Build Text To Image with HuggingFace Diffusers
Last Updated :
09 Apr, 2025
This article will implement the Text 2 Image application using the Hugging Face Diffusers library. We will demonstrate two different pipelines with 2 different pre-trained Stable Diffusion models. Before we dive into code implementation, let us understand Stable Diffusion.
What is Stable Diffusion?
With the advancement of AI in the Image and Video domain, one might come across a word called Stable Diffusion that can perform tasks such as Text-to-Image, Text-to-Video, Image-to-Video, Image-to-Image and so on. To understand Stable Diffusion as a whole, it all started as a cutting-edge text-to-image latent diffusion model developed collaboratively by researchers and engineers associated with CompVis, Stability AI, and LAION. The model originated from the research paper "High-Resolution Image Synthesis with Latent Diffusion Models" written by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. The fundamental idea behind latent diffusion revolves around implementing the diffusion process within a lower-dimensional latent space, effectively addressing the challenges posed by memory and computational demands in high-resolution image synthesis.
Working and Pre-trained Models
Stable Diffusion is trained on 512x512 images from a particular part of the LAION-5B dataset. Importantly, it uses a fixed OpenAI's CLIP ViT-L/14 text encoder to guide the model with text instructions. Despite its impressive features, the model stays lightweight with an 860M UNet and a 123M text encoder, making it run smoothly on regular consumer GPUs.
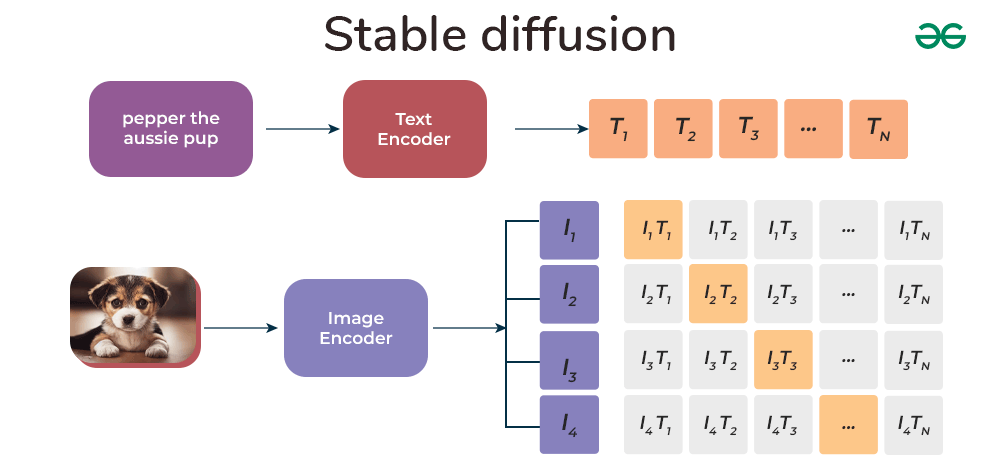
Since training the model is not affordable by everyone, one relies on pre-trained models. Now that we know, we are supposed to use pre-trained models, but where do we get the access to this model weights?
Hugging Face comes to the rescue. Hugging Face Hub is a cool place with over 120K+ models, 75K+ datasets, and 150K+ spaces (demo apps), all free and open to everyone.
Hugging Face Diffusers
In order to implement Stable Diffusion model using GitHub repository is not beginner friendly. To make it more appealing to the user HuggingFace released Diffusers, an open-source repository for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Further just like HuggingFace transformers, even diffusers support various pipelines which makes running state-of-art models run withing one-two lines of code.
Pipeline is the easiest way to use a pretrained diffusion system for running the inference. It is an end-to-end system containing the model and the scheduler. The pipeline works on cleaning up an image by introducing random noise matching the desired output size and running it through the model multiple times. In each step, the model anticipates the residual noise, and the scheduler utilizes this information to generate a less noisy image.
So, let's go build now.
Installation
! pip install diffusers accelerate
Note:
We are dealing with high computation when we need to run the Stable Diffusion Pipeline using Diffusers. In order to run the notebook, you need to change the runtime to GPU.
- Click on Runtime in Colab Notebook.
- Select change runtime type.
- Choose T4 GPU from the Hardware accelerator options.
Approach-1 Using StableDiffusionPipeline
In approach-1 we will use simple Stable Diffusion pipeline using a pre-trained model open sourced by RunwayML.
Import required Libraries
Python
import torch
from diffusers import StableDiffusionPipeline
Create Stable Diffusion Pipeline
In the StableDiffusionPipeline, the single-line process involves specifying the pre-trained model within the pipeline, where it internally loads both the model and scheduler. Additionally, to optimize computational efficiency, the inference is executed using floating-point 16-bit precision instead of 32-bit. Furthermore, the pipeline is converted to CUDA to ensure that the inference runs on the GPU.
Python
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
Define prompt and run Pipeline
Now, users have the flexibility to define their custom prompts and directly pass the text to the pipeline. The outcome will generate a list object containing the generated images.
Python
prompt = "a horse racing near beach, 8k, realistic photography"
image = pipe(prompt).images[0]
image
Output:
.webp) Output from Stable-diffusion-v1
Output from Stable-diffusion-v1
Great, I hope you got better results with your prompt. Let's proceed with the final approach in this article.
Before you proceed to next approach, make sure to create a new notebook. Now again switch the runtime to GPU. If you run both the approaches in same notebook, it will hit memory and give you error.
Approach-2 Using AutoPipelineForText2Image
In order to use task-oriented pipeline, Diffusers also provide AutoPipeline, where we have more flexibility in running inference by enabling the use_safetensors to directly load weights. By automatically identifying the appropriate pipeline class, the AutoPipeline eliminates the need to know the exact class name, simplifying the process of loading a checkpoint for a given task.
Import required Libraries
Python
import torch
from diffusers import AutoPipelineForText2Image
Create Auto Pipeline for Text to Image
The syntax is similar as approach-1, but here we also define use_safetensors to be True and variant to run on floating point 16-bit precision. Notice one change, here we are using the Stabel Diffusion XL pre-trained model, which is the most advanced model in the current date.
Python
pipe = AutoPipelineForText2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipe = pipe.to("cuda")
Define prompt and run Pipeline
Use the same prompt and check the response quality between the base model (v1.5) and advanced model (xl).
Python
prompt = "a horse racing near beach, 8k, realistic photography"
image = pipe(prompt=prompt).images[0]
image
Output:
 Output from Stable-diffusion-XL
Output from Stable-diffusion-XLStable Diffusion XL gives more accurate result compared to Stable Diffusion v1.5 as in prompt we mentioned beach, but v1.5 doesn't have beach in its image. With this we conclude.
Conclusion
Finally, we conclude how you can get started with Text2Image application using HuggingFace Diffusers library. Using pipelines, it makes it super simple to implement Stable Diffusion applications. Similarity you can use different pipelines to implement ControlNet, Text2Video, Image2Image and so on. The only required thing is get the pre-trained model, write a good prompt, execute and run the pipeline.
Similar Reads
Text-to-Image using Stable Diffusion HuggingFace Model
Models available through HuggingFace utilize advanced machine-learning techniques for a variety of applications, from natural language processing to computer vision. Recently, they have expanded to include the ability to generate images directly from text descriptions, prominently featuring models l
3 min read
Mastering 3D Scene Creation with stable-fast-3d Model Huggingface
Stable-Fast-3D, available on Hugging Face's Spaces, represents an advanced approach in the realm of 3D scene generation using AI. This model extends the capabilities of Stable Diffusion into the 3D space, enabling users to create intricate and detailed 3D scenes from textual descriptions. In this ar
3 min read
Text-to-Video Synthesis using HuggingFace Model
The emergence of deep learning has brought forward numerous innovations, particularly in natural language processing and computer vision. Recently, the synthesis of video content from textual descriptions has emerged as an exciting frontier. Hugging Face, a leader in artificial intelligence (AI) res
6 min read
How to use Hugging Face with LangChain ?
Hugging Face is an open-source platform that provides tools, datasets, and pre-trained models to build Generative AI applications. We can access a wide variety of open-source models using its API. With the Hugging Face API, we can build applications based on image-to-text, text generation, text-to-i
3 min read
Generate Images from Text in Python - Stable Diffusion
Looking for the images can be quite a hassle don't you think? Guess what? AI is here to make it much easier! Just imagine telling your computer what kind of picture you're looking for and voila it generates it for you. That's where Stable Diffusion, in Python, comes into play. It's like magic – tran
7 min read
How to convert any HuggingFace Model to gguf file format?
Hugging Face has become synonymous with state-of-the-art machine learning models, particularly in natural language processing. On the other hand, the GGUF file format, though less well-known, serves specific purposes that necessitate the conversion of models into this format. This article provides a
3 min read
Build Your Own Face Recognition Tool With Python
From unlocking smartphone to tagging friends on social media face recognition is everywhere. But have you ever wondered how it works? Well, you don’t need to be a computer science expert to create your own face recognition tool. With Python and some basic libraries, you can build one from scratch. T
4 min read
HuggingFace Spaces: A Beginner’s Guide
HuggingFace Spaces is a comprehensive ecosystem designed to facilitate creating, sharing, and deploying machine learning models. This platform is tailored to accommodate novice and experienced AI practitioners, providing tools and resources that streamline the development process. This article will
6 min read
How to Access HuggingFace API key?
HuggingFace is a widely popular platform in the AI and machine learning community, providing a vast range of pre-trained models, datasets, and tools for natural language processing (NLP) and other machine learning tasks. One of the key features of HuggingFace is its API, which allows developers to s
4 min read
How to Add Image to Background of Plot with Seaborn
Adding an image to the background of a plot increases its visual appeal and can provide contextual information or branding. Seaborn, combined with Matplotlib, offers several techniques to achieve this effect seamlessly. In this article, we will explore the approach to add an image to the background
4 min read