IPC through shared memory
Last Updated :
10 Jan, 2025
Inter-Process Communication (IPC) is a fundamental concept in operating systems that allows multiple processes to communicate and synchronize their actions. Among the various methods of IPC shared memory is one of the most efficient mechanisms especially when it comes to performance-critical applications. This article delves into the concept of IPC through shared memory explaining its working, advantages, and disadvantages.
Inter-process Communication through shared memory is a concept where two or more processes can access the common memory and communication is done via this shared memory where changes made by one process can be viewed by another process.
The problem with pipes, fifo and message queue – is that for two processes to exchange information. The information has to go through the kernel.
- The server reads from the input file.
- The server writes this data in a message using either a pipe, FIFO, or message queue.
- The client reads the data from the IPC channel, again requiring the data to be copied from the kernel’s IPC buffer to the client’s buffer.
- Finally, the data is copied from the client’s buffer.
Four copies of data are required (2 read and 2 write). So, shared memory provides a way to let two or more processes share a memory segment. With Shared Memory the data is only copied twice from the input file into shared memory and from shared memory to the output file.
What is IPC?
Inter-Process Communication (IPC) refers to the set of techniques that allow the processes to exchange data and signals with one another. IPC is crucial for modern operating systems that support multitasking as it will enable the different methods to cooperate and share resources effectively. The Common IPC mechanisms include message passing, semaphores, pipes, signals, and shared memory.
What is Shared Memory?
The Shared memory is a memory segment that multiple processes can access concurrently. It is one of the fastest IPC methods because the processes communicate by the reading and writing to a shared block of the memory. Unlike other IPC mechanisms that involve the more complex synchronization and data exchange procedures shared memory provides the straightforward way for the processes to share data.
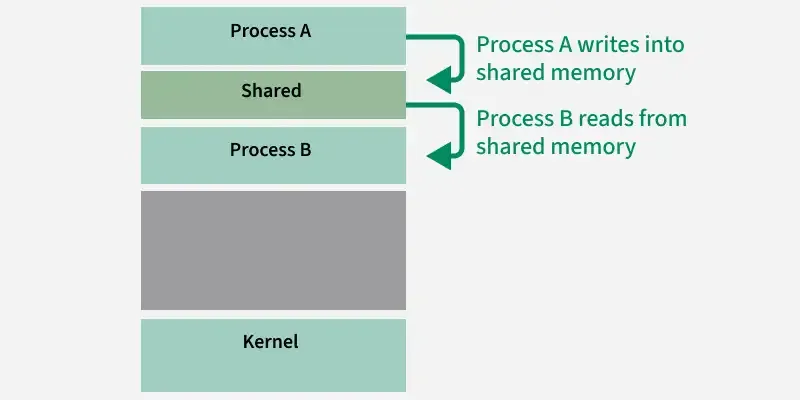
How Shared Memory IPC Works?
The Shared memory IPC works by creating a memory segment that is accessible by the multiple processes. Here's a basic outline of how it operates:
- Creation of Shared Memory Segment: A process usually the parent, creates a shared memory segment using the system calls like shmget() in Unix-like systems. This segment is assigned the unique identifier (shmid).
- Attaching to the Shared Memory Segment: The Processes that need to access the shared memory attach themselves to this segment using shmat() system call. Once attached the processes can directly read from and write to the shared memory.
- Synchronization: Since multiple processes can access the shared memory simultaneously synchronization mechanisms like semaphores are often used to the prevent race conditions and ensure data consistency.
- Detaching and Deleting the Segment: When a process no longer needs access to the shared memory it can detach from the segment using shmdt() system call. The shared memory segment can be removed entirely from system using shmctl() once all processes have the detached.
Advantages of Shared Memory IPC
- Speed: The Shared memory IPC is much faster than other IPC methods like message passing because processes directly read and write to the shared memory location.
- Low Overhead: It eliminates the overhead associated with the message passing where data has to be copied from the one process to another.
- Flexibility: The Shared memory can be used to share complex data structures like arrays, linked lists and matrices between the processes.
- Large Data Transfers: The Shared memory is particularly useful for the transferring large amounts of data between the processes as it avoids the need for the multiple data copies.
Disadvantages of Shared Memory IPC
- Complex Synchronization: The Shared memory requires explicit synchronization to the prevent race conditions which can make the code more complex and error-prone.
- Security Risks: Since shared memory is accessible by the multiple processes it can pose security risks if not managed properly as unauthorized processes may access or modify the data.
- Manual Cleanup: The Shared memory segments must be manually detached and removed which can lead to the resource leaks if not done correctly.
- Portability: The Shared memory IPC is platform-dependent and may not be easily portable across the different operating systems.
Used System Calls
The system calls that are used in the program are:
Function | Signature | Description |
|---|
| ftok() | key_t ftok() | It is used to generate a unique key. |
|---|
| shmget() | int shmget(key_t key,size_t size, int shmflg); | Upon successful completion, shmget() returns an identifier for the shared memory segment. |
|---|
| shmat() | void *shmat(int shmid ,void *shmaddr ,int shmflg); | Before you can use a shared memory segment, you have to attach yourself to it using shmat(). Here, shmid is a shared memory ID and shmaddr specifies the specific address to use but we should set it to zero and OS will automatically choose the address. |
|---|
| shmdt() | int shmdt(void *shmaddr); | When you’re done with the shared memory segment, your program should detach itself from it using shmdt(). |
|---|
| shmctl() | shmctl(int shmid,IPC_RMID,NULL); | When you detach from shared memory, it is not destroyed. So, to destroy shmctl() is used. |
|---|
Example Problem - Producer & Consumer
There are two processes: Producer and Consumer . The producer produces some items and the Consumer consumes that item. The two processes share a common space or memory location known as a buffer where the item produced by the Producer is stored and from which the Consumer consumes the item if needed. There are two versions of this problem: the first one is known as the unbounded buffer problem in which the Producer can keep on producing items and there is no limit on the size of the buffer, the second one is known as the bounded buffer problem in which the Producer can produce up to a certain number of items before it starts waiting for Consumer to consume it. We will discuss the bounded buffer problem. First, the Producer and the Consumer will share some common memory, then the producer will start producing items. If the total produced item is equal to the size of the buffer, the producer will wait to get it consumed by the Consumer. Similarly, the consumer will first check for the availability of the item. If no item is available, the Consumer will wait for the Producer to produce it. If there are items available, Consumer will consume them. The pseudo-code to demonstrate is provided below:
Shared Data Between the two Processes
C++
#define buff_max 25
#define mod %
struct item{
// different member of the produced data
// or consumed data
---------
}
// An array is needed for holding the items.
// This is the shared place which will be
// access by both process
// item shared_buff [ buff_max ];
// Two variables which will keep track of
// the indexes of the items produced by producer
// and consumer The free index points to
// the next free index. The full index points to
// the first full index.
int free_index = 0;
int full_index = 0;
Producer Process Code
C++
item nextProduced;
while(1){
// check if there is no space
// for production.
// if so keep waiting.
while((free_index+1) mod buff_max == full_index);
shared_buff[free_index] = nextProduced;
free_index = (free_index + 1) mod buff_max;
}
Consumer Process Code
C++
item nextConsumed;
while(1){
// check if there is an available
// item for consumption.
// if not keep on waiting for
// get them produced.
while((free_index == full_index);
nextConsumed = shared_buff[full_index];
full_index = (full_index + 1) mod buff_max;
}
In the above code, the Producer will start producing again when the (free_index+1) mod buff max will be free because if it is not free, this implies that there are still items that can be consumed by the Consumer so there is no need to produce more. Similarly, if free index and full index point to the same index, this implies that there are no items to consume.
Overall C++ Implementation:
C++
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
#define buff_max 25
#define mod %
struct item {
// different member of the produced data
// or consumed data
// ---------
};
// An array is needed for holding the items.
// This is the shared place which will be
// access by both process
// item shared_buff[buff_max];
// Two variables which will keep track of
// the indexes of the items produced by producer
// and consumer The free index points to
// the next free index. The full index points to
// the first full index.
std::atomic<int> free_index(0);
std::atomic<int> full_index(0);
std::mutex mtx;
void producer() {
item new_item;
while (true) {
// Produce the item
// ...
std::this_thread::sleep_for(std::chrono::milliseconds(100));
// Add the item to the buffer
while (((free_index + 1) mod buff_max) == full_index) {
// Buffer is full, wait for consumer
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
mtx.lock();
// Add the item to the buffer
// shared_buff[free_index] = new_item;
free_index = (free_index + 1) mod buff_max;
mtx.unlock();
}
}
void consumer() {
item consumed_item;
while (true) {
while (free_index == full_index) {
// Buffer is empty, wait for producer
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
mtx.lock();
// Consume the item from the buffer
// consumed_item = shared_buff[full_index];
full_index = (full_index + 1) mod buff_max;
mtx.unlock();
// Consume the item
// ...
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
int main() {
// Create producer and consumer threads
std::vector<std::thread> threads;
threads.emplace_back(producer);
threads.emplace_back(consumer);
// Wait for threads to finish
for (auto& thread : threads) {
thread.join();
}
return 0;
}
Note that the atomic class is used to make sure that the shared variables free_index and full_index are updated atomically. The mutex is used to protect the critical section where the shared buffer is accessed. The sleep_for function is used to simulate the production and consumption of items.
Conclusion
The Shared memory IPC is a powerful tool for the process communication offering the high speed and low overhead for the data exchange between the processes. However, it comes with the challenges related to synchronization, security and resource management. Understanding these aspects is crucial for the effectively implementing shared memory IPC in a multitasking environment.
Explore
OS Basics
Process Management
Memory Management
I/O Management
Important Links