What is a Dataset: Types, Features and Examples
Last Updated :
30 Sep, 2025
A dataset is a structured collection of related data, usually organized in rows and columns that represents information about a specific category or domain. It forms the foundation for many operations, techniques and models used across industries.
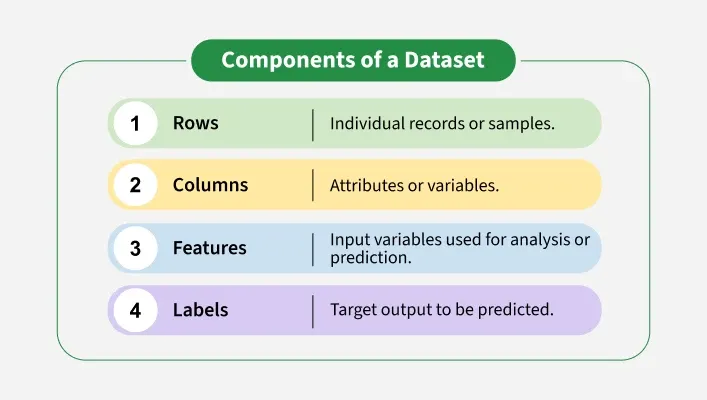 Components
ComponentsFor example, A student dataset may include rows for each student and columns for attributes like name, age, grade and marks.
Importance of Dataset
Some reasons why datasets are important in analysis and machine learning are:
- Analysis: Provide the raw material required for analysis and decision making.
- Training Machine Learning Models: Enable the training and testing of machine learning and AI models.
- Discover Patterns and Correlations: Help uncover patterns, correlations and insights across domains.
- Innovation: Support research and development in industries like healthcare, finance and education.
- Evaluation and Standards: Allow reproducibility and benchmarking in academic and professional projects.
Types of Dataset
There are various types of datasets available out there. Some of them are:
- Numerical Dataset: Contains numeric data points that can be analyzed using mathematical or statistical methods. For example temperature dataset.
- Categorical Dataset: Represents discrete categories or groups such as color, gender, occupation or sports.
- Time Series Dataset: Records data over a period of time to track trends or changes. For example stock prices.
- Ordered Dataset: Contains ranked or ordinal data where the order matters but not the exact difference between values. Example can be customer reviews, survey ratings or movie rankings.
- Image Dataset: Consists of images used for classification, recognition or analysis tasks. For example medical imaging for disease detection.
- Web Dataset: Collected from APIs or web sources, usually stored in structured formats like JSON for further analysis.
- File based Dataset: Stored in files such as CSV, Excel (.xlsx) or text files for easy access and manipulation.
Properties of Dataset
Here are the key properties that define a dataset:
- Center of Data: Refers to the "middle" value of a dataset, usually measured using mean, median or mode. It helps identify where most of the values lie and gives a sense of the average data point.
- Skewness of Data: This indicates how symmetrical the data distribution is. A perfectly symmetrical distribution like a normal distribution has a skewness of 0 while positive or negative skewness indicates a tilt in one direction.
- Spread: This describes how much the data points vary from the center. Common measures include standard deviation or variance, which quantify how far individual points deviate from the average.
- Outliers: These are data points that fall significantly outside the overall pattern. Identifying outliers can be important as they might influence analysis results and require further investigation.
- Correlation: It shows how strongly variables are related. A positive correlation means both increase together, a negative correlation means they move in opposite directions and no correlation means no clear relationship.
- Probability distribution: Understanding the distribution like normal, uniform, binomial helps us predict how likely it is to find certain values within the data and choose appropriate statistical methods for analysis.
Features of a Dataset
Some possible features of a dataset are:
- Numerical Features: These may include numerical values such as height, weight and so on. These may be continuous over an interval or discrete variables.
- Categorical Features: These include multiple classes or categories such as gender, colour and so on.
- Size of the Data: It refers to the number of entries and features it contains in the file containing the Dataset.
- Data Entries: These refer to the individual values of data present in the Dataset.
- Target Variable: This is the main feature in a dataset that we want to predict or explain using the other features.
Loading and Analysing
In this example, German Credit Risk Dataset is used to cluster people in Germany based on some features as those with good credit scores or poor credit scores using Excel.
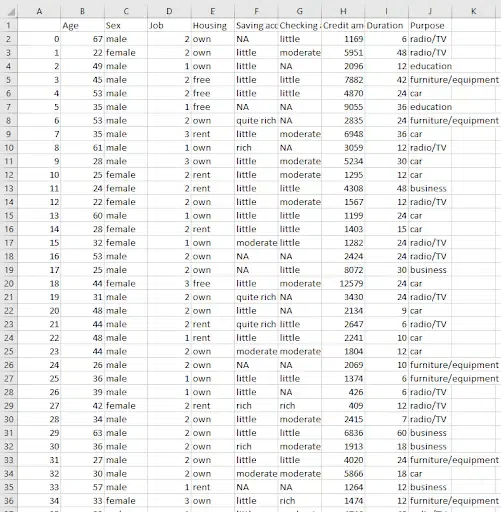 Dataset
Dataset Analysis
AnalysisOperations of Datasets
Some of the core operations of datasets in pandas and numpy in python are:
1. Loading and Reading Datasets:
Bringing data into your environment from CSV, JSON, SQL, APIs, etc.
Techniques: read_csv(), read_json(), read_excel(), etc.
2. Exploratory Data Analysis:
Understanding the dataset through summaries, distributions and patterns.
Techniques: head(), tail(), groupby(), etc
3. Data Preprocessing:
Data Preprocessing include cleaning, handling missing values, encoding, scaling and preparing data for use.
Techniques: drop(), fillna(), dropna(), copy(), etc
4. Data Manipulation:
Modifying or transforming data like filtering, grouping, merging, reshaping.
Techniques: merge(), concat(), join(), etc
5. Data Visualization:
Representing data with plots, charts or dashboards to uncover insights.
Techniques: plot()
6. Data Indexing:
Efficiently accessing and organizing data like row or column labels, keys or indices.
Techniques: iloc()
7. Export Data:
Saving processed data into formats like CSV, Excel, JSON or databases for future use.
Techniques: to_csv(), to_json(), etc
Data vs Datasets vs Database
Comparison table among data, dataset and database is mentioned below:
Aspect | Data | Dataset | Database |
|---|
Definition | Raw facts or basic information without context. | A structured collection of related data entries. | An organized collection of datasets stored systematically. |
Structure | Unorganized, lacks inherent structure. | Organized into rows and columns | Organized into tables, often across multiple dimensions |
Role | Backbone for datasets and databases. | Structures data and provides meaningful insights. | Defines relationships between features extensively. |
Manipulation | Cannot be manipulated directly due to lack of structure. | Can be analyzed or visualized using tools like Tableau, Power BI, Python. | Can be manipulated with queries, transactions and scripts. |
Usage | Needs preprocessing and transformation before use | Used for data analysis, modeling and visualization. | Used for querying, transactions and managing applications. |
- Data: Individual pieces of information such as numbers, categories or features. Alone, it cannot be analyzed effectively.
- Datasets: A collection of related, structured or unstructured data used for analysis or model building.
- Database: A system that stores multiple datasets, related or unrelated and allows querying for different applications.
Challenges in Working with Dataset
Common challenges faced when working with datasets are:
- Quality Issues: Poorly collected or inconsistent data can mislead analysis and reduce the accuracy of models.
- Missing Data: Incomplete records create gaps that make it harder to draw reliable conclusions or train models effectively.
- Bias: When datasets are unbalanced or unrepresentative, the resulting models may produce unfair or skewed outcomes.
- Scalability: Very large datasets can be challenging to clean, store and process efficiently with limited resources.
- Privacy Concerns: Sensitive or personal data requires strict handling to ensure compliance with privacy and security standards.
Applications of Dataset
Here are some of the applications of dataset:
- Machine Learning Training: Datasets are used to train models for tasks like image recognition, natural language processing or fraud detection.
- Business Analytics: Companies analyze sales, customer and financial datasets to make informed decisions.
- Healthcare: Patient records, medical images and genomic datasets support disease diagnosis and treatment planning.
- Education and Research: Public datasets help students and researchers experiment validate hypotheses and build new solutions.
- Recommendation Systems: Datasets of user behavior like purchases, clicks, ratings are used to suggest products, movies or music.
Getting Started with Datasets in Python
Explore
Introduction to Machine Learning
Python for Machine Learning
Introduction to Statistics
Feature Engineering
Model Evaluation and Tuning
Data Science Practice