Strong Consistency in System Design
Last Updated :
22 Oct, 2024
Strong consistency ensures that when data is updated, all users see that change immediately, no matter when or how they access it. This is essential for applications like banking systems, e-commerce platforms, and collaboration tools, where accuracy is critical.
What is Consistency?
Consistency refers to the property of ensuring that all nodes in a distributed system have the same view of the data at any given point in time, despite possible concurrent operations and network delays. In simpler terms, it means that when multiple clients access or modify the same data concurrently, they all see a consistent state of that data
Importance of Data Consistency in Systems
The system works in a trustworthy and predictable manner when the data is consistent. Regardless of when or how they access it, users expect the system to provide consistent results.
- Maintaining data consistency helps in preserving data integrity. It can be challenging to trust the accuracy and completeness of the information stored in the system when there is inconsistent data because it can result in data corruption.
- Users can trust that the information they're interacting with is correct and current when data is consistent. This encourages positive user experiences and builds confidence in the integrity of the system.
What is Strong Consistency?
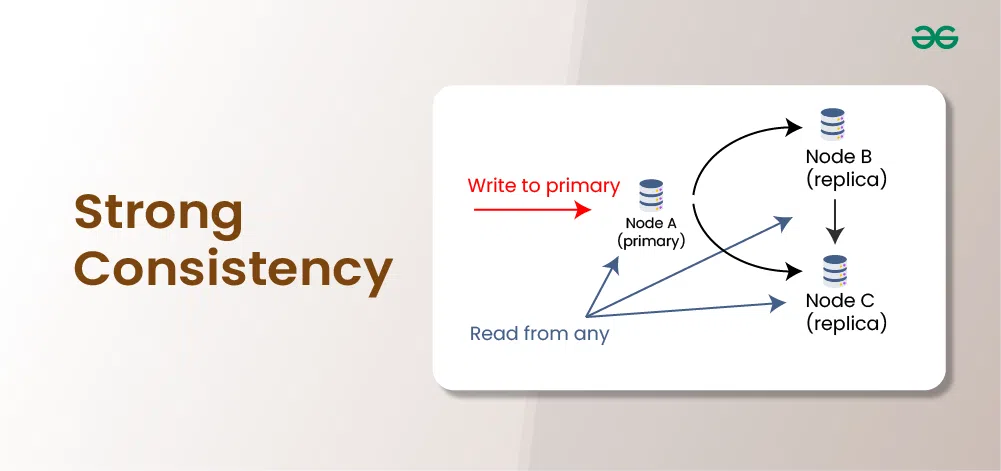
Strong consistency is a guarantee that all users see the same data at the same time, ensuring that any changes made to the data are immediately visible to everyone. This means that once a write operation is confirmed, any subsequent read operation will reflect that change, regardless of where or when it is accessed.

In distributed systems, strong consistency ensures that, regardless of where a node accesses the data, it is always visible to all nodes at the same time. This prevents any short-term inconsistencies because any changes made to the data are instantly reflected across all nodes. This indicates that, as if the system were a single, in order consistent entity, all read and write operations seem to happen instantly and in a linearizable order.
- Read consistency: Any read operation on the data will return the most recent write value or a value that satisfies specific consistency guarantees
- Write consistency: When a write operation is performed, the data will be propagated to all relevant nodes in the system, ensuring that all replicas are updated with the latest value before the operation is considered successful.
For example:
Banks and financial institutions operate on distributed databases to manage customer accounts, transactions, and other financial activities. Strong consistency ensures that all updates to these databases are immediately reflected across all nodes in the distributed system.
Characteristics of Strong Consistency
Below are some characteristics of Strong Consistency:
- Linearizability:
- Atomic consistency, or linearizability, is the property that guarantees all operations appear to happen instantaneously and atomically at a single point in time.
- It provides a global order for all operations that is consistent with a linear timeline, ensuring that every read operation returns either the most recent write or an error.
- Synchronization:
- Strong consistency calls for synchronization mechanisms, in order to ensure that every replica or node in the distributed system is updated simultaneously before any read operation.
- By guaranteeing that every node has an identical representation of the data, it removes the chance of old reads or inconsistent states amongst replicas.
- Instantaneous Visibility:
- Any write operation is guaranteed to become instantly visible to all following read operations with immediate visibility.
- It ensures that all clients or system nodes can view the updated data immediately upon the completion of a write operation.
Strong Consistency Comparison with Other Consistency Models
Consistency Model | Description | Key Characteristics | Advantages | Disadvantages |
|---|
Strong Consistency | Ensures that all replicas or nodes in the distributed system have the same view of the data at any given time. | Linearizability, Synchronization, Instantaneous Visibility, Consistency Guarantees, Simplicity and Predictability | Provides the strongest level of data consistency. | Higher latency due to synchronization mechanisms and Reduced availability under network partitions. |
|---|
Eventual Consistency | Allows replicas to diverge temporarily and resolves conflicts asynchronously. | Eventual Convergence, Asynchronous Conflict Resolution, Weaker Consistency Guarantees | Improved availability and partition tolerance. | May lead to temporarily inconsistent states. Also Requires conflict resolution mechanisms. |
|---|
Sequential Consistency | Preserves the order of operations from each client but doesn't guarantee a global order of operations. | Client, Specific Order, No Global Order | Simplicity in reasoning about data consistency. | May allow for inconsistencies between clients and does not ensure global ordering of operations. |
|---|
Causal Consistency | Preserves causal relationships between operations, allowing some operations to be reordered as long as they are causally related. | Causal Relationship Preservation, Some Operations May Be Reordered | Allows for more flexibility than strong consistency. | Requires understanding of causal relationships between operations. |
|---|
Eventual Consistency | A refined version of eventual consistency that ensures convergence of replicas within a specified time frame. | Eventual Convergence within a Specified Time Frame, Asynchronous Conflict Resolution, Weaker Consistency Guarantees | Improved predictability compared to eventual consistency, also balances consistency and availability. | Still requires conflict resolution mechanisms. It may not provide strong consistency guarantees within the time frame. |
|---|
Types of Strong Consistency
There are two main types of strong consistency:
- Sequential consistency: This is the strictest form of consistency, and it guarantees that all reads and writes appear to have been executed in a sequential order, even if they were issued from different processes or nodes in the system. In other words, it ensures that the outcome of any execution is the same as if all operations were executed one after the other in some sequential order.
- Linearizability: This is a slightly weaker form of consistency than sequential consistency. It guarantees that each operation appears to take effect instantaneously at some point in time, and that all processes agree on the order in which operations occurred. Linearizability is often considered to be the gold standard for consistency in distributed systems, but it can be more difficult to achieve than sequential consistency.
Ways to achieve Strong Consistency
Below are the common ways to achieve strong consistency:
- Linearizability (Atomic Consistency): This approach ensures that every action seems to happen at a single moment in time. It establishes a clear order for operations, so when you read data, you either see the most recent change or get an error.
- Synchronous Replication: This technique makes sure that when data is written, it gets sent to all replicas before the user gets a confirmation. This ensures that all copies of the data stay the same, helping maintain strong consistency.
- Quorum-based Protocols: Methods like Paxos or Quorum Consensus require a certain number of replicas to agree on the order of operations before finalizing them. This agreement is crucial for keeping everything consistent across the system.
- Distributed Locking: This method stops multiple users from accessing the same resource at once. By using locks, different parts of the system can coordinate their access to data, ensuring strong consistency.
- Two-phase Commit: This protocol is used in transactions that involve multiple systems to make sure everything goes as planned. It requires all replicas to agree on the outcome before finalizing or canceling the transaction, which helps maintain strong consistency.
Challenges with Strong Consistency
Below are the challenges in achieving strong consistency:
- Maintaining consistent data across multiple nodes requires additional communication and coordination, impacting performance.
- Implementing and maintaining strong consistency protocols can be complex and require significant expertise.
- As the number of nodes increases, the cost of maintaining consistency can become prohibitive.
- Strong consistency guarantees can be difficult to maintain in the presence of network failures or node outages.
- Synchronization mechanisms required for strong consistency introduce latency in read and write operations, impacting overall system performance.
Example of Strong Consistency
Below is the example to understand the Strong Consistency:
- User 1 sends a write request to Node C to update Val1 to 100.
- Node C receives the request, updates the value to 100, and propagates the update to Nodes A, B and D.
- The response from Node C is sent back to User 1
- Now the User 2 immediately sends a read request to Node D to get the value of Val1.
- Since the system follows strong consistency, Node D has already received the update from Node C and reflects the latest value of Val1, which is 100.
- Node D responds to User 2 with the value 100.

Below is how strong consistency impact on system performance, scalability and availability:
- System Performance: Strong consistency can impact system performance due to increased latency caused by synchronization mechanisms. However, the impact may vary depending on the implementation and workload.
- Scalability: Achieving strong consistency may impose scalability challenges, especially in large-scale distributed systems, as synchronization mechanisms can introduce bottlenecks and limit scalability.
- Availability: Strong consistency may negatively impact availability, particularly in the presence of network partitions or failures. Nodes may need to wait for synchronization, leading to increased response times or unavailability during these events.
Similar Reads
Consistency in System Design
Consistency in system design refers to the property of ensuring that all nodes in a distributed system have the same view of the data at any given point in time, despite possible concurrent operations and network delays. In simpler terms, it means that when multiple clients access or modify the same
8 min read
Strong vs. Eventual Consistency in System Design
Strong consistency and Eventual consistency are two basic principles that are being used in the creation of systems, especially distributed databases and systems. Strong consistency means that all nodes in a distributed system reflect the same data at once after any update, which gives immediate con
5 min read
Weak Consistency in System Design
Weak consistency is a relaxed approach to data consistency in distributed systems. It doesn't guarantee that all clients will see the same version of the data at the same time, or that updates will be reflected immediately across all nodes. This means there may be a temporary lag between a write ope
7 min read
Case Studies in System Design
System design case studies provide important insights into the planning and construction of real-world systems. You will discover helpful solutions to typical problems like scalability, dependability, and performance by studying these scenarios. This article highlights design choices, trade-offs, an
3 min read
Weak vs. Eventual Consistency in System Design
Consistency in system design refers to the property of ensuring that all nodes in a distributed system have the same view of the data at any given point in time, despite possible concurrent operations and network delays. In simpler terms, it means that when multiple clients access or modify the same
4 min read
Consistency vs. Availability in System Design
When it comes to the field of system design there are two fundamental Concepts often analyzed, they are Consistency and Availability. It is essential to comprehend these ideas to ensure the construction of dependable, inexpensive, and optimal systems. These two concepts are explained in detail in th
6 min read
Asynchronous Processing in System Design
Asynchronous processing involves handling tasks independently of the main program flow. It allows systems to execute multiple tasks concurrently, improving efficiency and responsiveness. This method is especially beneficial for waiting operations, such as I/O tasks or network requests. In this artic
10 min read
Polling in System Design
Polling in system design is an important method for gathering data or monitoring device status at regular intervals. This article provides an overview of polling, its importance, applications, strategies, and challenges also. Important Topics for Polling in System Design What is Polling?Importance o
10 min read
Design Principles in System Design
Design Principles in System Design are a set of considerations that form the basis of any good System. But the question now arises why use Design Principles in System Design? Design Principles help teams with decision-making, and is a multi-disciplinary field that involves trade-off analysis, balanc
5 min read
Event Storming - System Design
"Event Storming in System Design" introduces an innovative workshop technique aimed at rapidly capturing and visualizing complex business processes. By leveraging collaborative efforts and visual representation with sticky notes, Event Storming enhances understanding and facilitates streamlined syst
11 min read