Core development for absolute beginners.
Table of Contents
Prerequisites: basic C, Git, GNU Make and SQL knowledge, feeling comfortable working within the Linux terminal.
This article is a proper aggregation of the information already available at the time of writing. My goal is not to duplicate information, but to lead you through it step by step. It is important to do it as you read it.
First, learn to compile and install PostgreSQL.
Go to git.postgresql.org, find postgresql.git and git clone that repository. A build system is used to compile PostgreSQL, the build system is responsible for finding the dependencies/libraries on disk and enabling/disabling features. PostgreSQL versions 16 and newer use the Meson build system, 15 and older rely on GNU Autoconf.
Different build systems require different commands to compile the source code. A simple online search would give this page showing you how to compile PostgreSQL. Here is a quick Meson and Autoconf command reference.
You will have to gather stack traces a lot, so you must compile PostgreSQL with -Og -g flags to instruct C compiler to add debug symbols and not to optimize the code beyond sufficient: meson setup -debug=true -Dbuildtype=debugoptimized .... These are the defaults, but it is nice to be aware of them.
To be able to work with multiple major versions simultaneously, create a git worktree per each major version. This allows one to work with multiple branches at the same time. With worktrees there is no need to commit/stash changes, resolve conflicts, or lose build artifacts to switch branches.
Visit all the URLs, make sure you understand the commands you have to enter. Compile and install all the currently supported major PostgreSQL versions, satisfy the dependencies if needed. Install under $HOME, not /usr, to avoid sudo. Have a quick walk throughout the source tree, cd to the root folder of the repository and observe tree -d -L 5 | less output. Have a look at git tag and git branch --remote. Use online search to figure out how to run unit tests, and where to find the entire compilation output.
Read about PostgreSQL versioning policy. You will notice they support five major versions at a time.
This is what the folder structure looks like when you install multiple PostgreSQL major versions:
To be able to execute PostgreSQL binaries by name, you have to add the appropriate bin folder to your $PATH. For the development purposes it is also necessary to switch bin directories quickly, without doing export PATH="$PATH:/whatever/path. Here is a shell function to serve that particular purpose:
Append the above function to your ~/.bashrc or ~/.zshrc, and reload your shell config. If you want to work with PostgreSQL 17, run pgenv 17 in your terminal window. To change the version, just call it again with a different number. To verify it works, invoke which pg_config to see which one is going to be executed.
pg_ctl -D /path/to/cluster/dir start is usually used to start PostgreSQL. To run the server in the foreground and see the logs, start the server binary directly postgres -D /path/to/cluster/dir. Specifying -D gets annoying, as is telling psql what database to connect to. Define PGDATA, PGDATABASE, and the other environment variables in order to bypass that. I have the following attached to pgenv function body:
Now it is postgres instead of postgres -D /path/to/cluster, and psql instead of psql database_name.
Before you start contributing code to PostgreSQL, it is easier to begin with extension development in C. Let us create an extension to define a function that returns a string:
To create such an extension we need to write:
Makefile.Save as my_extension.c:
Save as my_extension--1.0.sql:
Save as my_extension.control:
Here are all the possible values.
Run pg_config binary, and observe the output:
As you can see, it knows all about our PostgreSQL installation. You can ask pg_config to print out only the information you want:
Notice --libdir value is what $libdir in control file will expand to. Have a look at --pgxs value, it is a path to a Makefile. Open it and read the first few lines:
The above tells us we do not have to write recipes in order to compile a PostgreSQL extension. Instead, we have to define some variables and include this file.
Look further down to see how to include this file:
Basically, the above asks pg_config where to find --pgxs file and includes it. PG_CONFIG variable is defined to be able to supply custom path to pg_config binary.
Look further down to see the variables you can define within the Makefile you are going to write:
I will not include the full list, go see for yourself. So, now that we know how to write the Makefile for our extension, let us actually write it down:
Save all the four files, invoke make to build the extension, make install to install it. (Re)start the server, connect with psql to it, then invoke CREATE EXTENSION my_extension;. Now you can call the function from the extension with SELECT postgres_func();
At this point you should look around, investigate, make sure you understand everything you have just read. Most importantly, try to break things, observe the errors, then fix them. Look at other extensions to see what else you can do, try to install and use them, notice the differences in the process, some of them require more than CREATE EXTENSION ...;. Try to break other extensions, see what happens if you do not follow all the steps outlined in the installation requirements. Download this extension template I created and study it, it has things I will not mention in this article.
There is no outlined procedure on how to do it, and there is no precise definition of prerequisites either. There can only be a an everlasting list of advice to follow.
A good way to get your feet wet is to participate in reviewing code during commit fests.
Read these PostgreSQL Wiki pages:
First thing you absolutely have to do is to read this book, it is the greatest overview of PostgreSQL internals out there. The book itself is brief, feels more like a series of articles, and to the point.
Read Git commit messages that introduce the code snippets you are working with, it is usually the best source of information.
PostgreSQL Doxygen is pointless.
Third source of useful information are README files scattered across the source tree, use find to find them:
Your effort is all good, but it is crucial to reach out to other people for help. Join mailing lists, attend conferences, connect with other developers using whatever means. I would judge PostgreSQL community as civilized, I have never seen hostility, so do not hesitate asking.
The following is not a strict list, it is legal to adjust it to your preferences/environment.
Working with PostgreSQL source code, you would have to navigate a large Git repository. You may find git bisect useful for finding a particular commit that introduced a given code snippet, though it may not always work. git log -S'code_line' /path/to/file sometimes also helps to identify commits. git blame will help you identify the latest commit to edit a particular line. git cherry-pick will help you to re-apply a series of commits (a patch) to a different branch. I like cherry-pick because it never fails, it wants you to manually resolve conflicts on the way rather than abort the whole thing.
Have a look at a number of random PostgreSQL project function bodies:
Notice the code style, each function name is at the beginning of the line and is followed by ( character. It means you can find any function's body by name across the entire source tree:
grep tells us the file path and the line number, and it works with any function. As Neovim allows specifying the line number to jump to, I can reach that function directly with nvim +115 src/backend/access/bash/bash.c. In fact, this can even be scripted:
There is a function named init_custom_variable(...) somewhere within the source tree. To immediately open its body in my text editor I just have to type ffunc init custom variable. ffunc script will grep the function, parse its location and open it in my Neovim.
Code comments atop function definitions are extremely helpful, which is why you must configure your code editor to be able to quickly jump to them:
Meson compilations of PostgreSQL yield compile_commands.json, take a peek at it:
It is literally the entire sequence of compilation commands, it will help our code editor to natigate the source tree. Miscrosoft released Language Server Protocol specification, it is a standard for code completion/navigation. For any text editor to provide code completion and advanced features like code actions, or jumping to definitions in any language, it only has to speak LSP. Text editors support LSP either natively or via plugins. Neovim, for instance, supports LSP natively. Clang toolchain provides clangd, the language server for C and C++. This particular language server requires the aforementioned compile_commands.json to work.
In summary, for code completion and navigation you need:
compile_commands.json, generated by Meson.compile_commands.json gets generated by Meson for PostgreSQL builds, but it does not work with extensions at the moment. And, obviously, it will not work with PostgreSQL versions 15 and older, as they do not use Meson. Bear can generate compile commands for arbitrary projects, including PostgreSQL extensions; simply start the build like that: bear -- make.
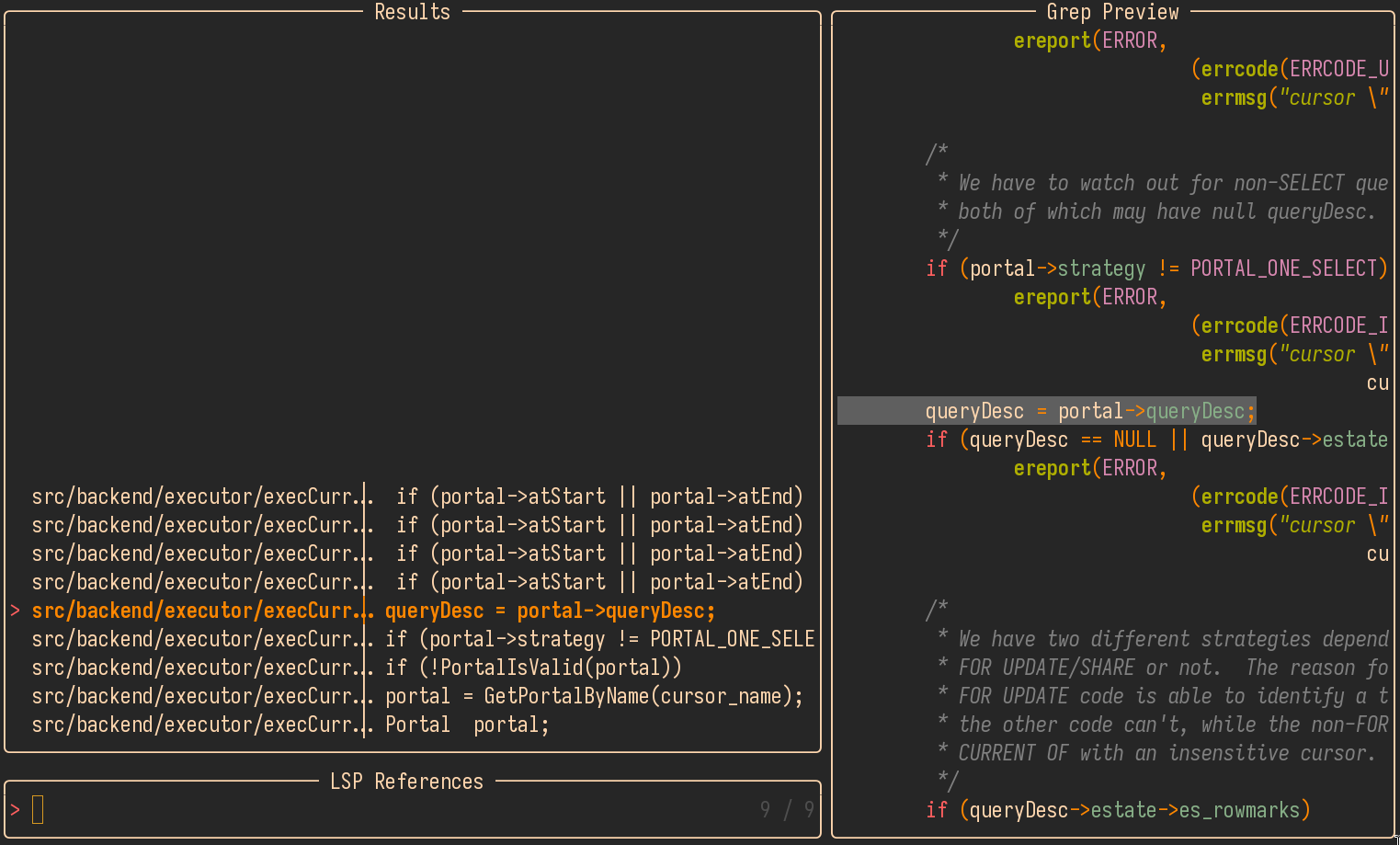
Here is LSP in action, it allows me to see all the references of portal variable:
Tree-sitter is super helpful in navigating the code. It is a generic language parser and syntax tree generator. It integrates well with text/code editors. Among many things it provides a proper syntax highlight based on syntax tree (not regular expressions) and allows navigating the project symbols:

Now you are familiar with the basics of PostgreSQL development. Being a good database administrator is not necessary for being a good database developer. Also, there are no people who know all about PostgreSQL, neither developers, nor administrators. Developers in particular, quite often, specialize in certain areas of PostgreSQL.
Leave a Reply