SQL Server Performance Tuning Essentials
Download as pptx, pdf3 likes1,285 views

SQL Serverのパフォーマンスチューニングに関する資料です。





































![durationの差と実行プランの違い
• インデックス効いてる
• select * from [Member] where LoginName = 'HunterGreen45744363'
• インデックス効いてない
• select * from [Member] with(index(PK_Member)) where LoginName =
'HunterGreen45744363’](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-38-320.jpg)






![クラスタ化インデックスの定義
[MemberID]で並び替えられたツリー構造になっている
ALTER TABLE [dbo].[Member] ADD CONSTRAINT
[PK_Member] PRIMARY KEY CLUSTERED
(
[MemberID] ASC
)](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-45-320.jpg)











![インデックスが効く(=seek)条件
例:「インデックスの並び順」=「where句で指定した条件」
ALTER TABLE [dbo].[Member] ADD CONSTRAINT [PK_Member] PRIMARY
KEY CLUSTERED
(
[MemberID] ASC
)
効く:select * from Member where MemberID = 18629768
効かない:select * from Member where LoginName = 'Janita1317'
インデックス≠万能薬](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-57-320.jpg)





![そのための新しいインデックス
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON
[dbo].[Member]
(
[LoginName] ASC
)](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-63-320.jpg)


![付加列インデックス
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON
[dbo].[Member]
(
[LoginName] ASC
) INCLUDE (RegistDate)](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-66-320.jpg)

![複合インデックス
CREATE NONCLUSTERED INDEX
[IX_Member_Sei_PrefectureID]
ON [dbo].[Member]
(
[Sei] ASC,
[PrefectureID] ASC
)
複合インデックス = 複数のカラムをインデックスキーに指定](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-68-320.jpg)




![LoginName MemberID RegistDate
a1 1 2020/10/1
a2 2 2020/10/2
… … …
b1 25000 2020/10/3
SELECT LoginName, RegistDate, Sei FROM Member WHERE LoginName = 'b1'
リーフページに[Sei]が無い
非クラスタ化インデックス
実データ
MemberID LoginName … Sei
1 a1 … Asai
2 a2 … Tanaka
… … … …
25000 b1 … Yokota
クラスタ化インデックス
キー参照 (MemberID =
25000でIndex Seek)](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-73-320.jpg)
![カバリングインデックス
• 上記ようなインデックスが作成されている場合
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member]
([LoginName] ASC) INCLUDE (RegistDate)
キー参照が発生しないインデックスを「カバリングインデックス」
SELECT LoginName, RegistDate FROM Member WHERE LoginName = 'Tawny265167'
インデックスキー
インデックスキー INCLUDE
カラム
クエリに必要なカラムをカバーするインデックスになっている
=カバリングインデックス](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-74-320.jpg)

![カバリングインデックスのポイント
• カバリングかどうかはクエリごとに決まる
• インデックスは下記のクエリに対して「カバリング」
• インデックスは 下記のクエリに対して「カバリングではない」
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member]
([LoginName] ASC) INCLUDE (RegistDate)
SELECT LoginName, RegistDate FROM Member WHERE LoginName = 'Tawny265167'
SELECT LoginName, RegistDate, Sei FROM Member WHERE LoginName = 'Tawny265167'](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-76-320.jpg)









![回答
※MemberIDは主キーなので自動的にインデックスに含まれる
CREATE NONCLUSTERED INDEX [IX_Member_Tel]
ON [dbo].[Member] ([Tel])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-86-320.jpg)

![回答①
CREATE NONCLUSTERED INDEX [IX_Memer_LoginName]
ON [dbo].[Member] ([LoginName])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-88-320.jpg)
![回答②:付加列を追加
CREATE NONCLUSTERED INDEX [IX_Memer_LoginName]
ON [dbo].[Member] ([LoginName]) INCLUDE ([GenderID],
[PrefectureID])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-89-320.jpg)




















































![回答:ソートをカットするインデックス
create index [IX_MemberEMail_Email] on [MemberEmail] ([Email] asc)](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-145-320.jpg)

![回答:order byとキーの並び順を同じにする
create index [IX_MemberEMail_DeleteFlag_Email] on [MemberEmail]
([DeleteFlag] asc, [EMail] desc)](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-147-320.jpg)

![回答:クエリ実行順序とキーの順番を同じにする
create index [IX_MemberEMail_DeleteFlag_Email] on
[MemberEmail]([DeleteFlag], [EMail])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-149-320.jpg)











































![回答:MemberEMailのScanをSeekにしたい
CREATE NONCLUSTERED INDEX [IX_MemberEmail_MemberID]
ON [dbo].[MemberEMail] ([MemberID])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-194-320.jpg)


![回答:まずMemberのScanをSeekにする
CREATE NONCLUSTERED INDEX [IX_Member_Tel]
ON [dbo].[Member] ([Tel])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-197-320.jpg)

![次にMemberEMailのScanをSeekにする
CREATE NONCLUSTERED INDEX [IX_MemberEMail_MemberID]
ON [dbo].[MemberEMail] ([MemberID])
INCLUDE ([MainFlag], [DeleteFlag])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-199-320.jpg)























![インデックス作成のアンチパターン
各クエリごとに最適なインデックスを作成する
⇒ 似たインデックスが大量に作成される
CREATE NONCLUSTERED INDEX
[IX_Member_LoginName] ON [dbo].[Member]
(
[LoginName] ASC
) INCLUDE (RegistDate)
CREATE NONCLUSTERED INDEX
[IX_Member_LoginName2] ON [dbo].[Member]
(
[LoginName] ASC
) INCLUDE (Sei, Mei)
CREATE NONCLUSTERED INDEX
[IX_Member_LoginName3] ON [dbo].[Member]
(
[LoginName] ASC, [RegistDate] ASC
) INCLUDE (Sei, Mei)
CREATE NONCLUSTERED INDEX
[IX_Member_LoginName4] ON [dbo].[Member]
(
[LoginName] ASC
) INCLUDE (DeleteFlag)](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-223-320.jpg)
![CREATE NONCLUSTERED INDEX
[IX_Member_LoginName] ON [dbo].[Member]
(
[LoginName] ASC
) INCLUDE (RegistDate)
CREATE NONCLUSTERED INDEX
[IX_Member_LoginName2] ON [dbo].[Member]
(
[LoginName] ASC
) INCLUDE (Sei, Mei)
CREATE NONCLUSTERED INDEX
[IX_Member_LoginName3] ON [dbo].[Member]
(
[LoginName] ASC, [RegistDate] ASC
) INCLUDE (Sei, Mei)
CREATE NONCLUSTERED INDEX
[IX_Member_LoginName4] ON [dbo].[Member]
(
[LoginName] ASC
) INCLUDE (DeleteFlag)
CREATE NONCLUSTERED INDEX [IX_Member_LoginName]
ON [dbo].[Member]
(
[LoginName] ASC , [RegistDate] ASC
) INCLUDE (RegistDate, Sei, Mei, DeleteFlag)](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-224-320.jpg)


![必要最小限のインデックスを設計する
SELECT句でしか使わないカラムは基本的には付加列にする
select Sei, Mei from Member where LoginName = 'Test'
〇
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName])
INCLUDE ([Sei], [Mei])
×
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName], [Sei],
[Mei])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-227-320.jpg)

![付加列にしたインデックスの場合
・既存のインデックスを一度DROPして作り直せばOK
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName])
INCLUDE ([Sei], [Mei])
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName],
[DeleteFlag])
INCLUDE ([Sei], [Mei])
・ひとつのインデックスで2種類のクエリに対応可能](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-229-320.jpg)
![CREATE NONCLUSTERED INDEX [IX_Memaber_LoginName] ON [dbo].[Member]
([LoginName], [DeleteFlag])
INCLUDE ([Sei], [Mei])
select Sei, Mei from Member where LoginName like 'Te%' and DeleteFlag = 1
select Sei, Mei from Member where LoginName = 'Test'](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-230-320.jpg)
![付加列にしないインデックスの場合
• 追加で別のインデックスを作るしかなくなる
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName],
[Sei], [Mei])
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName],
[DeleteFlag], [Sei], [Mei])
• このインデックスにまとめようとするのはNG。なぜか?](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-231-320.jpg)
![• インデックスを修正する時点でプロダクション環境で
実行されている全クエリを把握するのは難しい
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName],
[Sei], [Mei])
select * from Member where LoginName = 'Test' and Sei = 'aaa' and Mei = 'bbb'
• この既存インデックスだけみると、下記のようなクエリが
すでに実行されていると考えるのが妥当
・よってインデックスを増やすしかなくなる](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-232-320.jpg)
![• 結果的に以下のふたつのインデックスを作成する必要が出てくる
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member]
([LoginName], [Sei], [Mei])
CREATE NONCLUSTERED INDEX [IX_Member_LoginName2] ON [dbo].[Member]
([LoginName], [DeleteFlag], [Sei], [Mei])
• 無駄な容量や更新時のコスト増につながる](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-233-320.jpg)
![・一般化:良いselectivityが得られる最小カラム構成をとる
例:MemberテーブルはLoginNameでUniqueとなる性質がある
↓これが0レコード
select LoginName from Member group by LoginName having count(*) > 1
select Sei, Mei from Member where LoginName = 'Test' and DeleteFlag = 1
CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName])
INCLUDE ([Sei], [Mei], [DeleteFlag])
・したがって、上記のクエリのインデックスは下記でOK](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-234-320.jpg)














![問題:全体最適な観点でインデックスを再設計
してください
①
CREATE INDEX [IX_Member_Tel] ON [Member] ([tel]) INCLUDE ([RegistDate])
②
CREATE INDEX [IX_Member_LoginName] ON [Member] ([LoginName]) INCLUDE ([Sei], [Mei])
③
CREATE INDEX [IX_Member_LoginName2] ON [Member] ([LoginName])
INCLUDE ([GenderID], [PrefectureID])
④
CREATE INDEX [IX_Member_DeleteFlag_RegistDate] ON [Member] ([DeleteFlag], [RegistDate])
⑤
CREATE INDEX [IX_Member_LoginName_HashedPassword] ON [Member] ([LoginName],
[HashedPassword]) INCLUDE ([DeleteFlag])
⑥
CREATE INDEX [IX_Member_Tel_DeleteFlag] ON [Member] ([tel], [DeleteFlag])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-249-320.jpg)

![解説①
① + ⑥
CREATE INDEX [IX_Member_Tel_DeleteFlag] ON [Member] ([tel], [DeleteFlag])
INCLUDE ([RegistDate])
①
CREATE INDEX [IX_Member_Tel] ON [Member] ([tel]) INCLUDE ([RegistDate])
⑥
CREATE INDEX [IX_Member_Tel_DeleteFlag] ON[Member] ([tel], [DeleteFlag])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-251-320.jpg)
![解説②
② + ③ + ⑤
CREATE INDEX [IX_Member_LoginName] ON [Member] ([LoginName], [HashedPassword])
INCLUDE ([Sei], [Mei], [GenderID], [PrefectureID], [DeleteFlag])
②
CREATE INDEX [IX_Member_LoginName] ON [Member] ([LoginName]) INCLUDE ([Sei], [Mei])
③
CREATE INDEX [IX_Member_LoginName2] ON [Member] ([LoginName])
INCLUDE ([GenderID], [PrefectureID])
⑤
CREATE INDEX [IX_Member_LoginName_HashedPassword] ON [Member] ([LoginName], [HashedPassword])
INCLUDE ([DeleteFlag])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-252-320.jpg)
![最終的な回答
① + ⑥
CREATE INDEX [IX_Member_Tel_DeleteFlag] ON [Member] ([tel], [DeleteFlag])
INCLUDE ([RegistDate])
② + ③ + ⑤
CREATE INDEX [IX_Member_LoginName] ON [Member] ([LoginName], [HashedPassword])
INCLUDE ([Sei], [Mei], [GenderID], [PrefectureID], [DeleteFlag])
④
CREATE INDEX [IX_Member_DeleteFlag_RegistDate] ON [Member] ([DeleteFlag], [RegistDate])](https://image.slidesharecdn.com/sqlserverperformancetuning-210402091320/85/SQL-Server-Performance-Tuning-Essentials-253-320.jpg)
SQL Server Performance Tuning Essentials
- 7. 対象者 • 日頃SQL Server / Azure SQL Databaseを使って開発・運用・管理 などを行っており、単一または全体的なクエリパフォーマンス やサーバーのCPU高負荷状態に悩んでいる人 • CPU負荷を削減することで、クラウドで稼働中のDBをスケール ダウン/スケールインしてコストカットしたい人
- 8. 前提条件 • SQLの使用経験 • SQL Serverの使用経験 • SQL ServerのPaaSの使用経験 (Azure/AWS/GCP) • SQL Server Management Studio (SSMS)の使用経験
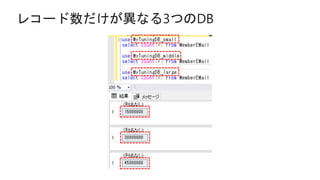
- 11. サンプルDBの内容 DB名 Member レコード数 MemberEMail レコード数 MyTuningDB_small 1,000万 1,500万 MyTuningDB_middle 2,000万 3,000万 MyTuningDB_large 3,000万 4,500万
- 13. サンプルDBについて • SQL Server 2019以降でリストア可能 • 用途:サンプルDBを使ってクエリチューニングを体感してもらう • データはすべてランダムに生成したデータ • 電話番号やメールアドレスはランダムだが、実在の可能性がある ため別用途での使用は禁止
- 14. 個別最適
- 20. クエリチューニングの流れ 1.対象クエリと削減したい値(duration/cpu)の決定 2.指標の計測 ① 3.チューニング実施(クエリ書き換え、インデックス作成等) 4.指標の計測 ② 5.評価
- 21. クエリチューニングの例 1. 実行時間 (duration) を削減したい 2. 指標の計測 ① 3. クエリチューニング(クエリの書き換え、インデックス作成など) 4. 指標の計測 ② 5. 評価 例:チューニングの結果、実行時間を1000msから10msへと99% 削減できた
- 24. Chapter 2 Lesson 3 set statistics time onとは
- 25. duration 計測方法① set statistics time on cpu
- 27. 計測方法② sys.dm_exec_query_stats • キャッシュされたクエリプランのパフォーマンス統計を取得 • プランがキャッシュから削除されると、そのプランに紐づく 統計データも消える • 粒度はステートメント単位 → 1ストアド内で3クエリ実行するストアドだと3行取得
- 29. duration/cpu 計測方法の使い分け • リリース前:set statistics time on SSMSでの検証時に手動で実行するクエリ • リリース後:sys.dm_exec_query_stats アプリケーションが実行しているクエリ
- 30. なぜsys.dm_exec_query_statsを使うのか? • プロダクション環境ではさまざまなパラメータでクエリが実行 • パラメータによって実行時間が大幅に変化するケースもある 例)リリース前の手動での検証時は「where col1 = 1」で1秒だったが、リリース後は 「where col1 = 2」が指定されることが多く、この場合だと10秒かかる。 • sys.dm_exec_query_statsを使えば、プロダクション環境で指定さ れるさまざまなパラメータによって実行された実際の duration/cpuを取得できる • プロダクション環境でのチューニングの評価方法として妥当
- 31. 注意点① durationとcpuは大きく違う場合も • duration >> cpu ロック競合などで待たされる時間が多いと、この関係になる • duration << cpu 並列クエリの場合はcpu時間のほうが大きくなることがある • duration/cpuは個別に把握することが大事
- 32. • コストとは • あるスペックのマシンでそのクエリを実行した場合に想定さ れる実行時間 • コストが高くても「実行時間が長そうだとSQL Serverが思っ ている」ということまでしかわからない • 基本的にはコストが低いほどduration/cpuも低いが、コストが下 がってもduration/cpuが増えることもある ⇒ 指標として不適当 注意点② 評価の指標にコスト値は使わない
- 35. SQLは宣言型言語 最大の利点は「なにを」と「どのように」を分離できること select * from Member where MemberID = 18629764 なにを取得したいか=SQL どのように取得するか=実行プラン
- 38. durationの差と実行プランの違い • インデックス効いてる • select * from [Member] where LoginName = 'HunterGreen45744363' • インデックス効いてない • select * from [Member] with(index(PK_Member)) where LoginName = 'HunterGreen45744363’
- 41. インデックスとは • クエリ高速化に有効なデータ構造 • さまざまな種類があるが、SQL Serverでもっとも一般的なのは ツリー構造のインデックス
- 42. 2種類の基本的なインデックス • クラスタ化インデックス • 1テーブルに1個 • テーブルの実データ(=全カラム)が格納 • 非クラスタ化インデックス • 1テーブルに0~999個 • テーブルの一部のカラムが格納 ⇒ どちらもページを論理的につなげてツリー構造にしたもの
- 43. page page page page page page page 双方向連結リスト B-Tree (Balanced-Tree) Root Branch (中間) Leaf
- 45. クラスタ化インデックスの定義 [MemberID]で並び替えられたツリー構造になっている ALTER TABLE [dbo].[Member] ADD CONSTRAINT [PK_Member] PRIMARY KEY CLUSTERED ( [MemberID] ASC )
- 46. クラスタ化インデックス:キーで並び替え Root Branch Leaf 実データ インデックスキーの範囲情報 + 対応するページ番号 MemberID Page 1-50000 ① 50001-100000 ② ① ② MemberID Page 1-25000 ③ 25001-50000 ④ ③ ④ MemberID LoginName … RegistDate 1 a1 … 2020/10/1 2 a2 … 2020/10/2 … … … … 25000 b1 … 2020/10/3
- 47. Chapter 3 Lesson 4 Index SeekとIndex Scan
- 49. ひとつずつ実行してみよう select * from Member where MemberID = 18629768 select * from Member where LoginName = 'Janita1317' どちらも使われるインデックスは同じ ⇒ インデックスはどう使われたのか?
- 50. 瞬時に実行完了したクエリ:Index Seek select * from Member where MemberID = 18629768
- 51. 時間がかかったクエリ:Index Scan select * from Member where LoginName = 'Janita1317'
- 52. 矢印の向きが違うだけなのになぜ速い/遅い? DECLARE @DB_ID int, @Object_ID int set @DB_ID = DB_ID('MyTuningDB_small') set @Object_ID = OBJECT_ID('Member') SELECT name, index_id, index_type_desc, index_depth, index_level, page_count, record_count, avg_fragmentation_in_percent as 断片化率 FROM sys.dm_db_index_physical_stats (@DB_ID, @Object_ID, NULL , NULL, 'DETAILED') as A JOIN sys.objects as B with(nolock) on A.object_id = B.object_id ORDER BY index_id, index_level desc
- 54. ツリーの深さ(4) << リーフページ数(160350) リーフページ数:160350 ツリーの深さ:4 Level=2 Level=1 Level=0 Level=3 seek時の読み取りページ数 << scan時の読み取りページ数
- 55. Seek = 読み取りページ数が圧倒的に小さい(160350 → 4) = 高速 リーフページ数:160350 ツリーの深さ:4 Level=2 Level=1 Level=0 Level=3
- 57. インデックスが効く(=seek)条件 例:「インデックスの並び順」=「where句で指定した条件」 ALTER TABLE [dbo].[Member] ADD CONSTRAINT [PK_Member] PRIMARY KEY CLUSTERED ( [MemberID] ASC ) 効く:select * from Member where MemberID = 18629768 効かない:select * from Member where LoginName = 'Janita1317' インデックス≠万能薬
- 58. set statistics io onで読み取りページ数を確認 seek scan
- 59. set statistics time, io on で両方確認も可能
- 60. 時間がかかったクエリを高速化するには? select * from Member where LoginName = 'Janita1317'
- 61. これが
- 62. こうなればOK
- 63. そのための新しいインデックス CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ( [LoginName] ASC )
- 64. 非クラスタ化インデックス Root Branch Leaf キー+クラスタ化インデックスキー インデックスキーの範囲情報 + 対応するページ番号 LoginName Page a1-c1 ① c2-d1 ② ① ② LoginName Page a1-b1 ③ b2-c1 ④ ③ ④ LoginName MemberID a1 1 a2 2 … … b1 25000
- 66. 付加列インデックス CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ( [LoginName] ASC ) INCLUDE (RegistDate)
- 67. 付加列インデックスの構造 Root Branch Leaf キー+クラスタ化インデックスキー+付加列 インデックスキーの範囲情報 + 対応するページ番号 LoginName Page a1-c1 ① c2-d1 ② ① ② LoginName Page a1-b1 ③ b2-c1 ④ ③ ④ LoginName MemberID RegistDate a1 1 2020/10/1 a2 2 2020/10/2 … … … b1 25000 2020/10/3
- 68. 複合インデックス CREATE NONCLUSTERED INDEX [IX_Member_Sei_PrefectureID] ON [dbo].[Member] ( [Sei] ASC, [PrefectureID] ASC ) 複合インデックス = 複数のカラムをインデックスキーに指定
- 69. 複合インデックス Root Branch Leaf ① ② ③ ④ Sei PrefectureID Page Adena 40 ① Barrett 25 ② Sei PrefectureID Page Adena 40 ③ Adrian 3 ④ Sei PrefectureID MemberID Adena 40 523 Adena 42 613 作成時に指定したカラムの順序で インデックスキーが作成される
- 70. 複合インデックスを使用した検索 インデックスキーに指定したカラムの順序が検索効率に影響する SELECT COUNT(*) FROM Member WHERE Sei = 'Adena' AND PrefectureID = 1 → インデックス作成時に指定したカラムの両方が検索条件に含まれる SELECT COUNT(*) FROM Member WHERE Sei = 'Adena‘ → インデックス作成時に指定した「先頭のカラム」が検索条件に含まれる SELECT COUNT(*) FROM Member WHERE PrefectureID = 1 → インデックス作成時に指定したカラムは含むが、「先頭のカラム」が検索条件に 含まれていない • Index Seekで検索されるケース • Index Seekで検索が行われないケース ⇒ インデックスの先頭には検索に使われる頻度の多い項目を指定する
- 72. キー参照 非クラスタ化インデックスだけではカラムを返せないとき • 非クラスタ化インデックスでIndex Seek • リーフページでクラスタ化インデックスキー取得 • 取得したキーでクラスタ化インデックスをIndex Seek ( = キー参照)
- 73. LoginName MemberID RegistDate a1 1 2020/10/1 a2 2 2020/10/2 … … … b1 25000 2020/10/3 SELECT LoginName, RegistDate, Sei FROM Member WHERE LoginName = 'b1' リーフページに[Sei]が無い 非クラスタ化インデックス 実データ MemberID LoginName … Sei 1 a1 … Asai 2 a2 … Tanaka … … … … 25000 b1 … Yokota クラスタ化インデックス キー参照 (MemberID = 25000でIndex Seek)
- 74. カバリングインデックス • 上記ようなインデックスが作成されている場合 CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName] ASC) INCLUDE (RegistDate) キー参照が発生しないインデックスを「カバリングインデックス」 SELECT LoginName, RegistDate FROM Member WHERE LoginName = 'Tawny265167' インデックスキー インデックスキー INCLUDE カラム クエリに必要なカラムをカバーするインデックスになっている =カバリングインデックス
- 76. カバリングインデックスのポイント • カバリングかどうかはクエリごとに決まる • インデックスは下記のクエリに対して「カバリング」 • インデックスは 下記のクエリに対して「カバリングではない」 CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName] ASC) INCLUDE (RegistDate) SELECT LoginName, RegistDate FROM Member WHERE LoginName = 'Tawny265167' SELECT LoginName, RegistDate, Sei FROM Member WHERE LoginName = 'Tawny265167'
- 78. インデックスのまとめ① • クラスタ化インデックス • キーの順番で並び替えられている • 1テーブルにつき1個だけしか作れない • 非クラスタ化インデックス • キーの順番で並び替えられている キーの範囲情報 キーの範囲情報 実データ キー + クラスタ化インデックスキー Seek Scan Seek Scan
- 79. • 付加列インデックス • 非クラスタ化インデックスとほぼ同じ • リーフページに付加列も含まれている • 複合インデックス • 非クラスタ化インデックスとほぼ同じ • 複数のカラムをインデックスキーに指定 キー+クラスタ化インデックスキー+付加列 インデックスのまとめ② キーの範囲情報 複数列のキー の範囲情報 Seek Scan Seek Scan キー + クラスタ化インデックスキー
- 81. Seek vs Scan • Seekが有利なとき • レコードを大幅に絞り込めるとき • Scanが有利なときやScanしか使われないとき • レコード数が少ないテーブル • count(*)などの集計処理で全件走査が必要なとき
- 83. インデックスのデメリット • ディスク容量が増える • 各インデックスは物理的に独立している • インデックスを作成したテーブルの更新速度が落ちる • 1レコードをINSERTするときも、最大でインデックスの数と同じだけ 書き込みが発生する
- 85. 問題:インデックスを設計してください DECLARE @Tel VARCHAR(20) SET @Tel = '0292866656' SELECT MemberID FROM Member WHERE tel = @Tel
- 86. 回答 ※MemberIDは主キーなので自動的にインデックスに含まれる CREATE NONCLUSTERED INDEX [IX_Member_Tel] ON [dbo].[Member] ([Tel])
- 87. 問題:インデックスを設計してください DECLARE @LoginName VARCHAR(20) SET @LoginName = 'Keg River4714' SELECT MemberID ,GenderID ,PrefectureID FROM Member WHERE LoginName = @LoginName
- 88. 回答① CREATE NONCLUSTERED INDEX [IX_Memer_LoginName] ON [dbo].[Member] ([LoginName])
- 89. 回答②:付加列を追加 CREATE NONCLUSTERED INDEX [IX_Memer_LoginName] ON [dbo].[Member] ([LoginName]) INCLUDE ([GenderID], [PrefectureID])
- 93. レコード数だけが異なる3つのDB
- 94. 事前準備:各DBでインデックス再構築 use MyTuningDB_small alter index PK_MemberEMail on MemberEMail rebuild go use MyTuningDB_middle alter index PK_MemberEMail on MemberEMail rebuild go use MyTuningDB_large alter index PK_MemberEMail on MemberEMail rebuild go
- 95. 各DBごとにインデックスの構造を確認 DECLARE @OBJECT_ID int set @OBJECT_ID = OBJECT_ID('MemberEMail') SELECT index_id ,index_type_desc ,index_depth ,index_level ,page_count ,record_count FROM sys.dm_db_index_physical_stats (DB_ID(), @OBJECT_ID, NULL , NULL, 'DETAILED') as A JOIN sys.objects as B on A.object_id = B.object_id ORDER BY index_id, index_level
- 97. レコード数増加によるインデックス構造の変化まとめ • 1000万単位のレコード数の差でもツリーの深さはほぼ同じ (index_depth = 3 or 4) • リーフノードのページ数(page_count)はレコード数にほぼ比例
- 101. Index Scanのポイント • レコード数が増えるほど「論理読み取り数」が増加 • リーフノードのページ数にほぼ一致 • レコード数が増えるほど如実に実行時間が増加 • 1.5秒 → 3秒 → 5秒
- 104. Index Seekのポイント • レコード数が増えても「論理読み取り数」がほぼ同じ • インデックスの階層数にほぼ一致 • そのためレコードが大幅に増加しても実行時間はほぼ同じ • Index Seekの強力な特徴
- 105. パフォーマンスへの影響のまとめ • データ量増加に伴うクエリ実行時間の変化を推定するときに • 「そのクエリの実行はScanなのか、Seekなのか」を 理解しておくことがとても重要 • 信頼度が低い推定 • 「データ量が増えたから遅くなった/遅くなりそう」 • 信頼度が高い推定 • 「データ量が増えてもSeek処理なので速度は変わらないはず」 • 「データ量が増えるとScan処理なので徐々に遅くなっていく懸念 がある」
- 106. Chapter 5 実行プランについて
- 108. このチャプターの目標 • 実行プランの見方を理解する • 実行プランで押さえておくべき演算子を理解する • チューニング目的で実行プランを見る際のポイントを理解する
- 109. 実行プランとは • 「どのように」データを取ってくるかの計画図 • SQL Serverがプランを作成する • グラフィカルなものとテキストベースの2種類がある • 今回はグラフィカルな実行プランを用いる
- 113. 実行プランの基本的な演算子まとめ • データへのアクセス方法 • Scan / Seek / キー参照 • 結合方法 • Nested Loops / Hash Match / Merge Join • 並び替え • Sort 他にもたくさんあるが、ボトルネックはこの中のどれかである場合 が多い
- 114. ① Index Scan
- 115. ① Index Scan
- 116. ② Index Seek
- 117. ② Index Seek
- 118. ③キー参照
- 119. ③キー参照
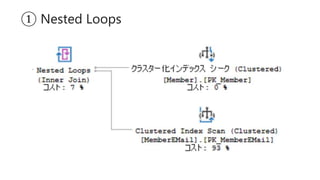
- 121. ① Nested Loops
- 122. ① Nested Loops – 2重for文のイメージ Table_A 1 2 3 4 Table_B 6 D 1 B 5 C 1 A
- 123. ① Nested Loops – 2重for文のイメージ Table_A 1 2 3 4 Table_B 6 D 1 B 5 C 1 A
- 124. ① Nested Loops – 2重for文のイメージ Table_A 1 2 3 4 Table_B 6 D 1 B 5 C 1 A
- 125. ① Nested Loops – 2重for文のイメージ Table_A 1 2 3 4 Table_B 6 D 1 B 5 C 1 A 1 1 B 1 1 A
- 126. ② Hash Match
- 127. ② Hash Match Table_A 1 2 3 4 ハッシュテーブルを作る Table_A ハッシュ値 1 1agsc3 2 fasd98 3 42cf89 4 fgt2cc ハッシュテーブル Table_B 6 D 1 B 5 C 3 A 35vxxv ハッシュ値計算、 マッチング
- 128. ② Hash Match Table_A 1 2 3 4 ハッシュテーブルを作る Table_A ハッシュ値 1 1agsc3 2 fasd98 3 42cf89 4 fgt2cc ハッシュテーブル Table_B 6 D 1 B 5 C 3 A 35vxxv 1agsc3 ハッシュ値計算、 マッチング h577v
- 129. ② Hash Match Table_A 1 2 3 4 ハッシュテーブルを作る Table_A ハッシュ値 1 1agsc3 2 fasd98 3 42cf89 4 fgt2cc ハッシュテーブル Table_B 6 D 1 B 5 C 3 A 35vxxv 1agsc3 h577v 42cf89 1 1 B 3 3 A ハッシュ値計算、 マッチング
- 130. ③ Merge Join
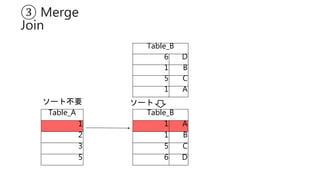
- 131. ③ Merge Join Table_B 6 D 1 B 5 C 1 A Table_A 1 2 3 5 Table_B 1 A 1 B 5 C 6 D ソート不要 ソート
- 132. ③ Merge Join Table_B 6 D 1 B 5 C 1 A Table_A 1 2 3 5 Table_B 1 A 1 B 5 C 6 D ソート不要 ソート
- 133. ③ Merge Join Table_B 6 D 1 B 5 C 1 A Table_A 1 2 3 5 Table_B 1 A 1 B 5 C 6 D ソート不要 ソート
- 134. ③ Merge Join Table_B 6 D 1 B 5 C 1 A Table_A 1 2 3 5 Table_B 1 A 1 B 5 C 6 D ソート不要 ソート
- 135. ③ Merge Join Table_B 6 D 1 B 5 C 1 A Table_A 1 2 3 5 Table_B 1 A 1 B 5 C 6 D ソート不要 1 1 A 1 1 B 5 5 C ソート
- 136. JOINの使い分け • 基本的にSQL Server側が最適な結合方法を判断する • JOINする2テーブルのサイズやインデックスの有無で最適な方法が違う • Nested Loops • 小さめのデータセットや where句でレコード数が大幅に絞り込めるとき向き • Merge Join / Hash Match • 大規模テーブル同士でレコード数が絞り込めないとき向き • メモリ消費大。場合によってはtempDBへの物理書き込み発生で速度低下
- 137. 常に最適なJOINが選択されるわけではない 「Nested Loopsが良いはずなのにHash Matchになっている」 「Hash MatchがいいはずなのにNested Loopsになっている」 といった箇所がボトルネックになる可能性はある
- 138. Sort:データの並び替え
- 140. 実行プランで見るべきポイント① • シーク述語 • Index Seek時にレコードを絞り込む条件 • 述語 • リーフページ走査時にレコードを絞り込む条件 • オブジェクト • 走査対象のクラスタ化インデックス/非クラスタ化インデックス/ヒープ
- 141. 実行プランで見るべきポイント② • 予測行数 / 実際の行数 / およびその差 • 予測実行回数 / 実際の実行回数 / およびその差 • 予測と実際の乖離が大きく、実行時間が長い場合は他に最適なプランが 存在する可能性がある
- 144. 問題:インデックスを設計してください SELECT TOP 10 * FROM MemberEMail ORDER BY Email ASC
- 145. 回答:ソートをカットするインデックス create index [IX_MemberEMail_Email] on [MemberEmail] ([Email] asc)
- 146. 問題:インデックスを設計してください SELECT TOP 10 * FROM MemberEMail ORDER BY DeleteFlag ASC ,Email DESC
- 147. 回答:order byとキーの並び順を同じにする create index [IX_MemberEMail_DeleteFlag_Email] on [MemberEmail] ([DeleteFlag] asc, [EMail] desc)
- 148. 問題:インデックスを設計してください SELECT TOP 10 * FROM MemberEMail WHERE DeleteFlag = 0 ORDER BY Email
- 149. 回答:クエリ実行順序とキーの順番を同じにする create index [IX_MemberEMail_DeleteFlag_Email] on [MemberEmail]([DeleteFlag], [EMail])
- 150. Chapter 6 クエリの実行
- 154. 実行プランを理解するためのポイント • 実行プランを生成するタイミングでは、オプティマイザは WHERE句でどれだけレコードが絞り込まれるかわからない ⇒ 推定するしかない • 絞り込まれるレコード数の推定方法 = 基数推定アルゴリズム • 基数推定に使用する重要な情報が統計情報
- 157. • インデックス作成時に対応する統計情報が 自動作成される • PK_Member • MemberテーブルのPKの統計情報 • _WA_Sys_*** • クエリ実行時に自動作成される場合あり 統計情報の概要
- 158. PK_Memberの統計情報 ① • 名前: 統計情報の名前 • 更新 : 統計情報の更新日時 • 行 : レコード数 • サンプリングされた行数 • 手順 : ヒストグラムのステップ数 • 列 : どのカラムの情報か
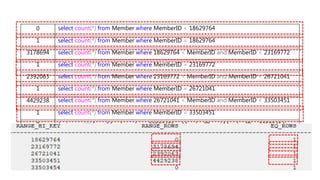
- 159. • RANGE_HI_KEY:ステップの上限キー • RANGE_ROWS:ステップ内の行数(上限は含まない) • EQ_ROWS:上限の値と列の値が等しい行数 PK_Memberの統計情報 ②
- 160. 0 1 3178694 1 2392063 1 4429238 1 0 1 0 select count(*) from Member where MemberID < 18629764 select count(*) from Member where MemberID = 18629764 select count(*) from Member where 18629764 < MemberID and MemberID < 23169772 select count(*) from Member where MemberID = 23169772 select count(*) from Member where 23169772 < MemberID and MemberID < 26721041 select count(*) from Member where MemberID = 26721041 select count(*) from Member where 26721041 < MemberID and MemberID < 33503451 select count(*) from Member where MemberID = 33503451 select count(*) from Member where 33503451 < MemberID and MemberID < 33503454 select count(*) from Member where 33503454 = MemberID select count(*) from Member where 33503454 < MemberID
- 161. ヒストグラム化するとこうなる
- 162. 通常はレコード数 >> サンプル 数 • 先ほどの例はサンプリング率100%(フルスキャン) update statistics member update statistics member with fullscan • with fullscan無し:レコード数に応じて自動でサンプリング率が決定
- 163. 統計情報のポイント① • 統計情報は「不完全な情報」 • 各テーブルの各レコードの全カラムの情報がわかれば、最適なプランは 生成しやすい • ただし全レコードを実行前にチェックしていると時間がかかってしまう → 最適化に時間がかかっては意味がない • そこで統計情報を利用する → 完全な情報ではなく、ざっくりとしたカラム値の分布で代用 • 基数推定アルゴリズムも完ぺきではない = 誤差は生じる • 統計情報を使って、WHERE句の絞り込みレコード数を推定する → 統計情報の時点でざっくりとした情報なので、完璧な精度は出ない ⇒ 自分で「このプランは妥当なのか」を評価する力が重要
- 164. • 統計情報は常に更新されるわけではない • 統計の自動更新がONになっていても、全レコードの20%が更新されて はじめて統計も更新される • 実際のデータ分布と統計情報に乖離が生まれる場合がある • 乖離が大きいほど、最適な実行プランが生成されない可能性も上がる 統計情報のポイント②
- 165. 統計情報についてのまとめ • オプティマイザの仕事は最高のプランを見つけることではなく、 限られた時間で「良いプラン」を生成すること • オプティマイザは実行プランを生成する際に統計情報を利用 • 統計情報はざっくりとしたカラムの分布をヒストグラムで保持 • 諸条件により最適でないプランが生成される場合もある • 統計情報のサンプリング数 • 統計情報の更新日時 • 基数推定アルゴリズムの限界
- 169. このレッスンで使う用語について • 検索述語:WHERE句の各条件のこと • selectivity (選択性):検索述語が行をどれだけ絞り込めるかの指標 • selectivityが良い:少ない行に絞り込みができること • 適切なインデックス:作成することでIOを劇的に削減できるインデックスのこと
- 170. 検索述語のselectivity評価例① 検索述語:MemberID = 18629764 1,000万レコードを1行に絞り込み →「selectivityがもっとも良い」
- 171. 検索述語のselectivity評価例② 検索述語:DeleteFlag = 0 1,000万レコードを約半数に絞り込み →「selectivityが悪い」
- 172. 「selectivityが良い」のボーダーラインは? • 「レコード全体の5%程度」まで絞り込めるか • 1,000万レコードのテーブルであれば、5%の50万レコードまで • ポイント:主キーやユニークキーはselectivityがもっとも良い • 「5%」の基準はディスク性能など環境によって変わる • あくまで目安と考えておく
- 173. 検索述語のselectivity評価例③ 検索述語:DeleteFlag = 0 and PrefectureID = 6 and GenderID = 2 and Sei = 'Marlin’ 1,000万レコードを26行に絞り込みできるので「selectivityが良い」 複数の検索述語もひとまとめで考えてOK
- 174. selectivityが良いクエリにインデックスを作成 • demo用クエリ select * from Member where DeleteFlag = 0 and PrefectureID = 6 and GenderID = 2 and Sei = 'Marlin' create index IX_Member_1 on Member (DeleteFlag, PrefectureID, GenderID, Sei) • demo用インデックス
- 175. 「適切なインデックス」を作るポイント selectivityの良い検索述語の組み合わせでインデックスを作ること で「適切なインデックス」を作成できる select * from Member where DeleteFlag = 0 and PrefectureID = 6 and GenderID = 2 and Sei = 'Marlin' create index IX_Member_1 on Member (DeleteFlag, PrefectureID, GenderID, Sei)
- 176. まとめ • 高速なクエリ = selectivityの良い検索述語 + 適切なインデックス • クエリチューニングの際は以下の2点を確認 • selectivityの良い検索述語があるか • 適切なインデックスが存在するか
- 181. チューニング後の実行プラン
- 183. MemberEMailのシーク述語は「結合条件」 select MemberID from Member where DeleteFlag = 0 and Tel = '0698903494' select MemberID from MemberEMail where MemberID = 18629764 and MainFlag = 1
- 184. 元クエリ SQL Serverが クエリ実行する際の イメージ select A.MemberID from Member A join MemberEMail B on A.MemberID = B.MemberID where A.DeleteFlag = 0 and A.Tel = '0698903494' and B.MainFlag = 1 select MemberID from Member where DeleteFlag = 0 and Tel = '0698903494' select MemberID from MemberEMail where MemberID = 18629764 and MainFlag = 1 ①まずMemberから MemberIDを取得 ②取得したMemberIDを検索 述語に追加
- 185. 実行プランのシーク述語をチェック ・Memberのシーク述語は元クエリのwhere句と同一 ・MemberEMailのシーク述語は元クエリのwhere句「MainFlag = 1」 ではなく、元クエリの結合条件「A.MemberID = B.MemberID」
- 186. select A.MemberID from Member A join MemberEMail B on A.MemberID = B.MemberID where A.DeleteFlag = 0 and A.Tel = '0698903494' and B.MainFlag = 1
- 187. selectivityが悪い時:後続の処理にも影響 select * from Member A join MemberEMail B on A.MemberID = B.MemberID where A.PrefectureID = 1 and A.DeleteFlag = 0 and A.Sei like 'a%' and B.MainFlag = 1
- 189. selectivityのまとめ① • JOINを含むSELECT文の実行の流れ 1. 各テーブル(正確にはインデックスまたはヒープ)ごとに データを絞り込む 2. テーブルを合体させる 3. 1と2を繰り返す • 検索述語に複数テーブルのカラムが指定されていても、 基本的には最もselectivityが良い検索述語のみがシーク述語 となり、それ以外は結合条件がシーク述語となる
- 190. selectivityのまとめ② • もっともselectivityが良い検索述語による絞り込みレコード数は、 その後の各結合処理の実行回数(≒レコード数)へと 影響が伝搬していく • selectivityが良い → パフォーマンス的な好影響が伝搬していく • selectivityが悪い → パフォーマンス的な悪影響が伝搬していく
- 193. 問題:インデックスを設計してください DECLARE @MemberID INT SET @MemberID = 18629764 SELECT * FROM Member a JOIN MemberEMail b ON a.MemberID = b.MemberID WHERE a.MemberID = @MemberID ORDER BY MainFlag DESC
- 194. 回答:MemberEMailのScanをSeekにしたい CREATE NONCLUSTERED INDEX [IX_MemberEmail_MemberID] ON [dbo].[MemberEMail] ([MemberID])
- 196. 問題:インデックスを設計してください DECLARE @Tel VARCHAR(100) SET @Tel = '09002505878' SELECT LoginName, Sei, Mei, Tel FROM Member a WHERE EXISTS ( SELECT * FROM MemberEMail b WHERE a.MemberID = b.MemberID AND MainFlag = 1 AND b.DeleteFlag = 0 ) AND Tel = @Tel
- 197. 回答:まずMemberのScanをSeekにする CREATE NONCLUSTERED INDEX [IX_Member_Tel] ON [dbo].[Member] ([Tel])
- 199. 次にMemberEMailのScanをSeekにする CREATE NONCLUSTERED INDEX [IX_MemberEMail_MemberID] ON [dbo].[MemberEMail] ([MemberID]) INCLUDE ([MainFlag], [DeleteFlag])
- 201. インデックス設計のポイント • とりあえず実行して「実際の実行プラン」をチェックする • 「ボトルネックはどこか」という観点で実行プランを見る • インデックスをひとつずつ作成していく • プラン確認 → インデックス作成 → プラン確認 をチューニング完了まで繰り返す
- 205. 全体最適なチューニングをするときの前提 • インスタンスでは多数のクエリが実行されている • 各クエリの詳細は把握していない • 各クエリの実行頻度も把握していない • 「どのクエリをチューニングすればいいのか」を調査すべき
- 206. パレートの法則(80:20の法則) • 「全体の数値の大部分は全体を構成するうちの一部の要素が 生み出している」という理論 • 例:ビジネスにおいて、売上の8割は全顧客の2割が生み出している • 例:商品の売上の8割は、全商品銘柄のうちの2割が生み出している
- 207. パレートの法則をDBサーバーに当てはめる • DBサーバー1台にかけるCPU負荷の8割は、 全クエリの2割が生み出している • DBサーバー1台で実行されるクエリの総実行時間の8割は、 全クエリの2割が生み出している • この「2割」のクエリを見つけ出すことが、 少ない労力で大きなCPU負荷減や総実行時間減につながる ※ 実際は1割以下のこともある
- 212. 拡張イベントとは 軽量なパフォーマンス監視システム ⇒ SQL Server ProfilerやSQLトレースの上位互換
- 213. 拡張イベントの例
- 214. チューニング目的でよく使用するイベント • rpc_completed:リモートプロシージャコール完了 • sql_batch_completed:バッチ完了 • sp_statement_completed:ストアドプロシージャの ステートメント完了 • sql_statement_completed:ステートメント実行完了
- 215. 各イベントの関係性 cpu/durationともに rpc_completed + sql_batch_completed ≒ コンパイル時間 + sp_statement_completed + sql_statement_completed まずはrpc_completed+sql_batch_completedの粒度で調査する 必要に応じてstatement系にドリルダウンする
- 217. DMV(Dynamic Management View)とは • サーバーの情報が格納されたViewのこと。沢山種類がある • sys.dm_exec_query_stats ⇒ クエリの実行統計(cpu/durationなど)をキャッシュ • 累積値なので、2回情報を取得して差分をとれば該当時間帯の 各クエリのcpuやdurationの合計値を取得できる ⇒ 降順に並び替えると、cpu負荷をかけているクエリを見つけ るといったことが可能
- 219. テーブルに作成すべきインデックスの数は? • 一般的にインデックスが増えるほど • 読み取りは高速になる • 更新は低速になる ⇒ 明確な答えはない • あるテーブルAに作成すべき最適なインデックスは 「テーブルAを参照する全クエリの総実行時間を最小化する インデックスの組み合わせ」
- 220. 総実行時間を最小化するインデックスの組み合わせ • インデックスの組み合わせで総実行時間や総CPU時間は変化する • 考えられるインデックス全パターンを試すのは時間的に無理 • そのため、実際には完璧な最適解は得られない
- 221. ではどうするか? 各テーブルに関するワークロードの性質を理解して柔軟に対応する • write heavyならインデックスは必要最小限に留める • read heavyならインデックスを積極的に作成する
- 222. インデックス作成の基本戦略 • 必要最小限のインデックス設計を心がける • キーが同じで付加列だけ異なる等のインデックスはまとめる • 意図した使われ方をしているか確認する • DMVを使ってseek回数とscan回数の比率をチェックする
- 223. インデックス作成のアンチパターン 各クエリごとに最適なインデックスを作成する ⇒ 似たインデックスが大量に作成される CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ( [LoginName] ASC ) INCLUDE (RegistDate) CREATE NONCLUSTERED INDEX [IX_Member_LoginName2] ON [dbo].[Member] ( [LoginName] ASC ) INCLUDE (Sei, Mei) CREATE NONCLUSTERED INDEX [IX_Member_LoginName3] ON [dbo].[Member] ( [LoginName] ASC, [RegistDate] ASC ) INCLUDE (Sei, Mei) CREATE NONCLUSTERED INDEX [IX_Member_LoginName4] ON [dbo].[Member] ( [LoginName] ASC ) INCLUDE (DeleteFlag)
- 224. CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ( [LoginName] ASC ) INCLUDE (RegistDate) CREATE NONCLUSTERED INDEX [IX_Member_LoginName2] ON [dbo].[Member] ( [LoginName] ASC ) INCLUDE (Sei, Mei) CREATE NONCLUSTERED INDEX [IX_Member_LoginName3] ON [dbo].[Member] ( [LoginName] ASC, [RegistDate] ASC ) INCLUDE (Sei, Mei) CREATE NONCLUSTERED INDEX [IX_Member_LoginName4] ON [dbo].[Member] ( [LoginName] ASC ) INCLUDE (DeleteFlag) CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ( [LoginName] ASC , [RegistDate] ASC ) INCLUDE (RegistDate, Sei, Mei, DeleteFlag)
- 225. 意図した使われ方をしているか確認する declare @TableName varchar(1000) = 'Member' select OBJECT_NAME(i.object_id) as table_name ,i.name as index_name ,ps.row_count as row_count ,ps.reserved_page_count * 8.0 / 1024 as size_mb ,type_desc ,us.* from sys.dm_db_partition_stats ps left join sys.indexes i on ps.object_id = i.object_id and ps.index_id = i.index_id left join sys.dm_db_index_usage_stats us on ps.object_id = us.object_id and ps.index_id = us.index_id where OBJECT_NAME(i.object_id) = @TableName order by index_id
- 227. 必要最小限のインデックスを設計する SELECT句でしか使わないカラムは基本的には付加列にする select Sei, Mei from Member where LoginName = 'Test' 〇 CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName]) INCLUDE ([Sei], [Mei]) × CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName], [Sei], [Mei])
- 228. なぜSELECT用カラムは付加列か? ・付加列として加えておいた方がインデックスに拡張性がある select top 10 Sei, Mei from Member where LoginName like 'Te%' and DeleteFlag = 1 • 例えば、上記のクエリを使った処理を 新しくリリースした場合を考慮する
- 229. 付加列にしたインデックスの場合 ・既存のインデックスを一度DROPして作り直せばOK CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName]) INCLUDE ([Sei], [Mei]) CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName], [DeleteFlag]) INCLUDE ([Sei], [Mei]) ・ひとつのインデックスで2種類のクエリに対応可能
- 230. CREATE NONCLUSTERED INDEX [IX_Memaber_LoginName] ON [dbo].[Member] ([LoginName], [DeleteFlag]) INCLUDE ([Sei], [Mei]) select Sei, Mei from Member where LoginName like 'Te%' and DeleteFlag = 1 select Sei, Mei from Member where LoginName = 'Test'
- 231. 付加列にしないインデックスの場合 • 追加で別のインデックスを作るしかなくなる CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName], [Sei], [Mei]) CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName], [DeleteFlag], [Sei], [Mei]) • このインデックスにまとめようとするのはNG。なぜか?
- 232. • インデックスを修正する時点でプロダクション環境で 実行されている全クエリを把握するのは難しい CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName], [Sei], [Mei]) select * from Member where LoginName = 'Test' and Sei = 'aaa' and Mei = 'bbb' • この既存インデックスだけみると、下記のようなクエリが すでに実行されていると考えるのが妥当 ・よってインデックスを増やすしかなくなる
- 233. • 結果的に以下のふたつのインデックスを作成する必要が出てくる CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName], [Sei], [Mei]) CREATE NONCLUSTERED INDEX [IX_Member_LoginName2] ON [dbo].[Member] ([LoginName], [DeleteFlag], [Sei], [Mei]) • 無駄な容量や更新時のコスト増につながる
- 234. ・一般化:良いselectivityが得られる最小カラム構成をとる 例:MemberテーブルはLoginNameでUniqueとなる性質がある ↓これが0レコード select LoginName from Member group by LoginName having count(*) > 1 select Sei, Mei from Member where LoginName = 'Test' and DeleteFlag = 1 CREATE NONCLUSTERED INDEX [IX_Member_LoginName] ON [dbo].[Member] ([LoginName]) INCLUDE ([Sei], [Mei], [DeleteFlag]) ・したがって、上記のクエリのインデックスは下記でOK
- 236. 全体最適なインデックス設計のまとめ • 良いselectivityが得られる最小カラム構成をとる • SELECT句でしか使わないカラムは基本付加列にする • WHERE句で使っているカラムでも、 それ以外のカラムで良いselectivityが得られるなら付加列でOK • 理由:インデックスの拡張性を保ち、できるだけ少ない インデックスで多くのクエリに対応できるため
- 238. ポイント①:アドホッククエリを避ける • アドホッククエリ • where句などで値が直接指定されているクエリのこと • SQLインジェクションの危険性 • 毎回コンパイルされる可能性が高くCPU負荷増、実行時間増に つながりやすい • 1文字でも異なれば各クエリすべてがキャッシュされるため メモリ効率が悪い select * from Member where PrefectureID = 2
- 239. 開発時の基本方針 • パラメータ化クエリまたはストアドプロシージャを使用する • パラメータごとのselectivityが大きく異なる場合は パラメータスニッフィングによる実行速度の低下に注意する • クエリプランの後退にも注意する
- 240. パラメータごとのselectivity 例:1,000万レコードのテーブル • select * from Member where PrefectureID = 1 → 9,999,995レコード • select * from Member where PrefectureID = 2 → 1レコード • select * from Member where PrefectureID = 3 → 1レコード • select * from Member where PrefectureID = 4 → 1レコード • select * from Member where PrefectureID = 5 → 1レコード • select * from Member where PrefectureID = 6 → 1レコード 「PrefectureID = 1」だけ selectivityが大きく異なる
- 241. パラメータスニッフィングとは コンパイル時に受け取ったパラメータにとって最適な実行プランを 生成する挙動のこと declare @PrefID int = 1 select top 10 * from Member where PrefectureID = @PrefID IndexScanの実行プランがキャッシュされ、@PrefIDで別の値が指定されても IndexScanでクエリ実行される @PrefID=1の場合はテーブルの99%以上のレコードが取得されるためIndexScan
- 243. 実行速度の低下に対する対策 リコンパイルヒントを付けて毎回コンパイルする • ストアドプロシージャ:with recompile • パラメータ化クエリ:option (recompile)
- 245. クエリプランの後退への対策 • クエリで使っている統計情報を更新する • 該当クエリをリコンパイルする • DBCC FREEPROCCACHE (plan_handle) • リコンパイルヒントを付けて毎回コンパイルする • ストアドプロシージャ:with recompile • パラメータ化クエリ:option (recompile)
- 246. ポイント②:インデックスが効かないケース • 暗黙の型変換 • where col1 = 1234 -- col1がchar(4)の場合は’1234’にすべき • カラムを加工する • where (col1*3) = 5 • where func(col1) = 5 • like ‘%***%’とする
- 247. ポイント③:ヒント句は使わない • ヒント句は使わず、基本的にはオプティマイザに任せる • 以下のヒント句は場合によっては有効な場合もある • option (maxdop 10) : 並列クエリの多重度を変更する • with(index(index_name)):指定したインデックスの使用を強制 • with(forceseek):index seekを強制
- 249. 問題:全体最適な観点でインデックスを再設計 してください ① CREATE INDEX [IX_Member_Tel] ON [Member] ([tel]) INCLUDE ([RegistDate]) ② CREATE INDEX [IX_Member_LoginName] ON [Member] ([LoginName]) INCLUDE ([Sei], [Mei]) ③ CREATE INDEX [IX_Member_LoginName2] ON [Member] ([LoginName]) INCLUDE ([GenderID], [PrefectureID]) ④ CREATE INDEX [IX_Member_DeleteFlag_RegistDate] ON [Member] ([DeleteFlag], [RegistDate]) ⑤ CREATE INDEX [IX_Member_LoginName_HashedPassword] ON [Member] ([LoginName], [HashedPassword]) INCLUDE ([DeleteFlag]) ⑥ CREATE INDEX [IX_Member_Tel_DeleteFlag] ON [Member] ([tel], [DeleteFlag])
- 251. 解説① ① + ⑥ CREATE INDEX [IX_Member_Tel_DeleteFlag] ON [Member] ([tel], [DeleteFlag]) INCLUDE ([RegistDate]) ① CREATE INDEX [IX_Member_Tel] ON [Member] ([tel]) INCLUDE ([RegistDate]) ⑥ CREATE INDEX [IX_Member_Tel_DeleteFlag] ON[Member] ([tel], [DeleteFlag])
- 252. 解説② ② + ③ + ⑤ CREATE INDEX [IX_Member_LoginName] ON [Member] ([LoginName], [HashedPassword]) INCLUDE ([Sei], [Mei], [GenderID], [PrefectureID], [DeleteFlag]) ② CREATE INDEX [IX_Member_LoginName] ON [Member] ([LoginName]) INCLUDE ([Sei], [Mei]) ③ CREATE INDEX [IX_Member_LoginName2] ON [Member] ([LoginName]) INCLUDE ([GenderID], [PrefectureID]) ⑤ CREATE INDEX [IX_Member_LoginName_HashedPassword] ON [Member] ([LoginName], [HashedPassword]) INCLUDE ([DeleteFlag])
- 253. 最終的な回答 ① + ⑥ CREATE INDEX [IX_Member_Tel_DeleteFlag] ON [Member] ([tel], [DeleteFlag]) INCLUDE ([RegistDate]) ② + ③ + ⑤ CREATE INDEX [IX_Member_LoginName] ON [Member] ([LoginName], [HashedPassword]) INCLUDE ([Sei], [Mei], [GenderID], [PrefectureID], [DeleteFlag]) ④ CREATE INDEX [IX_Member_DeleteFlag_RegistDate] ON [Member] ([DeleteFlag], [RegistDate])
Editor's Notes
- #163: デモ:想定1分
- #218: 使ったクエリ https://github.com/masaki-hirose/SQL-Server-Performance-Tuning/blob/master/EvaluationQuery.sql select top (100) qt.text as parent_query ,SUBSTRING(qt.text, qs.statement_start_offset / 2, (case when qs.statement_end_offset = - 1 then LEN(CONVERT(nvarchar(MAX), qt.text)) * 2 else qs.statement_end_offset end - qs.statement_start_offset) / 2) as statement -- average ,total_worker_time / qs.execution_count / 1000 as average_cpu_time_ms ,total_elapsed_time / qs.execution_count / 1000 as average_duration_ms ,total_physical_reads / qs.execution_count / 1000 as average_physical_reads_ms -- execution count ,qs.execution_count as execution_count -- creation / execution time ,last_execution_time ,creation_time -- total ,total_worker_time / 1000 as total_cpu_time_ms ,total_elapsed_time / 1000 as total_duration_ms ,total_physical_reads / 1000 as total_physical_reads_ms -- query plan ,qp.query_plan from sys.dm_exec_query_stats qs outer apply sys.dm_exec_sql_text(qs.sql_handle) as qt outer apply sys.dm_exec_query_plan(plan_handle) as qp where qt.text like '%%' --filtering by text order by total_worker_time desc