Introduction of Shadow Paging
Last Updated :
15 Jul, 2025
Shadow paging is a fundamental recovery technique used in database management systems (DBMS) to ensure the reliability and consistency of data. It plays a crucial role in maintaining atomicity and durability which are the two core properties of transaction management. Unlike log-based recovery mechanisms that rely on recording detailed logs of changes, shadow paging offers a simpler, log-free approach by maintaining two versions of the database state: the shadow page table and the current page table. This technique is also known as Cut-of-Place updating.
This technique ensures that a database can recover seamlessly from failures without losing data integrity. During a transaction, updates are made to a new version of the database pages tracked by the current page table, while the shadow page table preserves the pre-transaction state. This dual-table approach allows for efficient crash recovery and simplifies the commit and rollback processes.
Page Table : A page table is a data structure that maps logical pages (a logical division of data) to physical pages (actual storage on disk).
- Each entry in the page table corresponds to a physical page location on the disk.
- The database uses the page table to retrieve or modify data.
How Shadow Paging Works ?
Shadow paging is a recovery technique that views the database as a collection of fixed-sized logical storage units, known as pages, which are mapped to physical storage blocks using a structure called the page table. The page table enables the system to efficiently locate and manage database pages.
Here’s how shadow paging works in detail:
Start of Transaction:
- The shadow page table is created by copying the current page table.
- The shadow page table represents the original, unmodified state of the database.
- This table is saved to disk and remains unchanged throughout the transaction.
| Logical Page | Shadow Page Table (Disk) | Current Page Table |
|---|
| P1 | Address_1 | Address_1 |
| P2 | Address_2 | Address_2 |
| P3 | Address_3 | Address_3 |
Transaction Execution:
- Updates are made to the database by creating new pages.
- The current page table reflects these changes, while the shadow page table remains unchanged.
Page Modification:
If a logical page (e.g. P2) needs to be updated:
- A new version of the page (P2’) is created in memory and written to a new physical storage block.
- The current page table entry for P2 is updated to point to P2’.
- The shadow page table still points to the original page P2, ensuring it is unaffected by the changes.
| Logical Page | Shadow Page Table (Disk) | Current Page Table |
|---|
| P1 | Address_1 | Address_1 |
| P2 | Address_2 | Address_4 (P2') |
| P3 | Address_3 | Address_3 |
Commit:
- If the transaction is successful, the shadow page table is replaced by the current page table.
- This replacement makes the changes permanent.
| Logical Page | Shadow Page Table (Disk) | Current Page Table |
|---|
| P1 | Address_1 | Address_1 |
| P2 | Address_4 (P2') | Address_4 (P2') |
| P3 | Address_3 | Address_3 |
Abort:
- If the transaction is aborted, the current page table is discarded, leaving the shadow page table intact.
- Since the shadow page table still points to the original pages, no changes are reflected in the database.
Consider the below example:
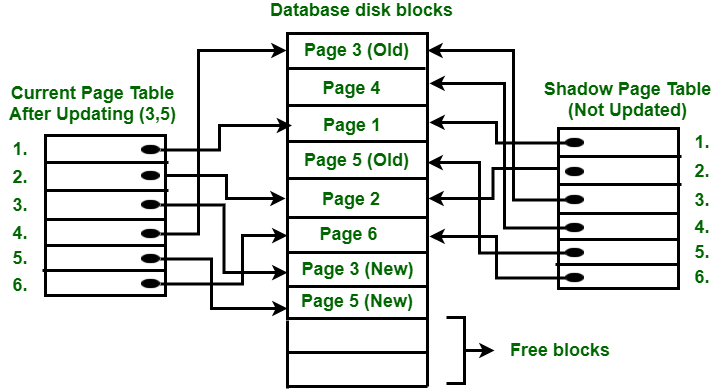
To understand concept, consider above figure. In this 2 write operations are performed on page 3 and 5. Before start of write operation on page 3, current page table points to old page 3. When write operation starts following steps are performed :
- Firstly, search start for available free block in disk blocks.
- After finding free block, it copies page 3 to free block which is represented by Page 3 (New).
- Now current page table points to Page 3 (New) on disk but shadow page table points to old page 3 because it is not modified.
- The changes are now propagated to Page 3 (New) which is pointed by current page table.
COMMIT Operation : To commit transaction following steps should be done :
- All the modifications which are done by transaction which are present in buffers are transferred to physical database.
- Output current page table to disk.
- Disk address of current page table output to fixed location which is in stable storage containing address of shadow page table. This operation overwrites address of old shadow page table. With this current page table becomes same as shadow page table and transaction is committed.
Failure : If the system crashes during the execution of a transaction but before the commit operation, it is sufficient to free the modified database pages and discard the current page table. The database state can be restored to its pre-transaction condition by reinstalling the shadow page table. If the system crashes after the final write operation, the changes made by the transaction remain unaffected. These changes are preserved, and there is no need to perform a redo operation.
How Shadow Paging different from Log-Based Recovery?
- Log-based recovery creates log records with fields such as the data item identifier, transaction identifier, new value, and old value. In contrast, shadow paging uses a structure based on fixed-size disk pages.
- The search process in log-based recovery can be time-consuming, whereas shadow paging is faster as it eliminates the overhead of managing log records.
- Log-based recovery requires only one block to complete a single transaction, while shadow paging often needs multiple blocks to commit a single transaction.
- Additionally, shadow paging may disrupt the locality of pages, whereas log-based recovery preserves this property.
Advantages of Shadow Paging
- Fewer Disk Accesses: Requires fewer disk operations to perform tasks.
- Fast Recovery: Crash recovery is quick and inexpensive, with no need for Undo or Redo operations.
- Improved Fault Tolerance: Transactions are isolated, so a failure in one transaction does not affect others.
- Increased Concurrency: Changes are made to shadow copies, allowing multiple transactions to run simultaneously without interference.
- Simplicity: Easy to implement and integrate into existing database systems.
- No Log Files: Eliminates the need for log files, reducing overhead and improving efficiency.
Disadvantages of Shadow Paging
- High Commit Overhead: A large number of pages need to be flushed during the commit process, increasing the overhead.
- Data Fragmentation: Related pages may become separated, leading to fragmentation.
- Garbage Collection Required: After each transaction, pages containing old versions of modified data must be garbage collected and added to the list of unused pages.
- Limited Concurrency: Extending the algorithm to support concurrent transactions is challenging.
Conclusion
Shadow paging is a method used in databases to recover data and ensure it stays accurate and reliable during transactions. It works by keeping two copies of the database state: the shadow page table and the current page table. This makes it possible to recover from system crashes quickly without needing complex processes like log files.
Shadow paging is simple to use and helps in situations where fast recovery is important. However, it has some downsides, such as requiring more effort to commit changes, causing data to become scattered, and making it harder to handle many transactions at the same time. Despite these challenges, it is an effective method for managing data in systems where its features are a good fit.
Explore
Basics of DBMS
ER & Relational Model
Relational Algebra
Functional Dependencies & Normalisation
Transactions & Concurrency Control
Advanced DBMS
Practice Questions