Downloaded 126 times












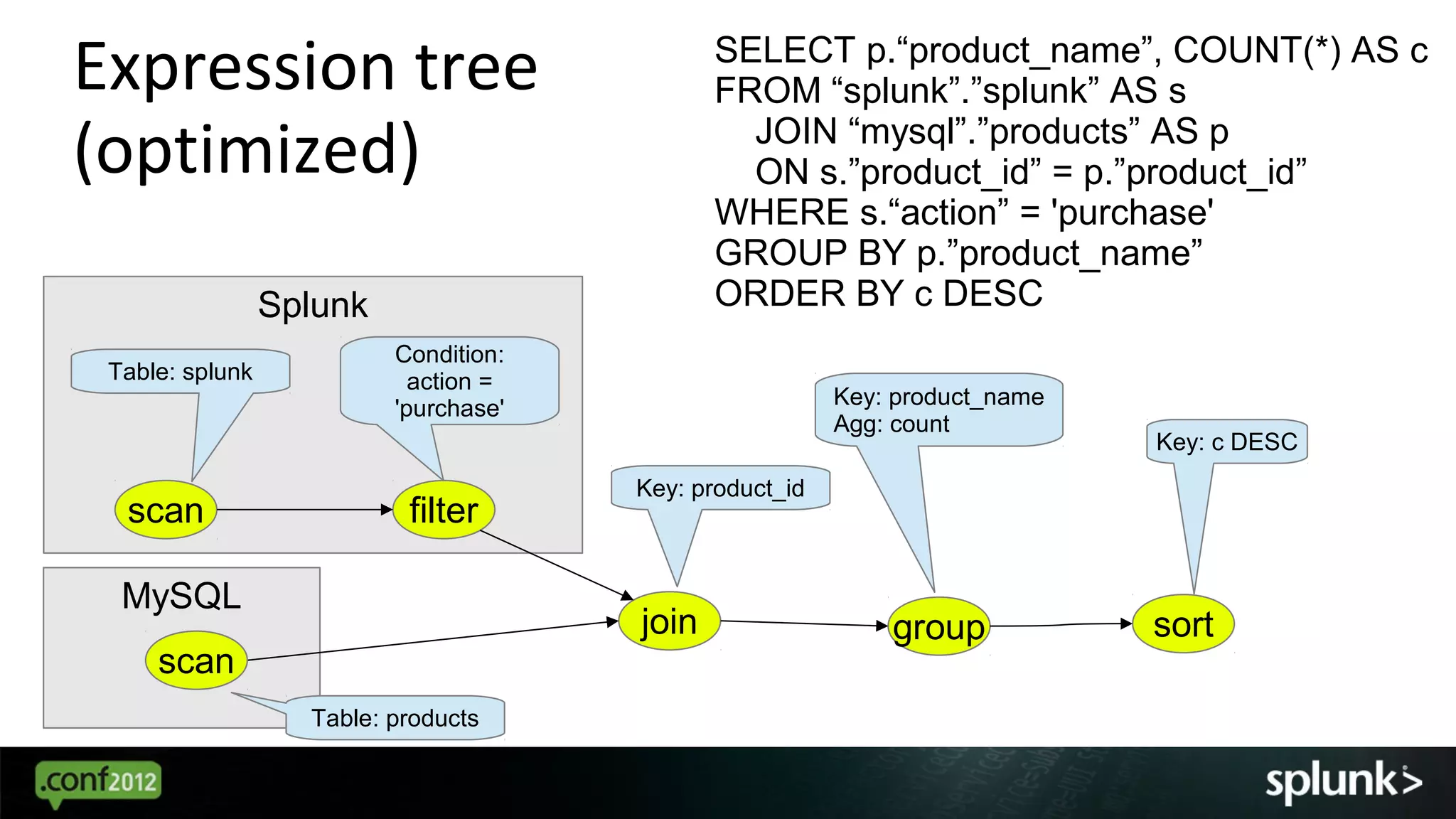














The document discusses how to integrate Splunk with various data sources using the Optiq project, aimed at enhancing data access within enterprises. It provides examples of SQL queries to effectively retrieve and join data from Splunk and MySQL, illustrating the functionality of the Optiq adapter. The author emphasizes that Optiq is a smart JDBC driver framework that can facilitate better data management and proposes future improvements for Splunk's data querying capabilities.
































































































