Intro to Big Data and NoSQL

This document provides an introduction to big data and NoSQL databases. It begins with an introduction of the presenter. It then discusses how the era of big data came to be due to limitations of traditional relational databases and scaling approaches. The document introduces different NoSQL data models including document, key-value, graph and column-oriented databases. It provides examples of NoSQL databases that use each data model. The document discusses how NoSQL databases are better suited than relational databases for big data problems and provides a real-world example of Twitter's use of FlockDB. It concludes by discussing approaches for working with big data using MapReduce and provides examples of using MongoDB and Azure for big data.









































![MongoDB Example
> // map function > // reduce function
> m = function(){ > r = function( key , values ){
... this.tags.forEach( ... var total = 0;
... function(z){ ... for ( var i=0; i<values.length; i++ )
... emit( z , { count : 1 } ... total += values[i].count;
); ... return { count : total };
... } ...};
... );
...};
> // execute
> res = db.things.mapReduce(m, r, { out : "myoutput" } );
42](https://image.slidesharecdn.com/ddemsak-introtobigdataandnosql-120422051419-phpapp01/85/Intro-to-Big-Data-and-NoSQL-42-320.jpg)





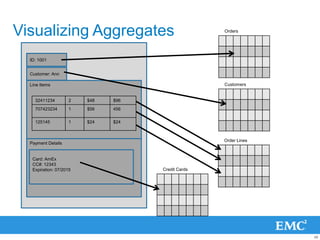
![Visualizing Aggregates
ID: 1001
Customer: Ann
Line Items
32411234 2 $48 $96 {
“SalesOrdersView”:{
707423234 1 $56 456 ID: 1001,
Customer: Ann,
125145 1 $24 $24 LineItems: []
……………..
…………….
……………..
Payment Details
}
}
Card: AmEx
CC#: 12343
Expiration: 07/2015
49](https://image.slidesharecdn.com/ddemsak-introtobigdataandnosql-120422051419-phpapp01/85/Intro-to-Big-Data-and-NoSQL-49-320.jpg)



More Related Content








































Similar to Intro to Big Data and NoSQL (20)







































Intro to Big Data and NoSQL
- 1. Introduction to Big Data and NoSQL SQL Azure Saturday April, 21, 2012 Don Demsak Advisory Solutions Architect EMC Consulting www.donxml.com 1
- 2. Meet Don • Advisory Solutions Architect – EMC Consulting • Application Architecture, Development & Design • DonXml.com, Twitter: donxml • Email – [email protected] • SlideShare - http://www.slideshare.net/dondemsak 2
- 3. The era of Big Data 3
- 4. How did we get here? • Expensive • Monoculture – Processors – Limit CPU cycles – Disk space – Limit disk space – Memory – Limit memory – Operating Systems – Limited OS – Software Development – Programmers – Limited Software – Programmers • Mono-lingual • Mono-persistence 4
- 5. Typical RDBMS Implementations • Fixed table schemas • Small but frequent reads/writes • Large batch transactions • Focus on ACID – Atomicity – Consistency – Isolation – Durability 5
- 6. How we scale RDBMS implementations 6
- 7. 1st Step – Build a relational database Database 7
- 8. 2nd Step – Table Partitioning p1 p2 p3 Database 8
- 9. 3rd Step – Database Partitioning Browser Web Tier B/L Tier Database Customer #1 Browser Web Tier B/L Tier Database Customer #2 Browser Web Tier B/L Tier Database Customer #3 9
- 10. 4th Step – Move to the cloud? Browser Web Tier B/L Tier SQL Azure Federation Customer #1 SQL Azure Browser Web Tier B/L Tier Federation Customer #2 SQL Azure Browser Web Tier B/L Tier Federation Customer #3 10
- 11. There has to be other ways 11
- 12. Polyglot Persistence 12
- 13. Polyglot Programmer 13
- 14. 14
- 15. Where Did NoSQL Originate? • 1998 - Carlo Strozzi – NoSQL project - lightweight open-source relational DB with no SQL interface • 2009 - Eric Evans & Johan Oskarsson of Last.fm wanted to organize an event to discuss open- source distributed databases 15
- 16. NoSQL (loose) Definition • (often) Open source • Non-relational • Distributed • (often) don‟t guarantee ACID 16
- 17. Atlanta 2009 • No:sql(east) conference – select fun, profit from real_world where relational=false • Billed as “conference of no-rel datastores” 17
- 18. Types Of NoSQL Data Stores 18
- 19. 5 Groups of Data Models Relational Document Key Value Graph Column Family 19
- 20. Document Store • Apache Jackrabbit • CouchDB • MongoDB • SimpleDB • XML Databases – MarkLogic Server – eXist. 20
- 21. Document? • Okay think of a web page... – Relational model requires column/tag – Lots of empty columns – Wasted space • Document model just stores the pages as is – Saves on space – Very flexible. 21
- 22. Graph Storage • AllegroGraph • Core Data • Neo4j • DEX • FlockDB • Microsoft Trinity (research project) – http://research.microsoft.com/en-us/projects/trinity/ 22
- 23. What‟s a graph? • Graph consists of – Node („stations‟ of the graph) – Edges (lines between them) • FlockDB – Created by the Twitter folks – Nodes = Users – Edges = Nature of relationship between nodes. 23
- 24. Key/Value Stores • On disk • Cache in Ram • Eventually Consistent – Weak Definition • “If no updates occur for a period, eventually all updates will propagate through the system and all replicas will be consistent” – Strong Definition • “for a given update and a given replica eventually either the update reaches the replica or the replica retires” • Ordered – Distributed Hash Table allows lexicographical processing 24
- 25. Key/Value Examples • Azure AppFabric Cache • Memcache-d • VMWare vFabric GemFire 25
- 26. Object Databases • Db4o • GemStone/S • InterSystems Caché • Objectivity/DB • ZODB 26
- 27. Tabular • BigTable • Mnesia • Hbase • Hypertable • Azure Table Storage • SQL Server 2012 27
- 28. Azure Table Storage Demo 28
- 29. Big Data 29
- 30. Big Data Definition • Volumes & volumes of data • Unstructured • Semi-structured • Not suited for Relational Databases • Often utilizes MapReduce frameworks 30
- 31. Big Data Examples • Cassandra • Hadoop • Greenplum • Azure Storage • EMC Atmos • Amazon S3 • SQL Azure (with Federations support) 31
- 32. Real World Example • Twitter – The challenges • Needs to store many graphs Who you are following Who‟s following you Who you receive phone notifications from etc • To deliver a tweet requires rapid paging of followers • Heavy write load as followers are added and removed • Set arithmetic for @mentions (intersection of users). 32
- 33. What did they try? • Started with Relational Databases • Tried Key-Value storage of denormalized lists • Did it work? – Nope • Either good at Handling the write load Or paging large amounts of data But not both 33
- 34. What did they need? • Simplest possible thing that would work • Allow for horizontal partitioning • Allow write operations to • Arrive out of order – Or be processed more than once – Failures should result in redundant work • Not lost work! 34
- 35. The Result was FlockDB • Stores graph data • Not optimized for graph traversal operations • Optimized for large adjacency lists – List of all edges in a graph • Key is the edge value a set of the node end points • Optimized for fast read and write • Optimized for page-able set arithmetic. 35
- 36. How Does it Work? • Stores graphs as sets of edges between nodes • Data is partitioned by node – All queries can be answered by a single partition • Write operations are idempotent – Can be applied multiple times without changing the result • And commutative – Changing the order of operands doesn‟t change the result. 36
- 37. Working With Big Data 37
- 38. ACID • Atomicity – All or Nothing • Consistency – Valid according to all defined rules • Isolation – No transaction should be able to interfere with another transaction • Durability – Once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors 38
- 39. BASE • Basically Available – High availability but not always consistent • Soft state – Background cleanup mechanism • Eventual consistency – Given a sufficiently long period of time over which no changes are sent, all updates can be expected to propagate eventually through the system and all the replicas will be consistent. 39
- 40. Traditional (relational) Approach Extract Transactional Data Store Transform Data Warehouse Load 40
- 41. Big Data Approach • MapReduce Pattern/Framework – an Input Reader – Map Function – To transform to a common shape (format) – a partition function – a compare function – Reduce Function – an Output Writer 41
- 42. MongoDB Example > // map function > // reduce function > m = function(){ > r = function( key , values ){ ... this.tags.forEach( ... var total = 0; ... function(z){ ... for ( var i=0; i<values.length; i++ ) ... emit( z , { count : 1 } ... total += values[i].count; ); ... return { count : total }; ... } ...}; ... ); ...}; > // execute > res = db.things.mapReduce(m, r, { out : "myoutput" } ); 42
- 43. MongoDB Demo 43
- 44. Big Data on Azure • Azure Table Storage – Azure Service Bus • SQL Azure Federations • MongoDB on Azure – http://www.mongodb.org/display/DOCS/MongoDB+on+Azure • Hadoop on Azure – https://www.hadooponazure.com/ 44
- 45. Using Azure for Computing Data Data Worker Data Client Master Worker Job/Task Scheduler Worker Data 45
- 46. Moving to Event Based Architecture Web Role Worker Role Web Role Worker Role Web Role Worker Role Req Req Req Queue Web Role Worker Role Web Role Monitor queue Worker Role length against Web Role user‟s expectations Worker Role 46
- 47. Aggregate Stores 47
- 48. Visualizing Aggregates Orders ID: 1001 Customer: Ann Line Items Customers 32411234 2 $48 $96 707423234 1 $56 456 125145 1 $24 $24 Order Lines Payment Details Card: AmEx CC#: 12343 Expiration: 07/2015 Credit Cards 48
- 49. Visualizing Aggregates ID: 1001 Customer: Ann Line Items 32411234 2 $48 $96 { “SalesOrdersView”:{ 707423234 1 $56 456 ID: 1001, Customer: Ann, 125145 1 $24 $24 LineItems: [] …………….. ……………. …………….. Payment Details } } Card: AmEx CC#: 12343 Expiration: 07/2015 49
- 50. MongoDB on Azure Demo 50
- 51. Next Steps • Learn a NoSQL product – Great place to start – AppFabric Cache, Azure Table Storage, MongoDB • Pick a new programming language to learn – Not Java or C#/VB – Node.js, JavaScript, F# 51
- 52. THANK YOU 52
Editor's Notes
- #20: t least four groups of data model: key-value, document, column-family, and graph. Looking at this list, there's a big similarity between the first three - all have a fundamental unit of storage which is a rich structure of closely related data: for key-value stores it's the value, for document stores it's the document, and for column-family stores it's the column family. In DDD terms, this group of data is an aggregate.A Graph Database stores data structured in the Nodes and Relationships of a graphColumn Family (BigTable-style) databases are an evolution of key-value, using "families" to allow grouping of rows. The rise of NoSQL databases has been driven primarily by the desire to store data effectively on large clusters - such as the setups used by Google and Amazon. Relational databases were not designed with clusters in mind, which is why people have cast around for an alternative. Storing aggregates as fundamental units makes a lot of sense for running on a cluster. Aggregates make natural units for distribution strategies such as sharding, since you have a large clump of data that you expect to be accessed together.The Relational ModelThe relational model provides for the storage of records that are made up of tuples. Records are stored in tables. Tables are defined by a schema, which determines what columns are in the table. Columns have a name and a type. All records within a table fit that table's definition. SQL is a query language designed to operate over tables. SQL provides syntax for finding records that meet criteria, as well as for relating records in one table to another via joins; a join finds a record in one table based on its relationship to a record in another table.Records can be created (inserted) or deleted. Fields within a record can be updated individually.Implementations of the relational model usually provide transactions, which provide a means to make modifications spanning multiple records atomically.In terms of what programming languages provide, tables are like arrays or lists of records or structures. For high performance access, tables can be indexed in various ways using b-trees or hash maps.Key-Value StoresKey-Value stores provide access to a value based on a key.The key-value pair can be created (inserted), or deleted. The value associated with a key may be updated.Key-value stores don't usually provide transactions.In terms of what programming languages provide, key-value stores resemble hash tables; these have many names: HashMap (Java), hash (Perl), dict (Python), associative array (PHP), boost::unordered_map<...> (C++).Key-value stores provide one implicit index on the key itself.A key-value store may not sound like the most useful thing, but a lot of information can be stored in the value. It is quite common for the value to be an XML document, a JSON object, or some other serialized form. The key point here is that the storage engine is not aware of the internal structure of the value. It is up to the client application to interpet the value andmanage its contents. The value can only be written as a whole; if the client is storing a JSON object, and only wants to update one field, the entire value must be fetched, the new value substituted, and then the entire value must be written back.The inability to fetch data by anything other than one key may appear limited, but there are workarounds. If the application requires a secondary index, the application can maintain one itself. To do this, the application manages a second collection of key-value pairs where the key is the value of another field in the first collection, and the value is the primary key in the first collection. Because there are no transactions that can be used to make sure that the secondary index is kept synchronized with the original collection, any application that does this would be wise to have a periodic syncing process to clean up after any partial changes that occur due to application crashes, bugs, or errors.Document StoresDocument stores provide access to structured data, but unlike the relational model, there may not be a schema that is enforced. In essence, the application stores bags of key-value pairs. In order to operate in this environment, the application adopts some conventions about how to deal with differing bags it may retrieve, or it may take advantage of the storage engine's ability to put different documents in different collections, which the application will use to manage its data.Unlike a relational store, document stores usually support nested structures. For example, for document stores that support XML or JSON documents, the value of a field may be something that looks like another document. Document stores can also support array or list-valued keys.Unlike a key-value store, document stores are aware of the internal structure of the document. This allows the storage engine to support secondary indexes directly, allowing for efficient queries on any field. The ability to support nested document storage leads to query languages that can be used to search for items nested inside others; XQuery is one example of this. MongoDB supports some similar functionality by allowing the specification of JSON field paths in queries.Column StoresColumn stores are like relational stores, except that they flip the data around. Instead of storing records, column stores store all the values for a column together in a stream. An index provides a means to get column values for any particular record.Map-reduce implementations such as Hadoop are most efficient if they can stream in their data. Column stores work particularly well for that. As a result, stores like HBase and Hypertable are often used as non-relational data warehouses to feed map-reduce for analytics.A relational-style column scalar may not be the most useful for analytics, so users often store more complex structures in columns. This manifests directly in Cassandra, which introduces the notion of "column families," which get treated as a "super-column."Column-oriented stores support retrieving records, but this requires fetching the column values from their individual columns and re-assembling the record.Graph DatabasesGraph databases store vertices and the edges between them. Some support adding annotations to the vertices and/or edges. This can be used to model things like social graphs (people are represented by vertices, and their relationships are the edges), or real-world objects (components are represented by vertices, and their connectedness is represented by edges). The content on IMDB is tied together by a graph: movies are related to to the actors in them, and actors are related to the movies they star in, forming a large complex graph.The access and query languages for graph databases are the most different of the set of those discussed here. Graph database query languages are generally about finding paths in the graph based on either endpoints, or constraints on attributes of the paths between endpoints; one example is SPARQL.
- #21: Need to go into the EMC offerings