


























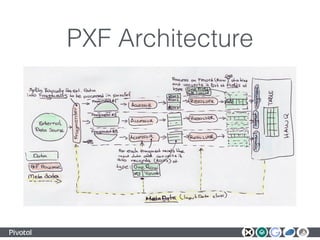









The document discusses the integration of OLTP and OLAP data systems using Apache Geode and Apache HAWQ, highlighting their architectural patterns and components like data lakes and PXF. It details passive data synchronization, federated queries, and the orchestration of data streams using Spring XD. Additionally, it provides insights into performance improvements and practical use cases within large-scale environments like the China and Indian railways.





























































































