Data Replication in DBMS refers to the process of storing copies of the same data at multiple sites or nodes within a distributed database system. The main purpose of replication is to improve data availability, reliability, performance and fault tolerance. In a distributed database environment, data replication ensures that:
- Users can access relevant data locally,
- The system remains operational even if some sites fail and
- The workload is balanced across servers.
Note: It involves copying data from one database (known as the source or publisher) to another (known as the replica, subscriber or target) so that all users can access consistent and up-to-date information without conflicts.
Need of Data Replication
Data replication is used for several reasons:
- To increase data availability in case of server failure.
- To enhance performance by allowing data to be accessed from local copies.
- To improve reliability and fault tolerance in distributed systems.
- To support load balancing, where read operations are distributed across replicas.
- To simplify disaster recovery and backup processes.
Types of Data Replication
1. Transactional Replication
Transactional replication involves sending an initial full copy of the database to subscribers, followed by real-time updates as changes occur at the publisher.
- Changes are propagated in the same order as they happen, ensuring transactional consistency.
- It is ideal for server-to-server environments that require high accuracy and reliability.
Example: Banking systems or e-commerce sites that demand consistent and up-to-date transaction data.
2. Snapshot Replication
Snapshot replication copies and distributes data exactly as it exists at a specific point in time, without tracking changes.
- It sends the entire dataset to subscribers periodically.
- Suitable for databases where data changes infrequently.
Drawback: Can be slower because it replicates the entire dataset each time.
3. Merge Replication
Merge replication allows both the publisher and subscriber to make changes independently.
- Changes are later merged into a single database.
- It is complex but useful in mobile or client-server environments, where users work offline and synchronize later.
Example: Field data collection systems or distributed applications where clients update data locally.
4. Master-Slave Replication
In this architecture:
- One database server is designated as the master and
- One or more servers are designated as slaves.
Note: The master handles all write operations and the slaves receive read-only copies from the master. This model ensures data consistency and simplifies synchronization.
5. Multi-Master Replication
All servers act as masters, meaning that updates can occur at any node and changes are replicated across all other nodes.
- Suitable for large distributed systems that require high availability and update flexibility.
- However, it requires conflict detection and resolution mechanisms.
6. Peer-to-Peer Replication
Every server acts as both a master and a slave, with data replicated in a peer-to-peer manner.
- Commonly used in distributed databases where each node can handle both reads and writes.
- Ensures redundancy and high availability.
7. Single Source Replication
In this type, a single source database replicates data to multiple target databases.
- Ideal for centralized data control with distributed read access.
- Simplifies consistency but increases load on the source server.
Replication Schemes
1. Full Replication
In full replication, the entire database is replicated at every site. Offers maximum availability and faster local access. However, it increases storage requirements and update complexity.
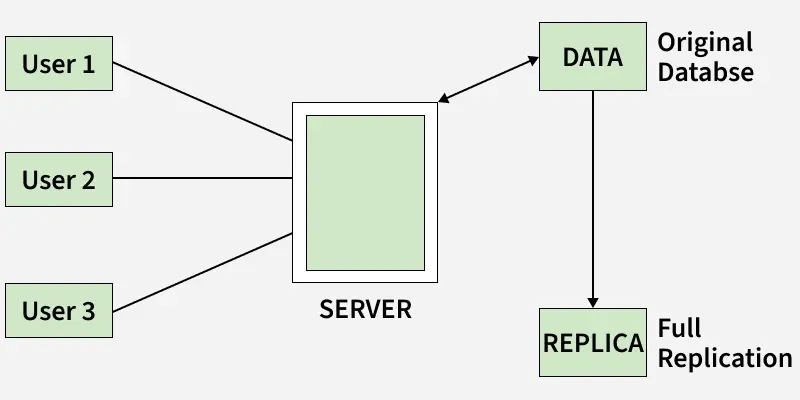 Full Replication
Full ReplicationAdvantages:
- High data availability
- Faster query execution (local access)
- Improved performance for global queries
Disadvantages:
- Difficult concurrency management
- Slow update propagation
- High storage and network costs
- Complex consistency maintenance
2. No Replication
In no replication, each data item is stored at only one location in the distributed system.
Advantages:
- Reduced concurrency issues
- Simplified recovery and management
Disadvantages:
- Poor data availability (single point of failure)
- Slower query response due to centralized access
3. Partial Replication
In partial replication, only selected fragments of the database are replicated based on their importance or access frequency. Balances between storage efficiency and availability.
Advantages:
- Optimized storage
- Flexibility based on data importance
- Better performance for critical data
Disadvantages:
- Complex management and configuration
- Possible inconsistent data access across sites
Advantages of Data Replication
- Improved Performance: Data can be read from local replicas instead of remote servers.
- Increased Availability: Copies can serve users even during failures.
- Improved Scalability: Reduces load on the primary database by distributing reads.
- Faster Response Times: Users can access nearby replicas for quicker queries.
- Enhanced Reliability: Multiple copies protect against data loss or corruption.
Disadvantages of Data Replication
- Increased Complexity: Requires careful configuration and synchronization.
- Risk of Inconsistency: Simultaneous updates at multiple sites may cause conflicts.
- Higher Storage and Bandwidth Usage: Multiple copies consume more resources.
- Maintenance Overhead: Managing and monitoring replication processes add administrative cost.
- Update Conflicts: Changes in one node may need complex conflict-resolution rules.
Applications: Online Transaction Processing (OLTP), Data Warehousing and Analytics, Distributed Database Systems, Content Delivery Networks (CDNs), Cloud-based and High-Availability Systems, etc.
What is replication in distributed databases?
-
Dividing tables into fragments
-
Linking databases via joins
-
Copying data to multiple sites
-
Explanation:
Replication creates multiple copies of data to improve availability and fault tolerance.
Which replication technique allows multiple replicas to accept updates?
Explanation:
Multi-primary replication increases throughput by allowing updates on multiple replicas.
In a master–slave replication setup, which situation most commonly increases replication lag?
-
Slave performing only read operations
-
Master receiving a burst of write-heavy transactions
-
Network bandwidth between nodes is highly under-utilized
-
Slave using a stronger consistency model than the master
Explanation:
Heavy write load on the master increases the delay before updates can propagate to the slave.
In a distributed system using multi-master replication, what is the primary challenge when a node fails temporarily?
-
Increased data redundancy
-
Conflict resolution during reintegration
-
-
Reduced checkpoint frequency
Explanation:
When the failed master rejoins, updates made during downtime must be merged, causing potential conflicts.
Quiz Completed Successfully
Your Score : 2/4
Accuracy : 0%
Login to View Explanation
1/4
1/4
< Previous
Next >
Explore
Basics of DBMS
ER & Relational Model
Relational Algebra
Functional Dependencies & Normalisation
Transactions & Concurrency Control
Advanced DBMS
Practice Questions