
在 Windows 上,创意、游戏和生产力应用方面的 AI 体验正在迅速扩展。有各种框架可用于在台式机、笔记本电脑或工作站上本地加速这些应用中的 AI 推理。开发者需要适应广泛的生态系统。他们必须在特定于硬件的库或跨供应商框架 (如 DirectML) 之间进行选择,以实现最高性能。DirectML 可简化 CPU、GPU 和 NPU 之间的部署,但并不总是充分发挥每个设备的潜力。在性能和兼容性之间取得适当平衡对于开发者至关重要。
今天,我们宣布推出适用于 RTX 的 NVIDIA TensorRT ,以应对这些挑战。它作为 Windows ML 的一部分在 Windows 11 上提供,Windows ML 是 Microsoft 在 Microsoft Build 上新发布的 AI 推理框架 。它们共同通过标准化 API 为开发者提供经 NVIDIA 优化的加速,从而实现跨各种硬件的无缝部署。
 图 1。Windows ML 推理堆栈中适用于 RTX 的 TensorRT 。 Foundry Local 是由 Microsoft 优化的一系列热门模型
图 1。Windows ML 推理堆栈中适用于 RTX 的 TensorRT 。 Foundry Local 是由 Microsoft 优化的一系列热门模型
什么是 TensorRT for RTX
TensorRT for RTX 是专为 Windows 构建的推理库。此新版本基于之前的 NVIDIA TensorRT 推理库对数据中心 GPU 的强大性能,针对 NVIDIA RTX GPU 进行了优化,与基准 DirectML 相比,优化幅度超过 50%,如图 2 所示。它还支持包括 FP4 在内的不同量化类型,使 FLUX-1.dev 等新一代生成式 AI 模型能够适应消费级 GPU。
它的一个关键优势是无需预先生成编译的推理引擎,因为这些引擎可以在目标 GPU 上在几秒钟内生成,如图 5 和 6 所示。 与硬件兼容引擎相比 ,这些特定于 SKU 的引擎可将性能提升高达 20%。该库现已轻量级,略低于 200 MB,如果使用 Windows ML,则无需在应用程序中预先打包,因为 Windows ML 将在后台自动下载必要的库。
 图 2。在 GeForce RTX 5090 上测得的性能。与 DirectML 相比,适用于 RTX 的 TensorRT 可显著提升热门 PC AI 工作负载的速度。
图 2。在 GeForce RTX 5090 上测得的性能。与 DirectML 相比,适用于 RTX 的 TensorRT 可显著提升热门 PC AI 工作负载的速度。
开发者可以在搭载 NVIDIA RTX GPU 的专用 NVIDIA Tensor Core 上使用 FP4 和 FP8 计算的原生加速,实现更高的吞吐量,如图 3 所示。
 图 3。适用于 RTX 的 TensorRT 将 FP8 和 FP4 GEMMs 用于扩散模型,从而提高吞吐量。FP16 流水线在低 VRAM 模式下运行
图 3。适用于 RTX 的 TensorRT 将 FP8 和 FP4 GEMMs 用于扩散模型,从而提高吞吐量。FP16 流水线在低 VRAM 模式下运行
Windows ML 公开预览版中提供了适用于 RTX 的 TensorRT。独立库也将于 6 月在 developer.nvidia.com 上提供。
我们一直在对 TensorRT for RTX 进行采样,以征求开发者的反馈,并且对收到的反馈感到惊讶。
Topaz Labs AI 引擎负责人 Dr. Suraj Raghuraman 表示:“Topaz Labs 快速集成了该库,消除了我们之前需要数周时间才能完成的预生成 TensorRT 引擎的需求。在我们的 2B 模型 (v0.9.6) 的 txt2video 和 img2video 用例中,TensorRT for RTX 可轻松将 PyTorch 在 Windows PC 上的 FP16 性能提升 70% 以上。借助 FP8,我们额外获得了 30% 的性能提升。所有这一切都需要不到 5 秒的令人慕的设备端 JIT 时间。我们很高兴能够探索该库可以使用我们最新的 13B 模型 (v0.9.7) 做些什么。” Lightricks 研究副总裁 Ofir Bibi 说道。
使用 TensorRT 为 RTX 编译模型
“适用于 RTX 推理库的 TensorRT 采用即时 (JIT) 编译的概念,并针对 RTX GPU 优化神经网络。整个流程十分高效,在最终用户设备上只需几秒钟即可完成,如下图 5 和 6 所示。这是一个一次性流程,可在应用程序安装时执行。目前,该库支持 CNN、音频、扩散和 Transformer 模型。”
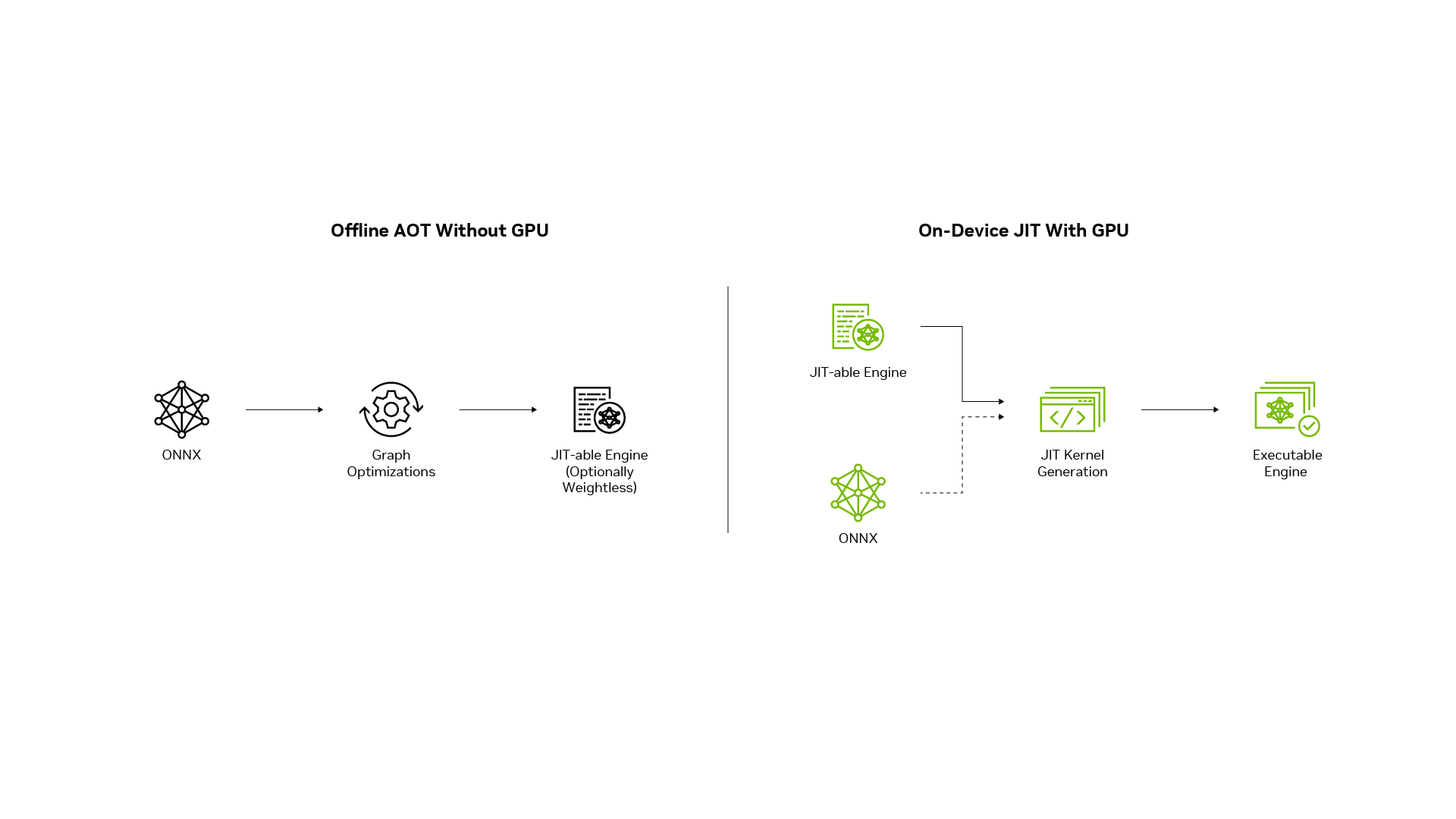
TensorRT for RTX 通过两阶段流程简化了将 ONNX 格式或通过原生 C++ API 定义的经过训练的神经网络转换为高度优化的推理引擎的过程,如图 4 所示。
AOT 编译阶段
与 GPU 无关的 AOT 阶段完全在 CPU 上执行。此阶段执行图形优化并生成中间引擎,可将其配置为可选的排除权重。此中间引擎兼容跨 GPU 和跨操作系统,允许开发者在 Windows 或 Linux 系统上连接到 x86/amd64 主机的任何 RTX GPU 上构建硬件优化的推理引擎。
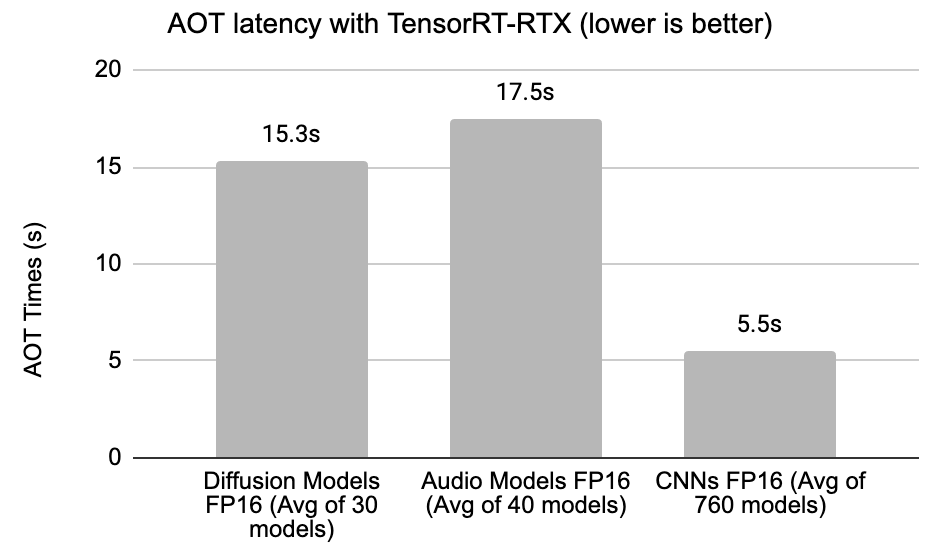
这使得“一次构建,在任意 NVIDIA GPU 上部署”的方法能够简化开发和部署工作流程。此过程所需的最小库占用不到 100 MB,通常在 15 秒内完成,如图 5 所示。开发者可以离线运行 AOT 阶段并将中间引擎与应用打包,也可以将 AOT 库与应用一起发布并在目标设备上运行 NVIDIA GPU 上。
此集合由专有模型和 OSS 模型组成,包括 SD2.1、SD3、SDXL、FLUX、ResNet、Mobilenet、DenseNet、Bert、Llama、Phi、VGG、T5、Inception、EfficientNet 等。对于任何给定网络,AOT 阶段只需运行一次。
JIT 编译阶段
在 JIT 编译阶段,中间引擎将转换为针对目标 GPU 优化的最终可执行引擎。它利用 NVIDIA CUDA 编程模型的全部功能,更大限度地提高了 GPU 架构的性能。JIT 过程通常在几秒钟内完成,编译的核函数会缓存在设备上,以进行近乎即时的后续调用。与 AOT 阶段一样,JIT 库保持在 100 MB 以下的轻量级,确保高效的资源利用。

针对 PC AI 用例优化开发者工作流
除了使用较小的库占用空间更快地构建高性能引擎外,TensorRT for RTX 还提供独特的功能,以改善最终用户在 Windows 应用中的 AI 体验。
就扩散模型而言,适用于 RTX 的 TensorRT 可以处理具有无限 WxH 形状维度的文本转图像工作负载。流程的 JIT 阶段可以自动处理最终用户请求的任何形状,而不是强制应用开发者在优化配置文件中提前定义固定的形状范围。
“这是因为 JIT 库为任何动态形状提供了默认的内核实现,尽管性能较低。与任何图像生成应用一样,用户可能希望构建更多图像,直到对质量和语义准确性感到满意为止。与此同时,当用户不断重新生成更多图像时,JIT 运行时会根据用户所需的特定形状尺寸快速调整,并开始在后台生成高性能内核。因此,inference 性能在经过一到两次迭代后可提升高达 15%,因为高性能内核会自动替换后台的默认内核。
TensorRT for RTX 还为开发者提供可配置的运行时内核缓存,以便在同一应用中跨多个模型共享。该缓存可加快不同模型之间类似工作负载的内核生成速度。它还支持在后续应用启动时近乎即时地生成内核。开发者可以选择在磁盘上保存缓存的位置,以及在应用或库更新期间如何管理缓存。
“适用于 RTX 的 TensorRT 支持 FP32、FP16、BF16、FP8、INT8、FP4 和 INT4 等各种精度,因此适合不同的用例。所有 NVIDIA RTX GPU 均支持量化 INT8,NVIDIA Ampere GPU 及更新版本支持 FP8,NVIDIA Blackwell GPU 支持 FP4。INT4 优化通过仅权重量化实现。所有量化技术均可轻松用于 TensorRT Model Optimizer 。TensorRT for RTX 库提供了在 NVIDIA RTX GPU 上实现新型数据类型产品化的最快途径,以便供应商无关的框架能够跟上这一趋势。这些工具可优化新一代模型,使其适合 RTX GPU。”
它还可以与 graphics 等其他资源密集型工作负载同时运行。
总结
我们很高兴在 Microsoft Build 上宣布推出适用于 RTX 的 TensorRT,作为 NVIDIA RTX GPU 的专用推理部署解决方案,并支持 Windows ML。该库的精简大小为 200 MB,与目前可用的热门解决方案相比,它缩短了构建时间,并将运行时性能提高了 50% 以上,从而开创了一个简化易用性、扩展可移植性和更高性能的新时代。它可作为执行提供程序或直接作为独立库,用于加速 PC 应用中的 CNN、扩散、音频和 Transformer 模型。
它可作为执行提供程序或直接作为独立库,用于加速 PC 应用中的 CNN、扩散、音频和 Transformer 模型。虽然 Windows ML 路径允许开发者通过标准化 API 自动访问 NVIDIA 特定的加速,但需要额外控制的开发者可以直接集成该库。
Microsoft Windows ML 将提供支持 TensorRT for RTX EP 的 Windows ML 预览版。TensorRT for RTX SDK 也将于 6 月在 developer.nvidia.com 上正式开放下载。
参加 Microsoft Build 的开发者还可以在 5 月 20 日 (星期二) 上午 11:45 (PDT) 或 5 月 21 日 (星期三) 上午 10:45 (PDT) 观看我们的会议: Supercharge AI on RTX AI PCs with TensorRT BYOD 。





