Evaluation Challenges in Using Generative AI for Science & Technical Content
0 likes122 views

Evaluation Challenges in Using Generative AI for Science & Technical Content. Foundation Models show impressive results in a wide-range of tasks on scientific and legal content from information extraction to question answering and even literature synthesis. However, standard evaluation approaches (e.g. comparing to ground truth) often don't seem to work. Qualitatively the results look great but quantitive scores do not align with these observations. In this talk, I discuss the challenges we've face in our lab in evaluation. I then outline potential routes forward.



































![Problem statement
• We will focus on how LLMs can be used to
support the evaluation of class membership
relations in a KG
• Class membership represents
classification schemes
• Classification schemes
• Crucial to knowledge infrastructures
• Implications for social policy and scientific
consensus
• Class membership is important for data
governance
• "providing a set of mappings from a
representation language to agreed-upon
concepts in the real world" [Khatri and Brown]
36
Allen, B.P., Groth, P.T. (2025). Evaluating Class Membership Relations in Knowledge Graphs Using
Large Language Models. In: Meroño Peñuela, A., et al. The Semantic Web: ESWC 2024 Satellite
Events. ESWC 2024. Lecture Notes in Computer Science, vol 15344. Springer, Cham. https://
doi.org/10.1007/978-3-031-78952-6_2](https://image.slidesharecdn.com/semtech4stld-eswc-2025-250602082251-ae90ab0b/85/Evaluation-Challenges-in-Using-Generative-AI-for-Science-Technical-Content-36-320.jpg)


































More Related Content
More from Paul Groth (20)
Recently uploaded (20)


















Evaluation Challenges in Using Generative AI for Science & Technical Content
- 1. Evaluation Challenges in Using Generative AI for Science & Technical Content Prof. Paul Groth | @pgroth | pgroth.com | indelab.org Thanks to Bradley Allen, Fina Polat, Xue Li, Daniel Daza SemTech4STLD Workshop - ESWC 2025
- 2. Outline • A use case & where we are today • The challenges of evaluation in for information extraction and knowledge graph construction • Some routes forward & maybe a bold idea
- 3. Using AI to Study Standards
- 4. • Provenance working group: • 8820 public emails, • 666 issues, • 600 wiki pages, • 6000 mercurial commits • 152 teleconferences Standards are hard The rationale of PROVL Moreau, P Groth, J Cheney, T Lebo, S Miles Web Semantics: Science, Services and Agents on the World Wide Web 35, 235-257
- 6. Standard development leaves digital traces
- 7. New tools to analyze standards development https://github.com/glasgow-ipl/ietfdata https://github.com/datactive/bigbang
- 8. Nick Doty et al. https://github.com/IETF-Hackathon/ietf111-project-presentations/blob/main/ietf111-hackathon-bigbang.pdf
- 9. Questions one might like to ask • Understand the content of email messages and their rhetorical structure. (e.g. arguments were put forward but constantly ignored) • Recover technical considerations and rationales behind the choices made and ultimately documented in a standard • More fine-grained quantitative and qualitative analysis From: Michael Welzl, Stephan Oepen, Cezary Jaskula, Carsten Griwodz, and Safiqul Islam. 2021. Collaboration in the IETF: an initial analysis of two decades in email discussions. SIGCOMM Comput. Commun. Rev. 51, 3 (July 2021), 29–32. DOI:https://doi.org/10.1145/3477482.3477488
- 10. Example uses of AI for standards analysis
- 11. From EUROCAE ED 133: FLIGHT OBJECT INTEROPERABILITY SPECIFICATION Recognising entities in conversations
- 12. Predicting the success of a standard Stephen McQuistin, Mladen Karan, Prashant Khare, Colin Perkins, Gareth Tyson, Matthew Purver, Patrick Healey, Waleed Iqbal, Junaid Qadir, and Ignacio Castro. 2021. Characterising the IETF through the lens of RFC deployment. In <i>Proceedings of the 21st ACM Internet Measurement Conference</i> (<i>IMC '21</i>). Association for Computing Machinery, New York, NY, USA, 137–149. DOI:https://doi.org/ 10.1145/3487552.3487821
- 13. Intelligent Interventions Develop new natural language processing and machine learning techniques to understand what’s going on within standards development: • How are people, organizations, topics, documents, priorities, requirements, etc… connected? • What are people and standards actually talking about? Based on this understanding, develop intelligent tools to better integrate public values.
- 14. Challenges in using AI for Standards Analysis 14 Email threads https://lists.w3.org/Archives/Public/ ● Long form conversations; ● Change of speaker; ● Lexical ambiguity; ● Specialized domain; ● Informal structures; ● Extensions across sessions; ● Lack of annotated data ● Complex entities ● Multiple perspectivies ● Dynamic analyses 15 Xue Li, Sara Magliacane, and Paul Groth. 2021. The Challenges of Cross-Document Coreference Resolution for Email. In <i>Proceedings of the 11th on Knowledge Capture Conference</i> (<i>K-CAP '21</i>). Association for Computing Machinery, New York, NY, USA, 273–276. DOI:https://doi.org/10.1145/3460210.3493573
- 15. Methods for building databases of information from standards conversations 1 – knowledge graphs 1
- 16. Decoder-only representative large language models. Source: S. Pan et al., Unifying Large Language Models and Knowledge Graphs: A Roadmap https://arxiv.org/abs/2306.08302 LLMs and Generative AI
- 20. - Sustainability - Security / Resilience - Connecting the Unconnected
- 22. The tale of SlotGan Daniel Daza, Michael Cochez, and Paul Groth. 2022. SlotGAN: Detecting Mentions in Text via Adversarial Distant Learning. In Proceedings of the Sixth Workshop on Structured Prediction for NLP, pages 32–39, Dublin, Ireland. Association for Computational Linguistics.
- 23. Relation Extraction & Instruction Tuning Do Instruction-tuned Large Language Models Help with Relation Extraction? Xue Li, Fina Polat and Paul Groth. LM-AKBC Workshop at ISWC 2023 https://ceur-ws.org/Vol-3577/paper15.pdf Results on REBEL dataset Results on Post-Hoc Human Eval Can we preserve relation extraction performance while preserving in-context capabilities? Method: Instruction Tune Dolly LLM with LORA using a relation extraction dataset (REBEL)
- 24. ▫ Prompt Engineering techniques: ▿ Zero-shot, one-shot, few-shot ▿ RAG - Retrieval Augmented Generation ▿ CoT - Chain of Thought ▿ CoT self consistency ▿ ReAct - Reasoning (e.g.chain-of-thought prompting) and Acting (e.g.action plan generation) ▫ Polat F, Tiddi I, Groth P. Testing prompt engineering methods for knowledge extraction from text. Semantic Web. 2025;16(2). doi:10.3233/SW-243719 05.06.24 24 Test and compare Prompt Engineering for Knowledge Extraction
- 25. 05.06.24 25 Open Information Extraction
- 27. 05.06.24 27 Ontology Based Triple Assesment
- 29. Impressions • Results appear to be really good qualitatively • Annotation quality is varied • Challenges in agreement • Large scale is often automated • Is everything in domain?
- 30. Routes Forward
- 32. User studies E Papadopoulou. Retrieval Augmented Generation of Tabular Answers at Query Time using Pre-trained Large Language Models. (2023) https:// scripties.uba.uva.nl/search?id=record_53599
- 33. LLMs as judges Zhen Li, Xiaohan Xu, Tao Shen, Can Xu, Jia-Chen Gu, Yuxuan Lai, Chongyang Tao, and Shuai Ma. 2024. Leveraging Large Language Models for NLG Evaluation: Advances and Challenges. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16028–16045, Miami, Florida, USA. Association for Computational Linguistics.
- 34. LLMs as judges Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-judge with MT-bench and Chatbot Arena. In Proceedings of the 37th International Conference on Neural Information Processing Systems (NIPS '23). Curran Associates Inc., Red Hook, NY, USA, Article 2020, 46595–46623.
- 35. Agreement
- 36. Problem statement • We will focus on how LLMs can be used to support the evaluation of class membership relations in a KG • Class membership represents classification schemes • Classification schemes • Crucial to knowledge infrastructures • Implications for social policy and scientific consensus • Class membership is important for data governance • "providing a set of mappings from a representation language to agreed-upon concepts in the real world" [Khatri and Brown] 36 Allen, B.P., Groth, P.T. (2025). Evaluating Class Membership Relations in Knowledge Graphs Using Large Language Models. In: Meroño Peñuela, A., et al. The Semantic Web: ESWC 2024 Satellite Events. ESWC 2024. Lecture Notes in Computer Science, vol 15344. Springer, Cham. https:// doi.org/10.1007/978-3-031-78952-6_2
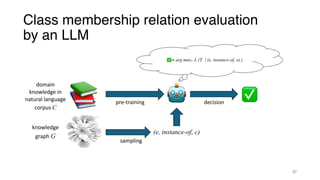
- 37. Class membership relation evaluation by an LLM domain knowledge in natural language corpus C = arg max L ( 𝑇 | (e, instance-of, o) ) knowledge graph G pre-training sampling (e, instance-of, c) decision 37
- 38. Performance metrics • Classifiers can exhibit good alignment with KGs (Q1) • One LLM was in moderate agreement (κ > 0.60) with Wikidata • Four were in moderate agreement with CaLiGraph 38
- 39. Error analysis results • Error analysis based on review by one of the authors • FNs, FPs with rationales and assign error to LLM or KG • LLM errors: incorrect reasoning, missing data • KG errors: missing relation, incorrect relation • Error analysis performed for gpt-4-0125-preview • Classifiers can detect missing or incorrect relations (Q2) • 40.9% of errors were due to the problems with the KG • 29.1% of errors were due to missing or insufficient data in the entity description • 30.0% of errors due to incorrect reasoning by the LLM • Pairwise human-KG and human-LLM agreement differed between the KGs • Human showed fair agreement with Wikidata and no agreement with the classifier • Human showed slight agreement with the classifier and no agreement with CaLiGraph 39
- 40. Agents as Peers • Rationales • Based on provenance and evidence • Consensus formation • Encoding consensus as sharable knowledge (graphs)
- 41. Conclusion • Gen AI allows for impressive capabilities for Scienti fi c & Legal Content • How do we know the results are good? • Standard evaluations • Approaches: complex tasks, user feedback, LLMs as judges • consensus among peers - science! Paul Groth | @pgroth | pgroth.com | indelab.org