Building highly scalable data pipelines with Apache Spark
Download as pptx, pdf0 likes511 views

This document provides a summary of Apache Spark, including: - Spark is a framework for large-scale data processing across clusters that is faster than Hadoop by relying more on RAM and minimizing disk IO. - Spark transformations operate on resilient distributed datasets (RDDs) to manipulate data, while actions return results to the driver program. - Spark can receive data from various sources like files, databases, sockets through its datasource APIs and process both batch and streaming data. - Spark streaming divides streaming data into micro-batches called DStreams and integrates with messaging systems like Kafka. Structured streaming is a newer API that works on DataFrames/Datasets.






























![Spark streaming
• To define a Spark stream you need to create a
JavaStreamingContext instance
SparkConf conf = new
SparkConf().setMaster("local[4]").setAppName("CustomerItems");
JavaStreamingContext jssc = new JavaStreamingContext(conf,
Durations.seconds(1));](https://image.slidesharecdn.com/buildinghighlyscalabledatapipelineswithapachespark-191211123846/85/Building-highly-scalable-data-pipelines-with-Apache-Spark-32-320.jpg)
















![Pipelines
Tokenizer tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words");
HashingTF hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol())
.setOutputCol("features");
LogisticRegression lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001);
Pipeline pipeline = new Pipeline()
.setStages(new PipelineStage[] {tokenizer, hashingTF, lr});](https://image.slidesharecdn.com/buildinghighlyscalabledatapipelineswithapachespark-191211123846/85/Building-highly-scalable-data-pipelines-with-Apache-Spark-49-320.jpg)










































More Related Content
What's hot (20)
Similar to Building highly scalable data pipelines with Apache Spark (20)


















More from Martin Toshev (20)




















Recently uploaded (20)




















Building highly scalable data pipelines with Apache Spark
- 1. Building highly scalable data pipelines with Apache Spark Martin Toshev
- 2. Who am I Software consultant (CoffeeCupConsulting) BG JUG board member (http://jug.bg) (BG JUG is a 2018 Oracle Duke’s choice award winner)
- 3. Agenda • Apache Spark from an eagle’s eye • Datasets and transformations • Datasources • Machine learning capabilities • Clustering
- 4. Apache Spark from an Eagle’s eye
- 5. Highlights • A framework for large-scale distributed data processing • Originally in Scala but extended with Java, Python and R • One of the most contributed open source/Apache/GitHub projects with over 1400 contributors
- 6. Spark vs MapReduce • Spark has been developed in order to address the shortcomings of the MapReduce programming model • In particular MapReduce is unsuitable for: – real-time processing (suitable for batch processing of present data) – operations not limited to the key-value format of data – large data on a network – online transaction processing – graph processing – sequential program execution
- 7. Spark vs Hadoop • Spark is faster as it depends more on RAM usage and tries to minimize disk IO (on the storage system) • Spark however can still use Hadoop: – as a storage engine (HDFS) – as a compute engine (MapReduce or Hadoop YARN) • Spark has pluggable storage and compute engine architecture
- 8. Spark components Spark Framework Spark Core Spark Streaming MLib GraphXSpark SQL
- 9. Spark architecture SparkContext (driver) Cluster manager Worker node Worker node Worker node Spark application (JAR) Input data sources Output data sources
- 11. Spark datasets • The building block of Spark are RDDs (Resilient Distributed Datasets) • They are immutable collections of objects spread across a Spark cluster and stored in RAM or on disk • Created by means of distributed transformations • Rebuilt on failure of a Spark node
- 12. Spark datasets • The DataFrame API is a superset of RDDs introduced in Spark 2.0 • The Dataset API provides a way to work with a combination of RDDs and DataFrames • The DataFrame API is preferred compared to RDDs due to improved performance and more advanced operations
- 13. Spark datasets List<Item> items = …; SparkConf configuration = new SparkConf().setAppName(“ItemsManager").setMaster("local"); JavaSparkContext context = new JavaSparkContext(configuration); JavaRDD<Item> itemsRDD = context.parallelize(items);
- 14. Spark transformations map itemsRDD.map(i -> { i.setName(“phone”); return i;}); filter itemsRDD.filter(i -> i.getName().contains(“phone”)) flatMap itemsRDD.flatMap(i -> Arrays.asList(i, i).iterator()); union itemsRDD.union(newItemsRDD); intersection itemsRDD.intersection(newItemsRDD); distinct itemsRDD.distinct() cartesian itemsRDD.cartesian(otherDatasetRDD)
- 15. Spark transformations groupBy pairItemsRDD = itemsRDD.mapToPair(i -> new Tuple2(i.getType(), i)); modifiedPairItemsRDD = pairItemsRDD.groupByKey(); reduceByKey pairItemsRDD = itemsRDD.mapToPair(o -> new Tuple2(o.getType(), o)); modifiedPairItemsRDD = pairItemsRDD.reduceByKey((o1, o2) -> new Item(o1.getType(), o1.getCount() + o2.getCount(), o1.getUnitPrice()) ); • Other transformations include aggregateByKey, sortByKey, join, cogroup …
- 16. Spark datasets • Some transformations such as mapPartitions and mapPartitionsWithIndex work directly on the dataset partitions • The number of partitions of an RDD can be modified using the coalesce and repartition transformations
- 17. Spark actions • Spark actions are the terminal operations that produce results from the transformations • Actions are a way to communicate back from the execution engine to the Spark driver instance
- 18. Spark actions collect itemsRDD.collect() reduce itemsRDD.map(i -> i.getUnitPrice() * i.getCount()). reduce((x, y) -> x + y); count itemsRDD.count() first itemsRDD.first() take itemsRDD.take(4) takeOrdered itemsRDD.takeOrdered(4, comparator) foreach itemsRDD.foreach(System.out::println) saveAsTextFile itemsRDD.saveAsTextFile(path) saveAsObjectFile itemsRDD.saveAsObjectFile(path)
- 19. DataFrames/DataSets • A dataframe can be created using an instance of the org.apache.spark.sql.SparkSession class • The DataFrame/DataSet APIs provide more advanced operations and the capability to run SQL queries on the data itemsDS.createOrReplaceTempView(“items"); session.sql("SELECT * FROM items");
- 20. DataFrames/DataSets • An existing RDD can be converted to a Spark dataframe: • An RDD can be retrieved from a dataframe as well: SparkSession session = SparkSession.builder().appName("app").getOrCreate(); Dataset<Row> itemsDS = session.createDataFrame(itemsRDD, Item.class); itemsDS.rdd()
- 21. Datasources
- 22. Spark data sources • Spark can receive data from a variety of data sources in a variety of ways (batching, real-time streaming) • These datasources might be: – files: Spark supports reading data from a variety of formats (JSON, CSV, Avro, etc.) – relational databases: using JDBC/ODBC driver Spark can extract data from an RDBMS – TCP sockets, messaging systems: using streaming capabilities of Spark data can be read from messaging systems and raw TCP sockets
- 23. Spark data sources • Spark provides support for operations on batch data or real time data • For real time data Spark provides two main APIs: – Spark streaming is an older API working on RDDs – Spark structured streaming is a newer API working on DataFrames/DataSets
- 24. Spark data sources • Spark provides capabilities to plug-in additional data sources not supported by Spark • For streaming sources you can define your own custom receivers
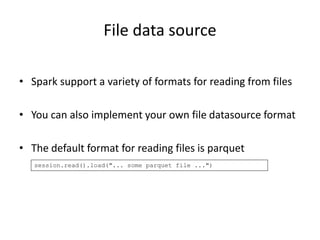
- 25. File data source • Spark support a variety of formats for reading from files • You can also implement your own file datasource format • The default format for reading files is parquet session.read().load("... some parquet file ...")
- 26. File data source • The format method can be used to specify the data source: • For some formats you can use a shorthand: session.read().format("json").load("...file path ...") session.read().format("csv").load("...file path ...") context.read().json("...json file"...)
- 27. File data source • In a similar way datasets can be writen to a particular file format: • datasets can be saved to an object file (serialized Java objects): • datasets can be saved to a text file: itemDF.write().format("csv").save("... file path ...") itemDS.saveAsObjectFile("... path ...") itemDS.saveAsTextFile("... path ...")
- 28. MySQL data source • Spark supports retrieval of data through JDBC/ODBC • Database driver must be supplied to the Spark classpath (specified with the --driver-class-path) option • For MySQL that is the ConnectorJ driver
- 29. MySQL data source context.read() .format("jdbc") .option("url", "jdbc:mysql://localhost:3306/spark") .option("dbtable", "customer_items") .option("user", "admin") .option("password", "admin") .load()
- 30. MySQL data source • You can use a variery of options when reading data from an RDBMS using the jdbc format: – query: a subquery that provides the possibility to limit retrieved data – queryTimeout: specify the timeout for the JDBC query executed against the RDBMS • You can also save datasets to a table: itemsDF.write().mode(org.apache.spark.sql.SaveMode.Append). jdbc("jdbc:mysql://localhost:3306/spark", "datasets_table", prop);
- 31. Spark streaming • Data is divided into batches called Dstreams (decentralized streams) • Typical use case is the integration of Spark with messaging systems such as Kafka, RabbitMQ and ActiveMQ etc. • Fault tolerance can be enabled in Spark Streaming whereby data is stored in HDFS
- 32. Spark streaming • To define a Spark stream you need to create a JavaStreamingContext instance SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("CustomerItems"); JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
- 33. Spark streaming • Then a receiver can be created for the data: – from sockets: – from data directory: – from RDD streams (for testing purposes): jssc.socketTextStream("localhost", 7777); jssc.textFileStream("... some data directory ..."); jssc.queueStream(... RDDs queue ... )
- 34. Spark streaming • Then the data pipeline can be built using transformations and actions on the streams • Finally retrieval of data must be triggered from the streaming context: jssc.start(); jssc.awaitTermination();
- 35. Spark streaming • Window streams can be created over stream data based on two criteria: – length of the window – sliding interval for the windows • Streaming datasets can also be joined with other streaming or batch datasets
- 36. Spark structured streaming • Newer streaming API working on DataSets/DataFrames: • A schema can be specified on the streaming data using the .schema(<schema>) method on the read stream SparkSession context = SparkSession .builder() .appName("CustomerItems") .getOrCreate(); Dataset<Row> lines = spark .readStream() .format("socket") .option("host", "localhost") .option("port", 7777) .load();
- 37. Spark structured streaming • Write sinks can also be used to write out streaming datasets: • The following write sinks are provided by Spark: - file - Kafka - foreach - console (for testing purpose) - memory (for testing purpose) StreamingQuery query = wordCounts.writeStream() .outputMode("complete") .format("console") .start(); query.awaitTermination();
- 38. Kafka data source • Kafka integration is provided both through the Spark streaming and Spark structured streaming frameworks • A Kafka source can also be created for batch queries: • Batch query results or a Kafka sink can be created with the write()/writeStream() methods Dataset<Row> df = context .read() .format("kafka") .option("kafka.bootstrap.servers","kafkaHost:kafkaPort,...") .option("subscribe", "customer_items") .load();
- 39. Kafka data source • For Spark streaming the application needs a dependency to the spark-streaming-kafka library: <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.10</artifactId> <version>2.2.3</version> </dependency>
- 40. Kafka data source Map<String, Object> kafkaParams = new HashMap<>(); kafkaParams.put("bootstrap.servers", "localhost:9092,…"); kafkaParams.put("key.deserializer", StringDeserializer.class); kafkaParams.put("value.deserializer", StringDeserializer.class); kafkaParams.put("group.id", "stream_group_id"); kafkaParams.put("auto.offset.reset", "latest"); kafkaParams.put("enable.auto.commit", false); Collection<String> topics = Arrays.asList(... kafka topics list ...); JavaInputDStream<ConsumerRecord<String, String>> stream = KafkaUtils.createDirectStream( streamingContext, LocationStrategies.PreferConsistent(), ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams) );
- 41. Kafka data source • For Spark structured streaming the application needs a dependency on the spark-sql-kafka library: <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql-kafka-0-10_2.12</artifactId> <version>2.4.0</version> </dependency>
- 42. Kafka data source Dataset<Row> df = context .readStream() .format("kafka") .option("kafka.bootstrap.servers", "kafkaHost:kafkaPort,...") .option("subscribe", "customer_items") .load();
- 43. DEMO
- 45. Overview • Spark MLib is a machine learning library supporting Spark’s datasets • The following Maven dependency must be used: <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.12</artifactId> <version>2.4.0</version> <scope>runtime</scope> </dependency>
- 46. Overview • MLib provides the following: – machine learning algorithms – featurization utilities – machine learning pipelines – persistence for the algorithms, models and pipelines – various utilities for linear algebra, statistics and data handling • MLib uses DataFrames as the primary dataset format • MLib utilities over RDDs are in maintenance mode
- 47. Machine learning algorithms • Spark Mlib provides implementation for the following categories of algorithms: – Classification – Regression – Clustering – Collaborative filtering
- 48. Pipelines • Provide a mechanism for creating a machine learning workflow • Allow for combination of different machine learning algorithms • Inspired by Python’s scikit-learn project
- 49. Pipelines Tokenizer tokenizer = new Tokenizer() .setInputCol("text") .setOutputCol("words"); HashingTF hashingTF = new HashingTF() .setNumFeatures(1000) .setInputCol(tokenizer.getOutputCol()) .setOutputCol("features"); LogisticRegression lr = new LogisticRegression() .setMaxIter(10) .setRegParam(0.001); Pipeline pipeline = new Pipeline() .setStages(new PipelineStage[] {tokenizer, hashingTF, lr});
- 50. Clustering
- 51. Cluster managers • Spark supports the following cluster managers: – Standalone scheduler (default) – YARN – Mesos • Support for Kubernetes cluster manager is also undergoing (experimental at present)
- 52. Standalone cluster • Spark provides several utilities to manage a standalone cluster: – start-master.sh: starts a Spark master instance (that runs the cluster manager) – start-slave.sh: starts a Spark worker node connecting to a specified Spark master • Standalone cluster topology is listed in the web UI of the master node
- 53. Standalone cluster • Applications can be deployed to the cluster using the spark-submit utility • Standalone cluster has 'client' and 'cluster' mode of operation (the Spark driver runs as a separate instance or as part of the Spark cluster) • Specified with the --deploy-mode parameter of the spark- submit utility
- 54. Standalone cluster • Additional scripts provide the possiblity to stop cluster nodes (master and slave) and also to start multiple nodes at once on a single machine where the Spark master resides • High availability can be established also at the level of the Spark master node by registering multiple master Spark nodes against a Zookeeper instance
- 55. Mesos cluster • A Mesos master node can be used as the cluster manager instead of Spark master node in the standalone mode • The Spark worker nodes running as Spark Mesos executors must be supplied with the Spark package • The Spark package is specified with the spark.executor.uri parameter of the Spark configuration instance or via the SPARK_EXECUTOR_URI environment variable
- 56. Mesos cluster • The Spark driver can also be run in the Mesos cluster • A mesos cluster dispatcher must be started to facilitate the cluster mode of operation start-mesos-dispatcher.sh
- 57. Mesos cluster • Spark executors run as Mesos tasks configured according to the following parameters: – spark.executor.memory – spark.executor.cores – spark.cores.max/spark.executor.cores • Spark tasks within executors can also be run as separate Mesos tasks but that mode of operation is deprecated in Spark
- 58. Yarn cluster • Spark can also run a Yarn master instance as a cluster manager • Spark also supports two deploy modes for Yarn: 'client' and 'cluster'
- 59. Kubernetes cluster • Support for using a Kubernetes cluster manager is experimental at present • The Spark topology aligns with Kubernetes as follows: – Spark driver is created as a Kubernetes pod – The Spark driver creates Spark executors also in Kubernetes pods – When the application completes executors pods are brought down • The spark-submit utility can be used to deploy Spark applications to a Kubernetes cluster
- 60. Application dependencies • Production Spark applications typically use some third- party libraries • These may be supplied to Spark either: – Using the --jars parameter to supply JAR files using spark-submit – Using the --packages parameter to supply Maven dependencies using spark-submit – Using the --repositories parameter to supply Maven repositories
- 61. Summary • Apache Spark is one of the most feature-rich and developed big data processing frameworks • Provides a mechanism to distribute load over a large number of nodes using different cluster managers • Apart from the variety of operations supported on the datasets Spark provides a rich machine learning library to facilitate the data processing capabilities of Spark