
分子动力学 (MD) 模拟模拟原子在一段时间内的相互作用,并且需要强大的计算能力。然而,许多模拟的系统规模很小 (约 400K 个原子) ,未充分利用现代 GPU,导致一些计算能力闲置。为更大限度地提高 GPU 利用率并提高吞吐量,使用 NVIDIA 多进程服务 (MPS) 在同一 GPU 上同时运行多个模拟可能是一种有效的解决方案。
本文将介绍 MPS 的背景及其启用方式,以及吞吐量提升的基准测试。它还提供了一些使用 OpenMM (一种热门的 MD 引擎和框架) 的常见使用场景作为示例。
什么是 MPS?
MPS 是 CUDA 应用编程接口 (API) 的另一种二进制兼容实现。它允许多个进程通过减少上下文交换开销来更高效地共享 GPU,从而提高整体利用率。通过让所有进程共享一组调度资源,MPS 消除了在切换上下文时打开和关闭 GPU 的调度资源交换需求。
从 NVIDIA Volta GPU 生成开始,MPS 还允许不同进程的内核并发运行,这在单个进程无法使整个 GPU 完全饱和时很有帮助。所有 NVIDIA GPU、Volta 架构及更高版本均支持此功能。
MPS 的一个主要优势是可以使用常规用户权限启动。如需了解启用和禁用 MPS 的最简单方法,请使用以下代码:
nvidia-cuda-mps-control -d # Enables MPS
echo quit | nvidia-cuda-mps-control # Disables MPS
要与 MPS 同时运行多个 MD 模拟,请启动多个 sim.py 实例,每个实例都作为一个单独的进程。如果一个系统上有多个 GPU,您可以使用 CUDA_VISIBLE_DEVICES 进一步控制一个进程的目标 GPU 或 GPU。
CUDA_VISIBLE_DEVICES=0 python sim1.py &
CUDA_VISIBLE_DEVICES=0 python sim2.py &
...
请注意,启用 MPS 后,每次模拟的速度可能会变慢,但由于您可以并行运行多个模拟,因此整体吞吐量会更高。
OpenMM 教程
在本简短教程中,我们使用 OpenMM 8.2.0、CUDA 12 和 Python 3.12。
测试设置
要创建此环境,请参阅 OpenMM 安装指南。
conda create -n openmm8.2
conda activate openmm8.2
conda install -c conda-forge openmm cuda-version=12
安装后,使用以下命令进行测试:
python -m openmm.testInstallation
我们使用了 openmm/examples/benchmark.py GitHub 库中的基准测试脚本。我们使用以下代码段同时运行多个模拟:
NSIMS=2 # or 1, 4, 8
for i in `seq 1 NSIMS`;
do
python benchmark.py --platform=CUDA --test=pme --seconds=60 &
done
# test systems: pme (DHFR, 23k atoms), apoa1pme (92k), cellulose (409k)
MPS 基准测试
一般来说,系统尺寸越小,预期提升幅度就越大。图 1、2 和 3 显示了在三个基准系统上应用 MPS 的结果:使用一系列 GPU 的 DHFR ( 23K 个原子) 、ApoA1 ( 92K 个原子) 和纤维素 ( 408K 个原子) 。这些图表显示了在同一 GPU 上同时运行的模拟数量以及最终的总吞吐量。

DHFR 测试系统是这三个系统中最小的,因此在使用 MPS 的情况下,性能提升最大。对于包括 NVIDIA H100 Tensor Core 在内的部分 GPU,总吞吐量可增加一倍以上。


即使系统大小增长到 40.9 万个原子 (如纤维素基准测试) ,MPS 仍能使高端 GPU 实现约 20% 的总吞吐量。
用 CUDA_MPS_ACTIVE_THREAD_PERCENTAGE 实现更高吞吐量
默认情况下,MPS 允许所有进程访问 GPU 的所有资源。这有利于提升性能,因为当其他模拟处于空闲状态时,模拟可以充分利用所有可用资源。MD 模拟的力计算阶段比位置更新阶段具有更多的并行性,允许模拟使用更多的 GPU 资源来提高性能。
但是,由于多个进程同时运行,这通常是不必要的,并且可能会导致对性能的破坏性干扰。CUDA_MPS_ACTIVE_THREAD_PERCENTAGE 是一个环境变量,允许用户设置单个进程可用线程的最大百分比,这可用于进一步提高吞吐量。
要实现此结果,请修改代码段:
NSIMS=2 # or 1, 4, 8
export CUDA_MPS_ACTIVE_THREAD_PERCENTAGE=$(( 200 / NSIMS ))
for i in `seq 1 NSIMS`;
do
python benchmark.py --platform=CUDA --test=pme --seconds=60 &
done

CUDA_MPS_ACTIVE_THREAD_PERCENTAGE 可进一步提高某些 GPU 的吞吐量此测试表明,200 / number of MPS processes 的百分比会导致最高吞吐量。在此设置下,在单个 NVIDIA L40S 或 NVIDIA H100 GPU 上,8 次 DHFR 模拟的总吞吐量进一步增加约 15% – 25%,接近每天 5 微秒。这不仅仅是 GPU 上单个模拟的吞吐量翻倍。
用于 OpenFE 自由能计算的 MPS
估计自由能微扰 (FEP) 是 MD 模拟的热门应用。FEP 依赖于复制交换分子动力学 (REMD) 模拟,其中不同窗口中的多个模拟以并行和交换配置运行,以增强采样。在 OpenMM 生态系统中,OpenFreeEnergy (OpenFE) 包提供基于 openmmtools 中的多状态实现的协议。但是,这些仿真通过 OpenMM 上下文切换运行,一次仅执行一次仿真。因此,它也面临 GPU 利用率不足的问题。
MPS 可用于解决此问题。安装 OpenFE 后,可使用以下命令运行 FEP 分支:
openfe quickrun <input> <output directory>
按照相同的逻辑,您可以同时运行多个分支:
nvidia-cuda-mps-control -d # Enables MPS
openfe quickrun <input1> <output directory> &
openfe quickrun <input2> <output directory>
...
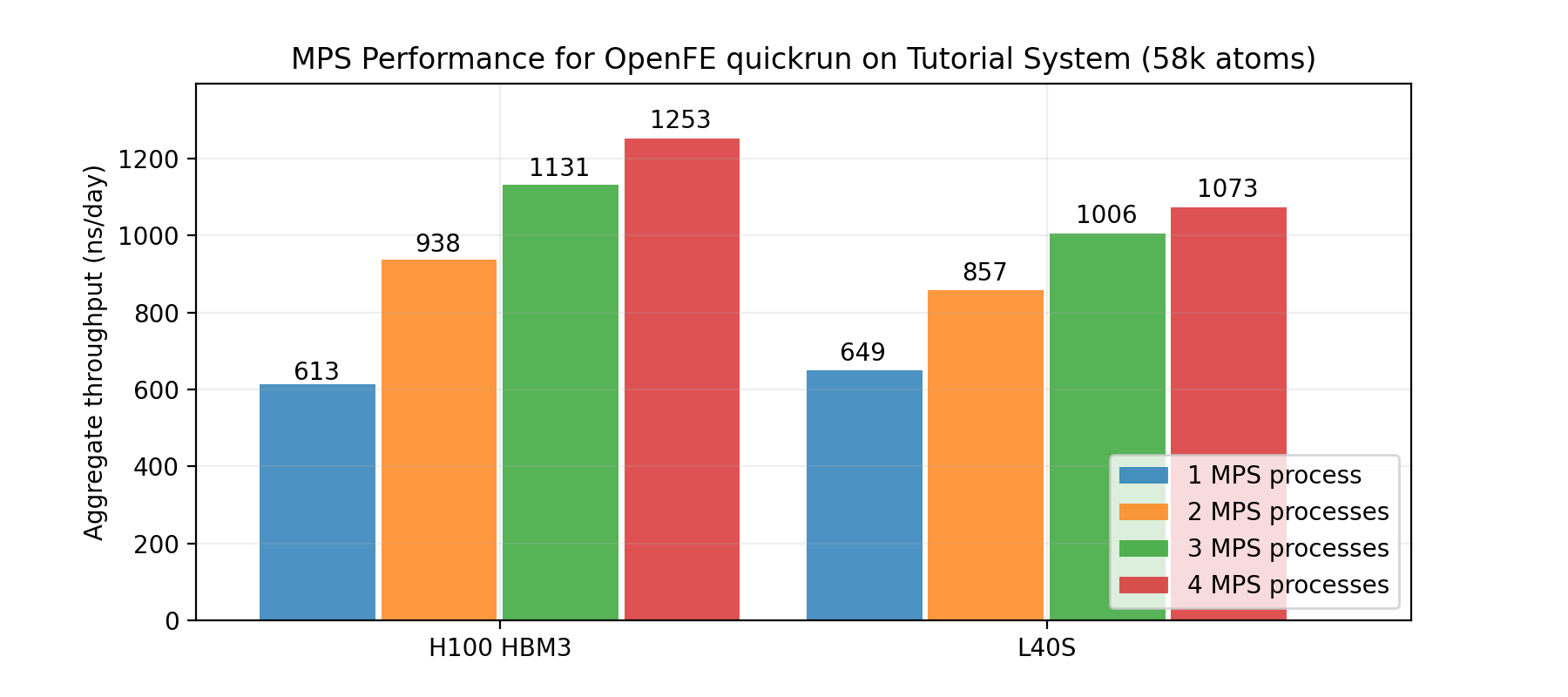
测量运行复制交换模拟的均衡阶段所需的时间,其中包括 12 × 100 ps 模拟。仿真在 L40S 或 H100 GPU 上运行。我们观察到,使用三个 MPS 进程时,吞吐量提高了 36%。
开始使用 MPS
MPS 是一款易于使用的工具,无需大量编码工作即可增加 MD 模拟吞吐量。本文探讨了使用多个不同的基准系统时不同 GPU 吞吐量的提升情况。我们研究了如何使用 CUDA_MPS_ACTIVE_THREAD_PERCENTAGE 进一步提高吞吐量。我们还将 MPS 应用于 OpenFE 自由能模拟,并观察到吞吐量增加。
在 NVIDIA GTC 点播会议“优化 GPU 利用率:了解 MIG 和 MPS”中详细了解 MPS。您可以在 NVIDIA 开发者 CUDA 论坛上提出 MPS 实施问题。
要开始使用 OpenMM 分子动力学模拟代码,请查看 OpenMM 教程。





