How to Delete Duplicate Rows in MariaDB
Last Updated :
12 Mar, 2024
Duplicate rows in a database can lead to data inconsistencies and inefficiencies. In MariaDB, we can remove duplicate rows using various methods to ensure data integrity and optimize database performance.
In this article, We will explore different techniques to identify and delete duplicate rows in MariaDB with the help of examples and so on.
How to Delete Duplicate Rows in MariaDB
Duplicate rows in a database can lead to data inconsistencies and inefficiencies, impacting database performance and integrity. MariaDB provides several methods to identify and delete duplicate rows. Below are the methods that help us to delete duplicate rows in MariaDB are as follows:
- Using DELETE Statement
- Using Subquery
- Using Temporary Table
Let's set up an environment
To understand How to delete duplicate rows in MariaDB we need a table on which we will perform various operations and queries. Here we will consider a table called indian_states which contains id, state_name, capital, and population as Columns.
We can see our table has been created successfully.
 States Table
States TableIdentify Duplicate Rows
Identify the duplicate rows in our table by executing the below steps:
Using GROUP BY and HAVING Clause: Construct a query grouping by the columns which define uniqueness and filter using the HAVING clause to identify rows having a count greater than one.
SELECT state_name, capital, COUNT(*) FROM States GROUP BY state_name, capital HAVING COUNT(*) > 1;
This query will group the records by state_name and capital, and then it will count the number of occurrences for each group. Finally, it will only return the groups where the count is greater than 1, indicating duplicate entries based on the combination of state_name and capital.
Output:
 Duplicate rows
Duplicate rowsExplanation: As we can see that there are two duplicate rows in our table.
1. Using DELETE Statement
After identifying duplicate rows, remove them using the DELETE statement. Ensure you have a backup before executing the delete operation.
DELETE FROM indian_states
WHERE id NOT IN (
SELECT MIN(id)
FROM indian_states
GROUP BY state_name, capital
);
Output:
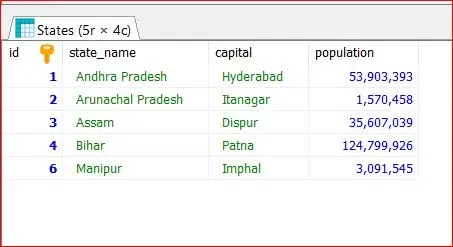 Duplicates Removed
Duplicates RemovedExplanation: This query selects the minimum id for each unique combination of state_name and capital, and then deletes all rows from the indian_states table where the id is not the minimum id for that combination. As we can see that there are no duplicates in our table.
This effectively keeps only one instance of each unique combination and removes duplicates.
2. Using Subquery
We’ll assume that the table has been restored to its original state (with the duplicates).
DELETE FROM States
WHERE (state_name, capital, id) NOT IN (
SELECT state_name, capital, MIN(id)
FROM States
GROUP BY state_name, capital
);
Output:
Duplicates RemovedExplanation: This query deletes rows from the States table where the combination of state_name and capital is not associated with the minimum id value for each combination. This effectively retains only one instance of each unique combination and removes duplicates. Now there are no duplicates in our States table.
3. Using Temporary Table
We’ll assume that the table has been restored to its original state (with the duplicates).
Create a temporary table with distinct records and then overwrite the original table with the temporary one.
-- Create a temporary table with distinct rows
CREATE TABLE temp_states AS SELECT DISTINCT * FROM states;
-- Drop the original states table
DROP TABLE states;
-- Rename the temporary table to replace the original states table
ALTER TABLE temp_states RENAME TO states;
Output:
Duplicates RemovedExplanation:
- CREATE TABLE temp_table AS SELECT DISTINCT * FROM states;: This statement creates a new table temp_table with the distinct rows from the states table. All columns and their data types will be copied from the original states table.
- DROP TABLE states;: This statement removes the original states table from the database. All data and table structure will be permanently deleted.
- ALTER TABLE temp_table RENAME TO states;: This statement renames the newly created temp_table to states, effectively replacing the original table with the deduplicated data.
- After executing these SQL statements, the states table will contain only distinct rows, and the original table will be replaced. Only unique values are there.
Conclusion
Overall, It is very important to choose a good strategy for automatic removal of the overlapping rows in a MariaDB database as it will ensure that the data integrity of the system stays on a high level and its performance is optimized. with the implementation of the specified tools, administrators can correctly identify, delete, and prevent replicated entries thus can maintain a uncomplicated database. You should always be aware of the dangers that might arise if you lose your data and try creating backups beforehand to ensure that in case of any accidental loss of data, you do not lose it completely.
Similar Reads
How to Delete Duplicate Rows in MySQL?
Duplicate rows are a common problem in MySQL databases. Duplicate rows can cause problems with data accuracy and integrity. They can also make it difficult to query and analyze data. Ways to Delete Duplicate Rows in MySQLThere are a few different ways to delete duplicate rows from tables in MySQL: U
4 min read
How to Delete Duplicate Rows in PL/SQL?
Inconsistencies and inefficiencies in data management are frequently caused by duplicate rows in a database table. Eliminating duplicate rows is a typical PL/SQL activity to maintain data integrity and improve database performance. This article will guide you on how to remove duplicated rows in PL/S
4 min read
How to delete duplicate rows in SQLite?
SQLite is an open-source and serverless database system that does not require any server to perform various queries also it is widely used in the development of embedded software like television and mobile phones Sometimes it might happen that we by mistake insert multiple times similar data into ta
3 min read
How to Delete Duplicate Records in Oracle Database?
Duplicate records in a database can lead to inefficiencies and incorrect query results. Oracle SQL provides several efficient methods for identifying and removing these duplicates, ensuring data accuracy and integrity. This article explains step-by-step how to remove duplicates using the ROWID, a un
3 min read
How to Remove All Duplicate Rows Except One in MariaDB?
Duplicate rows in database tables can lead to complexity and data integrity issues and affect performance. Removing all duplicate rows while keeping one instance of each unique row is important for maintaining a clean database. In this article, we will explore various methods with the help of exampl
5 min read
SQL Query to Delete Duplicate Rows
Duplicate rows in a database can cause inaccurate results, waste storage space, and slow down queries. Cleaning duplicate records from our database is an essential maintenance task for ensuring data accuracy and performance. Duplicate rows in a SQL table can lead to data inconsistencies and performa
6 min read
Delete Duplicate Rows in MS SQL Server
In MS SQL Server, managing duplicate rows is a common task that can affect the integrity and performance of a database. To address this issue, SQL Server provides several methods for identifying and deleting duplicate rows. In this article, We will explore three effective approaches: using the GROUP
5 min read
How to Find Duplicate Rows in PL/SQL
Finding duplicate rows is a widespread requirement when dealing with database analysis tasks. Duplicate rows often create problems in analyzing tasks. Detecting them is very important. PL/SQL is a procedural extension for SQL. We can write custom scripts with the help of PL/SQL and thus identifying
5 min read
How to Delete Blank Rows in Excel
How to Remove Empty Rows in Excel- Quick StepsSelect the data range.Press Ctrl + G >> Click Special >>Choose Blanks >> Click OK.Right-click on any blank cell >>Click Delete >>Choose Entire Row >> Click OK.Deleting blank rows in Excel is crucial for maintaining cle
10 min read
How to Fetch Duplicate Rows in a Table?
Identifying duplicate rows in a database table is a common requirement, especially when dealing with large datasets. Duplicates can arise due to data entry errors, system migrations, or batch processing issues. In this article, we will explain efficient SQL techniques to identify and retrieve duplic
3 min read