Categorical Encoding with CatBoost Encoder
Last Updated :
09 Mar, 2021
Many machine learning algorithms require data to be numeric. So, before training a model, we need to convert categorical data into numeric form. There are various categorical encoding methods available. Catboost is one of them. Catboost is a target-based categorical encoder. It is a supervised encoder that encodes categorical columns according to the target value. It supports binomial and continuous targets.
Target encoding is a popular technique used for categorical encoding. It replaces a categorical feature with average value of target corresponding to that category in training dataset combined with the target probability over the entire dataset. But this introduces a target leakage since the target is used to predict the target. Such models tend to be overfitted and don't generalize well in unseen circumstances.
A CatBoost encoder is similar to target encoding, but also involves an ordering principle in order to overcome this problem of target leakage. It uses the principle similar to the time series data validation. The values of target statistic rely on the observed history, i.e, target probability for the current feature is calculated only from the rows (observations) before it.
Categorical feature values are encoded using the following formula:
\frac{TargetSum+prior}{FeatureCount+1}
TargetCount: Sum of the target value for that particular categorical feature (upto the current one).
Prior: It is a constant value determined by (sum of target values in the whole dataset)/(total number of observations (i.e. rows) in the dataset)
FeatureCount: Total number of categorical features observed upto the current one with the same value as the current one.
With this approach, the first few observations in the dataset always have target statistics with much higher variance than the successive ones. To reduce this effect, many random permutations of the same data are used to calculate target statistics and the final encoding is calculated by averaging across these permutations. So, if the number of permutations is large enough, the final encoded values obey the following equation:
\frac{TargetSum+prior}{FeatureCount+1}
TargetCount: Sum of the target value for that particular categorical feature in the whole dataset.
Prior: It is a constant value determined by (sum of target values in the whole dataset)/(total number of observations (i.e. rows) in the dataset)
FeatureCount: Total number of categorical features observed in the whole dataset with the same value as the current one.
For Example, if we have categorical feature column with values
color=["red", "blue", "blue", "green", "red", "red", "black", "black", "blue", "green"] and target column with values, target=[1, 2, 3, 2, 3, 1, 4, 4, 2, 3]
Then, prior will be 25/10 = 2.5
For the "red" category, TargetCount will be 1+3+1 = 5 and FeatureCount = 3
And hence, encoded value for “red” will be (5+2.5) /(3+1)=1.875
Syntax:
category_encoders.cat_boost.CatBoostEncoder(verbose=0,
cols=None, drop_invariant=False, return_df=True,
handle_unknown='value', handle_missing='value',
random_state=None, sigma=None, a=1)
Parameters:
- verbose: Verbosity of the output, i.e., whether to print the processing output on the screen or not. 0 for no printing, positive value for printing the intermediate processing outputs.
- cols: A list of features (columns) to be encoded. By default, it is None indicating that all columns with an object data type are to be encoded.
- drop_invariant: True means drop columns with zero variance (same value for each row). False, by default.
- return_df: True to return a pandas dataframe from transform, False will return numpy array instead. True, by default.
- handle_missing: Way of handling missing (not filled) values. error generates missing value error, return_nan returns NaN and value returns the target mean. Default is value.
- handle_unknown: Way of handling unknown (undefined) values. Options are the same as handle_missing parameter.
- sigma: It is used to decrease overfitting. Training data is added with normal distribution noise whereas testing data are left untouched. sigma is the standard deviation of that normal distribution.
- a: Float value for additive smoothing. It is needed for scenarios when attributes or data points weren’t present in the training data set but may be present in the testing data set. By default, it is set to 1. If it is not 1, the encoding equation after including this smoothing parameter takes the following form: \frac{TargetSum+prior}{FeatureCount+a}
The encoder is available as CatBoostEncoder in categorical-encodings library. This encoder works similar to scikit-learn transformers with .fit_transform(), .fit() and .transform() methods.
Example:
Python3
# import libraries
import category_encoders as ce
import pandas as pd
# Make dataset
train = pd.DataFrame({
'color': ["red", "blue", "blue", "green", "red",
"red", "black", "black", "blue", "green"],
'interests': ["sketching", "painting", "instruments",
"sketching", "painting", "video games",
"painting", "instruments", "sketching",
"sketching"],
'height': [68, 64, 87, 45, 54, 64, 67, 98, 90, 87],
'grade': [1, 2, 3, 2, 3, 1, 4, 4, 2, 3], })
# Define train and target
target = train[['grade']]
train = train.drop('grade', axis = 1)
# Define catboost encoder
cbe_encoder = ce.cat_boost.CatBoostEncoder()
# Fit encoder and transform the features
cbe_encoder.fit(train, target)
train_cbe = cbe_encoder.transform(train)
# We can use fit_transform() instead of fit()
# and transform() separately as follows:
# train_cbe = cbe_encoder.fit_transform(train,target)
Output:
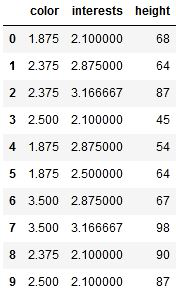 Dataset after Catboost encoding (train_cbe)
Dataset after Catboost encoding (train_cbe)
Similar Reads
Handling categorical features with CatBoost
Handling categorical features is an important aspect of building Machine Learning models because many real-world datasets contain non-numeric data which should be handled carefully to achieve good model performance. From this point of view, CatBoost is a powerful gradient-boosting library that is sp
10 min read
CatBoost's Categorical Encoding: One-Hot vs. Target Encoding
CatBoost is a powerful gradient boosting algorithm that excels in handling categorical data. It incorporates unique methods for encoding categorical features, including one-hot encoding and target encoding. Understanding these encoding techniques is crucial for effectively utilizing CatBoost in mach
6 min read
Fuel Efficiency Forecasting with CatBoost
The automobile sector is continuously looking for new and creative ways to cut fuel use in its pursuit of economy, and sustainability. Comprehending car fuel usage has become more crucial due to the increase in gas costs and the increased emphasis on environmental sustainability. A technique for thi
7 min read
Elevating Movie Recommendations with CatBoost
In todays digital era, Offering the customers with what they need plays a crucial role in marketing. When it comes to streaming platforms it is even more difficult to find a perfect movie to watch from a overwhelming array of choices. However, with advancements in machine learning techniques like Ca
6 min read
Enhancing CatBoost Model Performance with Custom Metrics
CatBoost, a machine learning library developed by Yandex, has gained popularity due to its superior performance on categorical data, fast training speed, and built-in support for various data preprocessing techniques. While CatBoost offers a range of standard evaluation metrics, leveraging custom me
4 min read
Visualize the Training Parameters with CatBoost
CatBoost is a powerful gradient boosting library that has gained popularity in recent years due to its ease of use and high performance. One of the key features of CatBoost is its ability to visualize the training parameters, which can be extremely useful for understanding how the model is performin
5 min read
Introduction to CatBoost
CatBoost is a potent gradient-boosting technique developed for excellent performance and support for categorical features. Yandex created CatBoost, which is notable for its capacity to handle categorical data without requiring a lot of preprocessing. With little need for parameter adjustment, it pro
10 min read
Categorical Data Encoding Techniques in Machine Learning
Machine learning algorithms perform more effectively with numeric values, so categorical data must be converted into a numerical format. In this article, we'll explore various techniques for encoding categorical data.Categorical data refers to variables that take on a limited set of values or catego
5 min read
Transform Text Features to Numerical Features with CatBoost
Handling text and category data is essential to machine learning to create correct prediction models. Yandex's gradient boosting library, CatBoost, performs very well. It provides sophisticated methods to convert text characteristics into numerical ones and supports categorical features natively, bo
4 min read
Implementing an Autoencoder in PyTorch
Autoencoders are neural networks designed for unsupervised tasks like dimensionality reduction, anomaly detection and feature extraction. They work by compressing data into a smaller form through an encoder and then reconstructing it back using a decoder. The goal is to minimize the difference betwe
4 min read