How to Partition a Queue in a Distributed Systems?
Last Updated :
23 Jul, 2025
In distributed systems, partitioning a queue involves dividing a single queue into multiple smaller queues to improve performance and scalability. This article explains how to efficiently split a queue to handle large volumes of data and traffic. By partitioning, tasks can be processed in parallel, reducing delays and preventing system overloads. Understanding queue partitioning helps in designing robust systems that can handle increasing workloads efficiently.
Important Topics to Understand How to Partition a Queue in a Distributed Systems?
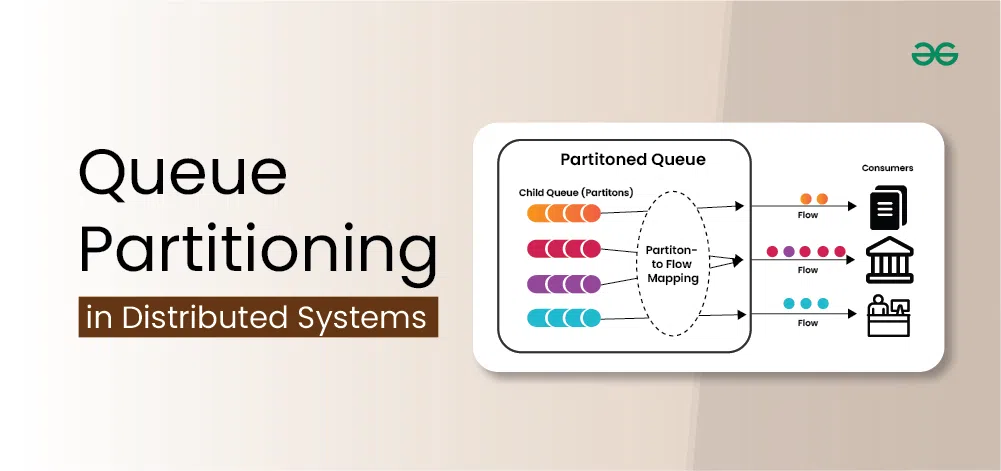
What is Queue Partitioning?

Queue partitioning in a distributed system is the process of dividing a single, large queue into multiple smaller queues to manage and process tasks more efficiently. In a distributed system, tasks or messages are often placed in a queue to be processed by different nodes or servers. When the volume of tasks grows, a single queue can become a bottleneck, leading to delays and decreased performance.
- By partitioning the queue, the workload is distributed across multiple queues, each handled by different servers or nodes.
- This allows tasks to be processed in parallel, improving the system's overall throughput and responsiveness. Queue partitioning helps in scaling the system to handle more tasks without overloading any single part of the system.
Key Benefits of Queue Partitioning
Below are some key benefits of queue partitioning:
- Improved Performance: By processing tasks in parallel across multiple queues, the system can handle more tasks simultaneously.
- Scalability: The system can grow by adding more partitions as the workload increases, without significantly redesigning the architecture.
- Fault Tolerance: If one partition fails, others can continue to operate, increasing the reliability of the system.
- Reduced Latency: With multiple queues, tasks can be processed more quickly, reducing the time they spend waiting in the queue.
Types of Queue Partitioning
In distributed systems, there are several types of queue partitioning strategies commonly used to manage and process tasks efficiently:
1. Static Partitioning
In this approach, the queue is divided into a fixed number of partitions during system setup or configuration. Each partition is assigned to a specific node or server in the system. Tasks are then distributed among these partitions based on predefined rules or algorithms. Static partitioning simplifies system management but may lead to uneven workload distribution if the workload varies over time.
2. Dynamic Partitioning
Unlike static partitioning, dynamic partitioning adjusts the number of partitions based on the current workload and system conditions. As the workload increases or decreases, partitions can be dynamically added or removed to balance the load across nodes or servers. Dynamic partitioning adapts to changing workload patterns, optimizing resource utilization and system performance.
3. Key-Based Partitioning
In key-based partitioning, tasks are assigned to partitions based on certain key attributes of the tasks. For example, tasks with similar characteristics or attributes are grouped together and routed to the same partition. This ensures that related tasks are processed by the same node or server, which can improve cache locality and reduce inter-node communication overhead.
4. Range-Based Partitioning
Range-based partitioning involves dividing the task queue into partitions based on predefined ranges of task attributes or identifiers. Each partition is responsible for processing tasks within a specific range of values. Range-based partitioning is often used in scenarios where tasks have a natural ordering or when tasks can be efficiently grouped based on certain criteria.
5. Hash-Based Partitioning
Hash-based partitioning involves applying a hash function to each task to determine which partition it should be routed to. The hash function generates a unique identifier for each task, which is used to distribute tasks evenly across partitions. Hash-based partitioning is commonly used in distributed databases and messaging systems to achieve uniform workload distribution and load balancing.
Partitioning Strategies
In a distributed system, partitioning strategies are crucial for efficiently managing data and workload distribution across multiple nodes or servers. Here are some common partitioning strategies:
- Key-Based Partitioning: Tasks or data are partitioned based on specific key attributes. Each partition is responsible for a range of keys, ensuring that related tasks or data are stored or processed together. This strategy is beneficial for workload isolation and can improve performance by reducing inter-node communication.
- Range-Based Partitioning: Data or tasks are partitioned into ranges based on certain criteria, such as numerical ranges or time intervals. Each partition is responsible for a specific range, enabling efficient querying or processing of data within that range. Range-based partitioning is useful when data has a natural ordering or when tasks can be grouped based on certain characteristics.
- Hash-Based Partitioning: Tasks or data are hashed using a hash function, and the resulting hash value determines the partition to which they belong. This strategy evenly distributes tasks or data across partitions, promoting load balancing and minimizing hotspots. Hash-based partitioning is commonly used in distributed databases and messaging systems.
- Round-Robin Partitioning: Tasks or data are distributed across partitions in a round-robin fashion, where each partition receives tasks or data in sequential order. This strategy ensures an even distribution of workload across partitions, making it suitable for scenarios with uniform task sizes or data distribution.
- Consistent Hashing: Consistent hashing is a variation of hash-based partitioning that minimizes data movement when the number of partitions changes. Each partition is assigned a range of hash values, and tasks or data are mapped to the partition responsible for the closest hash value. Consistent hashing is particularly useful in dynamic environments where partitions may be added or removed frequently.
Partitioning Algorithms
Queue partitioning in distributed systems requires efficient algorithms to distribute tasks or messages among multiple queues. Here are some commonly used partitioning algorithms:
- Round-Robin: Tasks are distributed among partitions in a round-robin fashion, where each new task is assigned to the next partition in sequence. This algorithm ensures an even distribution of workload across partitions, but it may not take into account the varying sizes or priorities of tasks.
- Hash-Based Partitioning: Tasks are hashed using a hash function, and the resulting hash value determines the partition to which they belong. This algorithm evenly distributes tasks across partitions based on their hash values, promoting load balancing and minimizing hotspots. Common hash functions include MD5, SHA-1, or MurmurHash.
- Key-Based Routing: Tasks are routed to partitions based on specific key attributes or identifiers. Each partition is responsible for processing tasks with certain key ranges, ensuring that related tasks are stored or processed together. Key-based routing is commonly used in distributed databases and messaging systems to maintain data locality and optimize query performance.
- Range-Based Partitioning: Tasks are partitioned into ranges based on certain criteria, such as numerical ranges or time intervals. Each partition is responsible for processing tasks within a specific range, enabling efficient querying or processing of data. Range-based partitioning algorithms vary depending on the type of range and the distribution of tasks.
- Consistent Hashing: Tasks are mapped to partitions using a consistent hashing function, which minimizes data movement when the number of partitions changes. Each partition is assigned a range of hash values, and tasks are routed to the partition responsible for the closest hash value. Consistent hashing algorithms ensure that tasks are evenly distributed across partitions and reduce the impact of partition changes on the system.
Integration with Distributed System Architecture
Queue partitioning integration within a distributed system architecture involves designing components and protocols to effectively manage and utilize partitioned queues across multiple nodes or servers. Here's how it can be integrated:
- Queue Management Service: Implement a centralized or distributed queue management service responsible for creating, monitoring, and managing partitioned queues. This service handles tasks such as partition creation, resizing, and deletion based on system load and requirements.
- Partition Coordination: Develop mechanisms for coordinating partition assignments and migrations across nodes in the distributed system. This includes protocols for adding new nodes, rebalancing partitions to maintain load balance, and handling node failures or departures.
- Load Balancing: Integrate load balancing mechanisms to evenly distribute tasks among partitions and nodes. This may involve dynamic routing of tasks based on workload or node capabilities, ensuring efficient resource utilization and system performance.
- Fault Tolerance: Design fault-tolerant mechanisms to ensure system resilience in the event of node failures or network partitions. This includes strategies such as data replication, partition replicas, or backup nodes to maintain data availability and consistency.
- Scalability: Ensure scalability by allowing the system to dynamically scale up or down based on workload demands. This involves automatic provisioning of additional nodes, partitions, or resources as needed, as well as efficient data migration and rebalancing to accommodate changes in system size.
Implementation Techniques
Below are the implementation of queue partitioning:
- Static Partitioning: Divide the queue into fixed partitions during system setup. Each partition is assigned to a specific node or server.
- Dynamic Partitioning: Adjust the number and size of partitions dynamically based on workload and system conditions.
- Hash-Based Partitioning: Apply a hash function to tasks or messages to determine their partition. Ensure even distribution of workload across partitions.
- Key-Based Partitioning: Route tasks to partitions based on specific key attributes or identifiers. Ensure related tasks are processed together within the same partition.
- Range-Based Partitioning: Partition tasks based on predefined ranges of attributes, such as numerical ranges or time intervals.
- Consistent Hashing: Use consistent hashing to minimize data movement when the number of partitions changes. Ensure tasks are evenly distributed and minimize the impact of partition changes.
- Load Balancing: Implement mechanisms to evenly distribute tasks among partitions and nodes, ensuring efficient resource utilization.
- Fault Tolerance: Design fault-tolerant mechanisms such as data replication or partition replicas to ensure data availability and consistency in case of node failures.
Use Cases and Examples
- Messaging Systems: Partition message queues based on message attributes or routing keys. This ensures that messages with similar characteristics are processed together, improving system efficiency. For example, Kafka uses partitioning to distribute message logs across multiple brokers in a Kafka cluster.
- Distributed Databases: Partition database tables or shards based on key attributes or ranges. This allows for parallel processing of queries and improves scalability. For instance, Apache Cassandra partitions data across nodes based on a consistent hashing algorithm to achieve horizontal scalability.
- Stream Processing: Partition event streams based on event attributes or keys to enable parallel processing of streaming data. This facilitates real-time analytics and processing of large-scale event streams. Apache Flink partitions data streams across parallel tasks for distributed processing.
- Task Queues: Partition task queues in distributed task processing systems to handle large volumes of tasks efficiently. Each partition can be assigned to a worker node for parallel task execution. Celery, a distributed task queue for Python, supports queue partitioning for scalable task processing.
- Load Balancers: Partition request queues in load balancers to evenly distribute incoming requests across backend servers. This improves request handling capacity and reduces response times. NGINX Plus, for example, supports queue partitioning for load balancing HTTP and TCP traffic across servers.
Conclusion
In conclusion, partitioning a queue in a distributed system involves dividing a large queue into smaller ones to enhance performance and scalability. This process helps manage large volumes of tasks more efficiently by enabling parallel processing, reducing delays, and preventing system overloads. Various partitioning strategies, such as static, dynamic, hash-based, and key-based partitioning, offer flexibility to meet different system requirements. Implementing effective queue partitioning ensures better load balancing, fault tolerance, and overall system efficiency.
Explore
OS Basics
Process Management
Memory Management
I/O Management
Important Links