.5 KB |
| v34-0003-Add-Datum-storage-support-to-tuplestore-Extend-t.patch | application/octet-stream | 21.0 KB |
| v34-0004-Use-auxiliary-indexes-for-concurrent-index-opera.patch | application/octet-stream | 98.1 KB |
| v34-0005-Track-and-drop-auxiliary-indexes-in-DROP-REINDEX.patch | application/octet-stream | 31.7 KB |
| v34-0006-Optimize-auxiliary-index-handling.patch | application/octet-stream | 3.0 KB |
| v34-0007-Refresh-snapshot-periodically-during-index-valid.patch | application/octet-stream | 27.1 KB |
| From: | Josh Kupershmidt <schmiddy(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-04-07 01:42:17 |
| Message-ID: | CAK3UJRGmCgCS5_pZDvugRmGhRuND0TwXXNs-u2sZzRQOE9E_JQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
I was interested in this feature, and took an initial look through the
patch. Sorry in advance that I'm missing some previous context from the
thread's history, I'm starting fresh here.
A few initial notes from looking at the v34 patches:
Usability and docs:
* We're leaving behind two invalid indexes now that the user has to figure
out how to drop in case of an error - that seems like it could be confusing
for the user. Could we have some better way (error handler,
background worker) try to perform this cleanup automatically? If not, we
should at least tell the user clearly in the error message that both
invalid indexes are left behind (i.e. "idx" and "idx_ccaux" in the example)
* Docs are inconsistent or confusing about whether there's one or two
indexes left behind in case of error - e.g. "command will fail but leave
behind *an* invalid index and its associated auxiliary index" - somewhat
implying there is only one invalid index, and somehow the auxiliary index
is valid?
* Similarly, when the doc mentions e.g. "drop the index" - it's not
necessarily clear which index we're talking about when there are two
invalid indexes left behind that the user will see with `\d`
* It would be nice to guard against users trying arbitrary CREATE INDEX
... USING stir(...) with a clear error
Few behavior notes and questions:
* One of the testcases (line 2478 of patch 0004) does `DELETE FROM
concur_reindex_tab4 WHERE c1 = 1;` but the table `concur_reindex_tab4`
looks like it has been dropped a few lines above that?
* The StirPageGetFreeSpace macro from patch 0002 reads
`StirPageGetMaxOffset(page)` which seems like it could cause an unsafe read
of opaque->maxoff if used on the metapage
* A comment explains "No predicate evaluation is needed here" , i.e. we
are skipping predicate evaluation in the validation scan step, assuming
that the auxiliary index contains only qualifying TIDs. Is this really
bulletproof for e.g. partial indexes which may no longer satisfy the
predicate at the time of the validation scan due to conflicting HOT updates?
Thanks
Josh
On Mon, Apr 6, 2026 at 2:22 PM Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>
wrote:
> Rebased once again.
>
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Josh Kupershmidt <schmiddy(at)gmail(dot)com> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-04-07 23:19:00 |
| Message-ID: | CADzfLwXpAHZujwO517mXwAtOD=LQsZfAK_JSgbQqGDeZVWgNCg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello, Josh!
Your review looks a bit LLM-generated, but anyway - thanks for review! :)
Especially because at least one point seems to be valid.
> We're leaving behind two invalid indexes now that the user has to figure
> out how to drop in case of an error - that seems like it could be confusing for the user.
> Could we have some better way (error handler, background worker) try to perform this cleanup automatically?
> If not, we should at least tell the user clearly in the error message that both
> invalid indexes are left behind (i.e. "idx" and "idx_ccaux" in the example)
Commit 0005 adds automatic dropping of auxiliary indexes when the
original index is reindexed or dropped. Also, documentation reflects
the ccaux index (similar to ccnew).
> Docs are inconsistent or confusing about whether there's one or two indexes left behind in case of error
> - e.g. "command will fail but leave behind *an* invalid index and its associated auxiliary index"
> somewhat implying there is only one invalid index, and somehow the auxiliary index is valid?
Auxiliary index is never marked as valid; I'm not sure we need to
highlight it here. Or do you have an idea how to rephrase?
> Similarly, when the doc mentions e.g. "drop the index" - it's not necessarily clear which index
> we're talking about when there are two invalid indexes left behind that the user will see with `\d`
In one commit it says: "method in such cases is to drop these indexes
and try again to perform".
After 0005 "The auxiliary index (suffixed with
<literal>_ccaux</literal>) will be automatically dropped when the main
index is dropped".
It seems clear to me, but feel free to provide your variant.
> * It would be nice to guard against users trying arbitrary CREATE INDEX ... USING stir(...) with a clear error
It will fail with "Building STIR indexes is not supported".
> One of the testcases (line 2478 of patch 0004) does `DELETE FROM concur_reindex_tab4 WHERE c1 = 1;`
> but the table `concur_reindex_tab4` looks like it has been dropped a few lines above that?
Hm, yep, I'll fix it.
> The StirPageGetFreeSpace macro from patch 0002 reads `StirPageGetMaxOffset(page)`
> which seems like it could cause an unsafe read of opaque->maxoff if used on the metapage
But it was never used for the metapage.
> A comment explains "No predicate evaluation is needed here" , i.e. we are skipping predicate
> evaluation in the validation scan step, assuming that the
> auxiliary index contains only qualifying TIDs. Is this really bulletproof for e.g. partial indexes which may
> no longer satisfy the predicate at the time of the validation scan due to conflicting HOT updates?
Conflicting HOT updates are not possible because the catalog contains
the new index definition from the start of the process.
Or do you mean a different scenario?
Best regards,
Mikhail.
| From: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
|---|---|
| To: | Josh Kupershmidt <schmiddy(at)gmail(dot)com> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-04-11 16:56:00 |
| Message-ID: | CADzfLwWC+KxYWb-2QotWaz-q1LK8koLNVUR1Q8obAtt+R_sORA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi!
Rebased, including fixes related to Josh's review.
Thanks!
| Attachment | Content-Type | Size |
|---|---|---|
| v35-0004-Use-auxiliary-indexes-for-concurrent-index-opera.patch | application/octet-stream | 97.5 KB |
| v35-0005-Track-and-drop-auxiliary-indexes-in-DROP-REINDEX.patch | application/octet-stream | 31.6 KB |
| v35-0003-Add-Datum-storage-support-to-tuplestore-Extend-t.patch | application/octet-stream | 21.0 KB |
| v35-0002-Add-STIR-access-method-and-flags-related-to-auxi.patch | application/octet-stream | 36.6 KB |
| v35-0001-Add-stress-tests-for-concurrent-index-builds.patch | application/octet-stream | 12.6 KB |
| v35-0006-Optimize-auxiliary-index-handling.patch | application/octet-stream | 3.0 KB |
| v35-0007-Refresh-snapshot-periodically-during-index-valid.patch | application/octet-stream | 27.1 KB |
| From: | Josh Kupershmidt <schmiddy(at)gmail(dot)com> |
|---|---|
| To: | Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, Antonin Houska <ah(at)cybertec(dot)at>, Hannu Krosing <hannuk(at)google(dot)com>, Sergey Sargsyan <sergey(dot)sargsyan(dot)2001(at)gmail(dot)com>, Álvaro Herrera <alvherre(at)kurilemu(dot)de>, Andres Freund <andres(at)anarazel(dot)de>, Michael Paquier <michael(at)paquier(dot)xyz>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org>, Andrey Borodin <amborodin86(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com> |
| Subject: | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date: | 2026-04-13 01:05:48 |
| Message-ID: | CAK3UJREa7qT_=QUx7Fc9D=Z2V-BAti8EXFR=9kB7yfN-bao32Q@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Apr 7, 2026 at 7:20 PM Mihail Nikalayeu <mihailnikalayeu(at)gmail(dot)com>
wrote:
> Hello, Josh!
>
> Your review looks a bit LLM-generated, but anyway - thanks for review! :)
> Especially because at least one point seems to be valid.
>
> > We're leaving behind two invalid indexes now that the user has to figure
> > out how to drop in case of an error - that seems like it could be
> confusing for the user.
> > Could we have some better way (error handler, background worker) try to
> perform this cleanup automatically?
> > If not, we should at least tell the user clearly in the error message
> that both
> > invalid indexes are left behind (i.e. "idx" and "idx_ccaux" in the
> example)
>
> Commit 0005 adds automatic dropping of auxiliary indexes when the
> original index is reindexed or dropped. Also, documentation reflects
> the ccaux index (similar to ccnew).
>
Well, we auto-drop the aux index if the user figures out that they should
drop the main index first.
> > Docs are inconsistent or confusing about whether there's one or two
> indexes left behind in case of error
> > - e.g. "command will fail but leave behind *an* invalid index and its
> associated auxiliary index"
> > somewhat implying there is only one invalid index, and somehow the
> auxiliary index is valid?
>
> Auxiliary index is never marked as valid; I'm not sure we need to
> highlight it here. Or do you have an idea how to rephrase?
>
For example in this doc change hunk:
@@ -664,12 +665,19 @@ postgres=# \d tab
col | integer | | |
Indexes:
"idx" btree (col) INVALID
+ "idx_ccaux" stir (col) INVALID
</programlisting>
- The recommended recovery
- method in such cases is to drop the index and try again to perform
- <command>CREATE INDEX CONCURRENTLY</command>. (Another possibility is
- to rebuild the index with <command>REINDEX INDEX
CONCURRENTLY</command>).
+ The recommended recovery method in such cases is to drop the index with
+ <command>DROP INDEX</command>. The auxiliary index (suffixed with
+ <literal>_ccaux</literal>) will be automatically dropped when the main
+ index is dropped. After dropping the indexes, you can try again to
perform
+ <command>CREATE INDEX CONCURRENTLY</command>. (Another possibility is
to
+ rebuild the index with <command>REINDEX INDEX CONCURRENTLY</command>,
+ which will also handle cleanup of any invalid auxiliary indexes.)
+ If the only invalid index is one suffixed <literal>_ccaux</literal>,
+ the recommended recovery method is just <literal>DROP INDEX</literal>
+ for that index.
</para>
The output we're showing the user from psql is two INVALID indexes, and
we're keeping the original doc suggestion on the first line that "The
recommended recovery method in such cases is to drop the index with DROP
INDEX". The next sentence clarifies a bit that there's an auxiliary index
that "will be automatically dropped". But now it's on the user to figure
out which index is which, and drop the right one.
> > Similarly, when the doc mentions e.g. "drop the index" - it's not
> necessarily clear which index
> > we're talking about when there are two invalid indexes left behind that
> the user will see with `\d`
>
> In one commit it says: "method in such cases is to drop these indexes
> and try again to perform".
> After 0005 "The auxiliary index (suffixed with
> <literal>_ccaux</literal>) will be automatically dropped when the main
> index is dropped".
> It seems clear to me, but feel free to provide your variant.
>
> > * It would be nice to guard against users trying arbitrary CREATE INDEX
> ... USING stir(...) with a clear error
>
> It will fail with "Building STIR indexes is not supported".
>
Sorry, you are right, this is handled with a good error.
>
> > One of the testcases (line 2478 of patch 0004) does `DELETE FROM
> concur_reindex_tab4 WHERE c1 = 1;`
> > but the table `concur_reindex_tab4` looks like it has been dropped a few
> lines above that?
>
> Hm, yep, I'll fix it.
>
> > The StirPageGetFreeSpace macro from patch 0002 reads
> `StirPageGetMaxOffset(page)`
> > which seems like it could cause an unsafe read of opaque->maxoff if used
> on the metapage
>
> But it was never used for the metapage.
>
Yes, but I think it'd be better not to leave a possible foot-gun around for
the next developer. Even just adding an AssertMacro like:
#define StirPageGetMaxOffset(page) (AssertMacro(!StirPageIsMeta(page)),
StirPageGetOpaque(page)->maxoff)
There are some other asserts for some of the trickier bookkeeping that
happens in this patch that I think would help check the code, and make it
easier to understand as well. E.g. adding an assertion check at the end of
StirPageAddItem(), and inside stirbulkdelete() (I tried calling it around
L499 of stir.c, just before 'while (itup < itupEnd)').
/*
* Validate that maxoff and pd_lower are consistent on a STIR data page.
*
* On a freshly initialized empty page, pd_lower is SizeOfPageHeaderData
* (set by PageInit). After the first insert, pd_lower is computed from
* PageGetContents which uses MAXALIGN(SizeOfPageHeaderData).
*/
static inline void
StirPageValidate(Page page)
{
Assert(!StirPageIsMeta(page));
Assert(StirPageGetOpaque(page)->maxoff == 0
? ((PageHeader) page)->pd_lower == SizeOfPageHeaderData
: ((PageHeader) page)->pd_lower ==
MAXALIGN(SizeOfPageHeaderData) +
StirPageGetOpaque(page)->maxoff * sizeof(StirTuple));
}
>
> > A comment explains "No predicate evaluation is needed here" , i.e. we
> are skipping predicate
> > evaluation in the validation scan step, assuming that the
> > auxiliary index contains only qualifying TIDs. Is this really
> bulletproof for e.g. partial indexes which may
> > no longer satisfy the predicate at the time of the validation scan due
> to conflicting HOT updates?
>
> Conflicting HOT updates are not possible because the catalog contains
> the new index definition from the start of the process.
> Or do you mean a different scenario?
>
Sorry for the false alarm, I believe you are right - I had to double
check RelationGetIndexAttrBitmap(), but I believe this is safe based on
the hotblockingattrs bitmap.
Overall, this is a nice improvement for CIC/RC that I think should help
particularly on large, busy systems.
Thanks,
Josh