






![object WordCount{
def main(args: Array[String])){
val conf = new SparkConf()
.setAppName("wordcount")
val sc = new SparkContext(conf)
sc.textFile(args(0))
.flatMap(_.split(" "))
.countByValue
.saveAsTextFile(args(1))
}
}
7
public class WordCount {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
Tiny CodeBig Code
Why Spark?](https://image.slidesharecdn.com/the-how-and-why-of-fast-data-analytics-with-apache-spark-160219212016/85/The-How-and-Why-of-Fast-Data-Analytics-with-Apache-Spark-7-320.jpg)



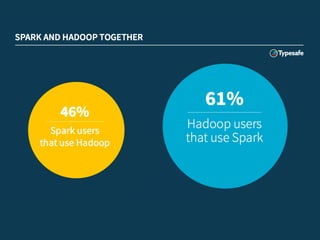


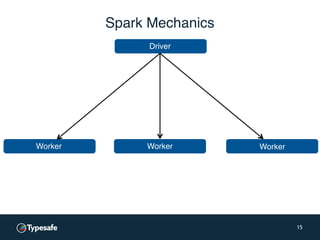









The document outlines a presentation by Justin Pihony on fast data analytics with Apache Spark, covering concerns regarding its adoption, its advantages over MapReduce, and basic coding examples. It highlights Spark's unified API that includes various components such as Spark SQL and Spark Streaming, emphasizing its expressiveness and fault tolerance. Additionally, it offers expert support services from Typesafe for implementing Spark in various infrastructure environments.










































![Interview questions on Apache spark [part 2]](https://cdn.slidesharecdn.com/ss_thumbnails/interviewquestionsonapachesparkpart2-150731093720-lva1-app6892-thumbnail.jpg?width=560&fit=bounds)


















![[Sneak Preview] Apache Spark: Preparing for the next wave of Reactive Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/coll-report-typesafe-apache-spark-slide-share-150127023731-conversion-gate01-thumbnail.jpg?width=560&fit=bounds)



















