Extending spark ML for custom models now with python!
1 like196 views

The document discusses the extension of Spark ML estimators and transformers, highlighting the role of its principal software engineer Holden Karau and the objectives of IBM's Spark Technology Center. It explains Spark ML pipelines, the structure and function of estimators and transformers, and introduces a project called SparklingML aimed at enhancing Spark ML capabilities. Additionally, it provides an overview of building custom stages within Spark ML and encourages contributions to the community.














![How are transformers made?
Estimator
data
class Estimator extends PipelineStage {
def fit(dataset: Dataset[_]): Transformer = {
// magic happens here
}
}
Transformer](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-15-320.jpg)
![How is new data made?
Transformer ( data )
class Transformer extends PipelineStage {
def transform(df: Dataset[_]): DataFrame
}
new data.transform](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-16-320.jpg)
![Feature transformations
+-----+-----+----+--------+
|admit| gre| gpa|prestige|
+-----+-----+----+--------+
| no|380.0|3.61| 3.0|
| yes|660.0|3.67| 3.0|
| yes|800.0| 4.0| 1.0|
| yes|640.0|3.19| 4.0|
| no|520.0|2.93| 4.0|
+-----+-----+----+--------+
val assembler = new VectorAssembler()
.setInputCols(Array("gre", "gpa", "prestige"))
val df2 = assembler.transform(df)
VectorAssembler
+-----+-----+----+--------+----------------+
|admit| gre| gpa|prestige| features|
+-----+-----+----+--------+----------------+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]|
+-----+-----+----+--------+----------------+](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-17-320.jpg)
![Train a classifier on the transformed data
StringIndexer
StringIndexerModel
val si = new StringIndexer().setInputCol("admit").setOutputCol("label")
val siModel = si.fit(df2)
val df3 = siModel.transform(df2)
+-----+-----+----+--------+----------------+
|admit| gre| gpa|prestige| features|
+-----+-----+----+--------+----------------+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]|
+-----+-----+----+--------+----------------+
+-----+-----+----+--------+----------------+-----+
|admit| gre| gpa|prestige| features|label|
+-----+-----+----+--------+----------------+-----+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]| 0.0|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]| 1.0|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]| 1.0|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]| 1.0|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]| 0.0|
+-----+-----+----+--------+----------------+-----+](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-18-320.jpg)
![Train a classifier on the transformed data
+----------------+-----+
| features|label|
+----------------+-----+
|[380.0,3.61,3.0]| 0.0|
|[660.0,3.67,3.0]| 1.0|
| [800.0,4.0,1.0]| 1.0|
|[640.0,3.19,4.0]| 1.0|
|[520.0,2.93,4.0]| 0.0|
+----------------+-----+
DecisionTreeClassifier
DecisionTree
ClassificationModel
+----------------+-----+----------+
| features|label|prediction|
+----------------+-----+----------+
|[380.0,3.61,3.0]| 0.0| 0.0|
|[660.0,3.67,3.0]| 1.0| 0.0|
| [800.0,4.0,1.0]| 1.0| 1.0|
|[640.0,3.19,4.0]| 1.0| 1.0|
|[520.0,2.93,4.0]| 0.0| 0.0|
+----------------+-----+----------+
val dt = new DecisionTreeClassifier()
val dtModel = dt.fit(df3)
val df4 = dtModel.transform(df3)](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-19-320.jpg)










![Do the “work” (e.g. predict labels or w/e):
def transform(df: Dataset[_]): DataFrame = {
val wordcount = udf { in: String => in.split(" ").size }
df.select(col("*"),
wordcount(df.col("happy_pandas")).as("happy_panda_counts"))
}
vic15](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-30-320.jpg)


final val outputCol = new Param[String](this, "outputCol", "The
output column")
def setInputCol(value: String): this.type = set(inputCol, value)
def setOutputCol(value: String): this.type = set(outputCol, value)
Jason Wesley Upton](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-32-320.jpg)




![A simple string indexer estimator
class SimpleIndexer(override val uid: String) extends
Estimator[SimpleIndexerModel] with SimpleIndexerParams {
….
override def fit(dataset: Dataset[_]): SimpleIndexerModel = {
import dataset.sparkSession.implicits._
val words = dataset.select(dataset($(inputCol)).as[String]).distinct
.collect()
new SimpleIndexerModel(uid, words)
}
}](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-37-320.jpg)

![And our friend the transformer is back:
class SimpleIndexerModel(
override val uid: String, words: Array[String]) extends
Model[SimpleIndexerModel] with SimpleIndexerParams {
...
private val labelToIndex: Map[String, Double] = words.zipWithIndex.
map{case (x, y) => (x, y.toDouble)}.toMap
override def transform(dataset: Dataset[_]): DataFrame = {
val indexer = udf { label: String => labelToIndex(label) }
dataset.select(col("*"),
indexer(dataset($(inputCol)).cast(StringType)).as($(outputCol)))
Still not to be confused with the Transformers franchise from Hasbro and Tomy.](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-39-320.jpg)










![Cross-validation
because saving a test set is effort & a reason to integrate
// ParamGridBuilder constructs an Array of parameter
combinations.
val paramGrid: Array[ParamMap] = new ParamGridBuilder()
.addGrid(nb.smoothing, Array(0.1, 0.5, 1.0, 2.0))
.build()
val cv = new CrossValidator()
.setEstimator(pipeline)
.setEstimatorParamMaps(paramGrid)
val cvModel = cv.fit(df)
val bestModel = cvModel.bestModel
Jonathan Kotta](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-51-320.jpg)


![Let’s make a Classifier* :)
// Example only - not for production use.
class SimpleNaiveBayes(val uid: String)
extends Classifier[Vector, SimpleNaiveBayes, SimpleNaiveBayesModel] {
Input type Trained Model](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-54-320.jpg)
![Let’s make a Classifier* :)
override def train(ds: Dataset[_]): SimpleNaiveBayesModel = {
import ds.sparkSession.implicits._
ds.cache()
….
…
….
}](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-55-320.jpg)
![If you reallllly want to see inside the ...s (1/5)
// Get the number of features by peaking at the first row
val numFeatures: Integer = ds.select(col($(featuresCol))).head
.get(0).asInstanceOf[Vector].size
// Determine the number of records for each class
val groupedByLabel = ds.select(col($(labelCol)).as[Double]).groupByKey(x =>
x)
val classCounts = groupedByLabel.agg(count("*").as[Long])
.sort(col("value")).collect().toMap
// Select the labels and features so we can more easily map over them.
// Note: we do this as a DataFrame using the untyped API because the Vector
// UDT is no longer public.
val df = ds.select(col($(labelCol)).cast(DoubleType), col($(featuresCol)))](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-56-320.jpg)

![If you reallllly want to see inside the ...s (3/5)
// Figure out the non-zero frequency of each feature for each label and
// output label index pairs using a case clas to make it easier to work
with.
val labelCounts: Dataset[LabeledToken] = df.flatMap {
case Row(label: Double, features: Vector) =>
features.toArray.zip(Stream from 1)
.filter{vIdx => vIdx._2 == 1.0}
.map{case (v, idx) => LabeledToken(label, idx)}
}
// Use the typed Dataset aggregation API to count the number of non-zero
// features for each label-feature index.
val aggregatedCounts: Array[((Double, Integer), Long)] = labelCounts
.groupByKey(x => (x.label, x.index))
.agg(count("*").as[Long]).collect()
val theta = Array.fill(numClasses)(new Array[Double](numFeatures))](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-58-320.jpg)








![Minimal prep continued
val assembler = new VectorAssembler()
assembler.setInputCols(Array("gre", "gpa", "prestige"))
val si = new StringIndexer()
si.setInputCol("admit").setOutputCol("label")
val pipeline = new Pipeline()
pipeline.setStages(Array(assembler, si))
Huang
Yun
Chung
+-----+-----+----+--------+----------------+-----+
|admit| gre| gpa|prestige| features|label|
+-----+-----+----+--------+----------------+-----+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]| 0.0|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]| 1.0|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]| 1.0|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]| 1.0|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]| 0.0|
+-----+-----+----+--------+----------------+-----+
+-----+-----+----+--------+----------------+
|admit| gre| gpa|prestige| features|
+-----+-----+----+--------+----------------+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]|
+-----+-----+----+--------+----------------+
+-----+-----+----+--------+
|admit| gre| gpa|prestige|
+-----+-----+----+--------+
| no|380.0|3.61| 3.0|
| yes|660.0|3.67| 3.0|
| yes|800.0| 4.0| 1.0|
| yes|640.0|3.19| 4.0|
| no|520.0|2.93| 4.0|
+-----+-----+----+--------+](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/85/Extending-spark-ML-for-custom-models-now-with-python-67-320.jpg)




More Related Content




























Similar to Extending spark ML for custom models now with python! (20)








































Extending spark ML for custom models now with python!
- 1. Extending Spark ML Estimators and Transformers kroszk@ Built with public APIs* *For the most part - see developer for details.
- 2. Holden: ● My name is Holden Karau ● Prefered pronouns are she/her ● I’m a Principal Software Engineer at IBM’s Spark Technology Center ● Apache Spark committer (as of January!) :) ● previously Alpine, Databricks, Google, Foursquare & Amazon ● co-author of Learning Spark & Fast Data processing with Spark ○ co-author of a new book focused on Spark performance coming this year* ● @holdenkarau ● Slide share http://www.slideshare.net/hkarau ● Linkedin https://www.linkedin.com/in/holdenkarau ● Github https://github.com/holdenk ● Spark Videos http://bit.ly/holdenSparkVideos
- 4. Spark Technology Center 4 IBM Spark Technology Center Founded in 2015. Location: Physical: 505 Howard St., San Francisco CA Web: http://spark.tc Twitter: @apachespark_tc Mission: Contribute intellectual and technical capital to the Apache Spark community. Make the core technology enterprise- and cloud-ready. Build data science skills to drive intelligence into business applications — http://bigdatauniversity.com Key statistics: About 50 developers, co-located with 25 IBM designers. Major contributions to Apache Spark http://jiras.spark.tc Apache SystemML is now an Apache Incubator project. Founding member of UC Berkeley AMPLab and RISE Lab Member of R Consortium and Scala Center Spark Technology Center
- 5. Who I think you wonderful humans are? ● Nice enough people ● Don’t mind pictures of cats ● Might know some Apache Spark ● Possibly know some Scala or Python ● Think machine learning is kind of cool ● Don’t overly mind a grab-bag of topics Lori Erickson
- 6. What are we going to talk about? ● What Spark ML pipelines look like ● What Estimators and Transformers are ● How to implement both of them ● What tools can help us ● My newest project - SparklingML - and trying to get y’all to contribute ● Publishing your fancy new Spark model so other’s (like me) can use it! ● Of course try and sell you many copies of my new book if you have an expense account.
- 7. Why should you care about Spark ML? ● Big data something something profit ● sci-kit-learn inspired API makes it nice to work with ● Ability to experiment and try different algorithms without learning new tool kits. ● Meta algorithms
- 8. First: get some data sparkSession.read returns a DataFrameReader We can specify general properties & data specific options ● option(“key”, “value”) ○ spark-csv ones we will use are header & inferSchema ● format(“formatName”) ○ built in formats include parquet, jdbc, etc. ● load(“path”) Jess Johnson
- 9. Everyones favourite: CSVs! :p val df = spark.read .option("inferSchema", "true") .option("delimiter", ";") .format("csv") .load("hdfs:///user/data/admissions.csv") Jess Johnson
- 10. Spark ML Pipelines Pipeline Stage ?data Pipeline Stage Pipeline Stage Pipeline Stage ... Pipeline Ray Bodden
- 11. Spark ML Pipelines Pipeline Stage ?data Pipeline Stage Pipeline Stage Pipeline Stage ... Pipeline data ? Also a pipeline stage! Ray Bodden
- 12. Two main types of pipeline stages Pipeline Stage ?data Transformer Estimatordata data data transformer Reboots Michael Coghlan
- 13. Pipelines are estimators Pipeline data model Also an estimator! Transformer Transformer Estimator Michael Coghlan
- 14. PipelineModels are transformers PipelineModel data data Also a transformer! Transformer Transformer Transformer Reboots
- 15. How are transformers made? Estimator data class Estimator extends PipelineStage { def fit(dataset: Dataset[_]): Transformer = { // magic happens here } } Transformer
- 16. How is new data made? Transformer ( data ) class Transformer extends PipelineStage { def transform(df: Dataset[_]): DataFrame } new data.transform
- 17. Feature transformations +-----+-----+----+--------+ |admit| gre| gpa|prestige| +-----+-----+----+--------+ | no|380.0|3.61| 3.0| | yes|660.0|3.67| 3.0| | yes|800.0| 4.0| 1.0| | yes|640.0|3.19| 4.0| | no|520.0|2.93| 4.0| +-----+-----+----+--------+ val assembler = new VectorAssembler() .setInputCols(Array("gre", "gpa", "prestige")) val df2 = assembler.transform(df) VectorAssembler +-----+-----+----+--------+----------------+ |admit| gre| gpa|prestige| features| +-----+-----+----+--------+----------------+ | no|380.0|3.61| 3.0|[380.0,3.61,3.0]| | yes|660.0|3.67| 3.0|[660.0,3.67,3.0]| | yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]| | yes|640.0|3.19| 4.0|[640.0,3.19,4.0]| | no|520.0|2.93| 4.0|[520.0,2.93,4.0]| +-----+-----+----+--------+----------------+
- 18. Train a classifier on the transformed data StringIndexer StringIndexerModel val si = new StringIndexer().setInputCol("admit").setOutputCol("label") val siModel = si.fit(df2) val df3 = siModel.transform(df2) +-----+-----+----+--------+----------------+ |admit| gre| gpa|prestige| features| +-----+-----+----+--------+----------------+ | no|380.0|3.61| 3.0|[380.0,3.61,3.0]| | yes|660.0|3.67| 3.0|[660.0,3.67,3.0]| | yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]| | yes|640.0|3.19| 4.0|[640.0,3.19,4.0]| | no|520.0|2.93| 4.0|[520.0,2.93,4.0]| +-----+-----+----+--------+----------------+ +-----+-----+----+--------+----------------+-----+ |admit| gre| gpa|prestige| features|label| +-----+-----+----+--------+----------------+-----+ | no|380.0|3.61| 3.0|[380.0,3.61,3.0]| 0.0| | yes|660.0|3.67| 3.0|[660.0,3.67,3.0]| 1.0| | yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]| 1.0| | yes|640.0|3.19| 4.0|[640.0,3.19,4.0]| 1.0| | no|520.0|2.93| 4.0|[520.0,2.93,4.0]| 0.0| +-----+-----+----+--------+----------------+-----+
- 19. Train a classifier on the transformed data +----------------+-----+ | features|label| +----------------+-----+ |[380.0,3.61,3.0]| 0.0| |[660.0,3.67,3.0]| 1.0| | [800.0,4.0,1.0]| 1.0| |[640.0,3.19,4.0]| 1.0| |[520.0,2.93,4.0]| 0.0| +----------------+-----+ DecisionTreeClassifier DecisionTree ClassificationModel +----------------+-----+----------+ | features|label|prediction| +----------------+-----+----------+ |[380.0,3.61,3.0]| 0.0| 0.0| |[660.0,3.67,3.0]| 1.0| 0.0| | [800.0,4.0,1.0]| 1.0| 1.0| |[640.0,3.19,4.0]| 1.0| 1.0| |[520.0,2.93,4.0]| 0.0| 0.0| +----------------+-----+----------+ val dt = new DecisionTreeClassifier() val dtModel = dt.fit(df3) val df4 = dtModel.transform(df3)
- 20. Or just throw it all in a pipeline ● Keeping track of intermediate data and calling fit/transform on every stage is way too much work ● This problem is worse when more stages are used ● Use a pipeline instead! val assembler = new VectorAssembler() assembler.setInputCols(Array("gre", "gpa", "prestige")) val sb = new StringIndexer() sb.setInputCol("admit").setOutputCol("label") val dt = new DecisionTreeClassifier() val pipeline = new Pipeline() pipeline.setStages(Array(assembler, sb, dt)) val pipelineModel = pipeline.fit(df) jasonwoodhead23
- 21. Yay! You have an ML pipeline! Photo by Jessica Fiess-Hill
- 22. Pipeline API has many models: ● org.apache.spark.ml.classification ○ BinaryLogisticRegressionClassification, DecissionTreeClassification, GBTClassifier, etc. ● org.apache.spark.ml.regression ○ DecissionTreeRegression, GBTRegressor, IsotonicRegression, LinearRegression, etc. ● org.apache.spark.ml.recommendation ○ ALS ● You can also check out spark-packages for some more ● But possible not your special AwesomeFooBazinatorML PROcarterse Follow
- 23. & data prep stages... ● org.apache.spark.ml.feature ○ ~30 elements from VectorAssembler to Tokenizer, to PCA, etc. ● Often simpler to understand while getting started with building our own stages PROcarterse Follow
- 24. What is/why Sparkling ML ● A place for useful Spark ML pipeline stages to live ○ Including both feature transformers and estimators ● The why: Spark ML can’t keep up with every new algorithm ● Lots of cool ML on Spark tools exist, but many don’t play nice with Spark ML or together Pretend there is a cool looking logo from fiverr here :p
- 25. So now begins our adventure to add stages
- 26. So what does a pipeline stage look like? Must provide: ● Scala: transformSchema (used to validate input schema is reasonable) & copy ● Both: Either a “fit” (for estimator) or transform (for transformer) Often have: ● Params for configuration (so we can do meta-algorithms) Wendy Piersall
- 27. Building a simple transformer: class HardCodedWordCountStage(override val uid: String) extends Transformer { def this() = this(Identifiable.randomUID("hardcodedwordcount")) def copy(extra: ParamMap): HardCodedWordCountStage = { defaultCopy(extra) } ... } Not to be confused with the Transformers franchise from Hasbro and Tomy.
- 28. Verify the input schema is reasonable: override def transformSchema(schema: StructType): StructType = { // Check that the input type is a string val idx = schema.fieldIndex("happy_pandas") val field = schema.fields(idx) if (field.dataType != StringType) { throw new Exception(s"Input type ${field.dataType} did not match input type StringType") } // Add the return field schema.add(StructField("happy_panda_counts", IntegerType, false)) }
- 29. How is transformSchema used? ● When you call fit on a pipeline it calls transformSchema on the pipeline stages in order ● This is used to verify that things should work ● Ideally allows pipelines to fail fast when misconfigured, instead of at the final stage of a 48-hour process ● Doesn’t always work that way :p ● Not supported in Python (I’m sorry!) Tricia Hall
- 30. Do the “work” (e.g. predict labels or w/e): def transform(df: Dataset[_]): DataFrame = { val wordcount = udf { in: String => in.split(" ").size } df.select(col("*"), wordcount(df.col("happy_pandas")).as("happy_panda_counts")) } vic15
- 31. Do the “work” (e.g. call numpy): class StrLenPlus3Transformer(Model): @keyword_only def __init__(self): super(StrLenPlusKTransformer, self).__init__() def _transform(self, dataset): func = lambda x : len(x) + 3 retType = IntegerType() udf = UserDefinedFunction(func, retType) return dataset.withColumn( "magic", udf("input") ) vic15
- 32. What about configuring our stage? class ConfigurableWordCount(override val uid: String) extends Transformer { final val inputCol= new Param[String](this, "inputCol", "The input column") final val outputCol = new Param[String](this, "outputCol", "The output column") def setInputCol(value: String): this.type = set(inputCol, value) def setOutputCol(value: String): this.type = set(outputCol, value) Jason Wesley Upton
- 33. What about configuring our stage? class StrLenPlusKTransformer(Model, HasInputCol, HasOutputCol): # We need a parameter to configure k k = Param(Params._dummy(), "k", "amount to add to str len", typeConverter=TypeConverters.toInt) @keyword_only def __init__(self, k=None, inputCol=None, outputCol=None): super(StrLenPlusKTransformer, self).__init__() kwargs = self._input_kwargs self.setParams(**kwargs) Jason Wesley Upton
- 34. What about configuring our stage? @keyword_only def setParams(self, k=None, inputCol=None, outputCol=None): kwargs = self._input_kwargs return self._set(**kwargs) def setK(self, value): return self._set(k=value) def getK(self): return self.getOrDefault(self.k) Jason Wesley Upton
- 35. So why do we configure it that way? ● Allow meta algorithms to work on it ● Scala: ○ If you look inside of spark you’ll see “sharedParams.scala” for common params (like input column) ○ We can’t access those unless we pretend to be inside of org.apache.spark - so we have to make our own ● Python: Just import pyspark.ml.param.shared Tricia Hall
- 36. So how to make an estimator? ● Very similar, instead of directly providing transform provide a `fit` which returns a “model” which implements the estimator interface as shown above ● Also take a look at the algorithms in Spark itself (helpful traits you can mixin to take care of many common things). ● Let’s look at a simple one now! sneakerdog
- 37. A simple string indexer estimator class SimpleIndexer(override val uid: String) extends Estimator[SimpleIndexerModel] with SimpleIndexerParams { …. override def fit(dataset: Dataset[_]): SimpleIndexerModel = { import dataset.sparkSession.implicits._ val words = dataset.select(dataset($(inputCol)).as[String]).distinct .collect() new SimpleIndexerModel(uid, words) } }
- 38. Quick aside: What’ts that “$(inputCol)”? ● How you get access to a configuration parameter ● Inside stage only (external use getInputCol just like Java™ :p)
- 39. And our friend the transformer is back: class SimpleIndexerModel( override val uid: String, words: Array[String]) extends Model[SimpleIndexerModel] with SimpleIndexerParams { ... private val labelToIndex: Map[String, Double] = words.zipWithIndex. map{case (x, y) => (x, y.toDouble)}.toMap override def transform(dataset: Dataset[_]): DataFrame = { val indexer = udf { label: String => labelToIndex(label) } dataset.select(col("*"), indexer(dataset($(inputCol)).cast(StringType)).as($(outputCol))) Still not to be confused with the Transformers franchise from Hasbro and Tomy.
- 40. Ok so how do you make the train function? ● Read some papers on the algorithm(s) you care about ● Most likely some iterative approach (pro-tip: RDDs > Datasets for iterative) ○ Seth has some interesting work around pluggable optimizers ● Closed form solution? Go have a party!
- 41. What else can you add to your models? ● Put in an ML pipeline ● Do hyper-parameter tuning And if you have some coffee left over: ● Persistence* ○ MLWriter & MLReader give you the basics ○ You’ll have to do a lot of work yourself :( ● Serving* *With enough coffee. Not guaranteed.
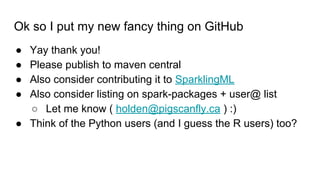
- 42. Ok so I put my new fancy thing on GitHub ● Yay thank you! ● Please publish to maven central ● Also consider contributing it to SparklingML ● Also consider listing on spark-packages + user@ list ○ Let me know ( [email protected] ) :) ● Think of the Python users (and I guess the R users) too?
- 43. Custom Estimators/Transformers in the Wild Classification/Regression xgboost Deep Learning! MXNet Feature Transformation FeatureHasher
- 44. More resources: ● High Performance Spark Example Repo has some sample models ○ Of course buy several copies of the book - it is the gift of the season :p ● The models inside of Spark itself (internal APIs though) ● Sparkling ML - So much fun! ● Nick Pentreath’s FeatureHasher ● O’Reilly radar blog post https://www.oreilly.com/learning/extend-structured-streami ng-for-spark-ml Captain Pancakes
- 45. Learning Spark Fast Data Processing with Spark (Out of Date) Fast Data Processing with Spark (2nd edition) Advanced Analytics with Spark Spark in Action High Performance SparkLearning PySpark
- 46. High Performance Spark! Available today! I brought one copy for one lucky person. The rest of you can buy it from that scrapy Seattle Book store :p * Early Release means extra mistakes, but also a chance to help us make a more awesome book.
- 47. And some upcoming talks: ● Kafak Summit (SF, August) ● Data Day Seattle (SEA, Sept) ● Strata New York (NYC, Sept) ● Strange Loop (Sept/Oct) ● Spark Summit EU (Dublin, October) ● November: Possibly Big Data Spain + Bee Scala (TBD) ● Strata Singapore (Singapore, December) ● ScalaX (London, December) ● Know of interesting conferences/webinar things that should be on my radar? Let me know!
- 48. k thnx bye :) If you care about Spark testing and don’t hate surveys: http://bit.ly/holdenTestingSpark Will tweet results “eventually” @holdenkarau Any PySpark Users: Have some simple UDFs you wish ran faster you are willing to share?: http://bit.ly/pySparkUDF Pssst: Have feedback on the presentation? Give me a shout ([email protected]) if you feel comfortable doing so :)
- 50. Cross-validation because saving a test set is effort ● Automagically* fit your model params ● Because thinking is effort ● org.apache.spark.ml.tuning has the tools Jonathan Kotta
- 51. Cross-validation because saving a test set is effort & a reason to integrate // ParamGridBuilder constructs an Array of parameter combinations. val paramGrid: Array[ParamMap] = new ParamGridBuilder() .addGrid(nb.smoothing, Array(0.1, 0.5, 1.0, 2.0)) .build() val cv = new CrossValidator() .setEstimator(pipeline) .setEstimatorParamMaps(paramGrid) val cvModel = cv.fit(df) val bestModel = cvModel.bestModel Jonathan Kotta
- 52. So what does a pipeline stage look like? Are either an: ● Estimator - has a method called “fit” which returns a Transformer (e.g. NaiveBayes, etc.) ● Transformer - no need to train can directly transform (e.g. HashingTF, VectorAssembler, etc.) (with transform) Wendy Piersall
- 53. We’ve left out a lot of “transformSchema”... ● It is necessary (but I’m lazy) ● But there are helper classes that can implement some of the boiler plate we’ve been skipping ● Classifier & Estimator base classes are your friends ● They provide transformSchema
- 54. Let’s make a Classifier* :) // Example only - not for production use. class SimpleNaiveBayes(val uid: String) extends Classifier[Vector, SimpleNaiveBayes, SimpleNaiveBayesModel] { Input type Trained Model
- 55. Let’s make a Classifier* :) override def train(ds: Dataset[_]): SimpleNaiveBayesModel = { import ds.sparkSession.implicits._ ds.cache() …. … …. }
- 56. If you reallllly want to see inside the ...s (1/5) // Get the number of features by peaking at the first row val numFeatures: Integer = ds.select(col($(featuresCol))).head .get(0).asInstanceOf[Vector].size // Determine the number of records for each class val groupedByLabel = ds.select(col($(labelCol)).as[Double]).groupByKey(x => x) val classCounts = groupedByLabel.agg(count("*").as[Long]) .sort(col("value")).collect().toMap // Select the labels and features so we can more easily map over them. // Note: we do this as a DataFrame using the untyped API because the Vector // UDT is no longer public. val df = ds.select(col($(labelCol)).cast(DoubleType), col($(featuresCol)))
- 57. If you reallllly want to see inside the ...s (2/5) // Note: you can use getNumClasses & extractLabeledPoints to get an RDD instead // Using the RDD approach is common when integrating with legacy machine learning code // or iterative algorithms which can create large query plans. // Here we use `Datasets` since neither of those apply. // Compute the number of documents val numDocs = ds.count // Get the number of classes. // Note this estimator assumes they start at 0 and go to numClasses val numClasses = getNumClasses(ds)
- 58. If you reallllly want to see inside the ...s (3/5) // Figure out the non-zero frequency of each feature for each label and // output label index pairs using a case clas to make it easier to work with. val labelCounts: Dataset[LabeledToken] = df.flatMap { case Row(label: Double, features: Vector) => features.toArray.zip(Stream from 1) .filter{vIdx => vIdx._2 == 1.0} .map{case (v, idx) => LabeledToken(label, idx)} } // Use the typed Dataset aggregation API to count the number of non-zero // features for each label-feature index. val aggregatedCounts: Array[((Double, Integer), Long)] = labelCounts .groupByKey(x => (x.label, x.index)) .agg(count("*").as[Long]).collect() val theta = Array.fill(numClasses)(new Array[Double](numFeatures))
- 59. If you reallllly want to see inside the ...s (4/5) // Compute the denominator for the general prioirs val piLogDenom = math.log(numDocs + numClasses) // Compute the priors for each class val pi = classCounts.map{case(_, cc) => math.log(cc.toDouble) - piLogDenom }.toArray // For each label/feature update the probabilities aggregatedCounts.foreach{case ((label, featureIndex), count) => // log of number of documents for this label + 2.0 (smoothing) val thetaLogDenom = math.log( classCounts.get(label).map(_.toDouble).getOrElse(0.0) + 2.0) theta(label.toInt)(featureIndex) = math.log(count + 1.0) - thetaLogDenom } // Unpersist now that we are done computing everything ds.unpersist()
- 60. If you reallllly want to see inside the ...s (5/5) // Construct a model new SimpleNaiveBayesModel(uid, numClasses, numFeatures, Vectors.dense(pi), new DenseMatrix(numClasses, theta(0).length, theta.flatten, true)) } override def copy(extra: ParamMap) = { defaultCopy(extra) } }
- 61. What is Spark? ● General purpose distributed system ○ With a really nice API including Python :) ● Apache project (one of the most active) ● Much faster than Hadoop Map/Reduce ● Good when data is too big for a single machine ● Built on top of two abstractions for distributed data: RDDs & Datasets
- 62. DataFrames & Datasets Totally the future ● Distributed collection ● Recomputed on node failure ● Distributes data & work across the cluster ● Lazily evaluated (transformations & actions) ● Has runtime schema information ● Allows for relational queries & supports SQL ● Declarative - many optimizations applied automagically ● Input for Spark Machine Learning Helen Olney
- 63. What is the performance like? Andrew Skudder
- 64. Spark ML pipelines Tokenizer HashingTF String Indexer Naive Bayes Tokenizer HashingTF String Indexer Naive Bayes fit(df) Estimator Transformer ● Consist of different stages (estimators or transformers) ● Themselves are an estimator We are going to build a stage together!
- 65. Minimal data prep: ● At a minimum most algorithms in Spark work on feature vectors of doubles (and if labeled - doubles too) Imports: import org.apache.spark.ml._ import org.apache.spark.ml.feature._ import org.apache.spark.ml.classification._ import org.apache.spark.ml.linalg.{Vector => SparkVector} Huang Yun Chung
- 66. Minimal prep continued // Combines a list of double input features into a vector val assembler = new VectorAssembler() assembler.setInputCols(Array("age", "education-num")) // String indexer converts a set of strings into doubles val sb = new StringIndexer() sb.setInputCol("category").setOutputCol("category-index") // Can be used to combine pipeline components together val pipeline = new Pipeline() pipeline.setStages(Array(assembler, sb)) Huang Yun Chung
- 67. Minimal prep continued val assembler = new VectorAssembler() assembler.setInputCols(Array("gre", "gpa", "prestige")) val si = new StringIndexer() si.setInputCol("admit").setOutputCol("label") val pipeline = new Pipeline() pipeline.setStages(Array(assembler, si)) Huang Yun Chung +-----+-----+----+--------+----------------+-----+ |admit| gre| gpa|prestige| features|label| +-----+-----+----+--------+----------------+-----+ | no|380.0|3.61| 3.0|[380.0,3.61,3.0]| 0.0| | yes|660.0|3.67| 3.0|[660.0,3.67,3.0]| 1.0| | yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]| 1.0| | yes|640.0|3.19| 4.0|[640.0,3.19,4.0]| 1.0| | no|520.0|2.93| 4.0|[520.0,2.93,4.0]| 0.0| +-----+-----+----+--------+----------------+-----+ +-----+-----+----+--------+----------------+ |admit| gre| gpa|prestige| features| +-----+-----+----+--------+----------------+ | no|380.0|3.61| 3.0|[380.0,3.61,3.0]| | yes|660.0|3.67| 3.0|[660.0,3.67,3.0]| | yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]| | yes|640.0|3.19| 4.0|[640.0,3.19,4.0]| | no|520.0|2.93| 4.0|[520.0,2.93,4.0]| +-----+-----+----+--------+----------------+ +-----+-----+----+--------+ |admit| gre| gpa|prestige| +-----+-----+----+--------+ | no|380.0|3.61| 3.0| | yes|660.0|3.67| 3.0| | yes|800.0| 4.0| 1.0| | yes|640.0|3.19| 4.0| | no|520.0|2.93| 4.0| +-----+-----+----+--------+
- 68. So a bit more about that pipeline ● Each of our previous components has “fit” & “transform” stage ● Constructing the pipeline this way makes it easier to work with (only need to call one fit & one transform) ● Can re-use the fitted model on future data val model = pipeline.fit(df) val prepared = model.transform(df) Andrey
- 69. Let's train a model on our prepared data: // Specify model val dt = new DecisionTreeClassifier() dt.setFeaturesCol("features") dt.setPredictionCol("prediction") // Fit it val dtModel = dt.fit(prepared)
- 70. Or wait let's just add it to the pipeline: // Specify model val dt = new DecisionTreeClassifier() dt.setFeaturesCol("features") dt.setPredictionCol("prediction") // Add to the pipeline pipeline.setStages(Array(assembler, si, dt)) pipelineModel = pipeline.fit(df)
- 71. And predict the results on the same data: pipelineModel.transform(df).select("prediction", "label").take(20) +----------+-----+ |prediction|label| +----------+-----+ | 0.0| 0.0| | 0.0| 1.0| | 1.0| 1.0| | 1.0| 1.0| | 0.0| 0.0| +----------+-----+