
# Lab 1实验报告
# 一、问题概述

# 二、数据生成

一个规模为20的训练集如图所示:

此外,为了保证结果可重复,以下未特殊说明的部分,均取测试集大小为20,随机数种子为0。
# 三、问题求解
## 3.1 无正则项解析解

取训练集规模为20,依次取多项式的阶数为0到8,结果如下图所示:









可以看到在阶数为5之前,拟合的效果随着阶数的增大而逐渐改善,但之后拟合的效果逐渐变差,拟合曲线和正弦曲线开始发生偏离,表明发生了过拟合的现象。
取多项式的阶数为8,依次取训练集的规模为20、60、100,结果如下图所示:



可以看到随着训练集规模的增大,过拟合的现象有所改善。
## 3.2 有正则项解析解

取训练集规模为20,多项式阶数为10,比较引入正则项前后的拟合效果如图所示:


可以看到,拟合效果有一定改善。
## 3.3 梯度下降法
(代码见process. gradient_descent)
在上述解析解直接求解的过程中,由于需要进行矩阵求逆的运算,所以在训练集或多项式阶数较大时,可能会有运算效率低下的问题。
我们知道,函数上任意一点的梯度指向函数下降最快的方向,而我们原本的目标,就是求损失函数的最小值。
因此我们可以先随机生成一个作为起点,每次沿着梯度的方向前进一定的距离,并更新,如此反复,直到函数的梯度小于一定的阈值,即已经位于最小值附近。
我们每次前进的距离为,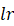称为学习率。
取训练集规模为20,依次取多项式的阶数为0到5,学习率为0.0001,梯度阈值为0.0001,结果如下图所示:



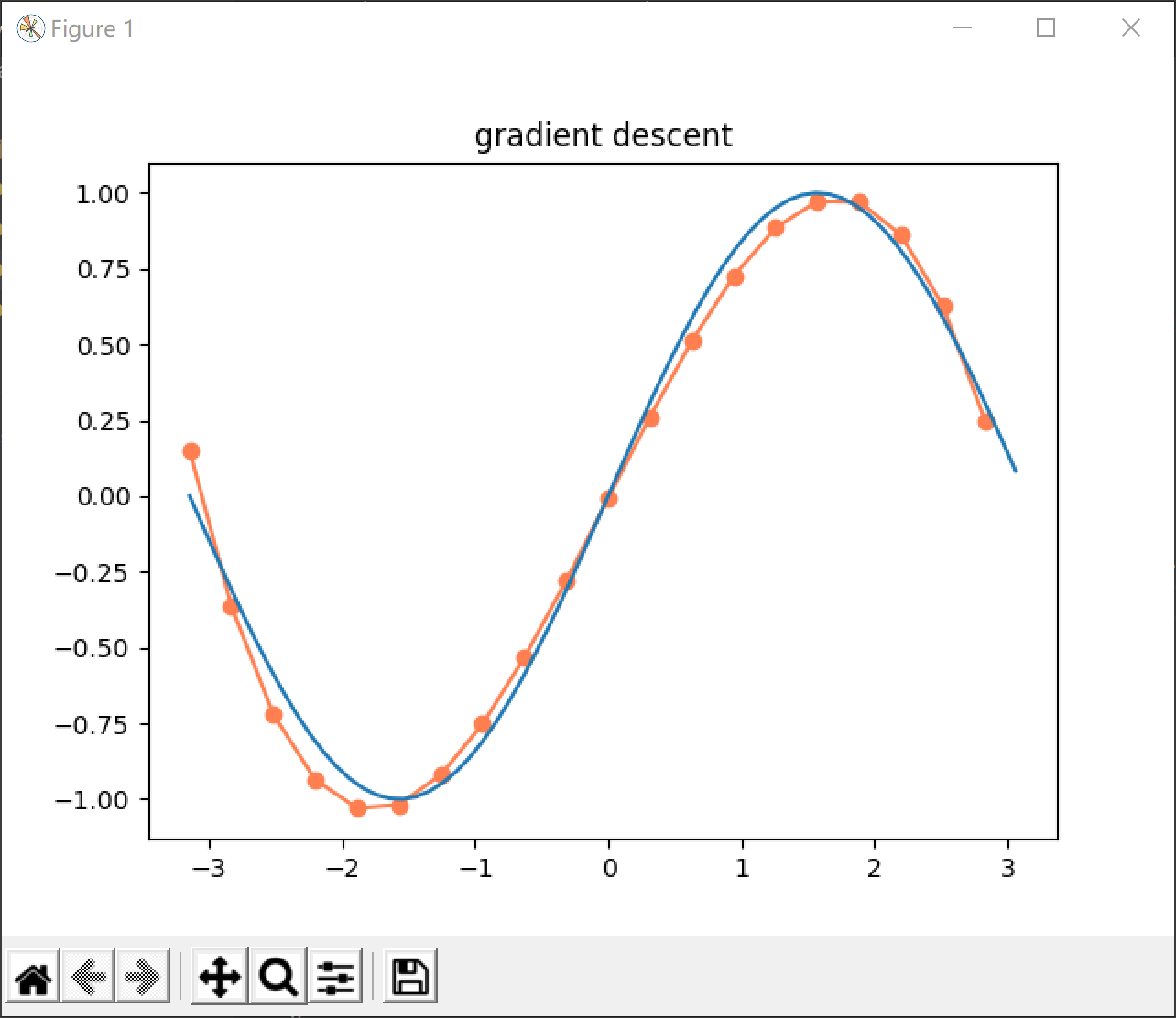


可以发现,梯度下降得到的结果和通过解析式直接求解得到的结果基本是一致的。
但是由于该方法每一步都是沿着这一点的梯度走,实际上是贪心的思想,所以会有陷入局部最优解的风险。
此外,由于迭代的次数并没有保证,所以在阶数较大时,很有可能出现计算效率低下的问题。
各阶数对应迭代次数如下表所示:
| 阶数 |0 |1 |2 |3 |4 |5 |
|----|----|----|----|----|----|----|
| 迭代次数 |31 |345 |7265 |81760 |115462 |178654 |
## 3.4 共轭梯度法
(代码见process. conjugate_gradient)
由于在梯度下降法中,为了达到目标精度,可能需要大量的迭代次数,所以在效率上依然存在较大的问题。
而共轭梯度法每次沿着全局下降最快的一个方向前进,所以理论上只需要迭代步就能走到最优解,其中为多项式的阶数。
取训练集规模为20,依次取多项式的阶数为0到5,结果如下图所示:






可以看到结果与前述方法基本一致,且计算速度极快,是一种特别优秀的方法。
 100011014-基于Python实现多项式拟合曲线.zip (9个子文件)
100011014-基于Python实现多项式拟合曲线.zip (9个子文件)  polynomial-fitting-curve
polynomial-fitting-curve  report.pdf 675KB src
report.pdf 675KB src  main.py 1KB process.py 3KB data.py 2KB config.py 1KB LICENSE 1KB
main.py 1KB process.py 3KB data.py 2KB config.py 1KB LICENSE 1KB 多项式拟合正弦曲线 .docx 12KB report.docx 1.18MB README.md 7KB
多项式拟合正弦曲线 .docx 12KB report.docx 1.18MB README.md 7KB资源评论

 Belugalalala2023-06-27总算找到了想要的资源,搞定遇到的大问题,赞赞赞!
Belugalalala2023-06-27总算找到了想要的资源,搞定遇到的大问题,赞赞赞!

神仙别闹
- 粉丝: 5970









最新资源
- (源码)基于JSP和Servlet的网上书城.zip
- 基于PLC水果清洗打蜡分级包装控制系统.doc
- 2023年自考网络经济与企业管理试题及重点资料.doc
- 从互联网到物联网.ppt
- 企业文化手册(网络).docx
- 工程项目管理的方法及应用.docx
- 网络公司工作总结.pptx
- 软件工程图书管理系统报告.docx
- 某重工集团研发项目管理培训教材.pptx
- 通信管理机技术手册.doc
- 联想乐PAD桌面虚拟化方案概述.doc
- 敏捷项目管理培训学习心得体会.docx
- 网络课程的设计与开发.doc
- (源码)基于Arduino的DIY智能手环.zip
- 樊昌信通信原理第六版课后思考题答案.doc
- 数据库的设计和管理规范.doc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


