




原文:
annas-archive.org/md5/a4f348a4e11e27ea41410c793e63daff译者:飞龙
第五章 数据挖掘——大海捞针
在本章中,我们将覆盖以下主题:
-
使用距离度量
-
学习和使用核方法
-
使用 k-means 方法进行数据聚类
-
学习向量量化
-
在单变量数据中寻找异常值
-
使用局部异常因子方法发现异常值
介绍
本章我们将主要关注无监督数据挖掘算法。我们将从涵盖各种距离度量的食谱开始。理解距离度量和不同的空间在构建数据科学应用程序时至关重要。任何数据集通常都是一组属于特定空间的对象。我们可以将空间定义为从中抽取数据集中的点的点集。最常见的空间是欧几里得空间。在欧几里得空间中,点是实数向量。向量的长度表示维度的数量。
接下来,我们将介绍一个食谱,介绍核方法。核方法是机器学习中一个非常重要的主题。它们帮助我们通过线性方法解决非线性数据问题。我们将介绍核技巧的概念。
接下来,我们将介绍一些聚类算法的食谱。聚类是将一组点划分为逻辑组的过程。例如,在超市场景中,商品按类别进行定性分组。然而,我们将关注定量方法。具体来说,我们将把注意力集中在 k-means 算法上,并讨论它的局限性和优点。
我们的下一个食谱是一种无监督技术,称为学习向量量化。它既可以用于聚类任务,也可以用于分类任务。
最后,我们将讨论异常值检测方法。异常值是数据集中与其他观测值有显著差异的观测值。研究这些异常值非常重要,因为它们可能是反映异常现象或数据生成过程中存在错误的信号。在机器学习模型应用于数据之前,了解如何处理异常值对于算法非常关键。本章将重点介绍几种经验性的异常值检测技术。
在本章中,我们将重点依赖 Python 库,如 NumPy、SciPy、matplotlib 和 scikit-learn 来编写大部分食谱。我们还将从脚本编写转变为在本章中编写过程和类的风格。
使用距离度量
距离和相似度度量是各种数据挖掘任务的关键。在本食谱中,我们将看到一些距离度量的应用。我们的下一个食谱将涉及相似度度量。在查看各种距离度量之前,让我们先定义一个距离度量。
作为数据科学家,我们总是会遇到不同维度的点或向量。从数学角度来看,一组点被定义为一个空间。在这个空间中,距离度量被定义为一个函数 d(x,y),它以空间中的两个点 x 和 y 作为参数,并输出一个实数。这个距离函数,即实数输出,应该满足以下公理:
-
距离函数的输出应该是非负的,d(x,y) >= 0
-
距离函数的输出只有在 x = y 时才为零
-
距离应该是对称的,也就是说,d(x,y) = d(y,x)
-
距离应该遵循三角不等式,也就是说,d(x,y) <= d(x,z) + d(z,y)
仔细查看第四个公理可以发现,距离是两点之间最短路径的长度。
你可以参考以下链接获取有关公理的更多信息:
en.wikipedia.org/wiki/Metric_%28mathematics%29
准备开始
我们将研究欧几里得空间和非欧几里得空间中的距离度量。我们将从欧几里得距离开始,然后定义 Lr-norm 距离。Lr-norm 是一个距离度量家族,欧几里得距离是其中的一个成员。接着,我们会讨论余弦距离。在非欧几里得空间中,我们将研究 Jaccard 距离和汉明距离。
如何实现…
让我们从定义函数开始,以计算不同的距离度量:
import numpy as np
def euclidean_distance(x,y):
if len(x) == len(y):
return np.sqrt(np.sum(np.power((x-y),2)))
else:
print "Input should be of equal length"
return None
def lrNorm_distance(x,y,power):
if len(x) == len(y):
return np.power(np.sum (np.power((x-y),power)),(1/(1.0*power)))
else:
print "Input should be of equal length"
return None
def cosine_distance(x,y):
if len(x) == len(y):
return np.dot(x,y) / np.sqrt(np.dot(x,x) * np.dot(y,y))
else:
print "Input should be of equal length"
return None
def jaccard_distance(x,y):
set_x = set(x)
set_y = set(y)
return 1 - len(set_x.intersection(set_y)) / len(set_x.union(set_y))
def hamming_distance(x,y):
diff = 0
if len(x) == len(y):
for char1,char2 in zip(x,y):
if char1 != char2:
diff+=1
return diff
else:
print "Input should be of equal length"
return None
现在,让我们编写一个主程序来调用这些不同的距离度量函数:
if __name__ == "__main__":
# Sample data, 2 vectors of dimension 3
x = np.asarray([1,2,3])
y = np.asarray([1,2,3])
# print euclidean distance
print euclidean_distance(x,y)
# Print euclidean by invoking lr norm with
# r value of 2
print lrNorm_distance(x,y,2)
# Manhattan or citi block Distance
print lrNorm_distance(x,y,1)
# Sample data for cosine distance
x =[1,1]
y =[1,0]
print 'cosine distance'
print cosine_distance(x,y)
# Sample data for jaccard distance
x = [1,2,3]
y = [1,2,3]
print jaccard_distance(x,y)
# Sample data for hamming distance
x =[11001]
y =[11011]
print hamming_distance(x,y)
它是如何工作的…
让我们来看看主函数。我们创建了一个示例数据集和两个三维向量,并调用了euclidean_distance函数。
这是一种最常用的距离度量,即欧几里得距离。它属于 Lr-Norm 距离的家族。如果空间中的点是由实数构成的向量,那么该空间被称为欧几里得空间。它也被称为 L2 范数距离。欧几里得距离的公式如下:
如你所见,欧几里得距离是通过在每个维度上计算距离(减去对应的维度),将距离平方,最后取平方根来推导出来的。
在我们的代码中,我们利用了 NumPy 的平方根和幂函数来实现前述公式:
np.sqrt(np.sum(np.power((x-y),2)))
欧几里得距离是严格正的。当 x 等于 y 时,距离为零。通过我们如何调用欧几里得距离,可以清楚地看到这一点:
x = np.asarray([1,2,3])
y = np.asarray([1,2,3])
print euclidean_distance(x,y)
如你所见,我们定义了两个 NumPy 数组,x和y。我们保持它们相同。现在,当我们用这些参数调用euclidean_distance函数时,输出是零。
现在,让我们调用 L2 范数函数,lrNorm_distance。
Lr-Norm 距离度量是距离度量家族中的一个成员,欧几里得距离属于该家族。我们可以通过它的公式来更清楚地理解这一点:
你可以看到,我们现在有了一个参数r。让我们将r替换为 2,这样会将前面的方程转化为欧几里得方程。因此,欧几里得距离也称为 L2 范数距离:
lrNorm_distance(x,y,power):
除了两个向量外,我们还将传入一个名为power的第三个参数。这就是公式中定义的r。将其调用并设置power值为 2 时,将得到欧几里得距离。你可以通过运行以下代码来验证:
print lrNorm_distance(x,y,2)
这将得到零作为结果,这类似于欧几里得距离函数。
让我们定义两个示例向量,x和y,并调用cosine_distance函数。
在将点视为方向的空间中,余弦距离表示给定输入向量之间角度的余弦值作为距离值。欧几里得空间以及点为整数或布尔值的空间,是余弦距离函数可以应用的候选空间。输入向量之间的角度余弦值是输入向量的点积与各自 L2 范数的乘积之比:
np.dot(x,y) / np.sqrt(np.dot(x,x) * np.dot(y,y))
让我们看一下分子,其中计算了输入向量之间的点积:
np.dot(x,y)
我们将使用 NumPy 的点积函数来获取点积值。x和y这两个向量的点积定义如下:
现在,让我们看一下分母:
np.sqrt(np.dot(x,x) * np.dot(y,y))
我们再次使用点积函数来计算输入向量的 L2 范数:
np.dot(x,x) is equivalent to
tot = 0
for i in range(len(x)):
tot+=x[i] * x[i]
因此,我们可以计算两个输入向量之间角度的余弦值。
接下来,我们将讨论 Jaccard 距离。与之前的调用类似,我们将定义示例向量并调用jaccard_distance函数。
从实数值的向量开始,让我们进入集合。通常称为 Jaccard 系数,它是给定输入向量交集与并集大小的比率。减去这个值等于 Jaccard 距离。如你所见,在实现中,我们首先将输入列表转换为集合。这样我们就可以利用 Python 集合数据类型提供的并集和交集操作:
set_x = set(x)
set_y = set(y)
最后,距离计算如下:
1 - len(set_x.intersection(set_y)) / (1.0 * len(set_x.union(set_y)))
我们必须使用set数据类型中可用的交集和并集功能来计算距离。
我们的最后一个距离度量是汉明距离。对于两个比特向量,汉明距离计算这两个向量中有多少个比特不同:
for char1,char2 in zip(x,y):
if char1 != char2:
diff+=1
return diff
如你所见,我们使用了zip功能来检查每个比特,并维护一个计数器,统计有多少个比特不同。汉明距离用于分类变量。
还有更多……
记住,通过从我们的距离值中减去 1,我们可以得到一个相似度值。
还有一种我们没有详细探讨的距离,但它被广泛使用,那就是曼哈顿距离或城市块距离。这是一种 L1 范数距离。通过将 r 值设置为 1 传递给 Lr 范数距离函数,我们将得到曼哈顿距离。
根据数据所处的底层空间,需要选择合适的距离度量。在算法中使用这些距离时,我们需要注意底层空间的情况。例如,在 k 均值算法中,每一步都会计算所有相互接近点的平均值作为簇中心。欧几里得空间的一个优点是点的平均值存在且也是该空间中的一个点。请注意,我们的 Jaccard 距离输入是集合,集合的平均值是没有意义的。
在使用余弦距离时,我们需要检查底层空间是否为欧几里得空间。如果向量的元素是实数,则空间是欧几里得的;如果它们是整数,则空间是非欧几里得的。余弦距离在文本挖掘中最为常见。在文本挖掘中,单词被视为坐标轴,文档是这个空间中的一个向量。两个文档向量之间夹角的余弦值表示这两个文档的相似度。
SciPy 实现了所有这些列出的距离度量及更多内容:
docs.scipy.org/doc/scipy/reference/spatial.distance.html。
上面的 URL 列出了 SciPy 支持的所有距离度量。
此外,scikit-learn 的pairwise子模块提供了一个叫做pairwise_distance的方法,可以用来计算输入记录之间的距离矩阵。你可以在以下位置找到:
scikitlearn.org/stable/modules/generated/sklearn.metrics.pairwise.pairwise_distances.html。
我们曾提到过汉明距离是用于分类变量的。这里需要提到的是,通常用于分类变量的一种编码方式是独热编码。在进行独热编码后,汉明距离可以作为输入向量之间的相似度/距离度量。
另见
- 使用随机投影减少数据维度,见第四章,数据分析 - 深入探索
学习和使用核方法
在本食谱中,我们将学习如何使用核方法进行数据处理。掌握核方法可以帮助你解决非线性问题。本食谱是核方法的入门介绍。
通常,线性模型——可以使用直线或超平面分离数据的模型——易于解释和理解。数据中的非线性使得我们无法有效使用线性模型。如果数据能够被转换到一个关系变为线性的空间中,我们就可以使用线性模型。然而,在变换后的空间中进行数学计算可能变成一个昂贵的操作。这就是核函数发挥作用的地方。
核函数是相似度函数。它接收两个输入参数,这两个输入之间的相似度就是核函数的输出。在这个示例中,我们将探讨核函数如何实现这种相似性。我们还将讨论所谓的“核技巧”。
正式定义一个核函数 K 是一个相似度函数:K(x1,x2) > 0 表示 x1 和 x2 之间的相似度。
准备就绪
在查看各种核函数之前,我们先来数学上定义一下:
这里,xi 和 xj 是输入向量:
上述映射函数用于将输入向量转化为一个新的空间。例如,如果输入向量位于一个 n 维空间中,变换函数将其转换为一个维度为 m 的新空间,其中 m >> n:
https://github.com/OpenDocCN/freelearn-ds-pt5-zh/raw/master/docs/py-ds-cb/img/B04041_05_09.jpghttps://github.com/OpenDocCN/freelearn-ds-pt5-zh/raw/master/docs/py-ds-cb/img/B04041_05_10.jpg
上图表示的是点积:
上图是点积,xi 和 xj 现在通过映射函数被转换到一个新的空间中。
在这个示例中,我们将看到一个简单的核函数在实际中的应用。
我们的映射函数如下所示:
当原始数据被输入到这个映射函数时,它将输入转化为新的空间。
如何做到这一点…
让我们创建两个输入向量,并按照前面章节中描述的方式定义映射函数:
import numpy as np
# Simple example to illustrate Kernel Function concept.
# 3 Dimensional input space
x = np.array([10,20,30])
y = np.array([8,9,10])
# Let us find a mapping function to transform this space
# phi(x1,x2,x3) = (x1x2,x1x3,x2x3,x1x1,x2x2,x3x3)
# this will transorm the input space into 6 dimesions
def mapping_function(x):
output_list =[]
for i in range(len(x)):
output_list.append(x[i]*x[i])
output_list.append(x[0]*x[1])
output_list.append(x[0]*x[2])
output_list.append(x[1]*x[0])
output_list.append(x[1]*x[2])
output_list.append(x[2]*x[1])
output_list.append(x[2]*x[0])
return np.array(output_list)
现在,让我们看看主程序如何调用核变换。在主函数中,我们将定义一个核函数并将输入变量传递给它,然后打印输出:
if __name_ == "__main__"
# Apply the mapping function
tranf_x = mapping_function(x)
tranf_y = mapping_function(y)
# Print the output
print tranf_x
print np.dot(tranf_x,tranf_y)
# Print the equivalent kernel functions
# transformation output.
output = np.power((np.dot(x,y)),2)
print output
它是如何工作的…
让我们从主函数开始跟踪这个程序。我们创建了两个输入向量,x 和 y。这两个向量都是三维的。
然后我们定义了一个映射函数。这个映射函数利用输入向量的值,将输入向量转化为一个维度增加的新空间。在这个例子中,维度的数量从三维增加到九维。
现在,让我们对这些向量应用一个映射函数,将它们的维度增加到九维。
如果我们打印 tranf_x,我们将得到如下结果:
[100 400 900 200 300 200 600 600 300]
如你所见,我们将输入向量 x 从三维空间转化为一个九维向量。
现在,让我们在变换后的空间中计算点积并打印输出。
输出为 313600,一个标量值。
现在让我们回顾一下:我们首先将两个输入向量转换到更高维的空间,然后计算点积以得到标量输出。
我们所做的是一个非常昂贵的操作,将原始的三维向量转换为九维向量,然后在其上执行点积操作。
相反,我们可以选择一个内核函数,它能够在不显式地将原始空间转换为新空间的情况下得到相同的标量输出。
我们的新内核定义如下:
对于两个输入,x 和 y,该内核计算向量的点积,并对它们进行平方。
在打印内核的输出后,我们得到了 313600。
我们从未进行过转换,但仍然能够得到与转换空间中点积输出相同的结果。这就是所谓的内核技巧。
选择这个内核并没有什么魔力。通过扩展内核,我们可以得到我们的映射函数。有关扩展的详细信息,请参考以下文献:
en.wikipedia.org/wiki/Polynomial_kernel。
还有更多…
有多种类型的内核。根据我们的数据特性和算法需求,我们需要选择合适的内核。以下是其中的一些:
线性内核:这是最简单的内核函数。对于两个给定的输入,它返回输入的点积:
多项式内核:它的定义如下:
在这里,x 和 y 是输入向量,d 是多项式的次数,c 是常数。在我们的配方中,我们使用了次数为 2 的多项式内核。
以下是线性和多项式内核的 scikit 实现:
另见
-
使用内核 PCA 配方见第四章,数据分析 – 深入分析
-
通过随机投影减少数据维度 配方见第四章,数据分析 – 深入分析
使用 k-means 方法进行数据聚类
在本节中,我们将讨论 k-means 算法。K-means 是一种寻求中心的无监督算法。它是一种迭代的非确定性方法。所谓迭代是指算法步骤会重复,直到达到指定步数的收敛。非确定性意味着不同的起始值可能导致不同的最终聚类结果。该算法需要输入聚类的数量k。选择k值没有固定的方法,它必须通过多次运行算法来确定。
对于任何聚类算法,其输出的质量由聚类间的凝聚度和聚类内的分离度来决定。同一聚类中的点应彼此靠近;不同聚类中的点应相互远离。
准备就绪
在我们深入了解如何用 Python 编写 k-means 算法之前,有两个关键概念需要讨论,它们将帮助我们更好地理解算法输出的质量。第一个是与聚类质量相关的定义,第二个是用于衡量聚类质量的度量标准。
每个由 k-means 检测到的聚类都可以通过以下度量进行评估:
-
聚类位置:这是聚类中心的坐标。K-means 算法从一些随机点作为聚类中心开始,并通过迭代不断找到新的中心,使得相似的点被聚集到一起。
-
聚类半径:这是所有点与聚类中心的平均偏差。
-
聚类质量:这是聚类中点的数量。
-
聚类密度:这是聚类质量与其半径的比值。
现在,我们将衡量输出聚类的质量。如前所述,这是一个无监督问题,我们没有标签来验证输出,因此无法计算诸如精确度、召回率、准确度、F1 分数或其他类似的度量指标。我们将为 k-means 算法使用的度量标准称为轮廓系数。它的取值范围是-1 到 1。负值表示聚类半径大于聚类之间的距离,从而导致聚类重叠,这表明聚类效果较差。较大的值,即接近 1 的值,表示聚类效果良好。
轮廓系数是为聚类中每个点定义的。对于一个聚类 C 和聚类中的一个点i,令xi为该点与聚类中所有其他点的平均距离。
现在,计算点i与另一个聚类 D 中所有点的平均距离,记为 D。选择这些值中的最小值,称为yi:
对于每个簇,所有点的轮廓系数的平均值可以作为簇质量的良好度量。所有数据点的轮廓系数的平均值可以作为整体簇质量的度量。
让我们继续生成一些随机数据:
import numpy as np
import matplotlib.pyplot as plt
def get_random_data():
x_1 = np.random.normal(loc=0.2,scale=0.2,size=(100,100))
x_2 = np.random.normal(loc=0.9,scale=0.1,size=(100,100))
x = np.r_[x_1,x_2]
return x
我们从正态分布中采样了两组数据。第一组数据的均值为0.2,标准差为0.2。第二组数据的均值为0.9,标准差为0.1。每个数据集的大小为 100 * 100——我们有100个实例和100个维度。最后,我们使用 NumPy 的行堆叠函数将它们合并。我们的最终数据集大小为 200 * 100。
让我们绘制数据的散点图:
x = get_random_data()
plt.cla()
plt.figure(1)
plt.title("Generated Data")
plt.scatter(x[:,0],x[:,1])
plt.show()
绘图如下:
虽然我们只绘制了第一维和第二维,但你仍然可以清楚地看到我们有两个簇。现在,让我们开始编写我们的 k-means 聚类算法。
如何实现…
让我们定义一个函数,可以对给定的数据和参数k执行 k-means 聚类。该函数对给定数据进行聚类,并返回整体的轮廓系数。
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
def form_clusters(x,k):
"""
Build clusters
"""
# k = required number of clusters
no_clusters = k
model = KMeans(n_clusters=no_clusters,init='random')
model.fit(x)
labels = model.labels_
print labels
# Cacluate the silhouette score
sh_score = silhouette_score(x,labels)
return sh_score
让我们调用上述函数,针对不同的k值,并存储返回的轮廓系数:
sh_scores = []
for i in range(1,5):
sh_score = form_clusters(x,i+1)
sh_scores.append(sh_score)
no_clusters = [i+1 for i in range(1,5)]
最后,让我们绘制不同k值的轮廓系数。
no_clusters = [i+1 for i in range(1,5)]
plt.figure(2)
plt.plot(no_clusters,sh_scores)
plt.title("Cluster Quality")
plt.xlabel("No of clusters k")
plt.ylabel("Silhouette Coefficient")
plt.show()
如何运作…
如前所述,k-means 是一个迭代算法。大致来说,k-means 的步骤如下:
-
从数据集中初始化
k个随机点作为初始中心点。 -
按照以下步骤进行,直到指定次数的迭代收敛:
-
将点分配给距离最近的簇中心。通常使用欧几里得距离来计算点与簇中心之间的距离。
-
根据本次迭代中的分配重新计算新的簇中心。
-
如果点的簇分配与上一次迭代相同,则退出循环。算法已收敛到最优解。
-
-
我们将使用来自 scikit-learn 库的 k-means 实现。我们的聚类函数接受 k 值和数据集作为参数,并运行 k-means 算法:
model = KMeans(n_clusters=no_clusters,init='random') model.fit(x)
no_clusters是我们将传递给函数的参数。使用 init 参数时,我们将初始中心点设置为随机值。当 init 设置为 random 时,scikit-learn 会根据数据估算均值和方差,然后从高斯分布中采样 k 个中心。
最后,我们必须调用 fit 方法,在我们的数据集上运行 k-means 算法:
labels = model.labels_
sh_score = silhouette_score(x,labels)
return sh_score
我们获取标签,即每个点的簇分配,并计算出簇中所有点的轮廓系数。
在实际场景中,当我们在数据集上启动 k-means 算法时,我们并不知道数据中存在的集群数量;换句话说,我们不知道 k 的理想值。然而,在我们的示例中,我们知道 k=2,因为我们生成的数据已经适配了两个集群。因此,我们需要针对不同的 k 值运行 k-means:
sh_scores = []
for i in range(1,5):
sh_score = form_clusters(x,i+1)
sh_scores.append(sh_score)
对于每次运行,也就是每个 k 值,我们都会存储轮廓系数。k 与轮廓系数的图表可以揭示数据集的理想 k 值:
no_clusters = [i+1 for i in range(1,5)]
plt.figure(2)
plt.plot(no_clusters,sh_scores)
plt.title("Cluster Quality")
plt.xlabel("No of clusters k")
plt.ylabel("Silhouette Coefficient")
plt.show()
正如预期的那样,k=2 时,我们的轮廓系数非常高。
还有更多…
关于 k-means 需要注意的几点:k-means 算法不能用于类别数据,对于类别数据需要使用 k-medoids。k-medoids 不是通过平均所有点来寻找集群中心,而是选择一个点,使其与该集群中所有其他点的平均距离最小。
在分配初始集群时需要小心。如果数据非常密集且集群之间距离非常远,且初始随机中心选择在同一个集群中,那么 k-means 可能表现不佳。
通常情况下,k-means 算法适用于具有星形凸集群的数据。有关星形凸数据点的更多信息,请参考以下链接:
mathworld.wolfram.com/StarConvex.html
如果数据中存在嵌套集群或其他复杂集群,k-means 的结果可能会是无意义的输出。
数据中异常值的存在可能导致较差的结果。一种好的做法是在运行 k-means 之前,进行彻底的数据探索,以便了解数据特征。
一种在算法开始时初始化中心的替代方法是 k-means++方法。因此,除了将 init 参数设置为随机值外,我们还可以使用 k-means++来设置它。有关 k-means++的更多信息,请参考以下论文:
k-means++:小心初始化的优势。ACM-SIAM 研讨会关于离散算法。2007 年
另见
- 在第五章中的距离度量工作法配方,数据挖掘 - 在大海捞针
使用局部离群因子方法发现异常值
局部离群因子(LOF)是一种异常值检测算法,它通过比较数据实例与其邻居的局部密度来检测异常值。其目的是决定数据实例是否属于相似密度的区域。它可以在数据集群数量未知且集群具有不同密度和大小的情况下,检测出数据集中的异常值。它受 KNN(K-最近邻)算法的启发,并被广泛使用。
准备工作
在前一个配方中,我们研究了单变量数据。在这个配方中,我们将使用多变量数据并尝试找出异常值。让我们使用一个非常小的数据集来理解 LOF 算法进行异常值检测。
我们将创建一个 5 X 2 的矩阵,查看数据后我们知道最后一个元组是异常值。我们也可以将其绘制为散点图:
from collections import defaultdict
import numpy as np
instances = np.matrix([[0,0],[0,1],[1,1],[1,0],[5,0]])
import numpy as np
import matplotlib.pyplot as plt
x = np.squeeze(np.asarray(instances[:,0]))
y = np.squeeze(np.asarray(instances[:,1]))
plt.cla()
plt.figure(1)
plt.scatter(x,y)
plt.show()
绘图结果如下:
LOF 通过计算每个点的局部密度来工作。根据点的 k 近邻的距离,估算该点的局部密度。通过将点的局部密度与其邻居的密度进行比较,检测出异常值。与邻居相比,异常值的密度较低。
为了理解 LOF,我们需要了解一些术语定义:
-
对象 P 的 k 距离是对象 P 与其第 k 近邻之间的距离。K 是算法的一个参数。
-
P 的 k 距离邻域是所有距离 P 的距离小于或等于 P 与其第 k 近邻之间距离的对象 Q 的列表。
-
从 P 到 Q 的可达距离定义为 P 与其第 k 近邻之间的距离与 P 到 Q 之间的距离中的最大值。以下符号可能有助于澄清这一点:
Reachability distance (P ß Q) = > maximum(K-Distance(P), Distance(P,Q)) -
P 的局部可达密度(LRD§)是 P 的 k 距离邻域与 P 及其邻居的可达距离之和的比值。
-
P 的局部异常因子(LOF§)是 P 的局部可达密度与 P 的 k 近邻局部可达密度的比值的平均值。
如何实现……
-
让我们计算点之间的
pairwise距离:k = 2 distance = 'manhattan' from sklearn.metrics import pairwise_distances dist = pairwise_distances(instances,metric=distance) -
让我们计算 k 距离。我们将使用
heapq来获取 k 近邻:# Calculate K distance import heapq k_distance = defaultdict(tuple) # For each data point for i in range(instances.shape[0]): # Get its distance to all the other points. # Convert array into list for convienience distances = dist[i].tolist() # Get the K nearest neighbours ksmallest = heapq.nsmallest(k+1,distances)[1:][k-1] # Get their indices ksmallest_idx = distances.index(ksmallest) # For each data point store the K th nearest neighbour and its distance k_distance[i]=(ksmallest,ksmallest_idx) -
计算 k 距离邻域:
def all_indices(value, inlist): out_indices = [] idx = -1 while True: try: idx = inlist.index(value, idx+1) out_indices.append(idx) except ValueError: break return out_indices # Calculate K distance neighbourhood import heapq k_distance_neig = defaultdict(list) # For each data point for i in range(instances.shape[0]): # Get the points distances to its neighbours distances = dist[i].tolist() print "k distance neighbourhood",i print distances # Get the 1 to K nearest neighbours ksmallest = heapq.nsmallest(k+1,distances)[1:] print ksmallest ksmallest_set = set(ksmallest) print ksmallest_set ksmallest_idx = [] # Get the indices of the K smallest elements for x in ksmallest_set: ksmallest_idx.append(all_indices(x,distances)) # Change a list of list to list ksmallest_idx = [item for sublist in ksmallest_idx for item in sublist] # For each data pont store the K distance neighbourhood k_distance_neig[i].extend(zip(ksmallest,ksmallest_idx)) -
然后,计算可达距离和 LRD:
#Local reachable density local_reach_density = defaultdict(float) for i in range(instances.shape[0]): # LRDs numerator, number of K distance neighbourhood no_neighbours = len(k_distance_neig[i]) denom_sum = 0 # Reachability distance sum for neigh in k_distance_neig[i]: # maximum(K-Distance(P), Distance(P,Q)) denom_sum+=max(k_distance[neigh[1]][0],neigh[0]) local_reach_density[i] = no_neighbours/(1.0*denom_sum) -
计算 LOF:
lof_list =[] #Local Outlier Factor for i in range(instances.shape[0]): lrd_sum = 0 rdist_sum = 0 for neigh in k_distance_neig[i]: lrd_sum+=local_reach_density[neigh[1]] rdist_sum+=max(k_distance[neigh[1]][0],neigh[0]) lof_list.append((i,lrd_sum*rdist_sum))
它是如何工作的……
在步骤 1 中,我们选择曼哈顿距离作为距离度量,k 值为 2。我们正在查看数据点的第二近邻。
然后我们必须计算我们的元组之间的成对距离。成对相似性存储在 dist 矩阵中。正如你所看到的,dist 的形状如下:
>>> dist.shape
(5, 5)
>>>
它是一个 5 X 5 的矩阵,其中行和列是各个元组,单元格的值表示它们之间的距离。
在步骤 2 中,我们导入heapq:
import heapq
heapq是一种数据结构,也称为优先队列。它类似于常规队列,区别在于每个元素都有一个优先级,优先级高的元素会先于优先级低的元素被处理。
请参考维基百科链接获取有关优先队列的更多信息:
en.wikipedia.org/wiki/Priority_queue。
Python 的 heapq 文档可以在docs.python.org/2/library/heapq.html找到。
k_distance = defaultdict(tuple)
接下来,我们定义一个字典,其中键是元组 ID,值是元组与其第 k 近邻的距离。在我们的情况下,应该是第二近邻。
然后,我们进入一个 for 循环,以便为每个数据点找到第 k 近邻的距离:
distances = dist[i].tolist()
从我们的距离矩阵中,我们提取第 i 行。正如你所看到的,第 i 行捕获了对象i与所有其他对象之间的距离。记住,单元格值(i,i)表示与自身的距离。我们需要在下一步中忽略这一点。我们必须将数组转换为列表以方便操作。让我们通过一个例子来理解这一点。距离矩阵如下所示:
>>> dist
array([[ 0., 1., 2., 1., 5.],
[ 1., 0., 1., 2., 6.],
[ 2., 1., 0., 1., 5.],
[ 1., 2., 1., 0., 4.],
[ 5., 6., 5., 4., 0.]])
假设我们处于 for 循环的第一次迭代中,因此我们的i=0。(记住,Python 的索引是从0开始的)。
所以,现在我们的距离列表将如下所示:
[ 0., 1., 2., 1., 5.]
从中,我们需要第 k 近邻,即第二近邻,因为我们在程序开始时将 K 设置为2。
从中我们可以看到,索引 1 和索引 3 都可以作为我们的第 k 近邻,因为它们的值都是1。
现在,我们使用heapq.nsmallest函数。记住,我们之前提到过,heapq是一个普通队列,但每个元素都有一个优先级。在这种情况下,元素的值即为优先级。当我们说给我 n 个最小值时,heapq会返回最小的元素:
# Get the Kth nearest neighbours
ksmallest = heapq.nsmallest(k+1,distances)[1:][k-1]
让我们看一下heapq.nsmallest函数的作用:
>>> help(heapq.nsmallest)
Help on function nsmallest in module heapq:
nsmallest(n, iterable, key=None)
Find the n smallest elements in a dataset.
Equivalent to: sorted(iterable, key=key)[:n]
它返回给定数据集中的 n 个最小元素。在我们的例子中,我们需要第二近邻。此外,我们需要避免之前提到的(i,i)。因此,我们必须传递 n=3 给heapq.nsmallest。这确保它返回三个最小元素。然后,我们对列表进行子集操作,排除第一个元素(参见 nsmallest 函数调用后的[1:]),最终获取第二近邻(参见[1:]后的[k-1])。
我们还必须获取i的第二近邻的索引,并将其存储在字典中:
# Get their indices
ksmallest_idx = distances.index(ksmallest)
# For each data point store the K th nearest neighbour and its distance
k_distance[i]=(ksmallest,ksmallest_idx)
让我们打印出我们的字典:
print k_distance
defaultdict(<type 'tuple'>, {0: (1.0, 1), 1: (1.0, 0), 2: (1.0, 1), 3: (1.0, 0), 4: (5.0, 0)})
我们的元组有两个元素:距离和在距离数组中元素的索引。例如,对于0,第二近邻是索引为1的元素。
计算完所有数据点的 k 距离后,我们接下来找出 k 距离邻域。
在步骤 3 中,我们为每个数据点找到 k 距离邻域:
# Calculate K distance neighbourhood
import heapq
k_distance_neig = defaultdict(list)
与前一步类似,我们导入了 heapq 模块并声明了一个字典,用来保存我们的 k 距离邻域的详细信息。让我们回顾一下什么是 k 距离邻域:
P 的 k 距离邻域是所有与 P 的距离小于或等于 P 与其第 k 近邻之间距离的对象 Q 的列表:
distances = dist[i].tolist()
# Get the 1 to K nearest neighbours
ksmallest = heapq.nsmallest(k+1,distances)[1:]
ksmallest_set = set(ksmallest)
前两行应该对你很熟悉。我们在上一步已经做过了。看看第二行。在这里,我们再次调用了 n smallest,n=3(即 K+1),但我们选择了输出列表中的所有元素,除了第一个。(猜猜为什么?答案在前一步中)。
让我们通过打印值来查看其实际操作。像往常一样,在循环中,我们假设我们看到的是第一个数据点或元组,其中 i=0。
我们的距离列表如下所示:
[0.0, 1.0, 2.0, 1.0, 5.0]
我们的heapq.nsmallest函数返回如下:
[1.0, 1.0]
这些是 1 到 k 个最近邻的距离。我们需要找到它们的索引,简单的 list.index 函数只会返回第一个匹配项,因此我们将编写all_indices函数来检索所有索引:
def all_indices(value, inlist):
out_indices = []
idx = -1
while True:
try:
idx = inlist.index(value, idx+1)
out_indices.append(idx)
except ValueError:
break
return out_indices
通过值和列表,all_indices将返回值在列表中出现的所有索引。我们必须将 k 个最小值转换为集合:
ksmallest_set = set(ksmallest)
所以,[1.0,1.0]变成了一个集合([1.0])。现在,使用 for 循环,我们可以找到所有元素的索引:
# Get the indices of the K smallest elements
for x in ksmallest_set:
ksmallest_idx.append(all_indices(x,distances))
我们为 1.0 得到两个索引;它们是 1 和 2:
ksmallest_idx = [item for sublist in ksmallest_idx for item in sublist]
下一个 for 循环用于将列表中的列表转换为列表。all_indices函数返回一个列表,我们然后将此列表添加到ksmallest_idx列表中。因此,我们通过下一个 for 循环将其展开。
最后,我们将 k 个最小的邻域添加到我们的字典中:
k_distance_neig[i].extend(zip(ksmallest,ksmallest_idx))
然后我们添加元组,其中元组中的第一个项是距离,第二个项是最近邻的索引。让我们打印 k 距离邻域字典:
defaultdict(<type 'list'>, {0: [(1.0, 1), (1.0, 3)], 1: [(1.0, 0), (1.0, 2)], 2: [(1.0, 1), (1.0, 3)], 3: [(1.0, 0), (1.0, 2)], 4: [(4.0, 3), (5.0, 0)]})
在步骤 4 中,我们计算 LRD。LRD 是通过可达距离来计算的。让我们回顾一下这两个定义:
-
从 P 到 Q 的可达距离被定义为 P 与其第 k 个最近邻之间的距离和 P 与 Q 之间的距离的最大值。以下符号可能有助于澄清这一点:
Reachability distance (P ß Q) = > maximum(K-Distance(P), Distance(P,Q)) -
P 的局部可达密度(LRD§)是 P 的 k 距离邻域与 k 及其邻域的可达距离之和的比率:
#Local reachable density local_reach_density = defaultdict(float)
我们首先声明一个字典来存储 LRD:
for i in range(instances.shape[0]):
# LRDs numerator, number of K distance neighbourhood
no_neighbours = len(k_distance_neig[i])
denom_sum = 0
# Reachability distance sum
for neigh in k_distance_neig[i]:
# maximum(K-Distance(P), Distance(P,Q))
denom_sum+=max(k_distance[neigh[1]][0],neigh[0])
local_reach_density[i] = no_neighbours/(1.0*denom_sum)
对于每个点,我们将首先找到该点的 k 距离邻域。例如,对于 i = 0,分子将是 len(k_distance_neig[0]),即 2。
现在,在内部的 for 循环中,我们计算分母。然后我们计算每个 k 距离邻域点的可达距离。该比率存储在local_reach_density字典中。
最后,在步骤 5 中,我们计算每个点的 LOF:
for i in range(instances.shape[0]):
lrd_sum = 0
rdist_sum = 0
for neigh in k_distance_neig[i]:
lrd_sum+=local_reach_density[neigh[1]]
rdist_sum+=max(k_distance[neigh[1]][0],neigh[0])
lof_list.append((i,lrd_sum*rdist_sum))
对于每个数据点,我们计算其邻居的 LRD 之和和与其邻居的可达距离之和,并将它们相乘以得到 LOF。
LOF 值非常高的点被视为异常点。让我们打印lof_list:
[(0, 4.0), (1, 4.0), (2, 4.0), (3, 4.0), (4, 18.0)]
正如你所见,最后一个点与其他点相比,LOF 非常高,因此,它是一个异常点。
还有更多……
为了更好地理解 LOF,你可以参考以下论文:
LOF:识别基于密度的局部异常点
Markus M. Breunig, Hans-Peter Kriegel, Raymond T. Ng, Jörg Sander
Proc. ACM SIGMOD 2000 国际数据管理会议,德克萨斯州达拉斯,2000 年
学习向量量化
在这个示例中,我们将看到一种无模型的方法来聚类数据点,称为学习向量量化,简称 LVQ。LVQ 可以用于分类任务。使用这种技术很难在目标变量和预测变量之间做出推理。与其他方法不同,很难弄清楚响应变量 Y 与预测变量 X 之间存在哪些关系。它们在许多现实世界的场景中作为黑箱方法非常有效。
准备工作
LVQ 是一种在线学习算法,其中数据点一次处理一个。它的直观理解非常简单。假设我们已经为数据集中不同的类别识别了原型向量。训练点会朝向相似类别的原型靠近,并会排斥其他类别的原型。
LVQ 的主要步骤如下:
为数据集中的每个类别选择 k 个初始原型向量。如果是二分类问题,我们决定为每个类别选择两个原型向量,那么我们将得到四个初始原型向量。初始原型向量是从输入数据集中随机选择的。
我们将开始迭代。我们的迭代将在 epsilon 值达到零或预定义阈值时结束。我们将决定一个 epsilon 值,并在每次迭代中递减 epsilon 值。
在每次迭代中,我们将对一个输入点进行抽样(有放回抽样),并找到离该点最近的原型向量。我们将使用欧几里得距离来找到最近的点。我们将如下更新最近点的原型向量:
如果原型向量的类别标签与输入数据点相同,我们将通过原型向量与数据点之间的差值来增大原型向量。
如果类别标签不同,我们将通过原型向量与数据点之间的差值来减少原型向量。
我们将使用 Iris 数据集来演示 LVQ 的工作原理。如同我们之前的一些示例,我们将使用 scikit-learn 的方便数据加载函数来加载 Iris 数据集。Iris 是一个广为人知的分类数据集。然而我们在这里使用它的目的是仅仅为了演示 LVQ 的能力。没有类别标签的数据集也可以被 LVQ 使用或处理。由于我们将使用欧几里得距离,因此我们将使用 minmax 缩放来对数据进行缩放。
from sklearn.datasets import load_iris
import numpy as np
from sklearn.metrics import euclidean_distances
data = load_iris()
x = data['data']
y = data['target']
# Scale the variables
from sklearn.preprocessing import MinMaxScaler
minmax = MinMaxScaler()
x = minmax.fit_transform(x)
如何实现…
-
让我们首先声明 LVQ 的参数:
R = 2 n_classes = 3 epsilon = 0.9 epsilon_dec_factor = 0.001 -
定义一个类来保存原型向量:
class prototype(object): """ Class to hold prototype vectors """ def __init__(self,class_id,p_vector,eplsilon): self.class_id = class_id self.p_vector = p_vector self.epsilon = epsilon def update(self,u_vector,increment=True): if increment: # Move the prototype vector closer to input vector self.p_vector = self.p_vector + self.epsilon*(u_vector - self.p_vector) else: # Move the prototype vector away from input vector self.p_vector = self.p_vector - self.epsilon*(u_vector - self.p_vector) -
这是一个用于找到给定向量最接近的原型向量的函数:
def find_closest(in_vector,proto_vectors): closest = None closest_distance = 99999 for p_v in proto_vectors: distance = euclidean_distances(in_vector,p_v.p_vector) if distance < closest_distance: closest_distance = distance closest = p_v return closest -
一个方便的函数,用来找到最接近的原型向量的类别 ID 如下:
def find_class_id(test_vector,p_vectors): return find_closest(test_vector,p_vectors).class_id -
选择初始的 K * 类别数的原型向量:
# Choose R initial prototypes for each class p_vectors = [] for i in range(n_classes): # Select a class y_subset = np.where(y == i) # Select tuples for choosen class x_subset = x[y_subset] # Get R random indices between 0 and 50 samples = np.random.randint(0,len(x_subset),R) # Select p_vectors for sample in samples: s = x_subset[sample] p = prototype(i,s,epsilon) p_vectors.append(p) print "class id \t Initial protype vector\n" for p_v in p_vectors: print p_v.class_id,'\t',p_v.p_vector print -
进行迭代调整原型向量,以便使用现有的数据点对任何新的输入点进行分类/聚类:
while epsilon >= 0.01: # Sample a training instance randonly rnd_i = np.random.randint(0,149) rnd_s = x[rnd_i] target_y = y[rnd_i] # Decrement epsilon value for next iteration epsilon = epsilon - epsilon_dec_factor # Find closes prototype vector to given point closest_pvector = find_closest(rnd_s,p_vectors) # Update closes prototype vector if target_y == closest_pvector.class_id: closest_pvector.update(rnd_s) else: closest_pvector.update(rnd_s,False) closest_pvector.epsilon = epsilon print "class id \t Final Prototype Vector\n" for p_vector in p_vectors: print p_vector.class_id,'\t',p_vector.p_vector -
以下是一个小的测试,用来验证我们方法的正确性:
predicted_y = [find_class_id(instance,p_vectors) for instance in x ] from sklearn.metrics import classification_report print print classification_report(y,predicted_y,target_names=['Iris-Setosa','Iris-Versicolour', 'Iris-Virginica'])
它是如何工作的…
在第 1 步中,我们初始化了算法的参数。我们选择了 R 值为 2,也就是说,每个类别标签有两个原型向量。Iris 数据集是一个三类问题,所以我们一共有六个原型向量。我们必须选择我们的 epsilon 值和 epsilon 减小因子。
然后我们在第 2 步中定义了一个数据结构,用来存储每个原型向量的详细信息。我们的类为数据集中每个点存储以下内容:
self.class_id = class_id
self.p_vector = p_vector
self.epsilon = epsilon
原型向量所属的类别 ID 就是向量本身和 epsilon 值。它还有一个 update 函数,用于更改原型值:
def update(self,u_vector,increment=True):
if increment:
# Move the prototype vector closer to input vector
self.p_vector = self.p_vector + self.epsilon*(u_vector - self.p_vector)
else:
# Move the prototype vector away from input vector
self.p_vector = self.p_vector - self.epsilon*(u_vector - self.p_vector)
在第 3 步中,我们定义了以下函数,该函数以任意给定的向量作为输入,并接受所有原型向量的列表。在所有原型向量中,函数返回与给定向量最接近的原型向量:
for p_v in proto_vectors:
distance = euclidean_distances(in_vector,p_v.p_vector)
if distance < closest_distance:
closest_distance = distance
closest = p_v
正如你所见,它会遍历所有的原型向量,找出最接近的一个。它使用欧几里得距离来衡量相似度。
第 4 步是一个小函数,可以返回与给定向量最接近的原型向量的类别 ID。
现在我们已经完成了 LVQ 算法所需的所有预处理,可以进入第 5 步的实际算法。对于每个类别,我们必须选择初始的原型向量。然后,我们从每个类别中选择 R 个随机点。外部循环遍历每个类别,对于每个类别,我们选择 R 个随机样本并创建我们的原型对象,具体如下:
samples = np.random.randint(0,len(x_subset),R)
# Select p_vectors
for sample in samples:
s = x_subset[sample]
p = prototype(i,s,epsilon)
p_vectors.append(p)
在第 6 步中,我们迭代地增加或减少原型向量。我们会持续循环,直到 epsilon 值降到 0.01 以下。
然后我们从数据集中随机采样一个点,具体如下:
# Sample a training instance randonly
rnd_i = np.random.randint(0,149)
rnd_s = x[rnd_i]
target_y = y[rnd_i]
点和它对应的类别 ID 已被提取。
然后我们可以找到最接近这个点的原型向量,具体如下:
closest_pvector = find_closest(rnd_s,p_vectors)
如果当前点的类别 ID 与原型的类别 ID 匹配,我们会调用 update 方法,增量设置为 True,否则我们将调用 update 方法,增量设置为 False:
# Update closes prototype vector
if target_y == closest_pvector.class_id:
closest_pvector.update(rnd_s)
else:
closest_pvector.update(rnd_s,False)
最后,我们更新最接近的原型向量的 epsilon 值:
closest_pvector.epsilon = epsilon
我们可以打印出原型向量,以便手动查看:
print "class id \t Final Prototype Vector\n"
for p_vector in p_vectors:
print p_vector.class_id,'\t',p_vector.p_vector
在第 7 步中,我们将原型向量投入实际应用,进行预测:
predicted_y = [find_class_id(instance,p_vectors) for instance in x ]
我们可以使用 find_class_id 函数获得预测的类别 ID。我们将一个点和所有已学习的原型向量传递给它,以获取类别 ID。
最后,我们给出我们的预测输出,以生成分类报告:
print classification_report(y,predicted_y,target_names=['Iris-Setosa','Iris-Versicolour', 'Iris-Virginica'])
分类报告函数是由 scikit-learn 库提供的一个便捷函数,用于查看分类准确度评分:
你可以看到我们在分类方面做得相当不错。请记住,我们并没有保留单独的测试集。绝不要根据训练数据来衡量模型的准确性。始终使用训练过程中未见过的测试集。我们这么做仅仅是为了说明。
还有更多…
请记住,这种技术不像其他分类方法那样涉及任何优化准则。因此,很难判断原型向量生成的效果如何。
在我们的配方中,我们将原型向量初始化为随机值。你也可以使用 K-Means 算法来初始化原型向量。
另见
- 使用 K-Means 聚类数据 配方见 第五章, 数据挖掘——大海捞针
查找单变量数据中的异常值
异常值是与数据集中其他数据点相距较远的数据点。在数据科学应用中,它们必须小心处理。无意中将它们包含在某些算法中可能导致错误的结果或结论。正确处理异常值并使用合适的算法来应对它们是非常重要的。
| “异常值检测是一个极其重要的问题,直接应用于许多领域,包括欺诈检测(Bolton, 2002)、识别计算机网络入侵和瓶颈(Lane, 1999)、电子商务中的犯罪活动和检测可疑活动(Chiu, 2003)。” | ||
|---|---|---|
| –- Jayakumar 和 Thomas, 基于多变量异常值检测的聚类新程序(《数据科学期刊》11(2013), 69-84) |
在本配方中,我们将查看如何检测单变量数据中的异常值,然后转向查看多变量数据和文本数据中的异常值。
准备就绪
在本配方中,我们将查看以下三种单变量数据异常值检测方法:
-
中位数绝对偏差
-
均值加减三个标准差
让我们看看如何利用这些方法来发现单变量数据中的异常值。在进入下一节之前,我们先创建一个包含异常值的数据集,以便我们可以通过经验评估我们的方法:
import numpy as np
import matplotlib.pyplot as plt
n_samples = 100
fraction_of_outliers = 0.1
number_inliers = int ( (1-fraction_of_outliers) * n_samples )
number_outliers = n_samples - number_inliers
我们将创建 100 个数据点,其中 10% 会是异常值:
# Get some samples from a normal distribution
normal_data = np.random.randn(number_inliers,1)
我们将在 NumPy 的 random 模块中使用 randn 函数生成我们的正常值数据。这将是一个均值为零,标准差为一的分布样本。让我们验证一下我们样本的均值和标准差:
# Print the mean and standard deviation
# to confirm the normality of our input data.
mean = np.mean(normal_data,axis=0)
std = np.std(normal_data,axis=0)
print "Mean =(%0.2f) and Standard Deviation (%0.2f)"%(mean[0],std[0])
我们将使用 NumPy 中的函数来计算均值和标准差,并打印输出。让我们查看输出结果:
Mean =(0.24) and Standard Deviation (0.90)
正如你所看到的,均值接近零,标准差接近一。
现在,让我们创建异常值数据。这将是整个数据集的 10%,即 10 个点,假设我们的样本大小是 100。正如你所看到的,我们从 -9 到 9 之间的均匀分布中采样了异常值。这个范围内的任何点都有相等的被选择的机会。我们将合并正常值和异常值数据。在运行异常值检测程序之前,最好通过散点图查看数据:
# Create outlier data
outlier_data = np.random.uniform(low=-9,high=9,size=(number_outliers,1))
total_data = np.r_[normal_data,outlier_data]
print "Size of input data = (%d,%d)"%(total_data.shape)
# Eyeball the data
plt.cla()
plt.figure(1)
plt.title("Input points")
plt.scatter(range(len(total_data)),total_data,c='b')
让我们来看一下生成的图形:
我们的y轴是我们生成的实际值,x轴是一个累积计数。您可以做一个练习,标记您认为是异常值的点。稍后我们可以将程序输出与您的手动选择进行比较。
如何操作…
-
让我们从中位数绝对偏差开始。然后我们将绘制我们的值,并将异常值标记为红色:
# Median Absolute Deviation median = np.median(total_data) b = 1.4826 mad = b * np.median(np.abs(total_data - median)) outliers = [] # Useful while plotting outlier_index = [] print "Median absolute Deviation = %.2f"%(mad) lower_limit = median - (3*mad) upper_limit = median + (3*mad) print "Lower limit = %0.2f, Upper limit = %0.2f"%(lower_limit,upper_limit) for i in range(len(total_data)): if total_data[i] > upper_limit or total_data[i] < lower_limit: print "Outlier %0.2f"%(total_data[i]) outliers.append(total_data[i]) outlier_index.append(i) plt.figure(2) plt.title("Outliers using mad") plt.scatter(range(len(total_data)),total_data,c='b') plt.scatter(outlier_index,outliers,c='r') plt.show() -
继续进行均值加减三倍标准差的操作,我们将绘制我们的值,并将异常值标记为红色:
# Standard deviation std = np.std(total_data) mean = np.mean(total_data) b = 3 outliers = [] outlier_index = [] lower_limt = mean-b*std upper_limt = mean+b*std print "Lower limit = %0.2f, Upper limit = %0.2f"%(lower_limit,upper_limit) for i in range(len(total_data)): x = total_data[i] if x > upper_limit or x < lower_limt: print "Outlier %0.2f"%(total_data[i]) outliers.append(total_data[i]) outlier_index.append(i) plt.figure(3) plt.title("Outliers using std") plt.scatter(range(len(total_data)),total_data,c='b') plt.scatter(outlier_index,outliers,c='r') plt.savefig("B04041 04 10.png") plt.show()
它是如何工作的…
在第一步中,我们使用中位数绝对偏差来检测数据中的异常值:
median = np.median(total_data)
b = 1.4826
mad = b * np.median(np.abs(total_data - median))
我们首先使用 NumPy 中的中位数函数计算数据集的中位数值。接着,我们声明一个值为 1.4826 的变量。这个常数将与偏离中位数的绝对偏差相乘。最后,我们计算每个数据点相对于中位数值的绝对偏差的中位数,并将其乘以常数 b。
任何偏离中位数绝对偏差三倍以上的点都被视为我们方法中的异常值:
lower_limit = median - (3*mad)
upper_limit = median + (3*mad)
print "Lower limit = %0.2f, Upper limit = %0.2f"%(lower_limit,upper_limit)
然后,我们计算了中位数绝对偏差的上下限,如前所示,并将每个点分类为异常值或正常值,具体如下:
for i in range(len(total_data)):
if total_data[i] > upper_limit or total_data[i] < lower_limit:
print "Outlier %0.2f"%(total_data[i])
outliers.append(total_data[i])
outlier_index.append(i)
最后,所有异常值都存储在名为 outliers 的列表中。我们还必须将异常值的索引存储在一个名为 outlier_index 的单独列表中。这是为了方便绘图,您将在下一步中看到这一点。
然后我们绘制原始点和异常值。绘图结果如下所示:
被红色标记的点被算法判定为异常值。
在第三步中,我们编写第二个算法,即均值加减三倍标准差:
std = np.std(total_data)
mean = np.mean(total_data)
b = 3
我们接着计算数据集的标准差和均值。在这里,您可以看到我们设置了b = 3。正如我们算法的名字所示,我们需要一个标准差为三,而这个 b 也正是用来实现这个目标的:
lower_limt = mean-b*std
upper_limt = mean+b*std
print "Lower limit = %0.2f, Upper limit = %0.2f"%(lower_limit,upper_limit)
for i in range(len(total_data)):
x = total_data[i]
if x > upper_limit or x < lower_limt:
print "Outlier %0.2f"%(total_data[i])
outliers.append(total_data[i])
outlier_index.append(i)
我们可以计算出上下限,方法是将均值减去三倍标准差。使用这些值,我们可以在 for 循环中将每个点分类为异常值或正常值。然后我们将所有异常值及其索引添加到两个列表中,outliers 和 outlier_index,以便绘图。
最后,我们绘制了异常值:
还有更多内容…
根据异常值的定义,给定数据集中的异常值是那些与其他数据点距离较远的点。数据集中心的估算值和数据集分布的估算值可以用来检测异常值。在我们在本食谱中概述的方法中,我们使用均值和中位数作为数据中心的估算值,使用标准差和中位数绝对偏差作为分布的估算值。分布也被称为尺度。
让我们稍微理清一下我们的检测异常值方法为何有效。首先从使用标准差的方法开始。对于高斯数据,我们知道 68.27% 的数据位于一个标准差内,95.45% 位于两个标准差内,99.73% 位于三个标准差内。因此,根据我们的规则,任何与均值的距离超过三个标准差的点都被归类为异常值。然而,这种方法并不稳健。我们来看一个小例子。
让我们从正态分布中抽取八个数据点,均值为零,标准差为一。
让我们使用 NumPy.random 中的便捷函数来生成我们的数据:
np.random.randn(8)
这给出了以下数值:
-1.76334861, -0.75817064, 0.44468944, -0.07724717, 0.12951944,0.43096092, -0.05436724, -0.23719402
现在我们手动添加两个异常值,例如 45 和 69,加入到这个列表中。
我们的数据集现在看起来如下:
-1.763348607322289, -0.7581706357821458, 0.4446894368956213, -0.07724717210195432, 0.1295194428816003, 0.4309609200681169, -0.05436724238743103, -0.23719402072058543, 45, 69
前面数据集的均值是 11.211,标准差是 23.523。
我们来看一下上限规则,均值 + 3 * 标准差。这是 11.211 + 3 * 23.523 = 81.78。
现在,根据这个上限规则,45 和 69 两个点都不是异常值!均值和标准差是数据集中心和尺度的非稳健估计量,因为它们对异常值非常敏感。如果我们用一个极端值替换数据集中任意一个点(样本量为 n),这将完全改变均值和标准差的估计值。估计量的这一特性被称为有限样本断点。
注意
有限样本断点被定义为,在样本中,能被替换的观察值比例,替换后估计器仍然能准确描述数据。
因此,对于均值和标准差,有限样本断点是 0%,因为在大样本中,替换哪怕一个点也会显著改变估计值。
相比之下,中位数是一个更稳健的估计值。中位数是有限观察集合中按升序排序后的中间值。为了使中位数发生显著变化,我们必须替换掉数据中远离中位数的一半观察值。这就给出了中位数的 50% 有限样本断点。
中位绝对偏差法归因于以下论文:
Leys, C., 等,检测异常值:不要使用均值周围的标准差,使用中位数周围的绝对偏差,《实验社会心理学杂志》(2013), dx.doi.org/10.1016/j.jesp.2013.03.013。
另见
- 第一章中的 执行汇总统计和绘图 配方,使用 Python 进行数据科学
第六章 机器学习 1
本章我们将涵盖以下主题:
-
为模型构建准备数据
-
查找最近邻
-
使用朴素贝叶斯对文档进行分类
-
构建决策树解决多类别问题
介绍
本章我们将探讨监督学习技术。在上一章中,我们介绍了包括聚类和学习向量量化在内的无监督技术。我们将从一个分类问题开始,然后转向回归问题。分类问题的输入是在下一章中的一组记录或实例。
每条记录或实例可以写作一个集合(X,y),其中 X 是属性集,y 是对应的类别标签。
学习一个目标函数 F,该函数将每条记录的属性集映射到预定义的类别标签 y,是分类算法的任务。
分类算法的一般步骤如下:
-
寻找合适的算法
-
使用训练集学习模型,并使用测试集验证模型
-
应用模型预测任何未见过的实例或记录
第一步是确定正确的分类算法。没有固定的方法来选择合适的算法,这需要通过反复的试错过程来完成。选择算法后,创建训练集和测试集,并将其提供给算法,以学习一个模型,也就是前面定义的目标函数 F。通过训练集创建模型后,使用测试集来验证模型。通常,我们使用混淆矩阵来验证模型。我们将在我们的食谱中进一步讨论混淆矩阵:查找最近邻。
我们将从一个食谱开始,展示如何将输入数据集划分为训练集和测试集。接下来我们将介绍一种懒惰学习者算法用于分类,称为 K-最近邻算法。然后我们将看一下朴素贝叶斯分类器。接下来我们将探讨一个使用决策树处理多类别问题的食谱。本章我们选择的算法并非随意选择。我们将在本章中介绍的三种算法都能够处理多类别问题,除了二分类问题。在多类别问题中,我们有多个类别标签,实例可以属于这些类别中的任意一个。
为模型构建准备数据
在这个示例中,我们将展示如何从给定的数据集中创建训练集和测试集用于分类问题。测试数据集永远不会被展示给模型。在实际应用中,我们通常会建立另一个名为 dev 的数据集。Dev 代表开发数据集:我们可以用它在模型的连续运行过程中持续调优模型。模型使用训练集进行训练,模型的性能度量,如准确率,则在 dev 数据集上进行评估。根据这些结果,如果需要改进,模型将进一步调优。在后续章节中,我们将介绍一些比简单的训练测试集拆分更复杂的数据拆分方法。
准备工作
我们将使用鸢尾花数据集来进行这个示例。由于我们已经在许多之前的示例中使用过它,所以使用这个数据集展示概念非常简单。
如何实现…
# Load the necesssary Library
from sklearn.cross_validation import train_test_split
from sklearn.datasets import load_iris
import numpy as np
def get_iris_data():
"""
Returns Iris dataset
"""
# Load iris dataset
data = load_iris()
# Extract the dependend and independent variables
# y is our class label
# x is our instances/records
x = data['data']
y = data['target']
# For ease we merge them
# column merge
input_dataset = np.column_stack([x,y])
# Let us shuffle the dataset
# We want records distributed randomly
# between our test and train set
np.random.shuffle(input_dataset)
return input_dataset
# We need 80/20 split.
# 80% of our records for Training
# 20% Remaining for our Test set
train_size = 0.8
test_size = 1-train_size
# get the data
input_dataset = get_iris_data()
# Split the data
train,test = train_test_split(input_dataset,test_size=test_size)
# Print the size of original dataset
print "Dataset size ",input_dataset.shape
# Print the train/test split
print "Train size ",train.shape
print "Test size",test.shape
这很简单。让我们检查一下类别标签是否在训练集和测试集之间按比例分配。这是一个典型的类别不平衡问题:
def get_class_distribution(y):
"""
Given an array of class labels
Return the class distribution
"""
distribution = {}
set_y = set(y)
for y_label in set_y:
no_elements = len(np.where(y == y_label)[0])
distribution[y_label] = no_elements
dist_percentage = {class_label: count/(1.0*sum(distribution.values())) for class_label,count in distribution.items()}
return dist_percentage
def print_class_label_split(train,test):
"""
Print the class distribution
in test and train dataset
"""
y_train = train[:,-1]
train_distribution = get_class_distribution(y_train)
print "\nTrain data set class label distribution"
print "=========================================\n"
for k,v in train_distribution.items():
print "Class label =%d, percentage records =%.2f"%(k,v)
y_test = test[:,-1]
test_distribution = get_class_distribution(y_test)
print "\nTest data set class label distribution"
print "=========================================\n"
for k,v in test_distribution.items():
print "Class label =%d, percentage records =%.2f"%(k,v)
print_class_label_split(train,test)
让我们看看如何将类别标签均匀分配到训练集和测试集中:
# Perform Split the data
stratified_split = StratifiedShuffleSplit(input_dataset[:,-1],test_size=test_size,n_iter=1)
for train_indx,test_indx in stratified_split:
train = input_dataset[train_indx]
test = input_dataset[test_indx]
print_class_label_split(train,test)
如何工作…
在我们导入必要的库模块后,必须编写一个方便的函数get_iris_data(),该函数将返回鸢尾花数据集。然后,我们将x和y数组按列连接成一个名为input_dataset的单一数组。接着,我们对数据集进行打乱,以便记录能够随机分配到测试集和训练集。该函数返回一个包含实例和类别标签的单一数组。
我们希望将 80%的记录包含在训练数据集中,剩余的用作测试数据集。train_size和test_size变量分别表示应该分配到训练集和测试集中的百分比值。
我们必须调用get_iris_data()函数以获取输入数据。然后,我们利用 scikit-learn 的cross_validation模块中的train_test_split函数将输入数据集拆分成两部分。
最后,我们可以打印原始数据集的大小,接着是测试集和训练集的大小:
我们的原始数据集有 150 行和五列。记住,只有四个属性;第五列是类别标签。我们已经将x和y按列连接。
正如你所看到的,150 行数据中的 80%(即 120 条记录)已被分配到我们的训练集中。我们已经展示了如何轻松地将输入数据拆分为训练集和测试集。
记住,这是一个分类问题。算法应该被训练来预测给定未知实例或记录的正确类别标签。为此,我们需要在训练期间为算法提供所有类别的均匀分布。鸢尾花数据集是一个三类问题,我们应该确保所有三类都有相等的代表性。让我们看看我们的方法是否已经解决了这个问题。
我们必须定义一个名为get_class_distribution的函数,该函数接受一个单一的y参数(类别标签数组)。此函数返回一个字典,其中键是类别标签,值是该分布记录的百分比。因此,字典提供了类别标签的分布情况。我们必须在以下函数中调用此函数,以了解训练集和测试集中的类别分布。
print_class_label_split函数不言自明。我们必须将训练集和测试集作为参数传递。由于我们已经将x和y连接在一起,最后一列就是我们的类别标签。然后,我们提取y_train和y_test中的训练集和测试集类别标签。我们将它们传递给get_class_distribution函数,以获取类别标签及其分布的字典,最后打印出来。
最后,我们可以调用print_class_label_split,我们的输出应该如下所示:
现在让我们查看输出结果。如您所见,我们的训练集和测试集中的类别标签分布不同。测试集中正好 40%的实例属于class label 1。这不是正确的分割方式。我们应该在训练集和测试集之间拥有相等的分布。
在最后一段代码中,我们使用了来自 scikit-learn 的StratifiedShuffleSplit,以实现训练集和测试集中类别的均匀分布。让我们查看StratifiedShuffleSplit的参数:
stratified_split = StratifiedShuffleSplit(input_dataset[:,-1],test_size=test_size,n_iter=1)
第一个参数是输入数据集。我们传递所有行和最后一列。我们的测试集大小由我们最初声明的test_size变量定义。我们可以假设仅使用n_iter变量进行一次分割。然后,我们继续调用print_class_label_split函数打印类别标签的分布情况。让我们查看输出结果:
现在,我们已经在测试集和训练集之间均匀分布了类别标签。
还有更多…
在使用机器学习算法之前,我们需要仔细准备数据。为训练集和测试集提供均匀的类别分布是构建成功分类模型的关键。
在实际的机器学习场景中,除了训练集和测试集外,我们还会创建另一个称为开发集(dev set)的数据集。我们可能在第一次迭代中无法正确构建模型。我们不希望将测试数据集展示给我们的模型,因为这可能会影响我们下一次模型构建的结果。因此,我们创建了这个开发集,可以在迭代模型构建过程中使用。
我们在本节中指定的 80/20 法则是一个理想化的场景。然而,在许多实际应用中,我们可能没有足够的数据来留下如此多的实例作为测试集。在这种情况下,一些实用技术,如交叉验证,便派上用场。在下一章中,我们将探讨各种交叉验证技术。
查找最近邻
在我们进入具体步骤之前,让我们先花些时间了解如何检查我们的分类模型是否达到预期的表现。在介绍部分,我们提到过一个术语叫做混淆矩阵。
混淆矩阵是实际标签与预测标签的矩阵排列。假设我们有一个二分类问题,即y可以取值为T或F。假设我们训练了一个分类器来预测y。在我们的测试数据中,我们知道y的实际值,同时我们也有模型预测的y值。我们可以按照以下方式填充混淆矩阵:
这里是一个表格,我们方便地列出了来自测试集的结果。记住,我们知道测试集中的类别标签,因此我们可以将分类模型的输出与实际类别标签进行比较。
-
在
TP(真正例)下,我们统计的是测试集中所有标签为T的记录,且模型也预测为T的记录数。 -
在
FN(假阴性)的情况下,我们统计的是所有实际标签为T,但算法预测为 N 的记录数。 -
FP表示假阳性,即实际标签为F,但算法预测为T -
TN表示真阴性,即算法预测的标签和实际类别标签都为F
通过了解这个混淆矩阵,我们现在可以推导出一些性能指标,用于衡量我们分类模型的质量。在未来的章节中,我们将探索更多的指标,但现在我们将介绍准确率和错误率。
准确率定义为正确预测与总预测次数的比率。从混淆矩阵中,我们可以知道 TP 和 TN 的总和是正确预测的总数:
从训练集得出的准确率通常过于乐观。应该关注测试集上的准确率值,以确定模型的真实表现。
掌握了这些知识后,让我们进入我们的示例。我们首先要看的分类算法是 K-最近邻,简称 KNN。在详细讲解 KNN 之前,让我们先看看一个非常简单的分类算法,叫做死记硬背分类算法。死记硬背分类器会记住整个训练数据,也就是说,它将所有数据加载到内存中。当我们需要对一个新的训练实例进行分类时,它会尝试将新的训练实例与内存中的任何训练实例进行匹配。它会将测试实例的每个属性与训练实例中的每个属性进行匹配。如果找到匹配项,它会将测试实例的类别标签预测为匹配的训练实例的类别标签。
你现在应该知道,如果测试实例与加载到内存中的任何训练实例不相似,这个分类器会失败。
KNN 类似于死记硬背分类器,不同之处在于它不是寻找完全匹配,而是使用相似度度量。与死记硬背分类器类似,KNN 将所有训练集加载到内存中。当它需要对一个测试实例进行分类时,它会计算测试实例与所有训练实例之间的距离。利用这个距离,它会选择训练集中 K 个最接近的实例。现在,测试集的预测是基于 K 个最近邻的多数类别。
例如,如果我们有一个二分类问题,并且选择我们的 K 值为 3,那么如果给定的测试记录的三个最近邻类别分别为 1、1 和 0,它将把测试实例分类为 1,也就是多数类别。
KNN 属于一种叫做基于实例学习的算法家族。此外,由于对测试实例的分类决定是在最后做出的,因此它也被称为懒学习者。
准备中
对于这个示例,我们将使用 scikit 的 make_classification 方法生成一些数据。我们将生成一个包含四列/属性/特征和 100 个实例的矩阵:
from sklearn.datasets import make_classification
import numpy as np
import matplotlib.pyplot as plt
import itertools
from sklearn.ensemble import BaggingClassifier
from sklearn.neighbors import KNeighborsClassifier
def get_data():
"""
Make a sample classification dataset
Returns : Independent variable y, dependent variable x
"""
x,y = make_classification(n_features=4)
return x,y
def plot_data(x,y):
"""
Plot a scatter plot fo all variable combinations
"""
subplot_start = 321
col_numbers = range(0,4)
col_pairs = itertools.combinations(col_numbers,2)
for col_pair in col_pairs:
plt.subplot(subplot_start)
plt.scatter(x[:,col_pair[0]],x[:,col_pair[1]],c=y)
title_string = str(col_pair[0]) + "-" + str(col_pair[1])
plt.title(title_string)
x_label = str(col_pair[0])
y_label = str(col_pair[1])
plt.xlabel(x_label)
plt.xlabel(y_label)
subplot_start+=1
plt.show()
x,y = get_data()
plot_data(x,y)
get_data 函数内部调用 make_classification 来生成任何分类任务的测试数据。
在将数据输入任何算法之前,最好先对数据进行可视化。我们的 plot_data 函数会生成所有变量之间的散点图:
我们已经绘制了所有变量的组合。顶部的两个图表显示了第 0 列与第 1 列之间的组合,接着是第 0 列与第 2 列的组合。数据点也按其类别标签上色。这展示了这些变量组合在进行分类任务时提供了多少信息。
如何做…
我们将数据集准备和模型训练分成两个不同的方法:get_train_test 用来获取训练和测试数据,build_model 用来构建模型。最后,我们将使用 test_model 来验证我们模型的有效性:
from sklearn.cross_validation import StratifiedShuffleSplit
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
def get_train_test(x,y):
"""
Perpare a stratified train and test split
"""
train_size = 0.8
test_size = 1-train_size
input_dataset = np.column_stack([x,y])
stratified_split = StratifiedShuffleSplit(input_dataset[:,-1],test_size=test_size,n_iter=1)
for train_indx,test_indx in stratified_split:
train_x = input_dataset[train_indx,:-1]
train_y = input_dataset[train_indx,-1]
test_x = input_dataset[test_indx,:-1]
test_y = input_dataset[test_indx,-1]
return train_x,train_y,test_x,test_y
def build_model(x,y,k=2):
"""
Fit a nearest neighbour model
"""
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(x,y)
return knn
def test_model(x,y,knn_model):
y_predicted = knn_model.predict(x)
print classification_report(y,y_predicted)
if __name__ == "__main__":
# Load the data
x,y = get_data()
# Scatter plot the data
plot_data(x,y)
# Split the data into train and test
train_x,train_y,test_x,test_y = get_train_test(x,y)
# Build the model
knn_model = build_model(train_x,train_y)
# Test the model
print "\nModel evaluation on training set"
print "================================\n"
test_model(train_x,train_y,knn_model)
print "\nModel evaluation on test set"
print "================================\n"
test_model(test_x,test_y,knn_model)
如何运作…
让我们尝试遵循主方法中的代码。我们必须从调用get_data并使用plot_data进行绘图开始,如前一部分所述。
如前所述,我们需要将一部分训练数据分离出来用于测试,以评估我们的模型。然后,我们调用get_train_test方法来完成这一操作。
在get_train_test中,我们决定了训练测试集的分割比例,标准为 80/20。然后,我们使用 80%的数据来训练我们的模型。现在,我们在拆分之前,使用 NumPy 的column_stack方法将 x 和 y 合并为一个矩阵。
然后,我们利用在前面配方中讨论的StratifiedShuffleSplit,以便在训练集和测试集之间获得均匀的类标签分布。
凭借我们的训练集和测试集,我们现在准备好构建分类器了。我们必须使用我们的训练集、属性x和类标签y来调用构建模型函数。该函数还接收K作为参数,表示邻居的数量,默认值为二。
我们使用了 scikit-learn 的 KNN 实现,KNeighborsClassifier。然后,我们创建分类器对象并调用fit方法来构建我们的模型。
我们准备好使用训练数据来测试模型的表现了。我们可以将训练数据(x 和 y)以及模型传递给test_model函数。
我们知道我们的实际类标签(y)。然后,我们调用预测函数,使用我们的 x 来获得预测标签。接着,我们打印出一些模型评估指标。我们可以从打印模型的准确率开始,接着是混淆矩阵,最后展示一个名为classification_report的函数的输出。scikit-learn 的 metrics 模块提供了一个名为classification_report的函数,可以打印出多个模型评估指标。
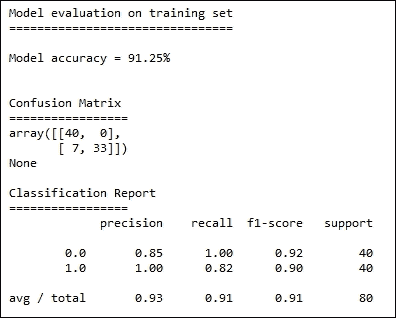
让我们来看看我们的模型指标:
如你所见,我们的准确率得分是 91.25%。我们不会重复准确率的定义,你可以参考介绍部分。
现在让我们来看一下混淆矩阵。左上角的单元格是正确正类单元格。我们可以看到没有假负类,但有七个假正类(第二行的第一个单元格)。
最后,我们在分类报告中得到了精确度、召回率、F1 分数和支持度。让我们来看看它们的定义:
精确度是正确正类与正确正类和假正类之和的比率
准确率是正确正类与正确正类和假负类之和的比率
F1 分数是精确度和敏感度的调和平均值
我们将在未来章节的单独配方中更详细地讨论这个指标。现在,暂时可以说我们会有较高的精确度和召回率值。
知道我们模型的准确率约为 91%是好的,但真正的考验将是在测试数据上运行时。让我们看看测试数据的指标:
很高兴地知道,我们的模型在测试数据上的准确率为 95%,这表明我们在拟合模型方面做得很好。
还有更多内容…
让我们更深入地了解我们已经构建的模型:
我们调用了一个名为get_params的函数。该函数返回所有传递给模型的参数。让我们来检查每个参数。
第一个参数指的是 KNN 实现所使用的底层数据结构。由于训练集中的每个记录都必须与其他所有记录进行比较,暴力实现可能会占用大量计算资源。因此,我们可以选择 kd_tree 或 ball_tree 作为数据结构。暴力方法会对每个记录使用暴力法,通过循环遍历所有记录。
叶子大小是传递给 kd_tree 或 ball_tree 方法的参数。
度量是用于寻找邻居的距离度量方法。两者的 p 值将 Minkowski 距离简化为欧几里得距离。
最后,我们有了权重参数。KNN 根据其 K 个最近邻的类别标签来决定测试实例的类别标签。多数投票决定测试实例的类别标签。但是,如果我们将权重设置为距离,那么每个邻居会被赋予一个与其距离成反比的权重。因此,在决定测试集的类别标签时,进行的是加权投票,而不是简单投票。
另请参见
-
为模型构建准备数据 这一方法在第六章,机器学习 I中有提到。
-
距离度量法工作 这一方法在第五章,数据挖掘——大海捞针中有提到。
使用朴素贝叶斯分类文档
在这个方案中,我们将查看一个文档分类问题。我们将使用的算法是朴素贝叶斯分类器。贝叶斯定理是驱动朴素贝叶斯算法的引擎,如下所示:
它展示了事件 X 发生的可能性,前提是我们已经知道事件 Y 已经发生。在我们的方案中,我们将对文本进行分类或分组。我们的分类问题是二分类问题:给定一条电影评论,我们想要分类评论是正面还是负面。
在贝叶斯术语中,我们需要找到条件概率:给定评论,评论为正的概率,和评论为负的概率。我们可以将其表示为一个方程:
对于任何评论,如果我们有前面的两个概率值,我们可以通过比较这些值将评论分类为正面或负面。如果负面的条件概率大于正面的条件概率,我们将评论分类为负面,反之亦然。
现在,让我们通过贝叶斯定理来讨论这些概率:
由于我们将比较这两个方程来最终确定预测结果,我们可以忽略分母,因为它只是一个简单的缩放因子。
上述方程的左侧(LHS)称为后验概率。
让我们看一下右侧(RHS)的分子部分:
P(positive) 是正类的概率,称为先验概率。这是我们基于训练集对正类标签分布的信念。
我们将从我们的训练测试中进行估计。计算公式如下:
P(review|positive) 是似然度。它回答了这样一个问题:在给定类别为正类的情况下,获得该评论的可能性是多少。同样,我们将从我们的训练集中进行估计。
在我们进一步展开似然度方程之前,让我们引入独立性假设的概念。由于这个假设,该算法被称为朴素的。与实际情况相反,我们假设文档中的词是相互独立的。我们将利用这个假设来计算似然度。
一条评论是一个单词列表。我们可以将其用数学符号表示如下:
基于独立性假设,我们可以说,这些词在评论中共同出现的概率是评论中各个单词的单独概率的乘积。
现在我们可以将似然度方程写成如下形式:
所以,给定一个新的评论,我们可以利用这两个方程——先验概率和似然度,来计算该评论是正面的还是负面的。
希望你到现在为止都跟上了。现在还有最后一块拼图:我们如何计算每个单词的概率?
这一步是指训练模型。
从我们的训练集出发,我们将取出每个评论,并且我们也知道它的标签。对于评论中的每一个词,我们将计算条件概率并将其存储在表格中。这样,我们就可以利用这些值来预测未来的测试实例。
理论够了!让我们深入了解我们的步骤。
准备工作
对于这个步骤,我们将使用 NLTK 库来处理数据和算法。在安装 NLTK 时,我们也可以下载数据集。一个这样的数据集是电影评论数据集。电影评论数据集被分为两类,正面和负面。对于每个类别,我们都有一个词列表;评论已经预先分割成单词:
from nltk.corpus import movie_reviews
如此处所示,我们将通过从 NLTK 导入语料库模块来包括数据集。
我们将利用 NaiveBayesClassifier 类,这个类定义在 NLTK 中,用来构建模型。我们将把我们的训练数据传递给一个名为 train() 的函数,以建立我们的模型。
如何操作……
让我们从导入必要的函数开始。接下来我们将导入两个工具函数。第一个函数用来获取电影评论数据,第二个函数帮助我们将数据划分为训练集和测试集:
from nltk.corpus import movie_reviews
from sklearn.cross_validation import StratifiedShuffleSplit
import nltk
from nltk.corpus import stopwords
from nltk.collocations import BigramCollocationFinder
from nltk.metrics import BigramAssocMeasures
def get_data():
"""
Get movie review data
"""
dataset = []
y_labels = []
# Extract categories
for cat in movie_reviews.categories():
# for files in each cateogry
for fileid in movie_reviews.fileids(cat):
# Get the words in that category
words = list(movie_reviews.words(fileid))
dataset.append((words,cat))
y_labels.append(cat)
return dataset,y_labels
def get_train_test(input_dataset,ylabels):
"""
Perpare a stratified train and test split
"""
train_size = 0.7
test_size = 1-train_size
stratified_split = StratifiedShuffleSplit(ylabels,test_size=test_size,n_iter=1,random_state=77)
for train_indx,test_indx in stratified_split:
train = [input_dataset[i] for i in train_indx]
train_y = [ylabels[i] for i in train_indx]
test = [input_dataset[i] for i in test_indx]
test_y = [ylabels[i] for i in test_indx]
return train,test,train_y,test_y
现在我们将介绍三个函数,这些函数主要用于特征生成。我们需要为分类器提供特征或属性。这些函数根据评论生成一组特征:
def build_word_features(instance):
"""
Build feature dictionary
Features are binary, name of the feature is word iteslf
and value is 1\. Features are stored in a dictionary
called feature_set
"""
# Dictionary to store the features
feature_set = {}
# The first item in instance tuple the word list
words = instance[0]
# Populate feature dicitonary
for word in words:
feature_set[word] = 1
# Second item in instance tuple is class label
return (feature_set,instance[1])
def build_negate_features(instance):
"""
If a word is preceeded by either 'not' or 'no'
this function adds a prefix 'Not_' to that word
It will also not insert the previous negation word
'not' or 'no' in feature dictionary
"""
# Retreive words, first item in instance tuple
words = instance[0]
final_words = []
# A boolean variable to track if the
# previous word is a negation word
negate = False
# List of negation words
negate_words = ['no','not']
# On looping throught the words, on encountering
# a negation word, variable negate is set to True
# negation word is not added to feature dictionary
# if negate variable is set to true
# 'Not_' prefix is added to the word
for word in words:
if negate:
word = 'Not_' + word
negate = False
if word not in negate_words:
final_words.append(word)
else:
negate = True
# Feature dictionary
feature_set = {}
for word in final_words:
feature_set[word] = 1
return (feature_set,instance[1])
def remove_stop_words(in_data):
"""
Utility function to remove stop words
from the given list of words
"""
stopword_list = stopwords.words('english')
negate_words = ['no','not']
# We dont want to remove the negate words
# Hence we create a new stop word list excluding
# the negate words
new_stopwords = [word for word in stopword_list if word not in negate_words]
label = in_data[1]
# Remove stopw words
words = [word for word in in_data[0] if word not in new_stopwords]
return (words,label)
def build_keyphrase_features(instance):
"""
A function to extract key phrases
from the given text.
Key Phrases are words of importance according to a measure
In this key our phrase of is our length 2, i.e two words or bigrams
"""
feature_set = {}
instance = remove_stop_words(instance)
words = instance[0]
bigram_finder = BigramCollocationFinder.from_words(words)
# We use the raw frequency count of bigrams, i.e. bigrams are
# ordered by their frequency of occurence in descending order
# and top 400 bigrams are selected.
bigrams = bigram_finder.nbest(BigramAssocMeasures.raw_freq,400)
for bigram in bigrams:
feature_set[bigram] = 1
return (feature_set,instance[1])
现在让我们编写一个函数来构建我们的模型,并稍后检查我们的模型,以评估其有效性:
def build_model(features):
"""
Build a naive bayes model
with the gvien feature set.
"""
model = nltk.NaiveBayesClassifier.train(features)
return model
def probe_model(model,features,dataset_type = 'Train'):
"""
A utility function to check the goodness
of our model.
"""
accuracy = nltk.classify.accuracy(model,features)
print "\n" + dataset_type + " Accuracy = %0.2f"%(accuracy*100) + "%"
def show_features(model,no_features=5):
"""
A utility function to see how important
various features are for our model.
"""
print "\nFeature Importance"
print "===================\n"
print model.show_most_informative_features(no_features)
在第一次尝试时,很难将模型调整到最佳状态。我们需要尝试不同的特征和参数调整。这基本上是一个反复试验的过程。在下一节代码中,我们将通过改进模型来展示我们的不同尝试:
def build_model_cycle_1(train_data,dev_data):
"""
First pass at trying out our model
"""
# Build features for training set
train_features =map(build_word_features,train_data)
# Build features for test set
dev_features = map(build_word_features,dev_data)
# Build model
model = build_model(train_features)
# Look at the model
probe_model(model,train_features)
probe_model(model,dev_features,'Dev')
return model
def build_model_cycle_2(train_data,dev_data):
"""
Second pass at trying out our model
"""
# Build features for training set
train_features =map(build_negate_features,train_data)
# Build features for test set
dev_features = map(build_negate_features,dev_data)
# Build model
model = build_model(train_features)
# Look at the model
probe_model(model,train_features)
probe_model(model,dev_features,'Dev')
return model
def build_model_cycle_3(train_data,dev_data):
"""
Third pass at trying out our model
"""
# Build features for training set
train_features =map(build_keyphrase_features,train_data)
# Build features for test set
dev_features = map(build_keyphrase_features,dev_data)
# Build model
model = build_model(train_features)
# Look at the model
probe_model(model,train_features)
probe_model(model,dev_features,'Dev')
test_features = map(build_keyphrase_features,test_data)
probe_model(model,test_features,'Test')
return model
最后,我们将编写一段代码,以便调用我们之前定义的所有函数:
if __name__ == "__main__":
# Load data
input_dataset, y_labels = get_data()
# Train data
train_data,all_test_data,train_y,all_test_y = get_train_test(input_dataset,y_labels)
# Dev data
dev_data,test_data,dev_y,test_y = get_train_test(all_test_data,all_test_y)
# Let us look at the data size in our different
# datasets
print "\nOriginal Data Size =", len(input_dataset)
print "\nTraining Data Size =", len(train_data)
print "\nDev Data Size =", len(dev_data)
print "\nTesting Data Size =", len(test_data)
# Different passes of our model building exercise
model_cycle_1 = build_model_cycle_1(train_data,dev_data)
# Print informative features
show_features(model_cycle_1)
model_cycle_2 = build_model_cycle_2(train_data,dev_data)
show_features(model_cycle_2)
model_cycle_3 = build_model_cycle_3(train_data,dev_data)
show_features(model_cycle_3)
它是如何工作的……
让我们尝试按照主函数中的步骤来执行这个过程。我们从调用get_data函数开始。如前所述,电影评论数据被存储为两类:正面和负面。我们的第一个循环遍历这些类别。在第二个循环中,我们使用这些类别来检索文件 ID。使用这些文件 ID,我们进一步获取单词,如下所示:
words = list(movie_reviews.words(fileid))
我们将这些单词附加到一个名为dataset的列表中。类别标签将附加到另一个名为y_labels的列表中。
最后,我们返回单词及其相应的类别标签:
return dataset,y_labels
凭借数据集,我们需要将其划分为测试集和训练集:
# Train data
train_data,all_test_data,train_y,all_test_y = get_train_test(input_dataset,y_labels)
我们调用了get_train_test函数,传入一个输入数据集和类别标签。此函数为我们提供了一个分层样本。我们使用 70%的数据作为训练集,剩余的作为测试集。
我们再次调用get_train_test,并传入上一步返回的测试数据集:
# Dev data
dev_data,test_data,dev_y,test_y = get_train_test(all_test_data,all_test_y)
我们创建了一个单独的数据集,并称其为开发集。我们需要这个数据集来调整我们的模型。我们希望我们的测试集真正充当测试集的角色。在构建模型的不同过程中,我们不希望暴露测试集。
让我们打印出我们的训练集、开发集和测试集的大小:
如你所见,70%的原始数据被分配到我们的训练集中。其余的 30%再次被划分为Dev和Testing的 70/30 分配。
让我们开始我们的模型构建活动。我们将调用build_model_cycle_1,并使用我们的训练集和开发集数据。在这个函数中,我们将首先通过调用build_word_feature并对数据集中的所有实例进行 map 操作来创建特征。build_word_feature是一个简单的特征生成函数。每个单词都是一个特征。这个函数的输出是一个特征字典,其中键是单词本身,值为 1。这种类型的特征通常被称为词袋模型(BOW)。build_word_features函数同时在训练集和开发集数据上调用:
# Build features for training set
train_features =map(build_negate_features,train_data)
# Build features for test set
dev_features = map(build_negate_features,dev_data)
我们现在将继续使用生成的特征来训练我们的模型:
# Build model
model = build_model(train_features)
我们需要测试我们的模型有多好。我们使用probe_model函数来实现这一点。Probe_model接受三个参数。第一个参数是我们感兴趣的模型,第二个参数是我们希望评估模型性能的特征,最后一个参数是用于显示目的的字符串。probe_model函数通过在nltk.classify模块中使用准确度函数来计算准确率指标。
我们调用probe_model两次:第一次使用训练数据来查看模型在训练集上的表现,第二次使用开发集数据:
# Look at the model
probe_model(model,train_features)
probe_model(model,dev_features,'Dev')
现在让我们来看一下准确率数据:
我们的模型在使用训练数据时表现得非常好。这并不令人惊讶,因为模型在训练阶段已经见过这些数据。它能够正确地分类训练记录。然而,我们的开发集准确率很差。我们的模型只能正确分类 60%的开发集实例。显然,我们的特征对于帮助模型高效分类未见过的实例并不够有信息量。查看哪些特征对将评论分类为正面或负面有更大贡献是很有帮助的:
show_features(model_cycle_1)
我们将调用show_features函数来查看各特征对模型的贡献。Show_features函数利用 NLTK 分类器对象中的show_most_informative_feature函数。我们第一个模型中最重要的特征如下:
读取方式是:特征stupidity = 1在将评论分类为负面时比其他特征更有效 15 倍。
接下来,我们将使用一组新的特征来进行第二轮模型构建。我们将通过调用build_model_cycle_2来实现。build_model_cycle_2与build_model_cycle_1非常相似,唯一不同的是在 map 函数中调用了不同的特征生成函数。
特征生成函数称为 build_negate_features。通常,像 “not” 和 “no” 这样的词被称为否定词。假设我们的评论者说这部电影不好。如果我们使用之前的特征生成器,单词 “good” 在正面和负面评论中会被平等对待。但我们知道,单词 “good” 应该用于区分正面评论。为了避免这个问题,我们将查找单词列表中的否定词“no”和“not”。我们希望将我们的示例句子修改如下:
"movie is not good" to "movie is not_good"
通过这种方式,no_good 可以作为一个很好的特征,帮助区分负面评论与正面评论。build_negate_features 函数完成了这个工作。
现在,让我们看看使用此否定特征构建的模型的探测输出:
我们在开发数据上的模型准确率提高了近 2%。现在让我们看看这个模型中最具信息量的特征:
看看最后一个特征。添加否定词后,“Not_funny” 特征对于区分负面评论比其他特征信息量多 11.7 倍。
我们能提高模型的准确性吗?目前,我们的准确率是 70%。让我们进行第三次实验,使用一组新的特征。我们将通过调用 build_model_cycle_3 来实现。build_model_cycle_3 与 build_model_cycle_2 非常相似,除了在 map 函数内部调用的特征生成函数不同。
build_keyphrase_features 函数用作特征生成器。让我们详细看看这个函数。我们将不使用单词作为特征,而是从评论中生成关键词组,并将它们用作特征。关键词组是我们通过某种度量认为重要的短语。关键词组可以由两个、三个或多个单词组成。在我们的例子中,我们将使用两个单词(二元组)来构建关键词组。我们将使用的度量是这些短语的原始频率计数。我们将选择频率计数较高的短语。在生成关键词组之前,我们将进行一些简单的预处理。我们将从单词列表中移除所有停用词和标点符号。remove_stop_words 函数会被调用来移除停用词和标点符号。NLTK 的语料库模块中有一个英文停用词列表。我们可以按如下方式检索它:
stopword_list = stopwords.words('english')
同样,Python 的字符串模块维护着一个标点符号列表。我们将按如下方式移除停用词和标点符号:
words = [word for word in in_data[0] if word not in new_stopwords \
and word not in punctuation]
然而,我们不会移除“not”和no。我们将通过“not”创建一组新的停用词,其中包含前一步中的否定词:
new_stopwords = [word for word in stopword_list if word not in negate_words]
我们将利用 NLTK 的 BigramCollocationFinder 类来生成我们的关键词组:
bigram_finder = BigramCollocationFinder.from_words(words)
# We use the raw frequency count of bigrams, i.e. bigrams are
# ordered by their frequency of occurence in descending order
# and top 400 bigrams are selected.
bigrams = bigram_finder.nbest(BigramAssocMeasures.raw_freq,400)
我们的度量是频率计数。你可以看到,在最后一行中我们将其指定为 raw_freq。我们将要求搭配查找器返回最多 400 个短语。
装载了新特征后,我们将继续构建模型并测试模型的正确性。让我们看看模型的输出:
是的!我们在开发集上取得了很大进展。从第一次使用词语特征时的 68%准确率,我们通过关键短语特征将准确率从 12%提升至 80%。现在让我们将测试集暴露给这个模型,检查准确度:
test_features = map(build_keyphrase_features,test_data)
probe_model(model,test_features,'Test')
我们的测试集准确度高于开发集准确度。我们在训练一个在未见数据集上表现良好的模型方面做得不错。在结束本教程之前,我们来看一下最有信息量的关键短语:
关键短语“奥斯卡提名”在区分评论为正面时比其他任何特征都要有帮助,效果是其他 10 倍。你无法否认这一点。我们可以看到我们的关键短语信息量非常大,因此我们的模型比前两次运行表现得更好。
还有更多…
我们是如何知道 400 个关键短语和度量频次计数是双词生成的最佳参数的呢?通过反复试验。虽然我们没有列出我们的试验过程,但基本上我们使用了不同的组合,比如 200 个短语与逐点互信息(pointwise mutual information),以及其他类似的方法。
这就是现实世界中需要做的事情。然而,我们不是每次都盲目地搜索参数空间,而是关注了最有信息量的特征。这给了我们有关特征区分能力的线索。
另见
- 在第六章中的为模型构建准备数据教程,机器学习 I
构建决策树来解决多类问题
在本教程中,我们将讨论构建决策树来解决多类分类问题。从直觉上看,决策树可以定义为通过一系列问题来得出答案的过程:一系列的“如果-那么”语句按层次结构排列构成了决策树。正因为这种特性,它们易于理解和解释。
请参考以下链接,详细了解决策树的介绍:
en.wikipedia.org/wiki/Decision_tree
理论上,可以为给定的数据集构建许多决策树。某些树比其他树更准确。有一些高效的算法可以在有限的时间内开发出一个合理准确的树。一个这样的算法是亨特算法。像 ID3、C4.5 和 CART(分类和回归树)这样的算法都基于亨特算法。亨特算法可以概述如下:
给定一个数据集 D,其中有 n 条记录,每条记录包含 m 个属性/特征/列,并且每条记录被标记为 y1、y2 或 y3,算法的处理流程如下:
-
如果 D 中的所有记录都属于同一类别标签,例如 y1,那么 y1 就是树的叶子节点,并被标记为 y1。
-
如果 D 中的记录属于多个类标签,则会采用特征测试条件将记录划分为更小的子集。假设在初始运行时,我们对所有属性进行特征测试条件,并找到一个能够将数据集划分为三个子集的属性。这个属性就成为根节点。我们对这三个子集应用测试条件,以找出下一层的节点。这个过程是迭代进行的。
请注意,当我们定义分类时,我们定义了三个类别标签 y1、y2 和 y3。与前两个食谱中我们只处理了两个标签的问题不同,这是一个多类问题。我们在大多数食谱中使用的鸢尾花数据集就是一个三类问题。我们的记录分布在三个类别标签之间。我们可以将其推广到 n 类问题。数字识别是另一个例子,我们需要将给定图像分类为零到九之间的某个数字。许多现实世界的问题本质上就是多类问题。一些算法也天生可以处理多类问题。对于这些算法,无需进行任何修改。我们将在各章节中讨论的算法都能处理多类问题。决策树、朴素贝叶斯和 KNN 算法擅长处理多类问题。
让我们看看如何利用决策树来处理这个食谱中的多类问题。理解决策树的原理也有助于此。随机森林是下一章我们将探讨的一种更为复杂的方法,它在行业中被广泛应用,且基于决策树。
现在让我们深入了解决策树的使用方法。
准备就绪
我们将使用鸢尾花数据集来演示如何构建决策树。决策树是一种非参数的监督学习方法,可以用来解决分类和回归问题。如前所述,使用决策树的优点有很多,具体如下:
-
它们易于解释
-
它们几乎不需要数据准备和特征转换:请记住我们在前一个食谱中的特征生成方法
-
它们天然支持多类问题
决策树并非没有问题。它们存在的一些问题如下:
-
它们很容易发生过拟合:在训练集上表现出高准确率,而在测试数据上表现很差。
-
可以为给定数据集拟合出数百万棵树。
-
类别不平衡问题可能会对决策树产生较大影响。类别不平衡问题出现在我们的训练集在二分类问题中未包含相等数量的实例标签时。这个问题在多类问题中也同样适用。
决策树的一个重要部分是特征测试条件。让我们花些时间理解特征测试条件。通常,我们的实例中的每个属性可以被理解为以下之一。
二元属性:这是指一个属性可以取两个可能的值,比如 true 或 false。在这种情况下,特征测试条件应该返回两个值。
名义属性:这是指一个属性可以取多个值,比如 n 个值。特征测试条件应该返回 n 个输出,或者将它们分组为二元拆分。
顺序属性:这是指属性的值之间存在隐含的顺序关系。例如,假设我们有一个虚拟属性叫做 size,它可以取小、中、大这三个值。这个属性有三个值,并且它们之间有顺序:小、中、大。它们由特征属性测试条件处理,这类似于名义属性的处理方式。
连续属性:这些是可以取连续值的属性。它们会被离散化为顺序属性,然后进行处理。
特征测试条件是一种根据叫做“杂质”的标准或度量,将输入记录拆分为子集的方法。这个杂质是相对于每个属性在实例中的类别标签计算的。贡献最大杂质的属性被选为数据拆分属性,或者换句话说,就是树中该层的节点。
让我们通过一个例子来解释它。我们将使用一种叫做熵的度量来计算杂质。
熵的定义如下:
其中:
让我们考虑一个例子:
X = {2,2}
现在我们可以根据这个集合计算熵,如下所示:
这个集合的熵为 0。熵为 0 表示同质性。在 Python 中编写熵计算非常简单。看一下以下的代码示例:
import math
def prob(data,element):
"""Calculates the percentage count of a given element
Given a list and an element, returns the elements percentage count
"""
element_count =0
# Test conditoin to check if we have proper input
if len(data) == 0 or element == None \
or not isinstance(element,(int,long,float)):
return None
element_count = data.count(element)
return element_count / (1.0 * len(data))
def entropy(data):
""""Calcuate entropy
"""
entropy =0.0
if len(data) == 0:
return None
if len(data) == 1:
return 0
try:
for element in data:
p = prob(data,element)
entropy+=-1*p*math.log(p,2)
except ValueError as e:
print e.message
return entropy
为了找到最佳的分割变量,我们将利用熵。首先,我们将根据类别标签计算熵,如下所示:
让我们定义另一个术语,称为信息增益。信息增益是一种衡量在给定实例中哪个属性对区分类别标签最有用的度量方法。
信息增益是父节点的熵与子节点的平均熵之间的差值。在树的每一层,我们将使用信息增益来构建树:
en.wikipedia.org/wiki/Information_gain_in_decision_trees
我们将从训练集中的所有属性开始,计算整体的熵。让我们来看以下的例子:
前面的数据集是为用户收集的虚拟数据,用来帮助他了解自己喜欢什么类型的电影。数据集包含四个属性:第一个属性是用户是否根据主演决定观看电影,第二个属性是用户是否根据电影是否获得奥斯卡奖来决定是否观看,第三个属性是用户是否根据电影是否票房成功来决定是否观看。
为了构建前面示例的决策树,我们将从整个数据集的熵计算开始。这是一个二类问题,因此 c = 2。并且,数据集共有四条记录,因此整个数据集的熵如下:
数据集的总体熵值为 0.811。
现在,让我们看一下第一个属性,即主演属性。对于主演为 Y 的实例,有一个实例类别标签为 Y,另一个实例类别标签为 N。对于主演为 N 的实例,两个实例类别标签均为 N。我们将按如下方式计算平均熵:
这是一个平均熵值。主演为 Y 的记录有两条,主演为 N 的记录也有两条;因此,我们有 2/4.0 乘以熵值。
当对这个数据子集计算熵时,我们可以看到在两个记录中,主演 Y 的一个记录的类别标签为 Y,另一个记录的类别标签为 N。类似地,对于主演为 N,两个记录的类别标签均为 N。因此,我们得到了该属性的平均熵。
主演属性的平均熵值为 0.5。
信息增益现在是 0.811 – 0.5 = 0.311。
同样地,我们将找到所有属性的信息增益。具有最高信息增益的属性胜出,并成为决策树的根节点。
相同的过程将重复进行,以便找到节点的第二级,依此类推。
如何操作…
让我们加载所需的库。接下来,我们将编写两个函数,一个用于加载数据,另一个用于将数据拆分为训练集和测试集:
from sklearn.datasets import load_iris
from sklearn.cross_validation import StratifiedShuffleSplit
import numpy as np
from sklearn import tree
from sklearn.metrics import accuracy_score,classification_report,confusion_matrix
import pprint
def get_data():
"""
Get Iris data
"""
data = load_iris()
x = data['data']
y = data['target']
label_names = data['target_names']
return x,y,label_names.tolist()
def get_train_test(x,y):
"""
Perpare a stratified train and test split
"""
train_size = 0.8
test_size = 1-train_size
input_dataset = np.column_stack([x,y])
stratified_split = StratifiedShuffleSplit(input_dataset[:,-1], \
test_size=test_size,n_iter=1,random_state = 77)
for train_indx,test_indx in stratified_split:
train_x = input_dataset[train_indx,:-1]
train_y = input_dataset[train_indx,-1]
test_x = input_dataset[test_indx,:-1]
test_y = input_dataset[test_indx,-1]
return train_x,train_y,test_x,test_y
让我们编写函数来帮助我们构建和测试决策树模型:
def build_model(x,y):
"""
Fit the model for the given attribute
class label pairs
"""
model = tree.DecisionTreeClassifier(criterion="entropy")
model = model.fit(x,y)
return model
def test_model(x,y,model,label_names):
"""
Inspect the model for accuracy
"""
y_predicted = model.predict(x)
print "Model accuracy = %0.2f"%(accuracy_score(y,y_predicted) * 100) + "%\n"
print "\nConfusion Matrix"
print "================="
print pprint.pprint(confusion_matrix(y,y_predicted))
print "\nClassification Report"
print "================="
print classification_report(y,y_predicted,target_names=label_names)
最后,调用我们定义的所有其他函数的主函数如下:
if __name__ == "__main__":
# Load the data
x,y,label_names = get_data()
# Split the data into train and test
train_x,train_y,test_x,test_y = get_train_test(x,y)
# Build model
model = build_model(train_x,train_y)
# Evaluate the model on train dataset
test_model(train_x,train_y,model,label_names)
# Evaluate the model on test dataset
test_model(test_x,test_y,model,label_names)
它是如何工作的…
我们从主函数开始。我们在 x、y 和 label_names 变量中调用 get_data 来检索鸢尾花数据集。我们获取标签名称,以便在看到模型准确性时,可以根据单个标签进行衡量。如前所述,鸢尾花数据集是一个三类问题。我们需要构建一个分类器,可以将任何新实例分类为三种类型之一:setosa、versicolor 或 virginica。
一如既往,get_train_test返回分层的训练和测试数据集。然后,我们利用 scikit-learn 中的StratifiedShuffleSplit获取具有相等类标签分布的训练和测试数据集。
我们必须调用build_model方法,在我们的训练集上构建决策树。scikit-learn 中的DecisionTreeClassifier类实现了一个决策树:
model = tree.DecisionTreeClassifier(criterion="entropy")
如你所见,我们指定了我们的特征测试条件是使用criterion变量来设置的熵。然后,我们通过调用fit函数来构建模型,并将模型返回给调用程序。
现在,让我们继续使用test_model函数来评估我们的模型。该模型接受实例x、类标签y、决策树模型model以及类标签名称label_names。
scikit-learn 中的模块度量提供了三种评估标准:
from sklearn.metrics import accuracy_score,classification_report,confusion_matrix
我们在前面的步骤和引言部分定义了准确率。
混淆矩阵打印了引言部分定义的混淆矩阵。混淆矩阵是一种评估模型表现的好方法。我们关注的是具有真正例和假正例值的单元格值。
最后,我们还有classification_report来打印精确度、召回率和 F1 得分。
我们必须首先在训练数据上评估模型:
我们在训练数据集上做得非常好,准确率达到了 100%。真正的考验是使用测试数据集,那里才是决定成败的地方。
让我们通过使用测试数据集来查看模型评估:
我们的分类器在测试集上的表现也非常出色。
还有更多…
让我们探查一下模型,看看各个特征如何有助于区分不同类别。
def get_feature_names():
data = load_iris()
return data['feature_names']
def probe_model(x,y,model,label_names):
feature_names = get_feature_names()
feature_importance = model.feature_importances_
print "\nFeature Importance\n"
print "=====================\n"
for i,feature_name in enumerate(feature_names):
print "%s = %0.3f"%(feature_name,feature_importance[i])
# Export the decison tree as a graph
tree.export_graphviz(model,out_file='tree.dot')
决策树分类器对象提供了一个属性feature_importances_,可以调用它来获取各个特征对构建我们模型的重要性。
我们写了一个简单的函数get_feature_names,用于获取特征名称。不过,这也可以作为get_data的一部分来添加。
让我们来看一下打印语句的输出:
这看起来好像花瓣宽度和花瓣长度在我们的分类中贡献更大。
有趣的是,我们还可以将分类器构建的树导出为 dot 文件,并使用 GraphViz 包进行可视化。在最后一行,我们将模型导出为 dot 文件:
# Export the decison tree as a graph
tree.export_graphviz(model,out_file='tree.dot')
你可以下载并安装 Graphviz 包来可视化它:
另请参见
-
为模型构建准备数据的步骤见第六章,机器学习 I
-
查找最近邻的步骤见第六章,机器学习 I
-
在第六章中,使用朴素贝叶斯分类文档的技巧,机器学习 I

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}